「検索補完生成を用いてより能力の高いLLMを構築する」
Building a more capable LLM using search completion generation.
リトリーバル増強生成による知識ベースの統合により、LLMを強化する方法

ChatGPTの制約事項
コード生成以外の実用的なビジネスユースケースでは、ChatGPTには制約があります。この制約は、トレーニングデータとモデルの幻覚傾向から生じます。執筆時点では、Chat-GPTに2021年9月以降のイベントに関する質問をすると、おそらく次のような回答が返ってきます:
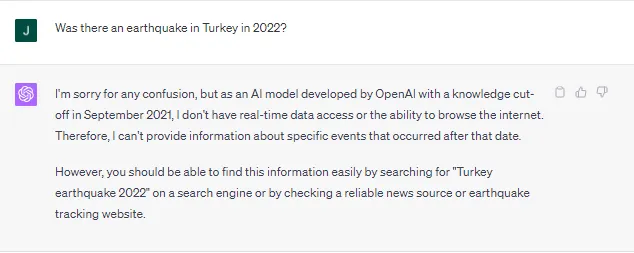
これは役に立たないので、どのように修正すればよいでしょうか?
オプション1 – 最新のデータでモデルをトレーニングまたはファインチューニングする。
モデルのファインチューニングやトレーニングは実用的ではなく、高額です。コストを置いておいても、データセットを準備するために必要な努力はこのオプションを選ばない理由となります。
オプション2 – リトリーバル増強生成(RAG)メソッドの使用。
RAGメソッドを使用することで、大規模言語モデルに最新の知識ベースへのアクセス権を与えることができます。これは、モデルをゼロからトレーニングするかファインチューニングするよりもはるかに安価で、実装も簡単です。この記事では、OpenAIモデルとRAGを利用する方法を紹介します。Wikipediaの知識ベースから2022年のロシア・ウクライナ紛争に関する質問に対するモデルの能力を短い分析を行うことで試してみます。
注意:このトピックは敏感なものですが、現在のChatGPTモデルには関連知識がないため、選ばれました。
ライブラリと前提条件
OpenAIのAPIキーが必要です。直接ウェブサイトから取得するか、このチュートリアルに従ってください。RAGに使用されるフレームワークはDeepsetのHaystackで、オープンソースです。彼らは大規模言語モデルの上でアプリケーションを構築するためのAPIを提供しています。また、Hugging Faceのsentence transformersとtransformersライブラリも利用しています。
文の埋め込みはモデルがテキストを解釈するのに役立ちます
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- PyTorch Lightningを使用して、ゼロからCNNを実装してトレーニングする
- 「AIが航空会社のコントレイルによる気候への影響を軽減するのに役立っている方法」
- 「Swift Transformersのリリース:AppleデバイスでのオンデバイスLLMsの実行」
- 「DPOを使用してLlama 2を微調整する」
- 「DENZAはWPPと協力し、NVIDIA Omniverse Cloud上で高度な車両設定ツールを構築・展開する」
- 「NVIDIA Studio内のコンテンツ作成が、新しいプロフェッショナルGPU、AIツール、OmniverseおよびOpenUSDの共同作業機能によって向上します」
- 「NVIDIAは、エンタープライズや開発者向けに拡張現実(Extended-Reality)ストリーミングをよりスケーラブルでカスタマイズ可能にする」






