ビジネスにおける機械学習オペレーションの構築
Building machine learning operations in business.
AI戦略を支援する効果的なMLOpsの設計図

背景 – MLOpsのナビゲーション
私のキャリアで、機械学習モデルを製品化する能力は、AI戦略の成功の鍵であることに気づきました。スケールで商業的な可能性を引き出すことができます。しかし、これは容易なことではありません。様々な技術の統合、チームの統合、そしてしばしば組織内の文化的な変革が必要となります。これをMLOpsと呼びます。
しかし、1つのMLOps戦略がすべてに適しているわけではありません。この記事では、柔軟なMLOps設計図を提供し、現在のワークフローを微調整するための出発点として利用できます。MLOpsの旅は複雑であるかもしれませんが、それをビジネスにAIを統合するための不可欠な初歩と見なすことを強くお勧めします。
MLOpsは技術以上のことをカバーする
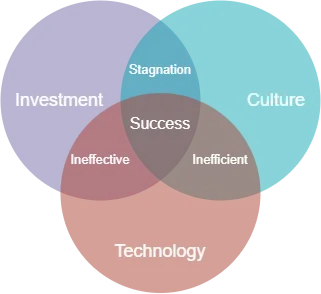
技術的な詳細に入る前に、私の経験から観察した様々なMLOps戦略に関する非技術的な洞察を共有したいと思います。MLOpsは単なる技術ではありません。投資、文化、技術の3つの要素にかかっています。最初からすべてを考慮した企業は、成功する傾向があります。一般的な誤りとして、文化的変革を必要とすることを考慮せずに、ソリューションへの投資を優先することが挙げられます。これは、予算を無駄にし、経営陣や投資家からの信頼を損なう可能性があるため、戦略を重大に損なう恐れがあります。
文化
任意のビジネスに新しい文化を導入することは容易なことではありません。ビジネスが古いツールを新しい輝かしいものに一方的に置き換えることを考慮せずに行う最も一般的な失敗の1つは、文化的変化を考慮しないことです。このアプローチは、不満を引き起こし、これらのツールが無視されたり、誤用されたりする原因となる可能性があります。
反対に、文化的変化を効果的に管理している企業は、エンドユーザーをMLOps戦略の策定に参加させ、彼らに所有権を促進する責任を割り当てています。さらに、これらのイニシアチブに関与することを報いるために、必要なサポートやトレーニングを提供して、ユーザーのスキルを向上させるよう配慮しています。
ソリューションが技術的に優れていても、文化的変化を促進しなければ、効果がない可能性があります。結局のところ、技術を操作するのは人間であるためです。
技術
簡潔にするために、技術を技術インフラストラクチャとデータ管理サービスの両方の組み合わせと定義しています。
効果的なMLOps戦略は、成熟したデータエコシステムの上に構築されます。データ管理ツールを活用することにより、データサイエンティストは、安全で規制に準拠した方法でモデル開発のためのデータにアクセスできるようになります。
技術インフラストラクチャの観点からは、データサイエンティストやMLエンジニアが必要なハードウェアやソフトウェアにアクセスし、AI製品の開発と提供を促進するために支援する必要があります。多くの企業にとって、クラウドインフラストラクチャを活用することは、この目的を達成するための不可欠な手段です。
投資
MLOpsにはショートカットはありません。特に投資に関しては、効率的なMLOps戦略は人と技術の両方に投資することを優先すべきです。クライアントとの繰り返し問題の1つは、予算制約のために1人のデータサイエンティストを中心にMLOps戦略を構築しようとする傾向があることです。この場合は、見直しを勧めるか、少なくとも期待値を抑えることをお勧めします。
最初から、革新への投資の範囲と期間を確立することが重要です。実際には、AIを業務の基盤にするために、そして関連する利益を得るためには、継続的な投資が不可欠です。
ビジネスのAI戦略の開発に関する見解については、Wardley Mapsを使用したAI戦略の作成に関する私の記事をお読みいただくことをお勧めします。
ビジネス向けのAI戦略の構築
ウォードレーマップを通じたAI戦略の作り方の秘訣
towardsdatascience.com
MLOpsのための高レベルブループリント
基礎を築いたところで、MLOpsのいくつかの技術的な要素について掘り下げてみましょう。可視化を助けるために、私はプロセス間の関係を示すフローチャートを設計しました。破線がある場合、データがフローします。実線がある場合、活動の移行があります。
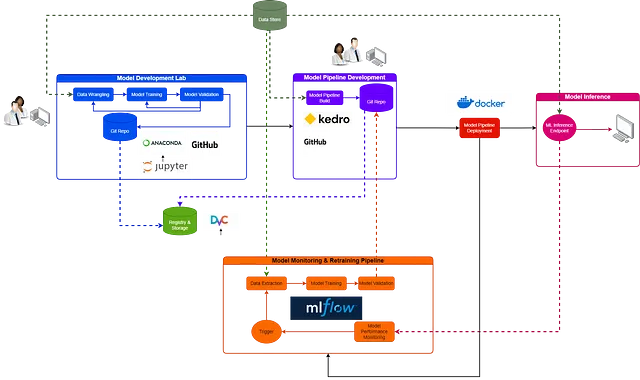
モデル開発ラボ
モデル開発のプロセスは不確実で反復的です。これに気付かない企業は、効果的なAI戦略の構築に苦労するでしょう。実際には、モデル開発はワークフローの中で最も混沌とした側面であり、実験、繰り返し、頻繁な失敗が詰まっています。これらすべての要素は、新しいソリューションを探求する上で不可欠であり、これがイノベーションの発源です。したがって、データサイエンティストが必要とするものは何でしょうか?実験、イノベーション、コラボレーションの自由です。
データサイエンティストは、コードの書き方でソフトウェアエンジニアリングのベストプラクティスに従うべきだという信念が広がっています。この感情には反対しませんが、すべてには時間と場所があります。モデル開発ラボは、このカオスを鎮めようとするのではなく、必要なワークフローの一部として受け入れ、それを管理するのに役立つツールを利用することが重要です。効果的なモデル開発ラボは、これを提供する必要があります。潜在的なコンポーネントを調べてみましょう。
実験とプロトタイピング—Jupyter Labs
Jupyter Labsは、プレリミナリーモデルやコンセプトの証明作成に適した多目的統合開発環境(IDE)を提供しています。ノートブック、スクリプト、コマンドラインインターフェースにアクセスできます。これらは、データサイエンティストにとってよく知られた機能です。
オープンソースツールとして、Jupyter LabsはPythonとRとのシームレスな統合を誇り、現代のデータサイエンスのモデル開発タスクの多くを包括しています。ほとんどのデータサイエンスのワークロードは、ラボIDEで実行できます。
環境管理—Anaconda
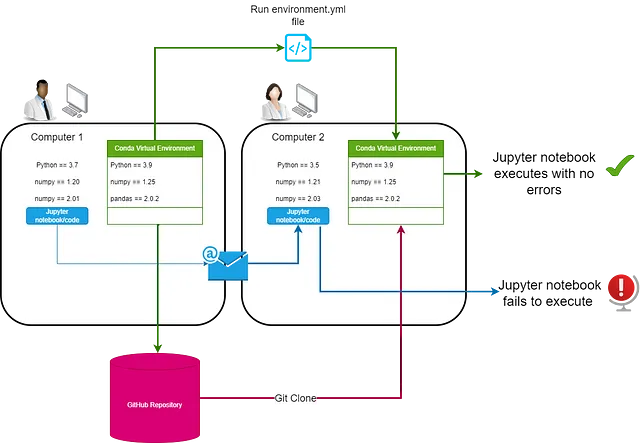
効果的な環境管理により、後続のMLOpsワークフローのステップを効率化し、オープンソースライブラリへの安全なアクセスと開発環境の再現に重点を置くことができます。Anacondaは、パッケージマネージャであり、データサイエンティストが仮想環境を作成し、簡単なコマンドラインインターフェース(CLI)で必要なライブラリとパッケージをインストールしてモデル開発を行うことができます。
Anacondaは、セキュアな商用利用のためのオープンソースパッケージを評価するリポジトリミラーリングも提供していますが、第三者管理の関連リスクは考慮する必要があります。仮想環境の使用は、実験フェーズの管理において重要であり、実験ごとにパッケージや依存関係を含むコンテナのような環境を提供します。
バージョンコントロールとコラボレーション—GitHub Desktop
コラボレーションは、成功したモデル開発ラボの重要な部分であり、GitHub Desktopを活用することは、効果的な方法です。データサイエンティストは、GitHub Desktopを通じて、各ラボのリポジトリを作成できます。各リポジトリには、モデル開発ノートブックまたはスクリプトと、環境.ymlファイルが含まれます。このファイルは、別のマシン上でノートブックが開発された環境をどのように再現するかをAnacondaに指示します。
Jupyter Labs、Anaconda、GitHubの3つのラボコンポーネントの組み合わせにより、データサイエンティストは、実験、イノベーション、コラボレーションを行う安全なスペースを提供されます。
#An example environment.yml file replicating a conda environmentname: myenvchannels: - conda-forgedependencies: - python=3.9 - pandas - scikit-learn - seabornモデルパイプラインの開発
私がMLOpsの成熟度が低いクライアントと議論する中で、データサイエンティストがモデルを開発してから機械学習エンジニアに「プロダクション化」を任せるという考えがあります。このアプローチはうまくいかず、機械学習エンジニアを失う最も早い方法かもしれません。誰も他人の乱雑なコードを扱いたくないし、正直言って、それをエンジニアに期待するのは不公平です。
代わりに、組織は、データサイエンティストがデータラボでモデルを開発し、エンドツーエンドのモデルパイプラインとして形式化する責任を持つ文化を育成する必要があります。これが理由です。
- データサイエンティストは他の誰よりも自分のモデルを理解しています。モデルパイプラインの作成に責任を持たせることで、効率が向上します。
- 開発の各段階でソフトウェアエンジニアリングのベストプラクティスの文化を確立します。
- 機械学習エンジニアは、他人のノートブックをリファクタリングする代わりに、リソースプロビジョニング、スケーリング、自動化など、価値を追加する仕事に集中できます。
エンドツーエンドのパイプラインの構築は最初は困難に見えるかもしれませんが、幸いにも、データサイエンティスト向けのツールがあります。
モデルパイプラインビルド-Kedro
Kedroは、データサイエンティストがモデルパイプラインを構築するのを支援するMcKinsey Quantum BlackのPythonオープンソースフレームワークです。
# Kedro projetcsの標準テンプレート{{ cookiecutter.repo_name }} # テンプレートの親ディレクトリ├── conf # プロジェクト構成ファイル├── data # ローカルプロジェクトデータ├── docs # プロジェクトのドキュメント├── notebooks # プロジェクト関連のJupyterノートブック├── README.md # プロジェクトREADME├── setup.cfg # ツールの構成オプション └── src # プロジェクトのソースコード └── {{ cookiecutter.python_package }} ├── __init.py__ ├── pipelines ├── pipeline_registry.py ├── __main__.py └── settings.py ├── requirements.txt ├── setup.py └── testsKedroは、ソフトウェアエンジニアリングのベストプラクティスを備えたエンドツーエンドのモデルパイプラインを構築するための標準テンプレートを提供します。その背後にあるコンセプトは、データサイエンティストがモジュール化、再現性、保守性の高いコードを構築することを促進することです。データサイエンティストがKedroワークフローを完了すると、本質的には、より簡単にプロダクション環境に展開できるものを構築したことになります。以下は、包括的なコンセプトです。
- プロジェクトテンプレート:Kedroは、構造、協力、効率を高める標準的で使いやすいプロジェクトテンプレートを提供します。
- データカタログ:Kedroのデータカタログは、プロジェクトが使用できるすべてのデータソースのレジストリです。データがどのように、どこに保存されるかを定義する簡単な方法を提供します。
https://docs.kedro.org/en/0.18.1/faq/faq.htmlから取得したKedroプロジェクトによるデータエンジニアリングカタログ
- パイプライン:Kedroは、依存するタスクのパイプラインとしてデータ処理を構造化し、明確なコード構造を強制し、データフローと依存関係を可視化します。
- ノード:Kedroでは、ノードは、Python関数のラッパーであり、その関数の入力と出力を名前付けて、Kedroパイプラインの構築ブロックとして機能します。
- 構成:Kedroは、コードに任意の構成をハードコードすることなく、さまざまな環境(開発、プロダクションなど)用の異なる構成を管理します。
- I/O:Kedroでは、I/O操作は、実際の計算から抽象化されており、コードのテスト性とモジュラリティが向上し、さまざまなデータソース間の切り替えが容易になります。
- モジュラリティと再利用性:Kedroは、再利用可能で、保守性が高く、テスト可能なコードを生み出すモジュラーコーディングスタイルを促進します。
- テスト:Kedroは、PythonのテストフレームワークであるPyTestと統合されており、パイプラインのテストを簡単に書くことができます。
- バージョン管理:Kedroは、データとコードのバージョン管理をサポートし、パイプラインの以前の状態を再現することができます。
- ログ記録:Kedroは、イベントと変更を追跡するための標準化されたログシステムを提供します。
- フックとプラグイン:Kedroは、フックとプラグインをサポートし、プロジェクト要件に応じてフレームワークの機能を拡張します。
- 他のツールとの統合:Kedroは、Jupyterノートブック、Dask、Apache Sparkなど、データサイエンスワークフローのさまざまな側面を容易にするために、さまざまなツールと統合できます。
すべてのKedroプロジェクトはこの基本テンプレートに従います。データサイエンスチーム全体でこの標準を実施することで、再現性と保守性を確保できます。
Kedroフレームワークのより詳細な概要については、以下のリソースをご覧ください。
- Kedroドキュメント:リンク
- データエンジニアリングにおける階層思考の重要性:リンク
レジストリとストレージ — データバージョン管理(DVC)
再現性を実現するには、機械学習におけるレジストリとストレージが重要です。MLモデルは、基本的にはコード、データ、モデルアーティファクト、環境から構成されています。再現性を確保するためには、これらすべてを追跡する必要があります。
DVCは、モデルとデータのバージョン管理とトラッキングを提供するツールです。GitHubは代替手段となり得ますが、大規模なデータセットやモデルに対しては容量制限があり、問題が発生する可能性があります。DVCはGitを拡張し、同じバージョン管理機能を提供すると同時に、ローカルまたはクラウドベースのDVCリポジトリに大規模なデータセットとモデルを保存できるようにします。
商用環境では、Gitリポジトリにコードのバージョンを管理し、実際のモデルアーティファクトとデータをコントロールされた環境に別々に保存することに明らかなセキュリティ上のメリットがあります。
AIの商用利用における規制が強化されるにつれて、モデルの再現性がますます重要になっていきます。再現性は監査可能性を促進します。
モデルパイプラインデプロイメント — Docker
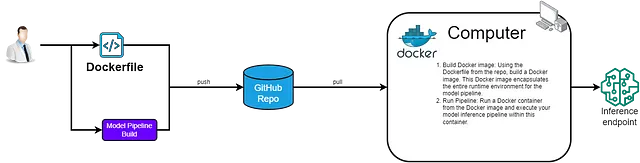
デプロイメントは単なる単一のタスクではなく、ツール、アクティビティ、プロセスを緻密に組み合わせたものであり、モデルデプロイメントにおいてこれらをすべて結びつけるのがDockerです。多数の依存関係を持つ複雑なMLアプリケーションにとって不可欠なDockerは、アプリケーションを環境とともにカプセル化することで、あらゆるマシンでの一貫性を保証します。
Dockerfileから始め、Dockerはコマンドを使用してイメージを構築し、Dockerで動作する準備ができたモデルパイプラインを提供します。Kedroのパイプライン機能と組み合わせることで、Dockerはモデルの再学習パイプラインと推論パイプラインの両方を効率的に展開し、MLワークフローのすべての段階で再現性を保証します。
モデルモニタリングと再学習パイプライン — MLflow
時間の経過とともに、機械学習モデルは性能の低下が発生することがあります。これは概念ドリフトやデータドリフトによるものです。モデルの性能が低下し始めた時点でモニタリングし、必要に応じて再学習することができるようにするために、MLflowはトラッキングAPIを提供します。トラッキングAPIは、データサイエンティストが構築したモデルトレーニングおよび推論パイプラインに組み込む必要があります。モデルモニタリングと再学習パイプラインにおけるトラッキングにMLflowを指定しましたが、実験トラッキングに関してはモデル開発ラボでも実行できます。
推論エンドポイント
推論パイプラインがDockerfileにカプセル化されたため、どこでも推論エンドポイントとして使用できるようにDockerイメージを作成できます。使用ケースに応じて、Dockerイメージをどこにデプロイするかを決定する必要がありますが、それはこの記事の範囲を超えています。
役割と責任
MLOpsにおいては、明確な役割分担が成功の鍵となります。多岐にわたるMLOpsの性質については、各タスクを効率的に実行するために明確な役割分担が必要です。これにより、問題の迅速な解決を促進することができます。さらに、明確な割り当ては混乱や重複を減らし、チームをより効率的にし、調和のとれた作業環境を維持するのに役立ちます。各歯車が完璧に機能するようになっているようなものです。
データサイエンティスト
- 役割:MLOps戦略におけるデータサイエンティストの主な役割は、モデル開発に集中することです。これには、初期実験、プロトタイピング、検証済みモデルのモデリングパイプラインの設定が含まれます。
- 責任:データサイエンティストは、機械学習のベストプラクティスに則り、ビジネスケースと一致するようにモデルを確認します。ラボのタスクを超えて、ビジネスステークホルダーと協力して、影響力のあるソリューションを特定します。リードデータサイエンティストは、ラボのオペレーティングリズムと設定のベストプラクティスを設定する責任を持ちます。
機械学習エンジニア
- 役割:MLエンジニアは、技術的インフラを監視し、データサイエンティストと共に戦略を策定し、プロセスの効率性を高める革新的なソリューションを探索します。
- 責任:技術的インフラの機能性を確保し、コストを抑制するためにコンポーネントのパフォーマンスを監視し、生産モデルが必要なスケールで需要を満たすことを確認します。
データガバナンスの専門家
- 役割:データガバナンスの専門家は、セキュリティとデータプライバシーのポリシーを維持し、MLOpsフレームワーク内でのデータの安全な転送に重要な役割を果たします。
- 責任:データガバナンスは誰の責任であるとされますが、これらの専門家はポリシーを作成し、定期的なチェックや監査によるコンプライアンスを確認します。彼らは規制に追いつき、すべてのデータ消費者からのコンプライアンスを確保します。
結論
MLOpsの領域を航海するには、綿密な計画、適切な技術と人材の組み合わせ、変化と学習を支持する組織文化が必要です。
旅は複雑に見えるかもしれませんが、よく設計されたブループリントを採用し、一回限りのプロジェクトではなく、ホリスティックで反復的なプロセスとしてMLOpsに取り組むことで、AI戦略から膨大な価値を得ることができます。ただし、すべてのシナリオに単一のアプローチが適用されるわけではありません。戦略を特定のニーズに合わせて調整し、変化する状況に対してアジャイルに対応することが重要です。
LinkedInで私をフォローしてください
私からのより多くの洞察を得るために、VoAGIに登録してください:
私の紹介リンクでVoAGIに参加する – John Adeojo
私はデータサイエンスのプロジェクト、経験、専門知識を共有し、あなたの旅を支援します。あなたは…を通じてVoAGIにサインアップすることができます。
johnadeojo.medium.com
あなたのビジネスオペレーションにAIまたはデータサイエンスを統合することに興味がある場合は、無料の初回相談をスケジュールするようにお招きします:
オンライン予約 | データセントリックソリューション
無料相談でビジネスが野心的な目標を達成するための私たちの専門知識を発見してください。私たちのデータサイエンティストと…
www.data-centric-solutions.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
