ML向けETLの構築に関するベストプラクティス
美とファッションのエキスパートが解説!『美とファッションの世界で活躍するための最新トレンド』
MLエンジニアリングの重要な部分は、信頼性のあるスケーラブルな手順を構築することです。データを抽出し、変換し、豊かにし、特定のファイルストアまたはデータベースにロードするための手順です。これは、データサイエンティストとMLエンジニアがもっとも協力するコンポーネントの1つです。通常、データサイエンティストはデータセットがどのようになるかの大まかなバージョンを考えます。理想的には、Jupyterノートブックではなく。その後、MLエンジニアは、このタスクに参加して、コードをより読みやすく、効率的かつ信頼性の高いものにするためのサポートを提供します。
ML ETLは、複数のサブ-ETLまたはタスクで構成することができます。そして、非常に異なる形で具現化することができます。一部の一般的な例:
- ScalaベースのSparkジョブは、S3に保存されているイベントログデータをParquetファイルとして読み取り、処理し、Airflowを介して週次でスケジュールします。
- Pythonプロセスは、スケジュールされたAWS Lambda関数を介してRedshift SQLクエリを実行します。
- EventBridgeトリガーを使用して、Sagemaker Processing Jobを使用して実行される複雑なPandas処理。
ETLのエンティティ
このタイプのETLにはさまざまなエンティティがあります。私たちはソース(生データが存在する場所)、デスティネーション(最終的なデータアーティファクトが保存される場所)、データプロセス(データの読み取り、処理、ロード方法)、およびトリガー(ETLが開始される方法)と言えます。
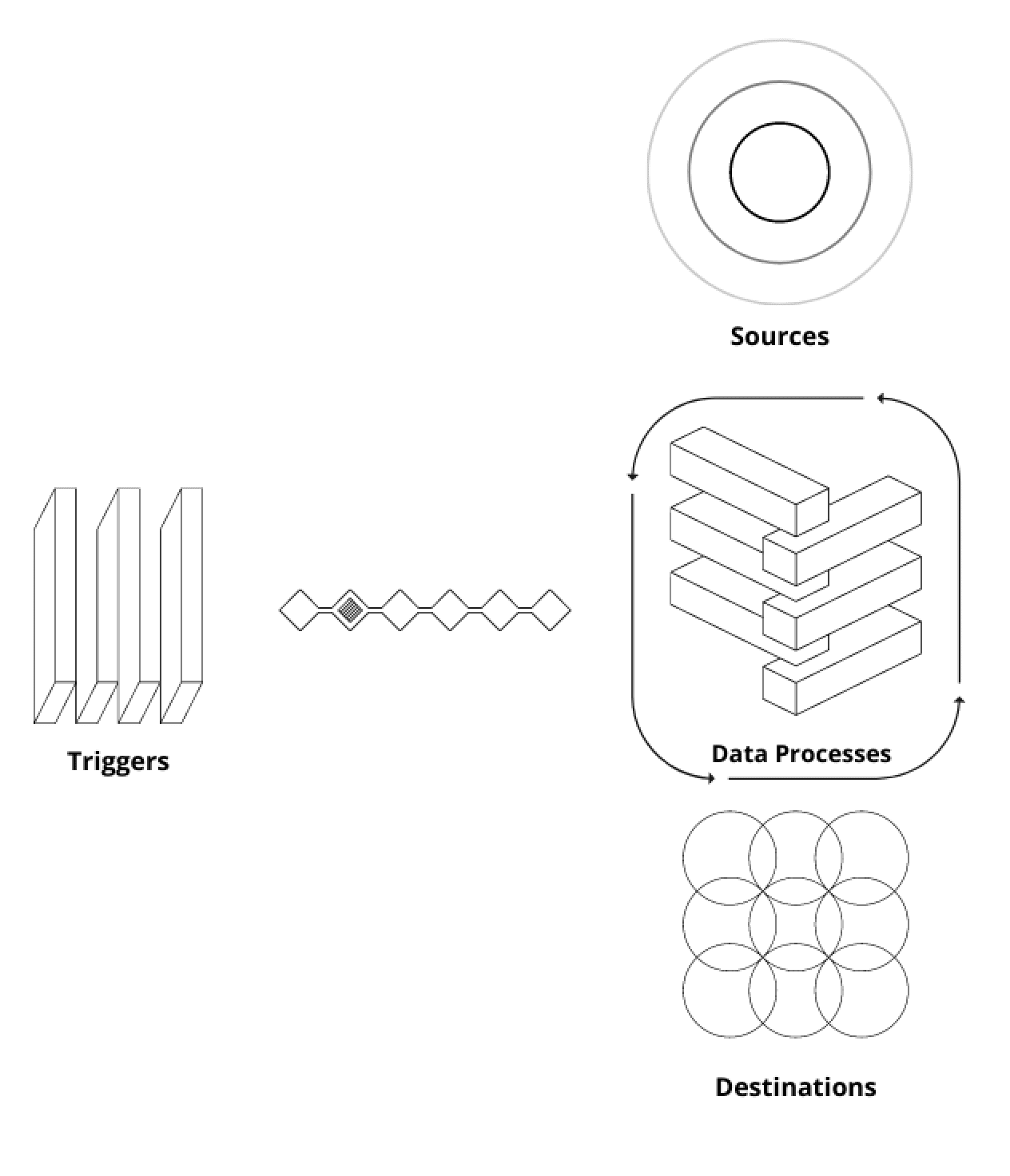
- ソースとしては、AWS Redshift、AWS S3、Cassandra、Redis、または外部APIなどがあります。デスティネーションも同様です。
- データプロセスは通常、一時的なDockerコンテナで実行されます。Kubernetesや他のAWSマネージドサービス(AWS ECSやAWS Fargateなど)を使用してさらに抽象化のレベルを追加することもできます。SageMakerパイプラインやProcessing Jobsも使用できます。データ処理エンジンとしては、Spark、Dask、Hive、Redshift SQLエンジンなどの特定のデータ処理エンジンを利用してクラスタ内でこれらのプロセスを実行することもできます。また、PythonプロセスとPandasを使用して単純な単一インスタンスプロセスを実行することもできます。それ以外にも、Polars、Vaex、Ray、Modinなどの興味深いフレームワークがあり、中間的なソリューションに取り組むのに役立つことがあります。
- 最も人気のあるトリガーツールはAirflowです。その他にも、Prefect、Dagster、Argo Workflows、Mageなどが使用できます。

フレームワークを使用すべきか?
フレームワークは、具体的な問題に適用されると、より一貫したコードベースを作成するための抽象化、慣例、すでに用意されているユーティリティのセットです。フレームワークはETLに非常に便利です。前述したように、抽象化またはカプセル化される可能性のある非常に一般的なエンティティが存在します。これにより包括的なワークフローを生成できます。
内部のデータ処理フレームワークを構築するための進行方法は次の通りです:
- 異なるソースとデスティネーションに対するコネクタのライブラリを構築することから始めます。必要に応じて、プロジェクトごとに必要に応じて実装してください。それがYAGNIを避けるための最良の方法です。
- 開発のためのシンプルで自動化されたワークフローを作成し、コードベースを迅速に反復することができるようにします。たとえば、CI/CDワークフローを設定して、パッケージの自動テスト、リント、公開を行います。
- SQLスクリプトの読み込み、Sparkセッションの立ち上げ、日付のフォーマット関数、メタデータジェネレータ、ログ記録ユーティリティ、認証情報と接続パラメータの取得用の関数、アラートユーティリティなどのユーティリティを作成します。
- ワークフローの作成には、内部フレームワークの構築、または既存のフレームワークの使用のいずれかを選択します。この社内開発を考慮すると、複雑さのスコープは広がります。ワークフローの構築時にはいくつかのシンプルな慣例から始めて、LuigiやMetaflowなどの一般的なクラスを持つDAGベースのライブラリを構築することもできます。これらは使用できる人気のあるフレームワークです。
“Utils”ライブラリの構築
これは、データコードベースの重要な中心的な部分です。すべてのプロセスは、このライブラリを使用してデータを1つのソースから別のデスティネーションに移動します。堅固でよく考え抜かれた初期のソフトウェア設計が重要です。
なぜこれをやりたいのでしょうか? それは、主な理由は次のとおりです:
- 再利用性:同じソフトウェアコンポーネントを異なるソフトウェアプロジェクトで使用することで、生産性を向上させることができます。ソフトウェアの部分は一度だけ開発すればよく、その後、他のソフトウェアプロジェクトに統合することができます。しかし、このアイデアは新しいものではありません。私たちは、1968年のカンファレンスでソフトウェア危機と呼ばれる問題を解決することを目指した参照先を見つけることができます。
- カプセル化:ライブラリを介して使用される異なるコネクタの内部すべてをエンドユーザーに表示する必要はありません。そのためには理解できるインターフェースを提供することが十分です。たとえば、データベースへのコネクタがある場合、コネクタクラスのパブリック属性として接続文字列が公開されることは望ましくありません。ライブラリを使用することで、データソースへのセキュアなアクセスが保証されます。この部分をチェックしてください
- 高品質のコードベース:テストは一度だけ開発する必要があります。したがって、開発者はテストスイート(理想的には非常に高いテストカバレッジを持つ)を含むライブラリに依存することができます。エラーや問題のデバッグ時に、テストスイートが信頼できる場合、最初のパスではライブラリ内で問題が発生しているとは考えないことができます。
- 標準化 / “意見の統一”:コネクタのライブラリを持つことで、ETLの開発方法がある程度決まります。これは良いことです、なぜなら組織内のETLは異なるデータソースへのデータの抽出や書き込みに同じ方法が使用されるからです。標準化はコミュニケーションの向上、生産性の向上、予測と計画の向上につながります。
このようなライブラリを構築する際には、チームが長期間にわたって保守することを約束し、必要に応じて複雑なリファクタリングを実施しなければならないリスクを引き受けることになります。これらのリファクタリングを行う必要があるいくつかの原因は次のとおりです:
- 組織が異なるパブリッククラウドに移行する。
- データウェアハウスエンジンが変更される。
- 新しい依存関係のバージョンがインターフェースを破壊する。
- より多くのセキュリティの許可チェックが必要になる。
- 新しいチームがライブラリの設計について異なる意見を持ち込む。
インターフェースクラス
ETLをソースやデスティネーションに対して独立させるために、基本エンティティのためのインターフェースクラスを作成するのは良い決定です。インターフェースはテンプレートの定義として機能します。
たとえば、データベースコネクタの必要なメソッドと属性を定義するための抽象クラスを持つことができます。以下にこのクラスがどのようなものになるかを簡略化された例で示します:
from abc import ABCclass DatabaseConnector(ABC): def __init__(self, connection_string: str): self.connection_string = connection_string @abc.abstractmethod def connect(self): pass @abc.abstractmethod def execute(self, sql: str): pass他の開発者はDatabaseConnectorを継承して新しい具体的な実装を作成することができます。例えば、MySqlConnectorやCassandraDbConnectorなどをこの方法で実装することができます。これにより、エンドユーザーはDatabaseConnectorから派生したコネクタをどのように使用するかを素早く理解することができます(同じインターフェースを持つメソッドがあるため)。
mysql = MySqlConnector(connection_string)mysql.connect()mysql.execute("SELECT * FROM public.table")cassandra = CassandraDbConnector(connection_string)cassandra.connect()cassandra.execute("SELECT * FROM public.table")シンプルで名前のわかりやすいメソッドを持つインターフェースは非常に強力であり、より高い生産性を実現することができます。したがって、それについて品質の高い時間をかけることをお勧めします。
適切なドキュメント
ドキュメントはコード中のdocstringやインラインコメントに限られません。それはライブラリに関する周囲の説明にも言及します。パッケージの最終目標と貢献するための要件とガイドラインについての鮮やかな説明と要件を記述することが重要です。
たとえば:
"このユーティリティライブラリは、組織内の異なるシステムに対するシンプルで信頼性の高いコネクタを提供するため、MLデータパイプラインと特徴エンジニアリングのジョブ全体で使用されます。"
または
"このライブラリには、シンプルなインタフェースで使用できる特徴エンジニアリングのメソッド、変換、アルゴリズムのセットが含まれており、scikit-learnのパイプラインと同様にチェーン化できます。"
明確なミッションがあると、寄稿者からの正しい解釈への道が開けます。これがなぜ、オープンソースライブラリ(たとえば、pandas、scikit-learnなど)がここ数年で大きな人気を得た理由です。寄稿者はライブラリの目標を受け入れ、示された基準に従うことにコミットしています。組織でも同様のことをすべきです。
ミッションが述べられた後、私たちは基礎となるソフトウェアアーキテクチャを開発する必要があります。インタフェースはどのように見えるか、どのような機能性をカバーするか(例:さまざまな振る舞いをもたらす引数の追加など)、またはより細かいメソッドを使用するか(例:各メソッドには非常に具体的な機能がある)などを決める必要があります。
それができたら、スタイルガイドです。優先するモジュールの階層構造、必要なドキュメンテーションの深さ、PRの公開方法、カバレッジの要件などを明確にします。
コード内のドキュメンテーションに関しては、docstringsは関数の振る舞いを十分に説明する必要がありますが、関数名を単純にコピーするだけではなりません。関数名が十分に表現力がある場合、その振る舞いを説明するdocstringは冗長になってしまいます。簡潔かつ正確に記述しましょう。簡単な例を示します:
❌いいえ!
class NeptuneDbConnector: ... def close(): """This function checks if the connection to the database is opened. If it is, it closes it and if it doesn’t, it does nothing. """
✅はい!
class NeptuneDbConnector: ... def close(): """データベースへの接続を閉じます。"""
インラインコメントについては、私は常に奇妙または不規則に見えるものを説明するために使用するのが好きです。また、複雑なロジックや派手な構文を使用する場合は、そのスニペットの上に明確な説明を書く方が良いです。
# リストから最大の整数を取得l = [23, 49, 6, 32]reduce((lambda x, y: x if x > y else y), l)
それ以外にも、Githubの問題やStackoverflowの回答へのリンクを含めることもできます。これは非常に便利です、特に既知の依存関係の問題を克服するために奇妙なロジックをコーディングしなければならなかった場合です。また、Stackoverflowから得た最適化のトリックを実装する必要があった場合も非常に便利です。
これらの2つ、インタフェースクラスと明確なドキュメンテーションは、共有ライブラリを長期間存続させる最善の方法だと私は考えています。怠惰で保守的な新しい開発者や、全力でエネルギッシュで主義主張の強い開発者にも対応できます。変更、改善、あるいは革新的なリファクタリングはスムーズに行われます。
ETLにソフトウェアデザインパターンを適用する
コードの観点から見ると、ETLには3つの明確に区別された上位関数があるべきです。それぞれが次のステップに関連しています:Extract(抽出)、Transform(変換)、Load(読み込み)。これは、ETLコードに対する最も簡単な要件のひとつです。
def extract(source: str) -> pd.DataFrame: ...def transform(data: pd.DataFrame) -> pd.DataFrame: ...def load(transformed_data: pd.DataFrame): ...
もちろん、これらの関数をこのように名前付けることが必須ではありませんが、広く受け入れられている用語として、可読性が向上します。
DRY(Don’t Repeat Yourself)
これは、コネクタライブラリを正当化する大きなデザインパターンの1つです。一度書けば、異なるステップやプロジェクト間で再利用できます。
関数型プログラミング
これは、関数を「純粋」または副作用のないものにすることを目指すプログラミングスタイルです。入力は変更不可能であり、出力は常にその入力に基づいて同じです。これらの関数はテストとデバッグが容易で、分離してテスト可能です。したがって、データパイプラインの再現性を高める上でより良いレベルを提供します。
<!–機能プログラミングがETLに適用されれば、冪等性を提供できるはずです。つまり、パイプラインを実行(または再実行)するたびに、同じ出力が返ってくるべきです。この特性により、私たちは自信を持ってETLを操作し、二重の実行が重複データを生成しないことを確信することができます。間違ったETL実行から挿入済みの行を削除するために奇妙なSQLクエリを作成しなければならなかった回数は何回ですか?冪等性を確保することで、それらの状況を回避できます。Apache AirflowとSupersetの作者であるMaxime Beaucheminは、Functional Data Engineeringの著名な支持者の一人です。
SOLID
クラス定義への参照を使用しますが、このセクションはファーストクラスの関数にも適用できます。これらのコンセプトを説明するために、重いオブジェクト指向プログラミングを使用しますが、これがETLを開発するための最善の方法であるという意味ではありません。特定の合意はなく、各企業が独自の方法で行っています。
単一責任の原則に関しては、変更する理由がただ1つだけあるエンティティを作成する必要があります。たとえば、SalesAggregatorとSalesDataCleanerクラスなど2つのオブジェクトの責任を分離することです。後者は、セールスからデータを「クリーンアップ」するための特定のビジネスルールを含んでいる可能性があり、前者はさまざまなシステムからセールスを抽出することに焦点を当てています。両方のクラスのコードは、異なる理由で変更する可能性があります。
オープンクローズの原則に関しては、エンティティは新しい機能を追加するために拡張可能であるべきですが、修正するために開かれてはいけません。たとえば、SalesAggregatorが物理店舗からセールスを抽出するためにStoresSalesCollectorをコンポーネントとして受け取った場合、オンラインでもデータを取得したい場合、互換性のあるインターフェースを持つ別のOnlineSalesCollectorも受け入れることができるかどうかを示すため、SalesCollectorは拡張のために開かれていると述べることができます。
from abc import ABC, abstractmethodclass BaseCollector(ABC): @abstractmethod def extract_sales() -> List[Sale]: passclass SalesAggregator: def __init__(self, collectors: List[BaseCollector]): self.collectors = collectors def get_sales(self) -> List[Sale]: sales = [] for collector in self.collectors: sales.extend(collector.extract_sales()) return salesclass StoreSalesCollector: def extract_sales() -> List[Sale]: # 物理店舗からセールスデータを抽出するclass OnlineSalesCollector: def extract_sales() -> List[Sale]: # オンラインセールスデータを抽出するif __name__ == "__main__": sales_aggregator = SalesAggregator( collectors = [ StoreSalesCollector(), OnlineSalesCollector() ] ) sales = sales_aggregator.get_sales()
以下の例でわかるように、DatabaseConnectorの任意のサブタイプはLiskovの代替原則に準拠しており、ETLManagerクラス内でその任意のサブタイプが使用されることができます。
さて、インターフェース分離の原則について話しましょう。クライアントは使用しないインターフェースに依存すべきではありません。これは、DatabaseConnectorの設計に非常に便利です。DatabaseConnectorを実装している場合、データベースの管理上の使用に関連する承認権限の付与やログエラーのチェックなど、ETLのコンテキストでは使用されないメソッドをインターフェースクラスにオーバーロードする必要はありません。
そして最後に依存性逆転の原則です。これは高レベルのモジュールが低レベルのモジュールではなく、抽象化に依存するべきであると言っています。これは上記のSalesAggregatorで明確に示されています。このメソッドの__init__は具体的なStoreSalesCollectorまたはOnlineSalesCollectorの実装には依存しません。基本的にはBaseCollectorインターフェースに依存しています。
優れたML ETLの見た目はどのようなものですか?
前述の例では、オブジェクト指向のクラスを大いに活用して、ETLジョブにSOLID原則を適用する方法を示しました。しかし、ETLを構築する際に最適なコードフォーマットや標準については一般的な合意がありません。それは非常に異なる形態を取ることがあり、業界全体で共通の標準を見つけようとするよりも、内部でよくドキュメント化された主観的なフレームワークを持つことの方が問題です。
したがって、このセクションでは、ETLコードをより読みやすく、安全で信頼性のあるものにするための特性に焦点を当てて説明します。
コマンドラインアプリケーション
考えられるすべてのデータプロセスは基本的にコマンドラインアプリケーションです。PythonでETLを開発する際は、常にパラメータ化されたCLIインターフェースを提供しておくことで、どの場所からでも実行できるようにします(たとえば、Kubernetesクラスターの下で実行できるDockerコンテナなど)。argparse、click、typer、yaspin、docoptなど、コマンドライン引数の解析のために構築するツールはさまざまあります。Typerはおそらく最も柔軟で使いやすく、既存のコードに非侵襲的なツールです。これは有名なPythonウェブサービスライブラリであるFastApiの作者によって開発され、そのGithubのスターは増え続けています。ドキュメントも素晴らしく、徐々に業界標準になりつつあります。
from typer import Typerapp = Typer()@app.command()def run_etl( environment: str, start_date: str, end_date: str, threshold: int): ...
上記のコマンドを実行するには、次のようにします:
python {file_name}.py run-etl --environment dev --start-date 2023/01/01 --end-date 2023/01/31 --threshold 10
プロセス対データベースエンジンの計算トレードオフ
データウェアハウスの上にETLを構築する場合、できるだけ多くの計算処理をデータウェアハウスに押し込むことが一般的に推奨されます。これはデータウェアハウスエンジンが需要に応じて自動的にスケーリングする場合は問題ありません。しかし、それはすべての企業、状況、チームに当てはまるわけではありません。いくつかのMLクエリは非常に長く、クラスターを簡単にオーバーロードすることがあります。非常に異なるテーブルからデータを集約し、数年前のデータを参照し、ポイントインタイム節を実行することは一般的です。そのため、すべてをクラスターに押し込むことは常に最善の選択肢ではありません。プロセスインスタンスのメモリに計算を分離することは、一部の場合においてはより安全です。ビジネスクリティカルなクエリを破損または遅延させることなく、クラスターに影響を与えることなく、リスクフリーです。これは、Sparkユーザーにとっては明らかな状況です。スケールの大きさにより、すべての計算とデータは実行エグゼキュータ間に分散されます。ただし、RedshiftまたはBigQueryクラスターを使用している場合は常に、どれだけの計算量をそれらに委任できるかを注視してください。
出力の追跡
ML ETLはさまざまな種類の出力アーティファクトを生成します。HDFSのParquetファイル、S3のCSVファイル、データウェアハウスのテーブル、マッピングファイル、レポートなどがあります。これらのファイルは後でモデルのトレーニング、本番のデータのエンリッチ、オンラインのフィーチャーの取得などに使用することができます。
これはデータセットの構築ジョブとトレーニングジョブをアーティファクトの識別子を使用してリンクできるため非常に便利です。たとえば、Neptune track_files()メソッドを使用する場合、この種のファイルを追跡できます。ここで使用できる非常に明確な例があります。
自動的なバックフィリングの実装
前日のデータを取得してモデルのトレーニングに使用するための特徴量を計算する日次ETLがあると想像してください。何らかの理由でETLが1日実行されなかった場合、次の日に実行された場合、前日に計算されたデータは失われてしまいます。
これを解決するためには、宛先テーブルやファイル内の最後に登録されたタイムスタンプを確認することが良い実践です。その後、ETLは遅れている2日間のために実行されます。
疎結合なコンポーネントの開発
コードは変更に非常に影響を受けやすく、データに依存するプロセスはさらに脆弱です。テーブルを構築するイベントは進化する可能性があり、列が変わる可能性やサイズが増加する可能性があります。異なる情報源に依存するETLがある場合は常にそれらをコード内で分離することが良いです。なぜなら、いつでも両方のコンポーネントを別々のタスクとして分離する必要がある場合(例:データが増えたので処理を実行するためにより大きなインスタンスタイプが必要な場合)は、コードがスパゲッティでない場合にはるかに簡単にできるからです!
ETLを冪等にする
ソースのテーブルやプロセス自体に問題があった場合、同じプロセスを複数回実行するのは典型的です。重複したデータ出力や半分だけ埋まったテーブルを生成しないために、ETLは冪等であるべきです。つまり、同じ条件で同じETLを2回実行しても、最初の実行時の出力や副作用が影響を受けるべきではありません(参照)。これをETLに強制するために、削除-書き込みパターンを適用することで、パイプラインは新しいデータを書き込む前に既存のデータをまず削除します。
ETLのコードを簡潔に保つ
実装コードとビジネス/論理レイヤーを明確に分離することが常に好ましいです。ETLを構築する際、最初のレイヤーはデータに何が起こっているかを明確に述べる手順(関数またはメソッド)の連続として読むべきです。多層の抽象化は悪いことではありません。これは、ETLを数年間メンテナンスする必要がある場合に非常に役立ちます。
高レベルの関数と低レベルの関数を常にお互いに分離してください。以下のようなものを見つけるのは非常に奇妙です:
from config import CONVERSION_FACTORSdef transform_data(data: pd.DataFrame) -> pd.DataFrame: data = remove_duplicates(data=data) data = encode_categorical_columns(data=data) data["price_dollars"] = data["price_euros"] * CONVERSION_FACTORS["dollar-euro"] data["price_pounds"] = data["price_euros"] * CONVERSION_FACTORS["pound-euro"] return data
上記の例では、「remove_duplicates」と「encode_categorical_columns」という高レベルの関数を使用していますが、同時に価格を変換する実装操作を明示的に示しています。これらの2つの行のコードを削除し、「convert_prices」関数で置き換えるのは素敵ではありませんか?
from config import CONVERSION_FACTORdef transform_data(data: pd.DataFrame) -> pd.DataFrame: data = remove_duplicates(data=data) data = encode_categorical_columns(data=data) data = convert_prices(data=data) return data
この例では読みやすさには問題ありませんが、代わりに「transform_data」に5行の長いgroupby操作を埋め込んで「remove_duplicates」と「encode_categorical_columns」と組み合わせた場合を想像してください。どちらの場合でも、高レベルと低レベルの関数を混在させます。包括的なレイヤードコードを維持することは非常に推奨されます。関数やモジュールを100%包括的にレイヤードすることは不可能であり、過剰に工学的な場合もありますが、それを追求することは非常に有益な目標です。
純粋関数を使用する
副作用やグローバルなステートをETLを複雑にすることはありません。純粋関数は、同じ引数が渡される場合には常に同じ結果を返します。
❌以下の関数は純粋ではありません。外部ソースから読み込まれた他の関数と結合されたデータフレームを渡しています。これは、テーブルが変更される可能性があるため、同じ引数で関数を呼び出すたびに異なるデータフレームが返される可能性があります。
def transform_data(data: pd.DataFrame) -> pd.DataFrame: reference_data = read_reference_data(table="public.references") data = data.join(reference_data, on="ref_id") return data
この関数を純粋なものにするためには、次のようにする必要があります:
def transform_data(data: pd.DataFrame, reference_data: pd.DataFrame) -> pd.DataFrame: data = data.join(reference_data, on="ref_id") return data
このようにすることで、同じ「data」と「reference_data」の引数を渡すと、関数は同じ結果を返します。
この例は簡単ですが、私たちはもっとひどい状況を目の当たりにしてきました。グローバルな状態変数に依存する関数、特定の条件に基づいてクラス属性の状態を変更するメソッド、他の今後のETLのメソッドの振る舞いを変える可能性のあるメソッドなど。
純粋な関数の使用を最大限にすることは、より機能的なETLを実現することにつながります。前述のポイントで既に議論したように、多くの利点があります。
できるだけパラメータ化する
ETLは変化します。それは私たちが受け入れなければならないものです。ソーステーブルの定義が変わったり、ビジネスルールが変わったり、望ましい結果が変わったり、実験が洗練されたり、MLモデルがより洗練された特徴を必要としたりします。
ETLの柔軟性を保つために、ETLのパラメータ指向実行を提供するためにどこに最も労力を注ぐかを徹底的に評価する必要があります。パラメータ化とは、シンプルなインターフェースを介してパラメータを変更するだけで、プロセスの振る舞いを変えることができる特徴です。インターフェースはYAMLファイル、クラスの初期化メソッド、関数の引数、またはCLI引数である場合があります。
シンプルで明快なパラメータ化は、「環境」または「ステージ」をETLの定義に含めることです。プロダクション環境でETLを実行する前に、そのプロセスやシステムに影響を与える可能性のあるものをテストするために、「テスト」、「統合」、または「開発」の独立した環境を準備することが重要です。その環境には、異なるレベルの分離が含まれる場合もあります。実行基盤(本番のインスタンスから分離された開発インスタンス)、オブジェクトストレージ、データウェアハウス、データソースなどが含まれます。
これは明らかなパラメータであり、おそらく最も重要なものです。しかし、ビジネス関連の引数にもパラメータを拡張することができます。実行するETLのウィンドウ日付、変更または洗練される可能性のある列名、データ型、フィルタリング値などをパラメータ化することができます。
適度なログの作成
これは、ETLの最も過小評価される特性の1つです。ログは、本番実行の異常や暗黙のバグの検出、またはデータセットの説明に役立ちます。抽出したデータに関する情報をログに記録することは常に便利です。コード内のバリデーション以外に、次のようなことも記録できます:
- ソーステーブル、API、または出力パスへの参照(例:「`item_clicks` テーブルからデータを取得」)
- 期待されるスキーマの変更(例:「 `promotion` テーブルに新しい列があります」)
- フェッチされた行の数(例:「 `item_clicks` テーブルから145234093行を取得しました」)
- 重要な列のnull値の数(例:「ソース列に125個のnull値を検出しました」)
- データの単純な統計情報(平均、標準偏差など)(例:「CTR 平均: 0.13、CTR 標準偏差: 0.40」)
- カテゴリ列の一意の値(例:「Country 列に ‘Spain’、’France’、’Italy’ が含まれています」)
- 重複行の数(例:「重複した行を1400行削除しました」)
- 計算集約処理の実行時間(例:「集計に560秒かかりました」)
- ETLの異なるステージの完了チェックポイント(例:「Enrichment プロセスが正常に終了しました」)
Manuel Martín は、データサイエンスの専門知識を持つエンジニアリングマネージャーです。彼は以前、データサイエンティストや機械学習エンジニアとして働いており、現在はBusuuでML/AIの実践をリードしています。
[マヌエル・マルティン](https://www.linkedin.com/in/manuelmart%C3%ADn11/)はデータサイエンスの専門知識を持つエンジニアリングマネージャーで、6年以上の経験があります。彼は以前、データサイエンティストおよび機械学習エンジニアとして働いていましたが、現在はBusuuでML/AIの実践をリードしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
