「グラフデータベースを使用してリアルタイムの推薦エンジンを構築する方法」
Building real-time recommendation engines using graph databases.
「これはあなたのためです」、「あなたにお勧めです」、「あなたも気に入るかもしれません」というフレーズは、特に電子商取引やストリーミングプラットフォームなどのデジタルビジネスにおいて、不可欠なものになっています。
これらは単純な概念に見えるかもしれませんが、それらはビジネスが顧客との相互作用や接続を行う新しい時代を意味しています。それがレコメンデーションの時代です。
正直に言って、私たちのほとんど、もしくは全員が、何を見るか探している時にNetflixのおすすめに引き込まれたり、次に何を買うか見るためにAmazonのおすすめセクションに直行したりしたことがあるでしょう。
この記事では、グラフデータベースを使用してリアルタイムのレコメンデーションエンジンを構築する方法について説明します。
レコメンデーションエンジンとは?
レコメンデーションエンジンは、高度なデータフィルタリングと予測分析を適用して、顧客のニーズや欲望、つまり顧客が消費したり関与したりする可能性があるコンテンツ、製品、またはサービスを予測するためのツールキットです。
これらのレコメンデーションを得るために、エンジンは以下の情報の組み合わせを使用します:
- 顧客の過去の行動と履歴、例えば購入した製品や視聴したシリーズ。
- 顧客の現在の行動と他の顧客との関係。
- 製品の顧客によるランキング。
- ビジネスのベストセラー。
- 類似または関連する顧客の行動と履歴。
グラフデータベースとは?
グラフデータベースは、データがテーブルや文書ではなくグラフ構造で格納されるNoSQLデータベースです。グラフデータ構造は、ノードと関係性によって接続されるノードで構成されます。ノードと関係性の両方には、それぞれのプロパティ(キーと値のペア)があり、さらに詳細に説明されています。
次の画像は、グラフデータ構造の基本的な概念を紹介しています:
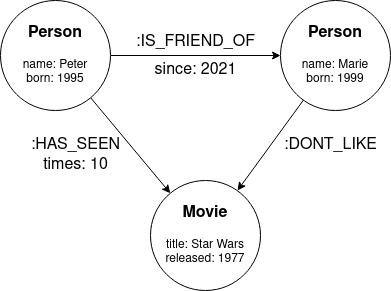
ストリーミングプラットフォーム向けのリアルタイムレコメンデーションエンジン
レコメンデーションエンジンとグラフデータベースの概要を知ったので、ストリーミングプラットフォーム向けにグラフデータベースを使用してレコメンデーションエンジンを構築する方法に入っていきましょう。
以下のグラフは、2人の顧客が視聴した映画と2人の顧客間の関係を格納しています。
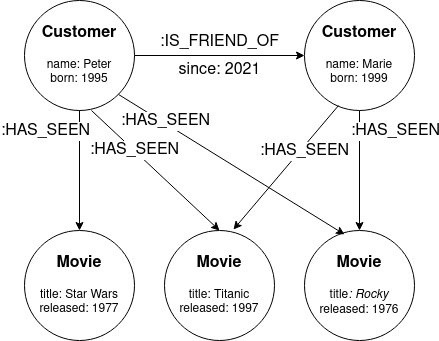
この情報をグラフとして格納した場合、次に視聴する映画に影響を与える映画のおすすめを考えることができます。最も視聴されている映画をプラットフォーム全体で表示するという最もシンプルな戦略があります。これはCypherクエリ言語を使用して簡単に行うことができます:
MATCH (:Customer)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5
しかし、このクエリは非常に一般的であり、顧客のコンテキストを考慮していないため、特定の顧客に最適化されていません。ソーシャルネットワークを使用してより良い結果を得ることができます。Cypherを使用すると非常に簡単です:
MATCH (customer:Customer {name:'Marie'})
<-[:IS_FRIEND_OF*1..2]-(friend:Customer)
WHERE customer <> friend
WITH DISTINCT friend
MATCH (friend)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5
このクエリにはWITH句によって2つのパートに分かれており、最初のパートの結果を2番目のパートにパイプすることができます。
クエリの最初のパートでは、現在の顧客({name: 'Marie'})を見つけ、グラフをトラバースしてマリーの直接の友達または友達(友達の友達)と一致させます。柔軟なパスの長さ表記法-[:IS_FRIEND_OF*1..2]->を使用しています。これは1つまたは2つのIS_FRIEND_OF関係まで深く探索することを意味します。
結果にマリー自身を含めないように注意しています(WHERE句)、また直接の友達でもあり友達の友達でもある重複した友達の友達を取得しないようにしています(DISTINCT句)。
クエリの後半は最も単純なクエリと同じですが、プラットフォーム上のすべての顧客を考慮する代わりに、マリーの友達と友達の友達を考慮しています。
それだけです、ストリーミングプラットフォームのリアルタイム推薦エンジンを作成しました。
まとめ
この記事では、以下のトピックが取り上げられました:
- リコメンデーションエンジンとその推薦に使用する情報の量。
- グラフデータベースと、データがテーブルやドキュメントではなくグラフとして保存される方法。
- グラフデータベースを使用してストリーミングプラットフォームのリアルタイム推薦エンジンを構築する方法の例。
ホセ・マリア・サンチェス・サラスはノルウェーに住んでいます。彼はスペインのムルシア出身のフリーランスデータエンジニアです。ビジネスと開発の世界の中で、彼はデータエンジニアリングのニュースレターも書いています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ヘイスタックの中の針を見つける – Jaccard類似度のための検索インデックス」 翻訳結果は以下の通りです: 「ヘイスタックの中の針を見つける – Jaccard類似度のための検索インデックス」
- 「プラットプス:データセットのキュレーションとアダプターによる大規模言語モデルの向上」
- 「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
- 「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
- 「正しい方法で新しいデータサイエンスのスキルを学ぶ」
- 「機械学習モデルが医学的診断と治療において不公平を増幅する方法」
- 「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
