「より良い機械学習システムの構築 – 第3章:モデリング楽しみが始まります」
Building Better Machine Learning Systems - Chapter 3 Modeling Begins
ベースライン、実験の追跡、適切なテストセット、およびメトリクスについて。 アルゴリズムを機能させることについて。
こんにちは。ここでまたお会いできてうれしいです。あなたがもっと良いプロフェッショナルになりたい、より良い仕事をしたい、そしてより良いMLシステムを構築したいというあなたの意欲を本当に感謝しています。あなたはすごいです、頑張ってください!
このシリーズでは、機械学習システムの設計と構築の芸術、科学、そして(時には)魔法をマスターするために最善を尽くします。ここでは、ビジネス価値と要件、データ収集とラベリング、モデル開発、実験の追跡、オンラインとオフラインの評価、展開、モニタリング、再トレーニングなどについて話します。
これは第3章であり、モデル開発に捧げられています。MLアルゴリズムはMLシステムのごく一部です。完全に正確なアルゴリズムでも、設計がよく考えられていなければ、顧客に役立たず、会社に利益をもたらしません。この投稿では、MLアルゴリズムの概要ではなく、アルゴリズムの主な目標はビジネスに価値をもたらすことであることを念頭において、アルゴリズムを選択し、開発し、評価する方法を紹介します。そして、結局のところ、ビジネスの問題を線形回帰で解決したのか、最も先進的なニューラルネットワークで解決したのかはあまり重要ではありません。
次に進む前に、すでに学んだことを簡単に振り返ってみましょう。
- ChatGPTのためのエニグマ:PUMAは、LLM推論のための高速かつ安全なAIアプローチを提案するものです
- 「読むアバター:リアルな感情制御可能な音声駆動のアバター」
- 感情の解読:EmoTXによる感情と心の状態の明らかにする、新しいTransformer-Powered AIフレームワーク
最初の章は計画についてでした。MLシステムはアドホックな方法で実装するには複雑すぎるため、すべてのプロジェクトは計画から始まる必要があります。MLプロジェクトのライフサイクルを見直し、プロジェクトのビジネス価値をなぜどのように見積もるか、要件を収集する方法、そして冷静な気持ちでMLが本当に必要かどうかを再評価する方法について説明しました。私たちは「PoC」と「MVP」という概念を使用して、少ないリソースで始めて、失敗を早く経験する方法を学びました。最後に、計画段階での設計ドキュメントの重要性について話しました。
2番目の章はデータについてでした。データ中心のAIという業界の新しいトレンドについて説明しました。これは、クリーンなデータが先進的なMLアルゴリズムよりもはるかに重要であると考えるMLシステムの構築手法です。データパイプラインに触れ、混沌で非構造化のデータの流れを整理し、データを分析に使用できるようにするための設計方法について説明しました。トレーニングデータは関連性があり、均一であり、代表的であり、包括的である必要があります。モデルはこのデータに基づいて世界の理解を構築します。人間のラベルと自然のラベルの2つのタイプのラベルについて説明し、人間のラベルを取得するための複雑で遅くて高価なプロセスを進める方法と、このプロセスを少しでも痛みの少ないものにするためのベストプラクティスについて話しました。最後に、リアルデータと人間のラベリングの代替手段である合成データについても話しました。
もし前の投稿を見逃してしまった場合は、進む前にそれらを読むことをおすすめします。ここでお待ちしています。
さあ、楽しんでください。
どのMLアルゴリズムを選択するか
すべての問題に適合するアルゴリズムはありません。いくつかのアプローチを試し、データと領域を本当によく理解するまで学んで、うまく機能するものを見つける必要があります。
考え、ブレインストーミングし、同僚と話し、ChatGPTに質問し、それから試すアプローチを3つ書き留めてください:1)非常にシンプルなもの、2)非常に人気のあるもの、3)新しくてクリエイティブなもの。
- 非常にシンプルなもの。アルゴリズムに導入されるすべての複雑さは正当化される必要があります。シンプルなアプローチ(おそらく非ML)から始めて、評価し、他のすべてのモデルと比較するためのベースラインとして使用します。
- 非常に人気のあるもの。多くの人々が特定のアルゴリズムで同じビジネスタスクを解決していると見聞きしましたら、実験リストに追加してください。集合知を活用しましょう!私は常に人気のあるアプローチに対して非常に期待しており、ほとんどの場合、それらは非常にうまく機能します。
- 新しくてクリエイティブなもの。試してみてください。典型的な人気のあるアプローチを打ち負かすことで、競争上の優位性を構築すると、上司と会社は喜びます。
警告: ホイールの再発明はしないでください。ほとんどのアルゴリズム、データサンプリング戦略、またはトレーニングループには、すでに実装された多数のオープンソースのライブラリやリポジトリがあります。独自のK-meansクラスタリングを作成しないでください — scikit-learnから使ってください。スクラッチからResNet50を作成しないでください — PyTorchから使ってください。最近の論文を実装する前に、PapersWithCodeをチェックしてください。誰かがもうやっているかもしれません。
研究を行い、新しいものを発明することはエキサイティングです。すべての行を理解できるスクラッチからのアルゴリズムの実装は魅力的です。ただし、研究は大学やビッグテック企業にしか適していません。スタートアップにとっては、1つの成功に対して100回の試行が必要なため、成功の確率が低いものに投資する余裕はありません。
「最先端」という言葉には注意してください。例えば、YOLOv7を使用して物体検出を行っているところで、YOLOv8がリリースされ、さらに優れていると聞くとどうでしょうか。それはすべてのプロダクションパイプラインをYOLOv8に対応させる必要があるということを意味しますか?必ずしもそうではありません。
ほとんどの場合、「より良い」とは、COCOなどの静的なベンチマークデータセットに対して1〜2%の改善を意味します。あなたのデータのモデルの精度は、あなたのデータとビジネスの問題がすべて異なるため、より良くなるか、無視できるほどの改善がないか、あるいは悪くなる場合があります。また、このシリーズの第2章から覚えておくべきことは、アルゴリズムを改善するよりもデータを改善する方がモデルの精度がより大幅に向上するということです。トレーニングデータのクリーニング方法を考え出してみてください — そうすれば5〜10%の精度向上が見られるでしょう。
機械学習アルゴリズムの開発方法
まず、ベースラインを取得してください。ベースラインとは、競争するモデルのことです。ベースラインのための2つの論理的な選択肢があります:
- 既存のモデル(もしあれば)から。既存のモデルを改善したいので、それと比較する必要があります。
- 展開しやすい非常にシンプルなモデル。ビジネスのタスクが簡単な方法で解決できる場合、複雑なモデルをトレーニングする必要はありません。数日間、簡単な解決策を探し、実装することに時間を割いてください。
そして、実験が始まります。ベースラインを改善するために、すべての実験を行います。有望なアルゴリズムを見つけましたか?素晴らしいです、それを評価し、ベースラインと比較してください。モデルが優れていますか?おめでとうございます、それが新しいベースラインになります。さらに改善するための実験のアイデアを考えてみてください。
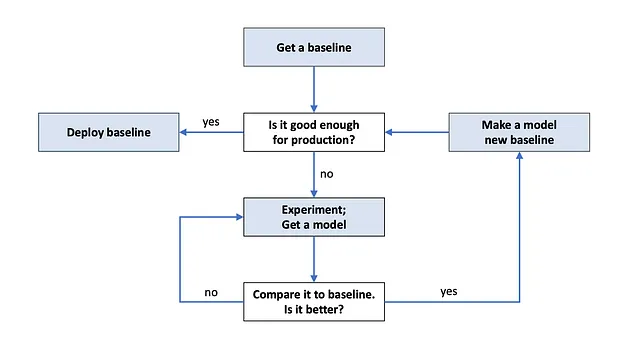
アルゴリズムの開発は反復的なプロセスです。プロダクションに十分なアルゴリズムが見つかるか、時間切れになるまで続けます。どちらのシナリオも可能です。
当然、試してみるアイデアのほとんどは失敗します。だから悲観する必要はありませんし、個人的に受け取る必要もありません。私たちは皆、そのように働いています: 良いアイデアを見つけ、試してみて、アイデアが実際には悪いことがわかり、新しい、うまくいくかもしれないアイデアを思いつけるようになり、それを試してみて、それもうまくいかないことがわかり、新しいアイデアを見つける…
ここでのアドバイス: 1つのアイデアに費やす時間を時間枠で設定してください。N日(事前にNを選んでください)以内にアイデアがうまくいかない場合は、それを終了し、別のアイデアに移ってください。本当に成功したいのであれば、多くの異なるアイデアを試す必要があります。前述したように、ほとんどの試みは失敗するからです。
データを非常によく理解してください。サンプルとラベルを可視化し、特徴の分布をプロットし、特徴の意味を理解してください。各クラスからのサンプルを探索し、データの収集戦略を理解し、アノテーターに与えられたデータラベリングの指示を読んでください。モデルが予測することを期待されるものを予測するように自分自身を訓練してください。良いアルゴリズムを作成したいのであれば、アルゴリズムのように考えることから始めましょう(冗談ではありません)。これらすべてが、データの問題を見つけ、モデルをデバッグし、実験のアイデアを思いつくのに役立ちます。
データをトレーニング、検証、テストのパートに分割してください。トレーニングセットでトレーニングし、検証セットでハイパーパラメータを選択し、テストセットで評価してください。分割間にオーバーラップやデータリークがないことを確認してください。詳細は、Jacob Solawetzによる「機械学習のためのトレーニング、検証、テストの分割」の記事を参照してください。
進め方:オープンソースモデルを使用し、デフォルトパラメータで実行し、ハイパーパラメータのチューニングを行います。scikit-learn、PyTorch、OpenCVなどのMLライブラリ、またはGitHubリポジトリからアルゴリズムを使用してください。GitHubリポジトリは、多くのスター、良いREADME、商用利用を許可するライセンスを持っているものを選びましょう。デフォルトのハイパーパラメータでデータをトレーニングし、評価します。アルゴリズムのデフォルトのハイパーパラメータは、ベンチマークデータセット(ImageNet、COCO)での精度を最大化するように選択されています。そのため、ほとんどの場合、データやタスクには適していません。各ハイパーパラメータが意味するものとトレーニング/推論にどのように影響するかを十分に理解し、ハイパーパラメータの最適化を行いましょう。ハイパーパラメータの最適化には、Grad Student Descent、ランダム/グリッド/ベイジアンサーチ、進化アルゴリズムなどの一般的な手法があります。ハイパーパラメータの最適化を行う前に、アルゴリズムが機能しないと言わないでください。詳細については、Pier Paolo Ippolitoによるこの記事をご覧ください:ハイパーパラメータの最適化。
さらにデータを活用しましょう:特徴エンジニアリングとデータ拡張を行います。 特徴エンジニアリングは既存の特徴量を変換し、新しい特徴量を作成することを指します。特徴エンジニアリングは重要なスキルですので、以下の2つの素晴らしい記事を参照してください:- Emre Rençberoğluによる機械学習のための特徴エンジニアリングの基本的な技術- Maarten Grootendorstによる高度な特徴エンジニアリングと前処理のための4つのヒント
データ拡張は、持っているデータから新しいトレーニングサンプルを作成する技術です。トレーニングセットを増やすことは、モデルの精度を向上させる最も簡単な方法ですので、できるだけ常にデータ拡張を行いましょう。例えば、コンピュータビジョンの領域では、基本的なイメージ拡張(回転、スケーリング、クロッピング、反転など)なしでモデルをトレーニングする人はほとんどいません。詳細については、以下の記事をご覧ください:コンピュータビジョンのためのデータ拡張の完全ガイド。
もし自然言語処理のための拡張方法に興味があるならば、Shahul ESによる「Data Augmentation in NLP: Best Practices From a Kaggle Master」を読んでみてください。
転移学習はあなたの味方です。ゼロショット学習はあなたの最良の仲間です。 転移学習はモデルの精度を向上させる人気のある技術です。実際には、あるデータセットで事前トレーニングされたモデルを取り、そのデータを使用してトレーニングを続けることを意味します(「知識の転送」)。COCOやImageNetのデータセットからの重みも、COCO/ImageNetの画像とは異なるようなデータであってもモデルを改善することができます。
ゼロショット学習とは、トレーニングなしでデータに適用されるアルゴリズムのことです。どのようにして?通常、これは巨大な数十億のサンプルデータセットで事前トレーニングされたモデルです。あなたのデータがこのモデルで既にトレーニングされたものに似ている場合、そしてそのモデルが多くのサンプルを「見た」ことがあるため、新しいデータに対しても一般化することができます。ゼロショット学習は夢のように聞こえるかもしれませんが、いくつかのスーパーモデルがあります:Segment Anything、ほとんどのワードエンベディングモデル、ChatGPTなど。
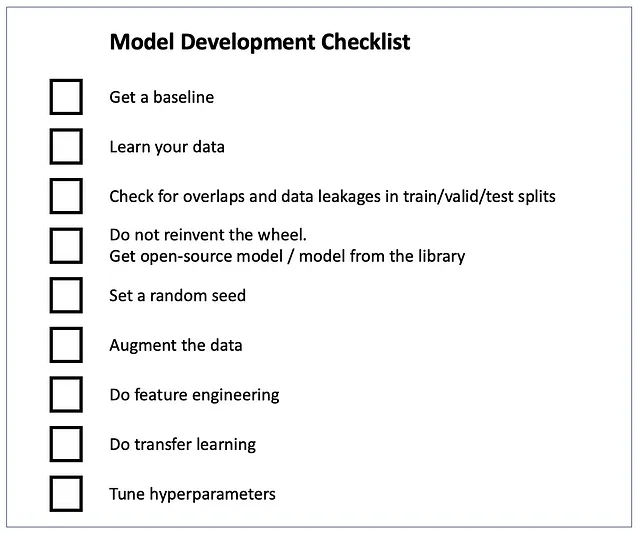
モデル開発についてはまだ話すべきことがたくさんありますが、実験トラッキングと評価のトピックのために時間を確保する必要があります。もしまだ知識を得たくてたまらない場合は、Andrej Karpathyによるこの素晴らしい記事をご覧ください:ニューラルネットワークのトレーニングレシピ。
実験トラッキング
実験トラッキングは、実験に関する情報をダッシュボードやファイルに保存し、将来的にそれを確認できるようにするプロセスです。ソフトウェア開発におけるログ記録のようなものです。トレーニングデータセットとテストデータセットへのリンク、ハイパーパラメータ、gitのハッシュ、テストデータのメトリックなどが、トラックする可能性のある例です。
実行したすべての実験をトラックする必要があります。何らかの理由でチームがそれを行っていない場合は、重要性についてチームで話し合うためのチームミーティングを今すぐ設定してください。後で私に感謝するでしょう 🙂
では、なぜ実験トラッキングを行うのでしょうか?
- 異なる実験を比較するため。モデルを開発する際には、さまざまなアルゴリズムをトレーニングし、評価し、さまざまなデータ前処理技術を試し、さまざまなハイパーパラメータを使用し、さまざまなクリエイティブなトリックを考案します。一日の終わりに、試したこと、うまくいったこと、最高の精度を出したことを知りたいと思うでしょう。後である実験に戻って、その結果を新鮮な気持ちで確認したいかもしれません。モデルの開発には数週間、数か月かかる場合がありますので、適切な実験トラッキングがないと、何を行ったかを簡単に忘れてしまい、実験をやり直さなければなりません。
- 実験を再現するため。再現できない実験はカウントされません。自分自身をチェックしてください:最も成功した実験に戻り、それを再実行して同じ精度を得ることができますか?もし「NO」と答えるのであれば、コードとデータのバージョン管理を行っていない、すべてのハイパーパラメータを保存していない、またはランダムシードを設定していない可能性があります。ランダムシードの設定の重要性については、Cecelia Shaoの記事「Properly Setting the Random Seed in ML Experiments. Not as Simple as You Might Imagine.」で詳しく説明されています。
- 実験のデバッグ。実験がうまくいかないこともあります:アルゴリズムが収束しない、予測が奇妙になる、精度がランダムに近いなど。情報が保存されていない場合、なぜ失敗したのかを理解することは実質的に不可能です。保存されたハイパーパラメータのリスト、サンプルと拡張の可視化、損失グラフなどは、問題がどこにあるかの手がかりを与えてくれ
今や実験の追跡が重要であることに納得したので、実際にどうやって行うかについて話しましょう。
無料または有料の実験追跡ツールは数多く存在していますので、要件と予算に合ったものを選びましょう。おそらく最も人気のあるツールはWeights&Biasesです。私はこれをよく使っていて、使いやすいです。他のツールのレビューについては、Patrycja Jenknerによる「ML実験の追跡と管理に最適な15のベストツール」をチェックしてください。
機械学習の実験はデータ、コード、およびハイパーパラメーターで構成されます。コードにはGithubやGitlabなどのバージョン管理ツールを使用して、開発中のすべての変更をコミットするようにしてください。以前のコードバージョンに戻って古い実験を再実行できるようにすることは重要です。データもバージョン管理しましょう。最もシンプルで一般的な方法は、各データセットの新しいバージョンごとに新しいフォルダまたはファイルを作成することです(理想的にはAmazon S3やGoogle Cloud Storageなどのクラウドストレージ上)。Data Version Control(DVC)というツールを使用する人もいます。
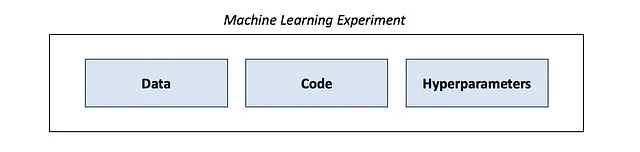
実験のために具体的に何を追跡すべきですか? 実験が失敗し、かなりの困難がある場合を除いて、私たちはほとんどの時間、その情報を使用しませんので、できるだけすべてを追跡することは悪い考えではありません :)
以下は、追跡を考慮する必要がある項目のリストです:
- コミットのGitハッシュ
- トレーニング、検証、テストデータセットへのリンク
- ハイパーパラメーターとその変化(モデルアーキテクチャ、学習率、バッチサイズ、データ拡張など)
- トレーニングセットと検証セットの損失プロット
- トレーニングセットと検証セットのメトリクスプロット
- テストセットのメトリクス
- ラベル付きトレーニングサンプルの視覚化(拡張を適用した場合と適用しない場合の両方)
- テストセットのエラーの視覚化
- 環境(OS、CUDAバージョン、パッケージバージョン、環境変数)
- トレーニング速度、メモリ使用量、CPU/GPU利用率
一度実験の追跡を設定し、その恩恵を永遠に享受しましょう。
モデル評価
モデルを本番環境に展開する前に、徹底的に評価する必要があります。この評価は「オフライン」と呼ばれます。対照的に、「オンライン」評価は既に本番環境で稼働しているモデルをチェックすることです。オンライン評価については、このシリーズの次の章で議論しますが、今日はオフライン評価に焦点を当てます。
オフライン評価を行うためには、メトリックとデータセットが必要です。
モデルはテストデータセット上で評価されます。つまり、トレーニングやハイパーパラメーターの調整中に取り分けておいたデータセットです。以下の仮定がされています:1)テストセットは十分に大きく、非常にクリーンであること、2)モデルがテストデータを見たことがないこと、3)テストデータが本番データを表していること。これらの仮定のいずれかが破られると、評価が誤って実行され、悪いモデルが展開されるリスクが高まります。
小さなテストセットでの評価は単に偶然によって良いメトリックを示す可能性があります。汚れたデータでの評価は真のモデルの性能を示しません。トレーニングセットでのエラーは許容範囲が広いですが(クリーンなラベル、汚れたラベル、ラベルがない場合などでトレーニングできます)、テストセットでのエラーは重大な問題となります。重要な注意点:教師なしモデルにもラベル付きのテストセットが必要です。そうしないと、モデルが十分に良いかどうかをどのように知ることができるでしょうか?
モデルがテストデータを「見た」ことがないことを確認してください。重複を除外して、同じサンプルがトレーニングセットとテストセットの両方に含まれないようにしてください。データをランダムに分割せず、時間ベースまたはユーザーベースの分割を使用してください。時間ベースの分割は、古いデータをトレーニングセットに配置し、新しいデータをテストセットに配置することを意味します。ユーザーベースの分割は、同じユーザーのすべてのデータを同じ分割内に含めることを意味します。また、データリークには非常に注意してください。詳細は、Prerna Singhによる「機械学習におけるデータリーク:検出とリスクの最小化」を参照してください。
メトリックは、モデルの真のパフォーマンスと相関すると仮定される数値です:数値が高いほどモデルが良いです。1つまたは複数のメトリックを選択できます。たとえば、分類タスクの典型的なメトリックは正確度、適合率、再現率、F1スコアです。非テクニカルなマネージャーやクライアントも理解できるように、シンプルで理解可能なものを選んでください。
以下は、Shervin Minaeeによるさまざまなタスクと領域のメトリクスに関する素晴らしい記事です。- 20人気のある機械学習のメトリクス。パート1:分類および回帰評価メトリクス- 20人気のある機械学習のメトリクス。パート2:ランキング、および統計メトリクス
スライスベースのメトリクスを使用し、考えられるすべてのデータセグメントでモデルを評価してください(「Zoomのバーチャル背景機能は黒人の顔に対応していません」というようなスキャンダルに巻き込まれたくない場合)。たとえば、顔検出システムは、異なる人種、性別、年齢の人々ごとに個別に評価する必要があります。Eコマースモデルは、デスクトップとモバイル、さまざまな国、およびブラウザで評価する価値があります。各セグメントがテストセットで十分に表現されているかどうかを再確認してください。スライスベースのメトリクスはクラスの不均衡にも役立ちます:各クラスごとの精度と再現率を個別に見ることは、総合的な精度/再現率よりもはるかに役立ちます。
スキャンダルを回避するもう1つの方法(今回は「Bank ABCの新しい信用スコアリングシステムが未婚の女性に差別的」というものです)は、行動テストを使用することです。優れた論文である「精度以外:CheckListを使用したNLPモデルの行動テスト」は、数値メトリクスに加えて、最小機能、不変性、および方向性期待テストの使用を提案しています。この論文は自然言語処理に焦点を当てていますが、これらのタイプのテストは表形式のデータや画像にも簡単に適用できます。
「Bank ABCの新しい信用スコアリングシステムが未婚の女性に差別的である」という例では、不変性の行動テストが非常に役立ちます。すべての特徴を同じに保ちながら、婚姻状況と性別を変更し、モデルの予測が変化するかどうかを確認します。予測に大きな違いが見られる場合(「不変性」であるべき場合)、おそらくモデルはトレーニングデータにバイアスを吸収しているため、これを修正する必要があります。たとえば、モデルへの入力から機密(差別的な傾向がある)の特徴を完全に削除することによって。
最後に、エラーを可視化してください。モデルがエラーを起こしたテストセットのサンプルを見つけ、それらを可視化してなぜこれが起こったのかを分析します。それはテストセットがまだ汚れているからですか?トレーニングセットに十分な類似のサンプルがありますか?モデルのエラーにはパターンがありますか?この分析は、テストセットの可能性のあるラベリングエラーやトレーニング中のバグを見つけるのに役立ちます。さらに、モデルの性能をさらに向上させるためのアイデアを考え出すのにも役立ちます。

結論
この章では、MLアルゴリズムがMLシステムの一部にすぎないことを念頭に置いてモデルを開発する方法を学びました。モデルの開発は、シンプルなベースラインモデルの作成から始まり、それに対する反復的な改善を続けます。効率的な進め方を見つけるために、オープンソースのモデルを取り上げ、それを中心に実験を構築することを選びました。車輪の再発明や研究の迷路に陥ることを避けるためです。また、「最先端」のアルゴリズムの落とし穴やデータ拡張と転移学習の利点についても議論しました。実験の追跡の重要性に合意し、それを設定する方法も学びました。そして最後に、オフライン評価について話しました-メトリックの選択、適切なテストセット、スライスベースの評価、および行動テスト。
ほとんど終わりです、あと1つの章が残っています。次の(最後の)投稿では、展開、モニタリング、オンライン評価、再学習について学びます-それはあなたがより良い機械学習システムを構築するのに役立つ知識の最後のピースです。
フィナーレは近日公開予定です。お楽しみに。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




