「ChatGPTのようなLLMの背後にある概念についての直感を構築する-パート1-ニューラルネットワーク、トランスフォーマ、事前学習、およびファインチューニング」
Building Intuition about the Concepts behind LLM like ChatGPT - Part 1 Neural Networks, Transformers, Pre-training, and Fine-tuning
私だけではないと思いますが、1月のツイートから明らかになっていなかった場合でも、私の心は完全に吹き飛びました。初めてChatGPTに出会った時の経験は、他のどの「チャットボット」とも異なるものでした。それはユーザーの意図を理解し、クエリやコメントに自然に応答するようなもので、人間だけができるような方法でした。もし、その会話の向こう側に別の人がいると言われたら、私は一秒たりとも疑わなかったでしょう。
初めの興奮の後、この神秘的な技術について手に入るものは何でも読み始めました。3月にリリースされたChatGPT APIを使ってチャットボットを作成し、その経験についてブログを書きました(そのうちの1つがVoAGIでブーストされ、まだずっと興奮しています)。もちろん、これでは足りませんでした。私はそのAPIコールの向こう側で何が起こっているのかをもっと知りたくなり、言語モデル、ディープラーニング、トランスフォーマーなどの分野に深く入り込みました。
サー・アーサー・C・クラークの予測した将来の科学技術の進歩に関する3つの法則の中で、最も有名なものは次のように述べています:
「十分に高度な技術は、魔法と区別がつかない。」
このブログ投稿は、大規模な言語モデル(LLM)の背後にある概念を、アクセスしやすい方法で明らかにする試みです。AIのトレンドに積極的に関心を寄せている人、AIエンジニアリングの領域を探求し、基礎を確立したい人、あるいは好奇心を満たそうとしている人など、この記事を読んだ後、ChatGPTを可能にする独創的な概念について少しでも情報を得ていただければと思います。
ニューラルネットワーク
ChatGPTのようなLLMは、人工ニューラルネットワークを使用して、インターネットからの公開可能な大量のテキストデータで訓練されます。人工ニューラルネットワークは、私たちの脳の構造と学習プロセスを抽象的に模倣するように設計された機械学習アルゴリズムです。それは相互に接続されたノードまたは「ニューロン」の層で構成されており、大量のテキストデータに対して繰り返しの訓練反復を通じて、ネットワークはテキストのパターンや言語の微妙なニュアンスを学習し、それに基づいて自動的に意味のある単語、文、あるいはドキュメントを生成する能力を獲得します。
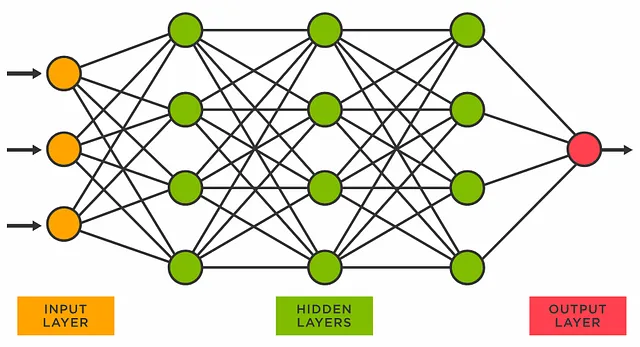
人工ニューラルネットワークは、ディープラーニングと呼ばれる機械学習の一部であり、非常に重要です。それは、複雑なパターンやデータの依存関係を捉え、これらのパターンから未知のデータに対して予測を行う能力を持っています。言語モデリングの文脈では、これは与えられた前の単語または単語の系列から次に来るべき単語を予測することを意味します。一般的な線形回帰などの従来の機械学習アルゴリズムと比較して、ニューラルネットワークは、ネットワークの隠れた層のニューロンの非線形数学関数(活性化関数)を使用することにより、大量のデータに存在する異なる特徴間の非線形関係を表現しモデル化することができます。
ニューラルネットワークは、おそらくあなたが触れたことのある消費者向けの技術を生み出しています(そして、必ずしも言語のタスクに限定されるわけではありません)。例えば、顔認識を使用してスマートフォンをロック解除したり、ポケモンのゲームでの拡張現実機能やNetflixのホーム画面の番組提案などです。
Andrej Karpathyは、それが新しいかつより良いソフトウェアの書き方になりえるとさえ主張しています:
たとえば、プログラムのロジックを手作業でコーディングする代わりに(条件Aが満たされれば、xを実行する;条件Aが満たされなければ、yを実行する)、ニューラルネットワークは、トレーニングデータからの例によって学習することによって、本番で「条件A」に遭遇した場合、xを実行すべきであるということを学習します。これらの条件/ロジックは、作成者によって定義されるのではなく、ニューラルネットワークは自分自身を調整し(数十億または数兆のパラメータである重みとバイアスを微調整することによって)、この望ましい動作に準拠するようにします。
各個別の重みやバイアスが具体的に何をするのか、また単一の重みが人工ニューラルネットワークの動作にどのように貢献するのかは誰も知りません。これらのパラメータは、トレーニング中に勾配の更新によって一括で変更されます(後で詳しく説明します)。
そのため、ニューラルネットワークでトレーニングされた機械学習モデルは「ブラックボックス」としてしばしば言われます。その入力と出力は観察できますが、内部の動作やその方法は簡単には理解できません。これが「新興」の能力が発見される理由でもあります。LLMが大きくなるにつれて(そのパラメータ数で測定される)、予期しない能力を持ってトレーニングから出てくるようになります。たとえば、GPT-2は言語翻訳に優れていることが発見され、GPT-3は優れたフューショットラーナーであり、GPT-4は人工汎用知能(AGI)の兆しを示しています。これらはいずれもトレーニングの目標として明示的に定義されていなかったものです-その主な目的はシーケンス内の次の単語を予測することでした。
新興の振る舞いは大規模なニューラルネットワークに限ったものではありません。システムが大きく、複雑になるにつれて、個々の構成要素間の相互作用によって予期しない振る舞いが生じることがあります。これは、単一のアリは愚かですが、アリの集団は非常に複雑なトンネルネットワークを構築し、他のコロニーとの戦争を行うことができるという現象です。この現象は、社会昆虫(アリやミツバチ)、群衆の行動、および他の生物生態系などのシステムで文書化されています。
プレトレーニングの基礎モデル
ChatGPTなどのものを作成するための最初のステップは、ベースモデルまたは基礎モデルのプレトレーニングです。このステップの目標は、前の単語に基づいて次に来るべき単語を予測することによって、機械学習モデルが一貫した単語構造または人間らしいテキスト(フレーズ、文、段落)を自律的に生成できるモデルを作成することです。これはプレトレーニングと呼ばれます。このステップの出力であるベースモデルは、まだ実用的な応用範囲が限られており、通常は研究者の興味の対象になるに過ぎません。ベースモデルは、テキストの翻訳、要約、分類などの具体的なタスクにおける実世界の有用性を持つように、ファインチューニングの段階を経てさらに「トレーニング」されます。
プレトレーニングの開始時には、ニューラルネットワークのパラメータはランダムな数値で設定されます。巨大なインターネットテキストデータの単語は、トークン(整数として)および埋め込み(ベクトルとして)の形で、ニューラルネットワークに供給される前に数値表現に変換されます。
トークンと埋め込みについては、このシリーズの次の部分で詳しく説明しますが、今のところ、トークンはモデルの語彙の中での単語の一意のIDとして、埋め込みはその単語の意味として考えてください。
モデルは単語または複数の単語を与えられ、それらの前の単語に基づいて次の単語を予測するよう求められます。その後、未知のデータでテストされ、モデルの予測の正確性に基づいて「グラウンドトゥルース」と呼ばれる次の単語が、モデルによって以前に見たことのない非公開データセットから評価されます。
機械学習では、データセットは通常、トレーニングデータセットとテストデータセットに分割されます。トレーニングデータセットはモデルのトレーニングに使用され、テストデータセット(未知のデータ)はモデルの予測を評価するために使用されます。テストセットはまた、「過学習」を防ぐためにも使用されます。過学習とは、モデルがトレーニングデータ上で非常に優れたパフォーマンスを発揮するが、新しい、未知のデータ上ではパフォーマンスが低下する現象のことです。
トレーニングデータセットの例文を考えてみましょう。「私は店に行かなければならない」という文が次のように使用されるかもしれません:
- モデルには「私は」と与えられ、「to」と予測することが期待されます。
- 次に、「私は行かなければならない」と与えられ、「go」と予測することが期待されます。
- 次に、「私は行かなければならない」と与えられ、「to」と予測することが期待されます。
- 最後に、「私は行かなければならない」「店に」と与えられ、「store」と予測することが期待されます。
このようにトレーニングデータセット全体を進めることで、モデルは異なる単語のセットの後に出現する傾向がある単語を学習することができます。「私」と「持っている」、「持っている」と「行く」などの依存関係を学習します。
テストの手順では、プロセスは似ていますが、使用される文やテキストはモデルがトレーニングされていないものです。これは、モデルの言語理解を未知のデータにどれだけ一般化できるかをチェックする方法です。
テストセットからの未知の文を考えてみましょう。「彼女は___に向かう必要があります」。この正確な文はトレーニングデータセットの一部ではありませんでしたが、モデルは同様の文脈を理解するための知識を使用して、教養豊かな予測を行うことができます。たとえば、トレーニング文「私は店に行かなければならない」という文で、「to go to the」や「to head to the」というフレーズの後に場所や目的地が続くことがよくあることがわかります。これに基づいて、モデルは「market」、「store」、「office」などの類似の単語を予測するかもしれません。なぜなら、このような文脈ではこれらの単語が一般的な目的地であるからです。したがって、モデルは「私は店に行かなければならない」という文や意味が似ているバリエーションのトレーニングデータに基づいて訓練されていながらも、その一般化能力を理解し、「彼女は___に向かう必要があります」の後に似たタイプの単語が続く可能性が高いことを理解することができます。
モデルの「学習」方法
プレトレーニングの開始時点では、モデルはまだ何も「学習」していないため、予測を行うときに意味のない単語のシーケンスを出力する場合があります。先ほどの例文では、正しい次の単語「store」の代わりに「apple」という単語が生成されるかもしれません。LLMは確率的なので、ここでの「間違い」とは、モデルが予測するために単語「apple」に対して予想されるよりも高い確率(選択される確率)を割り当てていることを意味します。
究極の目標は、モデルが「She needs to head to the ___」の後に登場する次の単語を予測するたびに常に「store」と出力することです。
実際の単語と予想されるまたはグラウンドトゥルースの次の単語との違いは、「損失関数」を使用して計算されます。違いが大きいほど、「損失」値が高くなります。損失は、モデルに予測を求めるすべての予測の損失またはエラーを「平均化」した単一の数値です。これらの手順のいくつかの反復を通じて、この「損失」の値を最小化することを目指し、バックプロパゲーションと勾配降下最適化と呼ばれるプロセスを実行します。モデルはこれらの手順を通じて「学習」し、予測能力を向上させます。
おそらく「2つの単語の違いを計算する方法」をどのように計算するか疑問に思っているかもしれません。注意しておいてください。ニューラルネットワークを通過するのは実際のテキスト(単語、文)ではなく、これらのテキストの数値表現であるトークンと埋め込みです。単語の数値表現は、ネットワークのレイヤーを通過し、次にどの単語が来るかを決定するための語彙に対する確率分布として処理されます。未訓練のモデルでは、「apple」という単語のトークンID(例えば0.8)に対して、「store」という予測される次の単語のトークンID(0.3であるとします)よりも高い確率を割り当てるかもしれません。ニューラルネットワークは、実際のテキストの単語や文字を一切エンカウントしません。数値のみを扱います。基本的には、計算機と同じです。 😅

バックプロパゲーションにより、モデルの誤差の度合い(損失値)がニューラルネットワークを逆方向に伝播します。それは、各個々の重みとバイアスの出力に対する微分を計算します。つまり、各特定のパラメータの変化に対して出力がどれだけ敏感かを示します。
学校で微分積分を学んでいない私のような人々にとって(私自身も含めて)、モデルのパラメータ(重み/バイアス)を調整可能なつまみと考えてください。これらのつまみは任意のものです – つまり、それがモデルの予測能力をどのように制御しているのかを特定することはできません。つまみは時計回りまたは反時計回りに回転させることができ、出力の振る舞いに異なる影響を与えます。つまみAは時計回りに回すと損失を3倍に増加させ、つまみBは反時計回りに回すと損失を1/8に減少させます(など)。これらのつまみはすべて(数十億個すべて)チェックされ、各つまみの調整に対して出力がどれだけ敏感かについての情報を得るため、その数値は出力に関するそれらの導関数です。これらの導関数の計算はバックプロパゲーションと呼ばれます。バックプロパゲーションの出力は、パラメータの個別の導関数からなるベクトル(数値のリスト)です。このベクトルは、ニューラルネットワークの既存のパラメータ値(または現在の学習値)に対するエラーの勾配です。
ベクトルには長さまたは大きさと方向の2つの特性があります。勾配ベクトルには、誤差または損失が増加している方向の情報が含まれています。ベクトルの大きさは、傾斜または増加率を示します。
勾配ベクトルを霧のかかった山の地図と考えてみてください。勾配降下最適化は、勾配ベクトルから方向と傾斜の情報を使用して、最小の損失値である山の底(最適な状態)にできるだけ効率的に到達するために、最大の下方向の傾斜をたどるパスに向かうことです。これには、ネットワークの重みとバイアスの値を反復的に調整すること(小さな値を引くこと、つまり学習率)が含まれます。この最適な状態に到達するためには、モデルの予測に対してエラーをバックプロパゲーション(逆伝播)し、モデルのパラメータを更新します(確率的勾配降下法またはSGDを使用して)。これは、各繰り返しまたはステップで損失値(黄色)を減少させ、モデルの予測の精度を向上させるためのループを介して数回繰り返されます。
これらの手順の後、次のトレーニングイテレーションで、「彼女は〜へ向かう必要がある」という次の単語の予測を再度求めると、それが単語「店」により高い確率を割り当てるべきです。このプロセスは、モデルの学習が安定化したか収束したことを意味する損失値に重要な変化がないまで、数回繰り返されます。
ニューラルネットワークが英語(および他の言語)でコミュニケーションを学ぶ方法のTL;DRは、数学の大量使用です。すごくたくさんです。ニューラルネットワーク内での複雑な計算から生成される単一の数値(損失値)の値を減らすことに焦点が当てられます。この数値が小さくなるほど、言語モデルはより「流暢」または「一貫性のある」ものになります。ネットワークの内部層で行われる行列とベクトルの間の数百万または数十億の数学的操作は、言語の幾何学的モデルに収束します。
直感的に理解するために、私たちはこのモデルを「理解する」「見る」「学ぶ」という言葉を使って擬人化していますが、実際にはこれらのことを行う能力はありません。これは、サンプリング方法に基づいて確率分布に基づいてシーケンスの次の最適なトークンを出力するアルゴリズムに過ぎません。
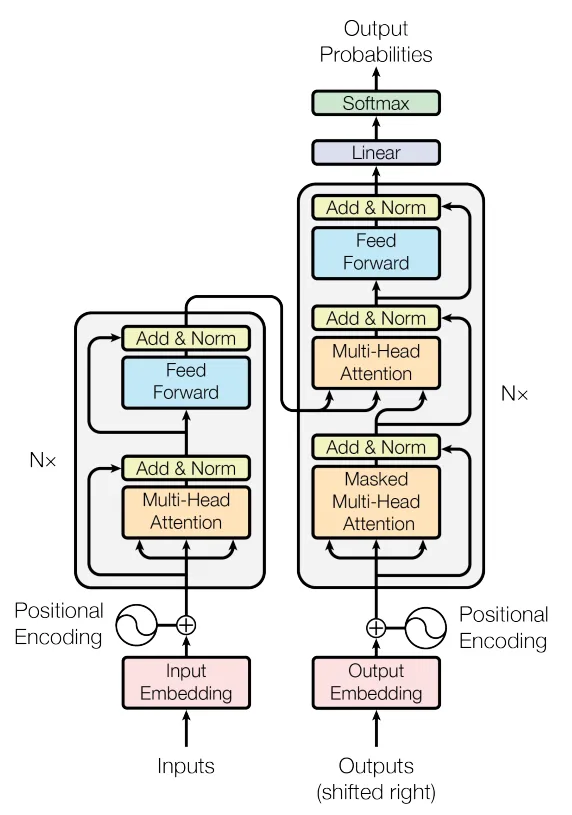
トランスフォーマー
トランスフォーマーは、ChatGPTを生み出した自然言語処理(NLP)研究の突破口です。これはユニークな自己注意メカニズムを利用するタイプのニューラルネットワークアーキテクチャです。2017年に発表された「Attention is All You Need」という論文で有名です。この論文の後に登場したBERT、GPT-1などのほぼすべての最先端のLLM(Language Model)は、この論文に基づいて構築されたか、またはそのアイデアを使用して構築されました。これは、深層学習に与える影響のため、その重要性を過小評価することはできません。現在、トランスフォーマーはビジョンタスクにも活用され、真にマルチモーダルであり、他の種類のデータを処理する柔軟性を示しています。また、さえもTowards AIの編集チームが抵抗できない「…は必要なものだけ」というメメティックなトレンドを始めました。 😂
トランスフォーマー以前のNLPにおいてSOTAモデルを生成したニューラルネットワークは、逐次的なデータ処理を利用するアーキテクチャに依存していました。つまり、トレーニング中に各単語またはトークンをネットワークが順番に処理します。単語の順序はシーケンスの文脈/意味を保持するために重要であり、例えば「猫がネズミを食べた」と「ネズミが猫を食べた」は、まったく同じ単語/トークンで構成されていますが、異なる順序であるため、2つの異なる意味を持ちます。
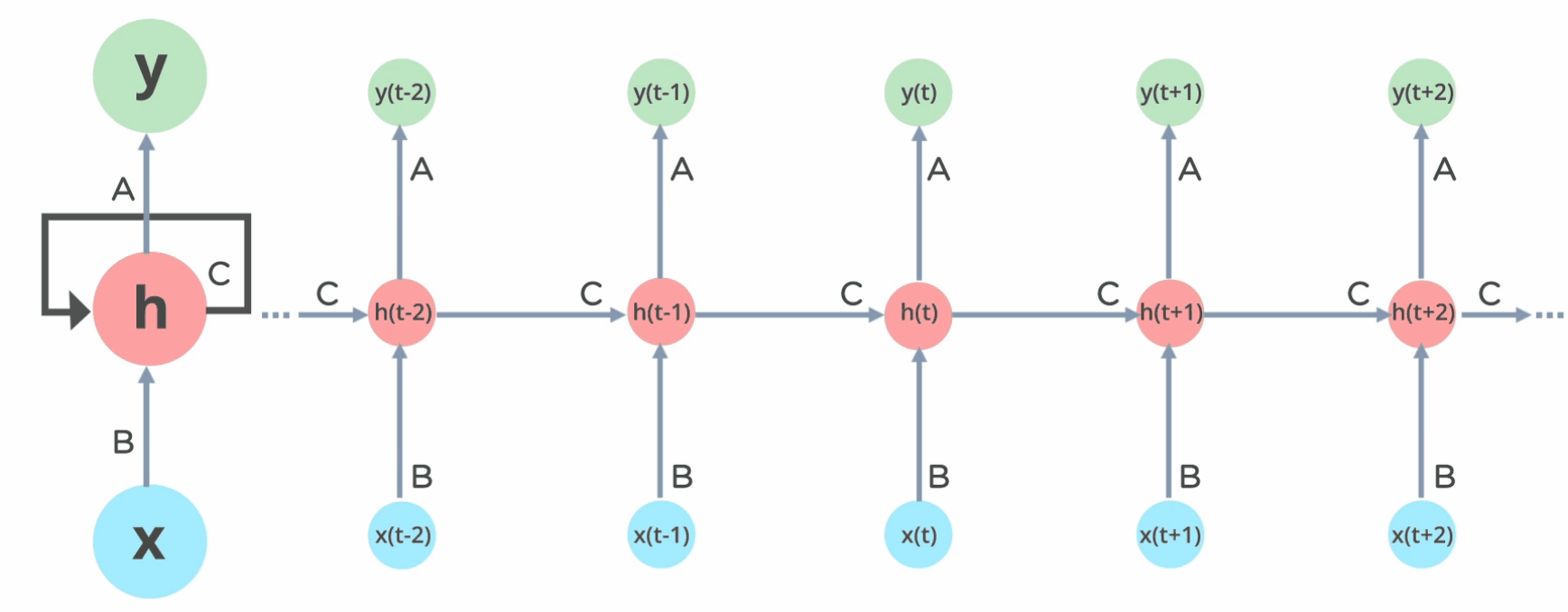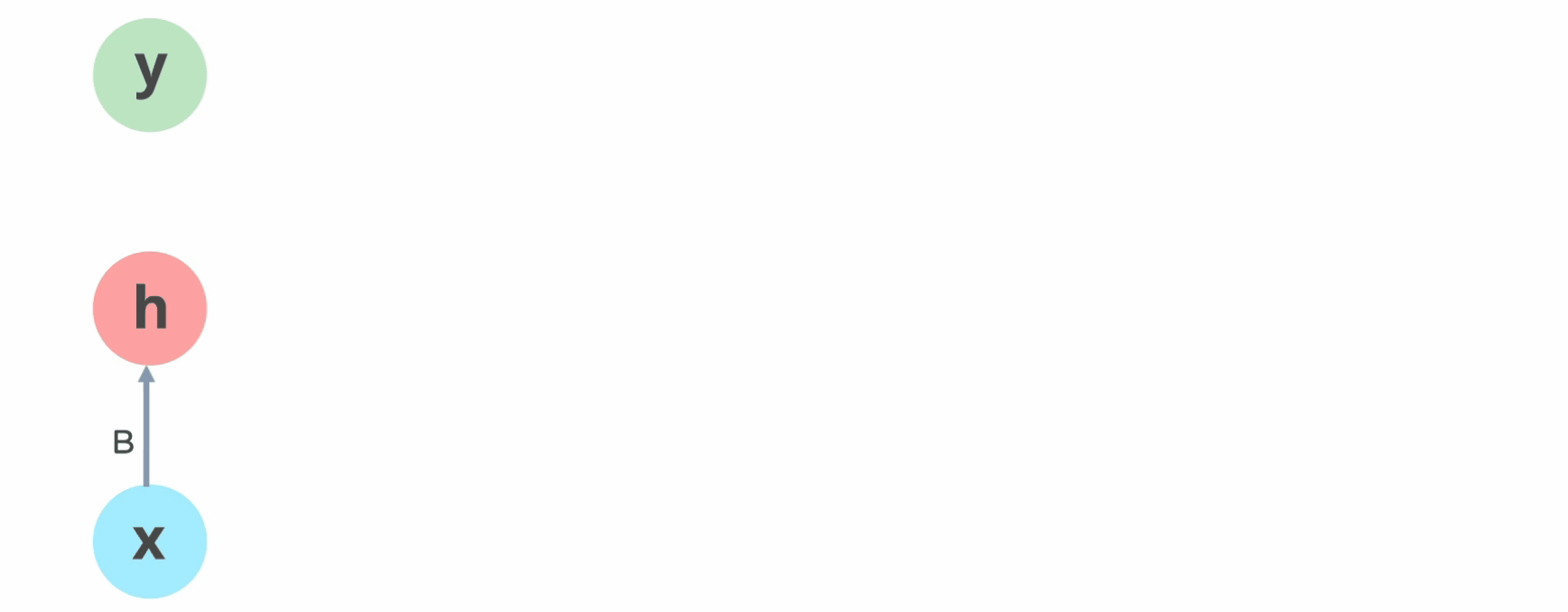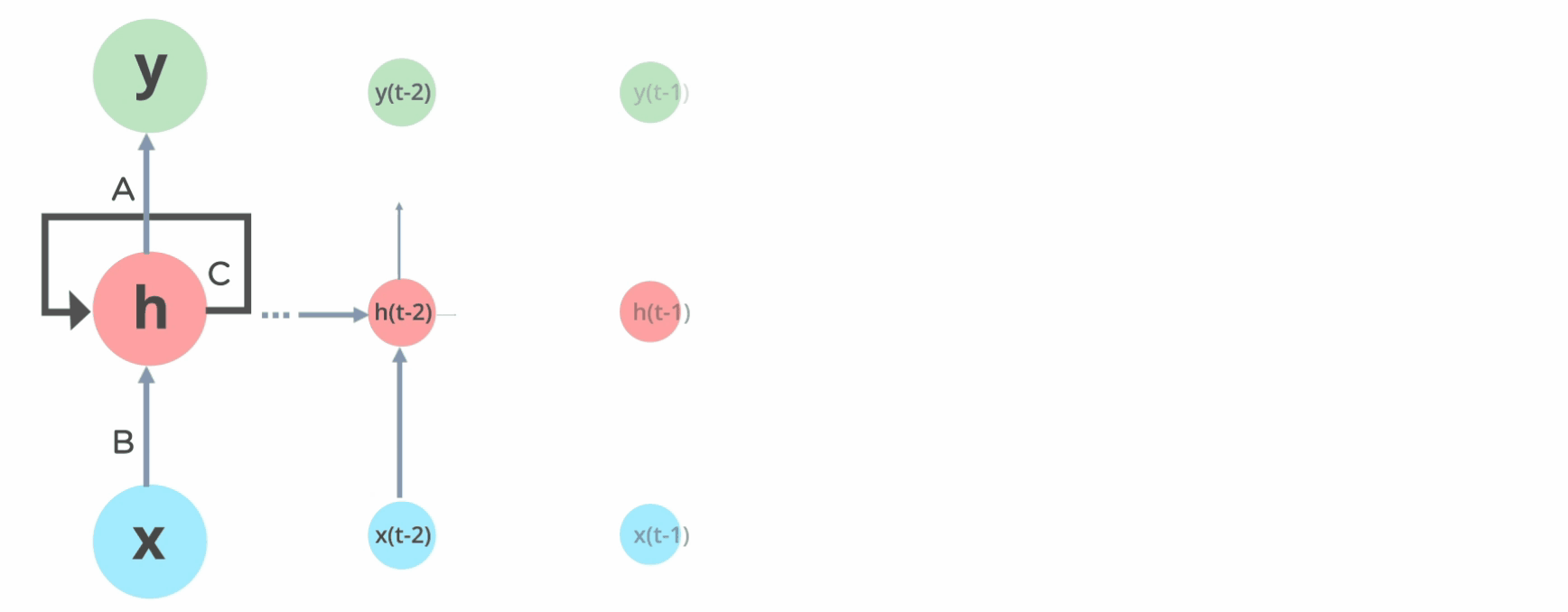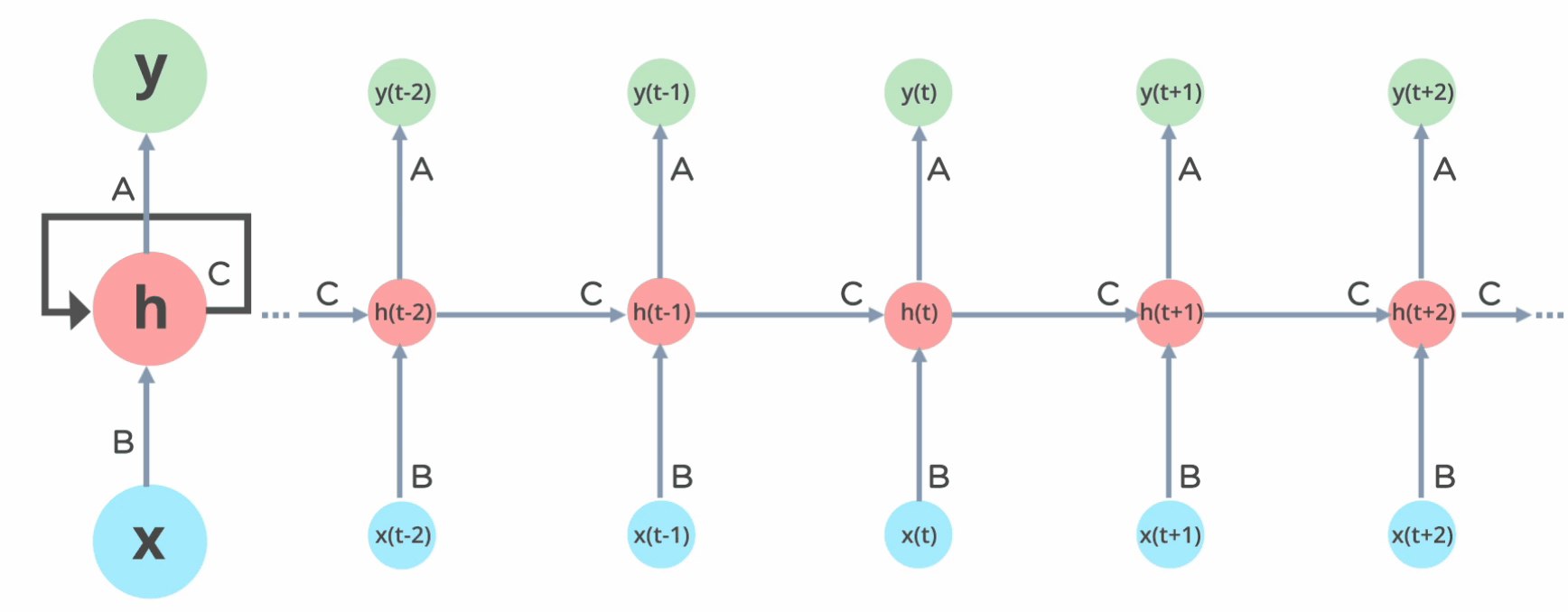
トランスフォーマーの主な革新の1つは、再帰または順次トークン処理を廃止することです。トークンを順次処理する代わりに、トランスフォーマーは各単語の位置情報(つまり、処理されるシーケンス内での単語の順序)を埋め込みにエンコードし、それをネットワークの内部層に入力します。
さらに重要な点として、トランスフォーマーはRNNなどのニューラルネットワークが苦労した長期的な依存関係の問題を解決しました。十分な長さの単語のシーケンス(非常に長い段落など)が与えられると、RNNはシーケンスの前の単語の文脈を「忘れてしまいます」。これは消失勾配問題と呼ばれます。RNNは、各順次または時間ステップで、シーケンス内の単語の関連性に関する情報を隠れた状態として記憶します。長いシーケンスを処理する間、バックプロパゲーション中に、以前の時間ステップに対応する勾配が非常に小さくなることがあります。これにより、RNNがシーケンスの初期部分から学習するのが困難になり、現在生成されているシーケンスの文脈に関する情報が「失われる」可能性があります。
トランスフォーマーは、この制限を「自己注意」メカニズムによって解決します。位置符号化と同様に、各単語は埋め込みを介して、シーケンス内の他の単語にどの程度「注意を払う」か、すなわち重みをどの程度置くかの情報でエンコードされます。シーケンス内のすべての単語に対して、このエンコーディングは同時に行われるため、トランスフォーマーは任意のシーケンスの文脈を保持することができます。
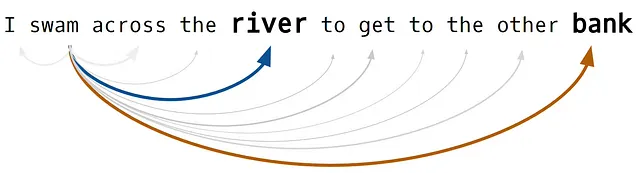
単語同士の関係性をどの程度注意すべきかという度合いは、モデルの重みに格納され、行列の乗算を介して単語の埋め込みにエンコードされます。これらの「学習」は、モデルがトレーニングデータ内の単語間の関係についてより多く学習するにつれて、各トレーニングイテレーションごとに調整されます。
セルフアテンション層の最終出力(上のイラストのZ行列)は、各単語の位置情報(位置エンコーディングステップでエンコードされたもの)と、各単語がシーケンス内の他のすべての単語にどれだけ注意する必要があるかに関する情報がエンコードされた単語埋め込みの行列です。
その後、この行列は、先述の記事で議論された通常のニューラルネットワーク(フィードフォワードニューラルネットワークと呼ばれるもの)に供給されます。これらの手順(アテンション+フィードフォワード-トランスフォーマーブロックを構成する)は、トランスフォーマーの各隠れ層に対して複数回繰り返されます。例えば、GPT3では96回繰り返されます。各層での変換は、シーケンスの次の単語を最も正確に予測するためのモデルの「知識」に追加の情報を追加します。
OpenAIによって公開されたLLMスケーリング法によると、より良いモデルを訓練するためには、パラメータの数を増やすことがトレーニングデータのサイズを増やすよりも3倍重要です。ただし、この問題に取り組むためには、パラメータの数が増えると計算要件も大幅に増加するため、計算の複雑さに対応するために並列化が不可欠です。
並列化は、順次的な性質を持つRNNでは難しいです。これは、トランスフォーマーには問題ではありません。トランスフォーマーは、シーケンス内のすべての要素間の関係を順次ではなく同時に計算するため、GPUやビデオカードとの相性が良いことを意味します。グラフィックスのレンダリングでは、同時に発生する多数の単純な計算が必要です。同時操作に設計された多数の小型で効率的な処理コアを備えたGPUは、ディープラーニングにおいて中心的な行列やベクトルの演算に適しているため、これらのタスクに適しています。
AIが「主流化」し、より大きく優れたモデルを構築しようとする競争が激化することは、GPUメーカーにとって好機です。この執筆時点で、NVIDIAの株価はYTDで200%成長し、これにより彼らの時価総額は1兆ドルに達しました。彼らは、Apple、Google、Microsoft、Amazonなどのメガキャップ企業に加わりました。
トランスフォーマーは明らかに複雑なトピックであり、上記の説明では重要な概念を省いて幅広い読者に理解しやすくするために簡略化されています。もっと詳しく知りたい場合は、Jay Allamarさんのイラスト入りトランスフォーマー、Lili Jiangさんのポーションの比喩、またはより高度な内容を求める場合は、Karpathyさんのシェイクスピア風のナノGPTを参考にしてください。
ChatGPTのような「チャット」モデルの微調整
事前学習の出力は、ベースモデルまたは基礎モデルです。最近リリースされたテキスト生成の基礎モデルの例には、GPT-4、Bard、LLaMa 1 & 2、Claude 1 & 2があります。ベースモデルは、事前学習から既に言語の幅広い知識(文の構造、単語間の関係など)を持っているため、この知識を活用して、モデルを翻訳、要約、またはChatGPTのような対話アシスタントとして特定のタスクを行うようにさらにトレーニングすることができます。基本的な考え方は、事前学習から得られたモデルの一般的な言語理解を、幅広い下流タスクに使用できるということです。この考え方は、転移学習と呼ばれます。
ベースモデルに質問をしたり促したりすると、おそらく別の質問で返答するでしょう。前の単語の系列が与えられた場合、次に来るべき単語を予測することによって、単語の系列を完了するように訓練されているからです。例:

ただし、ベースモデルに質問に答えさせることができます。それは、モデルを「騙す」ことで、シーケンスを完了しようとしていると思わせることによって達成されます:

この考えを利用して、モデルは質問と回答の形式で異なるセットのプロンプト/完成のペアを使用して別のトレーニングラウンドを行います。ランダムなテキストから言葉のセットの後にどの単語が続くかを予測することによって「英語を学ぶ」代わりに、モデルは、プロンプトを「質問」形式で完了するために、完成は「回答」形式であるべきだと「学習」します。これが監督つき微調整(SFT)の段階です。

事前学習では、モデルが自己教師あり学習と呼ばれるタイプの機械学習を利用して、トレーニングデータ自体から予測しようとしている「ラベル」または正解単語を作成します。先ほどの例を見てみましょう:
- モデルに「I have」と与えられ、「to」を予測することが期待されています。
- 次に、「I have to」と与えられ、「go」を予測することが期待されています。
ターゲット/正解単語の「to」と「go」は、モデルがコーパスを通過する際に作成されます。ターゲット/正解単語が重要であることに注意してください。これが損失値の基準であり、現在のモデルの予測がターゲットとどれだけ一致しているかとその後の勾配更新の基礎です。
事前学習フェーズに比べて、微調整の段階のトレーニングデータの準備は労力を要します。人間のラベラーとレビューアが、ターゲットの完成やアノテーションを慎重に行う必要があります。ただし、モデルは既に言語の一般的な特徴を学んでいるため、タスク固有のトレーニングデータの利用可能性が限られていても、迅速にその言語タスクに適応することができます。これは転移学習の利点の一つであり、事前学習の背後にある動機です。Karpathyによると、LLMをトレーニングするために99%の計算能力とトレーニング時間、およびほとんどのデータが事前学習フェーズで利用され、微調整の段階ではほんの一部が使用されます。
ファインチューニングは、先ほど説明した勾配更新法を使用しますが、今回は人間が選んだ質問と回答のペアのリストから学習し、補完の構造を学ぶ方法を教えます。つまり、「何を言うか」と「どのように言うか」を学びます。
ファインチューニングでは、報酬モデリングや人間のフィードバックによる強化学習(RLHF)などの他のファインチューニング段階を経て、モデルが人間の好みにより合った補完を出力するように訓練します。この段階では、人間のラベラーがモデルの補完を真実性、有用性、無害性、有害性などの属性で評価します。人間が好む補完はトレーニングに強化され、ファインチューニングされたモデルの補完に高い確率で現れるようになります。

これらのファインチューニングのステップの出力は、「アシスタント」または「チャット」モデル、例えばChatGPTです。これらはこれらの基礎モデルの「小売り」バージョンであり、ChatGPTのウェブサイトで対話するときに使用されます。GPT-3ベースモデル(davinci)はAPI経由でアクセスできます。GPT-4ベースモデルは、この執筆時点ではAPIとしてリリースされておらず、OpenAIによる競争とLLMの安全性に関する最近の発表を考慮すると、リリースされる可能性は低いです。これらのファインチューニングのステップは、利用可能な商用およびオープンソースのファインチューニングモデル全般において基本的に同じです。
Part 1 終わり
注:Part 2では、LLMの急増よりも前に存在していた埋め込みについて説明しますが、同様に魅力的です。埋め込みモデルのトレーニング方法、文やドキュメントレベルの埋め込み(RAGシステムで使用される)の生成方法についても説明します。また、トークンについても話し合います。この投稿では、トークン=単語と暗示しましたが、実際のトークンは個々の文字や文字、サブワード、完全な単語、複数の単語、またはモデルの語彙全体でこれらすべてのタイプです!
何か間違いがあれば、コメントで訂正していただければ幸いです! 🙂
参考文献/参考資料:
3blue1brown. ニューラルネットワークとは何ですか?
Geeks for Geeks. 人工ニューラルネットワークとその応用
Jay Alammar. イラスト付きトランスフォーマー
Luis Serrano. トランスフォーマーモデルとは何ですか?それはどのように機能しますか?
Andrej Karpathy. GPTの現状
Andrej Karpathy. GPTを構築しましょう:ゼロからコードで詳細に説明します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
