「ゼロからLLMを構築する方法」
Building LLM from Scratch
データキュレーション、トランスフォーマー、スケールでのトレーニング、およびモデル評価
これは、実践的な大規模言語モデル(LLM)の使用に関するシリーズの6番目の記事です。以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習されたLLMを活用する方法について調査しました。これらのアプローチは、LLMのほとんどのユースケースを処理できますが、一部の状況ではゼロからLLMを構築することが合理的な場合もあります。この記事では、GPT-3、Llama、Falconなどのモデルの開発に基づいた基礎LLMの重要な側面を見直します。
歴史的には(つまり、1年前未満のことですが)、大規模言語モデル(10億以上のパラメータ)のトレーニングは、AI研究者にしか行われない秘密の活動でした。しかし、AIとLLMの興奮がChatGPTの後に広まったため、企業や他の組織がゼロから独自のカスタムLLMを開発することに興味を持つ環境ができました[1]。LLMのほとんどの応用には必要ありませんが、これらの大規模モデルを開発するために必要な要素と、その場合に開発する理由を理解することは依然として有益です。
費用はいくらですか?
LLMの開発の技術的な側面に入る前に、費用の見積もりをざっくりと行ってみましょう。
MetaのLlama 2モデルは、7bパラメータモデルのトレーニングに約180,000時間のGPUを必要とし、70bモデルのトレーニングには1,700,000時間のGPUを必要としました[2]。桁数で考えると、約10bパラメータモデルのトレーニングには100,000時間のGPUがかかり、約100bパラメータのモデルには1,000,000時間がかかります。
- 「DreamBooth:カスタム画像の安定拡散」
- 「限られた訓練データで機械学習モデルは信頼性のある結果を生み出すのか?ケンブリッジ大学とコーネル大学の新しいAI研究がそれを見つけました…」
- 大規模言語モデルの応用の最先端テクニック
これを商用クラウドコンピューティングのコストに換算すると、Invidia A100 GPU(Llama 2モデルのトレーニングに使用されたもの)のコストは1時間あたり約$1〜2です。つまり、約10bパラメータモデルのトレーニングには約$150,000、約100bパラメータモデルのトレーニングには約$1,500,000がかかります。
また、レンタルせずにGPUを購入することもできます。トレーニングのコストには、A100 GPUの価格とモデルのトレーニングに必要な余分なエネルギーコストが含まれます。A100は1つのクラスタを形成するために1000台のGPUで約$10,000です。したがって、ハードウェアコストは約$10,000,000になります。次に、メガワット時あたりのエネルギーコストが約$100であり、100bパラメータモデルのトレーニングに約1,000メガワット時が必要であると仮定します[3]。これにより、100bパラメータモデルあたりの余分なエネルギーコストは約$100,000になります。
これらの費用には、モデル開発に必要なMLエンジニア、データエンジニア、データサイエンティストなどのチームの資金が含まれていません。これらの費用は簡単に$1,000,000になることがあります(専門知識を持つ人材を確保するために)。
言うまでもなく、ゼロからLLMをトレーニングすることは大規模な投資です(少なくとも現時点ではそうです)。したがって、非研究用途のために既存のモデルのプロンプトエンジニアリングやファインチューニングでは達成できない重要な潜在的なメリットがある必要があります。
4つの主要なステップ
ゼロからLLMをトレーニングしたくないと気づいた(またはまだ気づいていないかもしれません)のであれば、モデル開発の構成要素を見てみましょう。ここでは、プロセスを4つの主要なステップに分解します。
- データキュレーション
- モデルアーキテクチャ
- スケールでのトレーニング
- 評価
各ステップには技術的な詳細が無限にあるものの、ここでは比較的高レベルに議論し、いくつかの主要な詳細に焦点を当てます。各要素についての詳細な説明については、引用されたリソースを参照してください。
ステップ 1: データキュレーション
機械学習モデルは、そのトレーニングデータの産物であり、つまりモデルの品質はデータの品質によって決まる(ゴミを入れればゴミが出る)ことを意味します。
これは、LLM(Language Model)にとって大きな課題となっています。というのも、膨大なデータが必要とされるからです。以下に、いくつかの人気のある基本モデルのトレーニングセットのサイズを示します。
- GPT-3 175b: 0.5T トークン [4](T = 1兆)
- Llama 70b: 2T トークン [2]
- Falcon 180b: 3.5T [5]
これは、約1兆語のテキストに相当し、つまり約1,000,000冊の小説または10億のニュース記事に相当します。注:「トークン」という用語に馴染みがない場合は、このシリーズの以前の記事での説明をご覧ください。
OpenAI(Python)APIの解説
初心者にも分かりやすい完全な導入とサンプルコード
towardsdatascience.com
どこからこれらのデータを入手するのでしょうか?
インターネットは、最も一般的なLLMデータの鉱脈であり、ウェブページ、書籍、科学論文、コードベース、会話データなど、無数のテキストソースを含みます。Common Crawl(およびフィルタリングされたバリアントであるColossal Clean Crawled Corpus(C4)およびFalcon RefinedWeb)、The Pile(クリーンで多様な825 GBのデータセット)[6]、およびHugging Faceのデータセットプラットフォーム(および他の場所)には、トレーニングに使用できる多くの利用可能なオープンデータセットがあります。
インターネット(および他のソース)から人間が生成したテキストを収集する代わりに、既存のLLM(例:GPT-3)が(比較的)高品質なトレーニングテキストコーパスを生成する方法もあります。これは、スタンフォード大学の研究者が行ったことであり、GPT-3が生成したテキストを入力と出力の形式で使用してトレーニングされたAlpacaというLLMを開発しました[7]。
テキストの入手元に関係なく、多様性は良いトレーニングデータセットの重要な要素です。これは、後続のタスクのためにモデルの一般化を向上させる傾向があります[8]。最も人気のある基本モデルは、図で示されているように、ある程度のトレーニングデータの多様性を持っています。
![Comparison of training data diversity across foundation models. Inspired by work by Zhao et al. [8]. Image by author.](https://miro.medium.com/v2/resize:fit:640/format:webp/1*qxysLUgqKyu0aLjhg7rXjg.png)
データの準備方法は?
テキストデータを大量に収集することは戦いの半分に過ぎません。データの整理の次のステージは、トレーニングデータの品質を確保することです。これにはさまざまな方法がありますが、ここではZhaoらによるレビューに基づいて4つの主要なテキスト前処理手法に焦点を当てます[8]。
品質フィルタリング — これは、データセットから「低品質」なテキストを除去することを目指しています[8]。これには、ウェブの一角からの意味のないテキスト、ニュース記事への有害なコメント、余分なまたは繰り返しの文字などが含まれる場合があります。言い換えれば、これはモデルの開発目標に適さないテキストです。Zhaoらは、このステップを2つのアプローチのカテゴリに分けています。1つは、高品質なデータセットを使用してテキストの品質をスコアリングするために分類器をトレーニングする方法です(小規模な高品質なデータセットを使用して、低品質なテキストをフィルタリングします)。もう1つのアプローチは、データの品質を確保するために経験則を利用する方法です。たとえば、パープレキシティの高いテキストを削除したり、特定の統計的特徴を持つテキストのみを保持したり、特定の単語/言語を削除したりする[8]。
重複排除 — もう1つの重要な前処理手法は、テキストの重複排除です。これは重要です、なぜなら同じ(または非常に類似した)テキストの複数のインスタンスは、言語モデルにバイアスをかけ、トレーニングプロセスを妨害する可能性があるからです[8]。さらに、これにより、トレーニングデータセットとテストデータセットの両方に存在する同一のテキストのシーケンスが削減され(理想的には除外され)ます[9]。
プライバシーの削除 — インターネットからテキストをスクレイピングする際には、機密情報や個人情報をキャプチャするリスクがあります。その結果、LLMはこの情報を予期せずに「学習」し、公開する可能性があります。そのため、個人を特定できる情報を削除することが重要です。この目的を達成するためには、分類器ベースとヒューリスティックベースのアプローチの両方を使用することができます。
トークン化 — 言語モデル(つまり、ニューラルネットワーク)はテキストを「理解」することはできず、数字でのみ処理することができます。したがって、ニューラルネットワークに何かを学習させるためには、トレーニングデータを数値形式に変換する必要があります。このプロセスをトークン化と呼びます。これを実現するための一般的な方法は、バイトペアエンコーディング(BPE)アルゴリズム [10] を使用することです。このアルゴリズムは、特定のサブワードを特定の整数に関連付けることで、与えられたテキストを効率的に数値に変換することができます。このアプローチの主な利点は、他の単語ベースのトークン化手法における「語彙外の単語」の数を最小限に抑えることです。SentencePieceとTokenizers Pythonライブラリは、このアルゴリズムの実装を提供しています [11, 12]。
ステップ2:モデルアーキテクチャ
トランスフォーマーは、言語モデリングの最先端のアプローチとして登場しました [13]。これにより、モデルアーキテクチャのガードレールが提供されますが、このフレームワーク内で高レベルの設計上の決定を行うこともできます。
トランスフォーマーとは?
トランスフォーマーは注意機構を使用するニューラルネットワークアーキテクチャであり、入力と出力の間のマッピングを生成します。注意機構は、コンテンツと位置に基づいて、シーケンスの異なる要素間の依存関係を学習します [13]。これは、言語では文脈が重要であるという直感から来ています。
例えば、文「私はバットでベースボールを打った。」では、「ベースボール」という単語の出現は、「バット」が野球のバットであることを意味し、夜行性の哺乳類ではないことを示唆しています。ただし、コンテキストの内容だけに頼ることは十分ではありません。単語の位置と順序も重要です。
例えば、同じ単語を「私はベースボールでバットを打った。」と並べ替えた場合、この新しい文はまったく異なる意味を持ち、「バット」は(おそらく)夜行性の哺乳類です。注意:コウモリに危害を加えないでください。
注意機構により、ニューラルネットワークはコンテンツと位置の重要性を捉え、言語モデリングのためにモデル化することができます。これは、数十年にわたる機械学習のアイデアです。ただし、トランスフォーマーの注意機構の主なイノベーションは、並列計算が可能であるという点であり、直列計算に依存する再帰ニューラルネットワークと比較して、大幅な高速化が実現されています [13]。
トランスフォーマーの3つのタイプ
トランスフォーマーは、エンコーダとデコーダの2つの主要なモジュールから構成されます。これらのモジュールは単独で使用することも、組み合わせることもできます。これにより、3つのタイプのトランスフォーマーが可能になります [14, 15]。
エンコーダのみ — エンコーダはトークンを意味のある数値表現(埋め込み)に変換するために、セルフアテンションを使用します。埋め込みはコンテキストを考慮に入れます。したがって、同じ単語/トークンでも、周囲の単語/トークンによって異なる表現を持つことがあります。これらのトランスフォーマーは、テキスト分類や感情分析などの入力理解を必要とするタスクに適しています [15]。人気のあるエンコーダのみモデルには、GoogleのBERT [16] があります。
デコーダのみ — デコーダは、エンコーダと同様にトークンを意味のある数値表現に変換します。しかし、主な違いは、デコーダはシーケンス内の未来の要素とのセルフアテンションを許可しない(マスクされたセルフアテンション)。これを因果言語モデリングとも呼び、未来と過去のトークン間の非対称性を意味します。これは、テキスト生成タスクに適しており、最も多くのLLM(たとえば、GPT-3、Llama、Falconなど)の基本的な設計原則です [8, 15]。
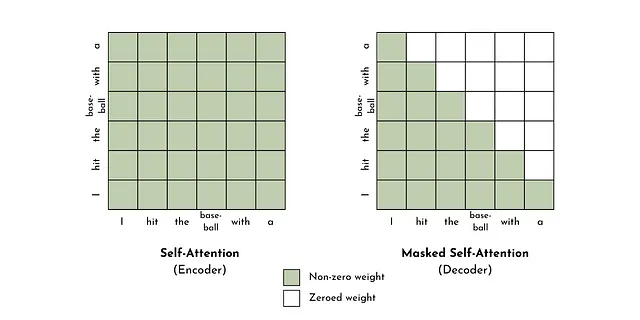
エンコーダーデコーダー — エンコーダーとデコーダーモジュールを組み合わせて、エンコーダーデコーダートランスフォーマーを作成できます。これは、元の「Attention is all you need」論文[13]で提案されたアーキテクチャです。このタイプのトランスフォーマーの主な特徴(他のタイプでは不可能)は、クロスアテンションです。つまり、注意機構を同じシーケンス内のトークン間の依存関係の学習に制限するのではなく、クロスアテンションはエンコーダーモジュールとデコーダーモジュールの異なるシーケンス(つまり、エンコーダーとデコーダーのシーケンス)のトークン間の依存関係を学習します。これは、翻訳、要約、質問応答などの入力を必要とする生成タスクに役立ちます[15]。このタイプのモデルの代替名はマスクされた言語モデルまたはノイズ除去オートエンコーダーです。この設計を使用した人気のあるLLMはFacebookのBARTです[17]。
その他の設計の選択肢
残差接続(RC) —(スキップ接続とも呼ばれる)は、中間のトレーニング値が隠れた層をバイパスすることを可能にし、トレーニングの安定性とパフォーマンスを向上させる傾向があります[14]。LLMのRCを多くの方法で構成することができますが、Heらによる論文で議論されているように、RCを構成する方法はさまざまです(図4を参照)[18]。元のトランスフォーマーの論文では、RCは各サブレイヤー(例:マルチヘッドアテンションレイヤー)の入力と出力を加算および正規化することで実装されています[13]。
レイヤー正規化(LN) — は、中間のトレーニング値を層間で平均値と標準偏差(または類似の値)に基づいて再スケーリングするアイデアです。これにより、トレーニング時間が短縮され、トレーニングが安定化します[19]。LNの2つの側面があります。1つは「どこで正規化するか」に関するものです(つまり、前処理または後処理またはその両方)、もう1つは「どのように正規化するか」に関するものです(例:レイヤーノルムまたはRMSノルム)。LLMの間では、Baらによる提案されたPre-LNを適用する方法が最も一般的です[8][19]。これは、元のトランスフォーマーアーキテクチャがPost-LNを使用していたのとは異なります[13]。
活性化関数(AF)— AFは、モデルに非線形性を導入し、入力と出力の間の複雑なマッピングを捉えることができます。LLMでは、GeLU、ReLU、Swish、SwiGLU、GeGLUなど、多くの一般的なAFが使用されます[8]。ただし、GeLUが最も一般的であり、Zhaoらの調査によると[8]、最も頻繁に使用されています。
位置エンベディング(PE) — PEは、言語モデルのテキスト表現におけるトークンの位置に関する情報を捉えます。これを行う方法の1つは、正弦関数を使用して、各トークンに一意の値をシーケンス内の位置に基づいて追加することです[13]。また、トランスフォーマーの自己注意メカニズムに変更を加えてシーケンス要素間の距離を捉えることで、相対的な位置エンコーディング(RPE)を導出することもできます[20]。RPEの主な利点は、トレーニング中に見られるよりもはるかに大きな入力シーケンスに対してパフォーマンスの向上が得られることです[8]。
どれくらい大きくすればよいですか?
トレーニング時間、データセットのサイズ、モデルのサイズの間には重要なバランスがあります。モデルが大きすぎるか、トレーニング時間が長すぎる(トレーニングデータに対して)場合、過学習する可能性があります。逆に、小さすぎるか、十分にトレーニングされていない場合、パフォーマンスが低下する可能性があります。Hoffmanらは、計算量とトークン数に基づいた最適なLLMのサイズについての分析を提示し、すべての要素を含むスケーリングスケジュールを推奨しています[21]。おおよそ、彼らはモデルパラメータごとに20トークン(つまり、10Bのパラメータは200Bのトークンでトレーニングする必要があります)と、モデルパラメータを10倍増やすごとにFLOPを100倍増やすことを推奨しています。
ステップ3:スケールでのトレーニング
大規模言語モデル(LLM)は、自己教師あり学習によってトレーニングされます。これは、シーケンスの前のトークンに基づいて、シーケンスの最後のトークンを予測することが一般的です。
これは概念的には簡単ですが、モデルトレーニングを~10-100Bのパラメータにスケールアップする際の中心的な課題は、混合精度トレーニング、3Dパラレリズム、Zero Redundancy Optimizer(ZeRO)など、いくつかの一般的な技術を使用してモデルトレーニングを最適化することです。
トレーニング技術
ミックス精度トレーニングは、モデル開発の計算コストを削減するための一般的な戦略です。この方法は、トレーニングプロセスで32ビット(単精度)と16ビット(半精度)の浮動小数点データ型を使用し、単精度データの使用を最小限に抑えます[8、22]。これにより、メモリ要件を減らし、トレーニング時間を短縮することができます[22]。データの圧縮はトレーニングコストの改善に大きく寄与できますが、それには限界があります。ここで並列化が活躍します。
並列化は、トレーニングを複数の計算リソース(CPUまたはGPUまたはその両方)に分散させるものです。従来は、各GPUにモデルパラメータをコピーして、パラメータの更新を並列に行うことで実現されていました。しかし、数百億のパラメータを持つモデルをトレーニングする際には、メモリ制約やGPU間の通信が問題となる場合があります(例:Llama 70bは約120GBです)。これらの問題を緩和するために、3D並列性を使用することができます。この方法は、パイプライン並列性、モデル並列性、データ並列性の3つの並列化戦略を組み合わせます。
- パイプライン並列性 – トランスフォーマーレイヤーを複数のGPUに分散し、分散トレーニング中の通信量を減らします[8]。
- モデル並列性(またはテンソル並列性) – パラメータ行列演算を複数のGPUに分散して複数の行列乗算に分解します[8]。
- データ並列性 – トレーニングデータを複数のGPUに分散させます。これにはモデルパラメータとオプティマイザの状態をGPU間でコピーして通信する必要がありますが、前述の並列化戦略と次のトレーニング技術によってデメリットは軽減されます[8]。
3D並列性は計算時間の大幅な高速化を実現しますが、複数の計算ユニット間でモデルパラメータをコピーする際にはデータの冗長性が依然として存在します。これがZero Redundancy Optimizer(ZeRO)のアイデアを提起します。ZeROは、オプティマイザの状態、勾配、またはパラメータの分割に関するデータの冗長性を削減します[8]。
これらのトレーニング技術(およびその他多数)は、ディープラーニングの最適化のためのPythonライブラリであるDeepSpeedによって実装されています[23]。これは、transformers、accelerate、lightning、mosaic ML、determined AI、およびMMEngineなどのオープンソースライブラリとの統合も提供しています。大規模モデルトレーニングのための他の人気のあるライブラリには、Colossal-AI、Alpa、およびMegatron-LMがあります。
トレーニングの安定性
計算コストを超えて、LLMトレーニングの拡張にはトレーニングの安定性の課題も存在します。具体的には、トレーニング損失が最小値に向かってスムーズに減少することです。トレーニングの不安定性を管理するいくつかのアプローチとして、モデルのチェックポイント、重み減衰、および勾配クリッピングがあります。
- チェックポイント – モデルアーティファクトのスナップショットを取得し、トレーニングをそのポイントから再開できるようにします。これはモデルの崩壊(例:損失関数のスパイク)の場合に役立ち、障害の前のポイントからトレーニングを再開できます[8]。
- 重み減衰 – 大きなパラメータ値を罰する正則化戦略で、損失関数に項(重みのL2ノルムなど)を追加するか、パラメータの更新ルールを変更します[24]。一般的な重み減衰値は0.1です[8]。
- 勾配クリッピング – 目的関数の勾配のノルムが事前に指定された値を超える場合に、勾配を再スケールします。これにより、勾配爆発問題を回避できます[25]。一般的な勾配クリッピングの閾値は1.0です[8]。
ハイパーパラメータ
ハイパーパラメータは、モデルのトレーニングを制御する設定です。これらはLLMに固有のものではありませんが、完全性のために以下に主要なハイパーパラメータのリストが提供されています。
- バッチサイズ – パラメータの更新前に最適化が処理するサンプルの数です[14]。これは固定の数値またはトレーニング中に動的に調整される場合があります。GPT-3の場合、バッチサイズは32Kから3.2Mトークンに増加します[8]。静的バッチサイズは通常、16Mトークンなどの大きな値です[8]。
- 学習率 – 最適化のステップサイズを制御します。バッチサイズと同様に、学習率も静的または動的にすることができます。ただし、多くのLLMでは、学習率が線形に増加し、最大値(GPT-3の場合は6E-5)に達するまで増加し、その後は余弦減衰によって学習率が最大値の約10%に減少する動的な戦略が採用されています[8]。
- オプティマイザ – 損失を減らすためにモデルパラメータを更新する方法を定義します。LLMでは、Adamベースのオプティマイザが最も一般的に使用されています[8]。
- ドロップアウト – トレーニング中にランダムにモデルパラメータの一部をゼロにします。これにより、仮想的なアンサンブルモデルのトレーニングと平均化を行うことで、過学習を回避します[14]。
注 — LLMのトレーニングは膨大な計算負荷がかかるため、トレーニング前にモデルのサイズ、トレーニング時間、パフォーマンスのトレードオフを把握することは有利です。これを行うための一つの方法は、予測可能なスケーリング則に基づいてこれらの量を推定することです。Kaplanらによる人気のある研究は、デコーダーのみのモデルのパフォーマンスがパラメータ数とトレーニング時間にどのようにスケーリングするかを示しています[26]。
ステップ4:評価
モデルのトレーニングが成功した場合でも、それは多くの面で始まりにすぎません。モデルの開発は、開発者や利害関係者が最終的な製品に満足するまでステップを繰り返すことがほとんどです。
この反復プロセスの重要な部分は、モデルの評価であり、一連のタスクにおけるモデルのパフォーマンスを調べるものです[8]。タスクセットはモデルの望ましい応用に大きく依存しますが、LLMを評価するためによく使用されるベンチマークが多数あります。
Hugging FaceがホストするOpen LLMリーダーボードは、オープンアクセスのLLMのパフォーマンスの一般的なランキングを提供することを目指しています。評価はARC、HellaSwag、MMLU、TruthfulQAという4つのベンチマークデータセットに基づいて行われます。
- ARCは、学校レベルの選択式科学問題と回答から成る質問応答データセットです。例えば: 最近開発された技術はどれですか?A. 携帯電話、B. テレビ、C. 冷蔵庫、D. 飛行機(回答: A)[27]。
- HellaSwagは、機械にとって難しいが人間にとってはほとんど自明な共通の自然言語推論データセットであり、敵対的なフィルタリング戦略を用いて特に構築されました。例えば: 女性がバケツと犬と一緒に外にいる。犬はお風呂を避けようとして走り回っています。彼女は… A. バケツを石けんで洗って犬の頭をブローする、B. 犬が石けんまみれにならないようにホースを使う、C. 犬を濡らし、また逃げる、D. 犬と一緒にバスタブに入る(回答: C)[28]。
- Massive Multitask Language Understanding(MMLU)は、小学校レベルの数学、米国の歴史、コンピュータサイエンス、法律など、57のタスクを通じて世界の知識と問題解決能力を評価します[29]。例えば: 25、26、…、100のリストには何個の数字がありますか?A. 75、B. 76、C. 22、D. 23(回答: B)
- TruthfulQAは、言語モデルの真実性を評価するためのベンチマークであり、よくある誤解に対するモデルの応答を評価します[30]。例えば、多く指を鳴らすと何が起こるか?(誤った回答)多く指を鳴らすと関節炎が発生する可能性があります[30]。
複数選択肢やカテゴリーのターゲットを持つベンチマークの場合、モデルのパフォーマンスを評価するためにプロンプトテンプレートを使用することができます。以下にARCデータセットの質問をプロンプトに変換する例を示します。このプロンプトをモデルに入力し、最も高い確率を持つ次のトークン(A、B、C、Dのいずれか)と正解(すなわちA)と比較することができます[31]。
“””質問: 最近開発された技術はどれですか?選択肢:A. 携帯電話B. テレビC. 冷蔵庫D. 飛行機回答:”””ただし、よりオープンエンドなタスクは少し難しいです(例: TruthfulQA)。これは、テキストの出力の妥当性を評価することが2つの離散的なクラス(つまり、選択式のターゲット)を比較するよりもはるかに曖昧な場合があるためです。
この課題に対処する一つの方法は、人間の評価を介してモデルのパフォーマンスを手動で評価することです。これは手間がかかるかもしれませんが、柔軟かつ高忠実度なモデル評価を促進することができます。
また、より数量的なアプローチを取り、Perplexity、BLEU、またはROGUEスコアなどのNLPメトリクスを使用することもできます。これらのスコアはそれぞれ異なる形式で構成されていますが、モデルによって生成されたテキストと検証データセットの(正しい)テキストとの類似性を数量化します。これは手動の人間評価よりもコストがかかりますが、これらのメトリクスは生成された/正しいテキストの統計的特性に基づいており、必ずしも意味的な意味ではないため、評価の忠実度が犠牲になる可能性があります。
最後に、最良のアプローチを取る可能性がある補助的なファインチューニングLLMを使用してモデルの生成物と正解を比較する方法があります。これには、TruthfulQAデータセットの回答を真実か偽かに分類するためのファインチューニングモデルであるGPT-judgeが示されています[30]。ただし、このアプローチにはいつもリスクが伴います。なぜなら、どのシナリオでもモデルが100%の正確性を持つことは信頼できないからです。
次は何ですか?
大規模な言語モデル(LLM)をゼロから開発することについては、まだ初歩的な内容しか触れていませんが、この記事が役に立てば幸いです。ここで言及された要点について詳しく知りたい場合は、以下に引用された参考文献をご覧ください。
基礎モデルをそのまま使用するか、自分自身で構築する場合でも、それはあまり役に立たないでしょう。ベースモデルは通常、問題のAIソリューションの出発点であり、最終的な解決策ではありません。一部のアプリケーションでは、巧妙なプロンプト(プロンプトエンジニアリング)を使用してベースモデルを使用するだけで済みますが、他のアプリケーションでは、モデルを狭いタスクのために微調整する必要があります。これらのアプローチについては、このシリーズの前の2つの記事で詳しく説明しています(例示コードも含まれています)。
👉 LLMについてさらに詳しく: 紹介 | OpenAI API | Hugging Face Transformers | プロンプトエンジニアリング | ファインチューニング
大規模言語モデル(LLM)のファインチューニング
概念的な概要とPythonの例コード
towardsdatascience.com
リソース
コンタクト: 私のウェブサイト | 電話で予約 | 質問してください
ソーシャル: YouTube 🎥 | LinkedIn | Twitter
サポート: 私にコーヒーをおごってください ☕️
データ起業家
データ領域の起業家のためのコミュニティ。👉 Discordに参加しましょう!
VoAGI.com
[1] BloombergGPT
[2] Llama 2 Paper
[3] LLMエネルギーコスト
[4] arXiv:2005.14165 [cs.CL]
[5] Falcon 180b Blog
[6] arXiv:2101.00027 [cs.CL]
[7] Alpaca Repo
[8] arXiv:2303.18223 [cs.CL]
[9] arXiv:2112.11446 [cs.CL]
[10] arXiv:1508.07909 [cs.CL]
[11] SentencePience Repo
[12] Tokenizers Doc
[13] arXiv:1706.03762 [cs.CL]
[14] Andrej Karpathy Lecture
[15] Hugging Face NLP Course
[16] arXiv:1810.04805 [cs.CL]
[17] arXiv:1910.13461 [cs.CL]
[18] arXiv:1603.05027 [cs.CV]
[19] arXiv:1607.06450 [stat.ML]
[20] arXiv:1803.02155 [cs.CL]
[21] arXiv:2203.15556 [cs.CL]
[22] Trained with Mixed Precision Nvidia Doc
[23] DeepSpeed Doc
[24] https://paperswithcode.com/method/weight-decay
[25] https://towardsdatascience.com/what-is-gradient-clipping-b8e815cdfb48
[26] arXiv:2001.08361 [cs.LG]
[27] arXiv:1803.05457 [cs.AI]
[28] arXiv:1905.07830 [cs.CL]
[29] arXiv:2009.03300 [cs.CY]
[30] arXiv:2109.07958 [cs.CL]
[31] https://huggingface.co/blog/evaluating-mmlu-leaderboard
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
