AIを活用した言語学習アプリの構築:2つのAIチャットからの学習
Building a language learning app using AI Learning from two AI chats.
Langchain、OpenAI、gTTS、およびStreamlitを使用してデュアルチャットボット言語学習アプリを作成するステップバイステップチュートリアル

新しい言語を学び始めたばかりのとき、私は「会話ダイアログ」の本を買うのが好きです。これらの本は、文法や語彙だけでなく、日常生活での人々の実際の使い方も理解するのに役立つので、とても役立つと思います。
今、大規模言語モデル(LLM)の台頭に伴い、私は思いつきました。LLMを活用して、よりインタラクティブでダイナミックでスケーラブルな形式でこれらの言語学習の本を再現できるでしょうか?言語学習者向けに新鮮でオンデマンドの会話を生成するツールを作成することはできるでしょうか?
この考えは、本日共有したいプロジェクトのインスピレーションとなりました。AIパワードの言語学習アプリであり、学習者は、ユーザーが定義した「会話」と「議論」のどちらかに参加する2つのAIチャットボットから学ぶことができます。
使用されたテックスタックについては、Langchain、OpenAI API、gTTS、およびStreamlitを使用して、ユーザーが役割、シナリオ、または議論のトピックを定義し、AIにコンテンツを生成させるアプリケーションを作成しました。
- これをデジタルパペットにしてください:GenMMは、単一の例を使用して動きを合成できるAIモデルです
- LLMの巨人たちの戦い:Google PaLM 2 vs OpenAI GPT-3.5
- Video-ControlNetを紹介します:コントロール可能なビデオ生成の未来を形作る革新的なテキストからビデオへの拡散モデル
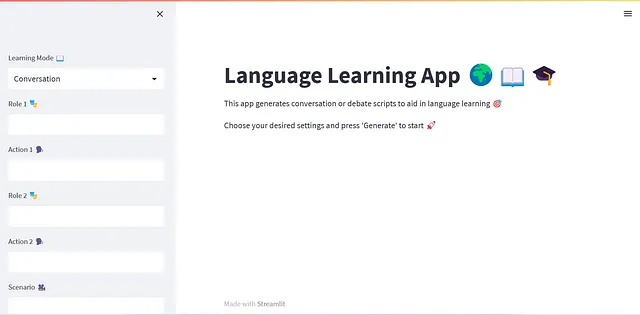
開発された言語学習アプリのデモ。 (著者による画像)
それがどのように機能するかに興味がある場合は、ステップバイステップでこのインタラクティブなデュアルチャットボットシステムの構築の旅に私と一緒に参加してください🗺️📍🚶♀️。
完全なソースコードはこちらから見つけることができます💻。このブログでは、アイデアを説明するための主要なコードスニペットを説明します。
それでは、始めましょう!
目次 · 1. プロジェクトの概要 · 2. 前提条件 ∘ 2.1 LangChain ∘ 2.2 ConversationChain · 3. プロジェクトのデザイン ∘ 3.1 シングルチャットボットの開発 ∘ 3.2 デュアルチャットボットシステムの開発 · 4. Streamlitでのアプリインターフェースデザイン · 5. 学習と将来の拡張 · 6. 結論
1. プロジェクトの概要
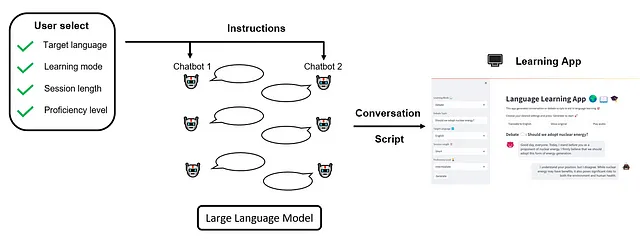
前述のように、私たちの目標は、2つの会話AIまたはチャットボットで動作するユニークな言語学習アプリを作成することです。このアプリの革新的な側面は、これらのチャットボットがお互いに相互作用し、目標言語で現実的な対話を作成することにあります。ユーザーはこれらのAIによる会話を観察し、言語学習リソースとして使用し、選択した言語の実際の使用方法を理解することができます。
私たちのアプリでは、ユーザーは必要に応じて学習体験をカスタマイズできる柔軟性が必要です。対象言語、学習モード、セッションの長さ、および熟練度レベルなど、複数の設定を調整できます。
対象言語 🔤
ユーザーは学びたい言語を選択できます。この選択は、チャットボットが相互作用する際に使用される言語を指示します。現時点では、英語—「en」、ドイツ語—「de」、スペイン語—「es」、およびフランス語—「fr」のサポートが含まれていますが、GPTモデルがそれらについて十分な知識を持っている限り、より多くの言語を追加することは簡単です。
学習モード 📖
この設定により、ユーザーはチャットボット間の会話のスタイルを選択できます。 「会話」モードでは、ユーザーは各ボットの「役割」(例:顧客とウェイトスタッフ)と「アクション」(注文食品と注文を受ける)を定義し、「シナリオ」(レストランで)を指定することで、ボットは現実的な会話をシミュレートします。 「ディベート」モードでは、ユーザーはディベートの「トピック」(原子力エネルギーを採用すべきか)を入力するよう促されます。ボットは提供されたトピックに関して活発な議論を行います。
アプリのインターフェースは、ユーザーが選択した学習モードに基づいてダイナミックに調整され、シームレスなユーザーエクスペリエンスを提供します。
セッション長さ ⏰
セッション長さの設定により、ユーザーは各チャットボット会話または議論の期間を制御できます。これにより、ユーザーは短い、迅速な対話またはより長く、より詳細な議論を好みに応じて行うことができます。
熟練度レベル 🏆
この設定は、チャットボット会話の複雑さをユーザーの言語スキルレベルに合わせて調整します。初心者はより単純な会話を好むかもしれませんが、より上級の学習者は複雑な議論や会話を扱うことができます。
ユーザーがこれらの設定を指定した後、セッションを開始し、AIチャットボットがユーザーの好みに応じてダイナミックでインタラクティブな対話を実行するのを見ることができます。私たちの全体的なワークフローは以下のように表されます:
2. 前提条件
アプリを開発する前に使用するツールを理解しましょう。このセクションでは、LangChainライブラリ、特に私たちのアプリのバックボーンとして機能するConversationChainモジュールを簡単に紹介します。
2.1 LangChain
大規模言語モデル(LLM)を活用したアプリケーションの構築には多くの複雑さが伴います。言語モデルプロバイダーとのAPI呼び出しを介して接続し、これらのモデルをさまざまなデータソースに接続し、ユーザーインタラクションの履歴を処理し、複雑なタスクを実行するためのパイプラインを設計する必要があります。これがLangChainライブラリの出番です。
LangChainは、LLMを活用したアプリケーションの開発を効率化するためのフレームワークです。上記のよくある痛みを解消するためのさまざまなコンポーネントを提供しています。言語モデルプロバイダーとのインタラクションの管理、データ接続のオーケストレーション、ヒストリカルなインタラクションのメモリの維持、複雑なタスクパイプラインの定義など、LangChainが対応しています。
LangChainが導入するキーとなるコンセプトは「Chain」です。本質的に、Chainを使用することで、複数のコンポーネントを組み合わせて単一の一貫性のあるアプリケーションを作成できます。たとえば、LangChainの基本的なChainタイプの1つはLLMChainです。これは、最初にユーザー提供の入力キー値を使用してプロンプトテンプレートをフォーマットし、次にフォーマットされた指示をLLMに渡し、最後にLLMの出力を返すパイプラインを作成します。
LangChainには、ドキュメントに対する質問応答のためのRetrievalQAChain、複数のドキュメントを要約するためのSummarizationChain、そして今日の焦点であるConversationChainを含むさまざまなChainタイプがあります。
2.2 ConversationChain
ConversationChainは、メッセージの交換と会話履歴の保存のフレームワークを提供して、インタラクティブな会話を容易にします。以下のコードスニペットを使用して使用方法を説明します。
from langchain.chains import ConversationChain# Create conversation chainconversation = ConversationChain(memory, prompt, llm)# Run conversation chainconversation.predict(input="Hi there!")# Obtain the LLM response: "Hello! How can I assist you today?"# We can keep calling conversation chainconversation.predict(input="I'm doing well! Just having a conversation with an AI.")# Obtain the LLM response: "That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?"この例では、ConversationChainは3つの入力を取ります。memoryは、ユーザーの対話履歴を保持するLangChainコンポーネントです。promptは、LLMへの入力です。llmは、コアの大規模言語モデル(例:GPT-3.5-Turboなど)です。
ConversationChainオブジェクトがインスタンス化されると、ユーザー入力をconversation.predict()で呼び出すだけで、LLMの応答を取得できます。 ConversationChainの便利な点は、conversation.predict()を複数回呼び出すことができ、メッセージ履歴を自動的に記録することです。
次のセクションでは、ConversationChainの力を利用してチャットボットを作成し、メモリ、プロンプトテンプレート、LLMの定義と利用方法について深く掘り下げます。
LangChainについて詳しく知りたい場合は、公式ドキュメントを参照してください。また、このYouTubeプレイリストも包括的で実践的な紹介を提供しています。
3. プロジェクトの設計
何を構築したいかと、それを構築するためのツールが明確になったので、いよいよコードに取り掛かりましょう!このセクションでは、デュアルチャットボットの相互作用を作成するための基本的な方法に焦点を当てます。まず、単一のチャットボットのクラス定義を探索し、その後、これを拡張してデュアルチャットボットクラスを作成し、2つのチャットボットが相互作用できるようにします。アプリのインターフェイスの設計は、セクション4で行います。
3.1 単一のチャットボットを開発する
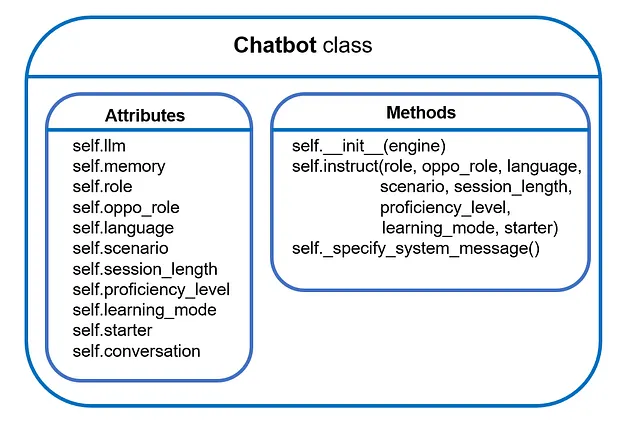
このサブセクションでは、後でデュアルチャットボットシステムに統合される単一のチャットボットを共同で開発します。まず、全体的なクラス設計から始めて、次にプロンプトエンジニアリングに注目します。
🏗️ クラス設計
私たちのチャットボットクラスは、個々のチャットボットの管理を可能にする必要があります。これには、ユーザー指定のLLMをバックボーンとしてチャットボットをインスタンス化し、ユーザーの意図に基づいて指示を提供し、対話的なマルチラウンドの会話を容易にすることが含まれます。そのために、コーディングを始めましょう。
まず、必要なライブラリをインポートします。
import osimport openaifrom langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate)from langchain.prompts import PromptTemplatefrom langchain.chains import LLMChainfrom langchain.chains import ConversationChainfrom langchain.chat_models import ChatOpenAIfrom langchain.memory import ConversationBufferMemory次に、クラスコンストラクタを定義します。
class Chatbot: """LangChainで作成されたメモリを持つ単一のチャットボットのクラス定義。""" def __init__(self, engine): """バックボーンのLLMを選択し、LangChainで言語チェーンを作成するためのメモリをインスタンス化します。""" # LLMをインスタンス化する if engine == 'OpenAI': # 注意:OpenAI APIキーを環境変数OPENAI_API_KEYを通じて設定する必要があります。 self.llm = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.7 ) else: raise KeyError("現在サポートされていないチャットモデルタイプです!") # メモリをインスタンス化する self.memory = ConversationBufferMemory(return_messages=True)現在、ネイティブのOpenAI APIを使用することしかできません。ただし、LangChainはさまざまなタイプのバックエンドLLM(Azure OpenAIエンドポイント、Anthropicチャットモデル、Google Vertex AIのPaLM APIなど)に対応しているため、追加することは簡単です。
LLMの他にも、会話履歴を追跡するためにインスタンス化する必要があるもう1つの重要なコンポーネントは、memoryです。ここでは、ConversationBufferMemoryを使用して、直近の入力/出力を現在のチャットボットの入力の前に追加するだけです。これは、LangChainで提供される最も単純なメモリタイプであり、現在の目的に十分です。
他の種類のメモリの完全な概要については、公式ドキュメントを参照してください。
次に、チャットボットに指示を与えて会話をするためのクラスメソッドが必要です。これがself.instruct()の役割です。
def instruct(self, role, oppo_role, language, scenario, session_length, proficiency_level, learning_mode, starter=False): """チャットボット相互作用の文脈を決定する。""" # 言語設定を定義する self.role = role self.oppo_role = oppo_role self.language = language self.scenario = scenario self.session_length = session_length self.proficiency_level = proficiency_level self.learning_mode = learning_mode self.starter = starter # プロンプトテンプレートを定義する prompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template(self._specify_system_message()), MessagesPlaceholder(variable_name="history"), HumanMessagePromptTemplate.from_template("{input}") ]) # 会話チェーンを作成する self.conversation = ConversationChain(memory=self.memory, prompt=prompt, llm=self.llm, verbose=False)- ユーザーが学習体験をカスタマイズできるように、いくつかの設定を定義します。
「セクション1プロジェクト概要」で述べたものに加えて、4つの新しい属性があります:
self.role / self.oppo_role: この属性は、役割名とそれに対応するアクションを記録する辞書の形式を取ります。 たとえば:
self.role = {'name': 'Customer', 'action': 'ordering food'}self.oppo_role は、現在のチャットボットと会話している他のチャットボットが取る役割を表します。 現在のチャットボットは、必要な文脈情報を提供するため、誰とコミュニケーションしているかを理解する必要があります。
self.scenario は、会話の舞台を設定します。 「会話」学習モードの場合、self.scenario は会話が発生している場所を表し、「ディベート」モードの場合、self.scenario はディベートのトピックを表します。
最後に、 self.starter は、現在のチャットボットが会話を開始するかどうかを示すブールフラグです。
- チャットボットのプロンプトを構造化します。
OpenAIでは、チャットモデルは一般的にメッセージのリストを入力として受け取り、モデルによって生成されたメッセージを出力として返します。 LangChainは SystemMessage 、 AIMessage 、 HumanMessage をサポートしています。 SystemMessage はチャットボットの動作を設定するのに役立ち、AIMessage は以前のチャットボットの応答を格納し、HumanMessage はチャットボットが応答するためのリクエストまたはコメントを提供します。
LangChainは、プロンプト生成と取り込みを簡素化するために PromptTemplate を提供しています。 チャットボットアプリケーションでは、すべての3つのメッセージタイプのために PromptTemplate を指定する必要があります。 最も重要なのは、SystemMessage を設定することで、チャットボットの動作を制御することです。 これを処理する別のメソッド、self._specify_system_message() があります。後で詳しく説明します。
- 最後に、すべての要素をまとめて、
ConversationChainを構築します。
🖋️ プロンプトの設計
今回は、ユーザーが希望に沿って会話に参加するようにチャットボットをガイドすることに焦点を当てます。 このために、self._specify_system_message() メソッドがあります。 このメソッドのシグネチャは以下の通りです:
def _specify_system_message(self): """チャットボットの動作を指定します。以下のようなもので構成されます: - 一般的な文脈:所定のシナリオの下での会話/ディベートの実施 - 話される言語 - シミュレートされた会話/ディベートの目的 - 言語の複雑さの要件 - 交換の長さの要件 - その他のニュアンス制約 出力: -------- prompt:チャットボットの指示。 """ 基本的に、このメソッドは文字列をコンパイルし、SystemMessagePromptTemplate.from_template() にフィードすることでチャットボットを指示します。これは、上記の self.instruct() メソッドの定義で示されています。 以下では、この「長い文字列」を解析して、各言語学習要件がプロンプトにどのように組み込まれるかを理解します。
1️⃣ セッションの長さ
セッションの長さは、1つのセッションで発生できる最大の交換数を直接指定することで制御されます。 これらの数値は今のところハードコードされています。
# Determine the number of exchanges between two botsexchange_counts_dict = { 'Short': {'Conversation': 8, 'Debate': 4}, 'Long': {'Conversation': 16, 'Debate': 8}}exchange_counts = exchange_counts_dict[self.session_length][self.learning_mode]2️⃣ 1つの交換でチャットボットが言える文の数
許可される総交換数を制限するだけでなく、チャットボットが1回の交換でどれだけ言えるか、つまり文の数を制限することも有益です。
私の実験では、「会話」モードでは通常制限する必要はありません。 チャットボットは実際の対話を模倣し、適度な長さで話す傾向があるためです。 ただし、「ディベート」モードでは、制限する必要があります。 そうしないと、チャットボットは話し続け、最終的には「エッセイ」を生成する可能性があります😆。
セッションの長さを制限することと同様に、発言の長さを制限する数字もハードコードされており、ユーザーの目標言語の熟練度レベルに対応しています:
# Determine number of sentences in one debate roundargument_num_dict = { '初心者': 4, '中級者': 6, '上級者': 8} 3️⃣ 発言の複雑さを決定する
ここでは、チャットボットが使用できる言語の複雑性レベルを調整します:
if self.proficiency_level == '初心者': lang_requirement = """できるだけ基本的でシンプルな語彙と 文章構造を使用してください。イディオム、俗語、 複雑な文法構造は避けてください。"""elif self.proficiency_level == '中級者': lang_requirement = """より広い範囲の語彙と多様な文構造を使用してください。 いくつかのイディオムや口語表現を含めることができますが、 高度な技術的言語や複雑な文学的表現は避けてください。"""elif self.proficiency_level == '上級者': lang_requirement = """適切な場合には洗練された語彙、複雑な文構造、イディオム、 口語表現、技術的言語を使用してください。"""else: raise KeyError('現在サポートされていない熟練度レベルです!')4️⃣ すべてをまとめる!
以下は、異なる学習モードに対する指示の例です:
# Compile bot instructions if self.learning_mode == '会話': prompt = f"""あなたは役割演技が得意なAIです。 あなたは{self.scenario}で起こった典型的な会話をシミュレーションしています。 このシナリオでは、あなたは{self.role['name']} {self.role['action']}を演じ、 {self.oppo_role['name']} {self.oppo_role['action']}に話しかけています。 あなたの会話は{self.language}でのみ行われます。翻訳しないでください。 このシミュレートされた{self.learning_mode}は、{self.language}言語学習者が実際の会話を学ぶために設計されています。 あなたは{self.language}での学習者の熟練度レベルが{self.proficiency_level}であると仮定する必要があります。 したがって、{lang_requirement}する必要があります。 {self.oppo_role['name']}との会話は{exchange_counts}回の交換内で終了する必要があります。 シナリオにおいて、{self.language}文化での典型的な会話を{self.oppo_role['name']}と 自然に行ってください。"""elif self.learning_mode == '討論': prompt = f"""あなたはディベートが得意なAIです。 次のトピックでディベートに参加しています:{self.scenario}。 このディベートでは、あなたは{self.role['name']}の役割を担っています。 常にディベートでの立場を覚えておいてください。 あなたのディベートは{self.language}でのみ行われます。翻訳しないでください。 このシミュレートされたディベートは、{self.language}言語学習者が{self.language}を学ぶために設計されています。 あなたは{self.language}での学習者の熟練度レベルが{self.proficiency_level}であると仮定する必要があります。 したがって、{lang_requirement}する必要があります。 あなたは別のAI({self.oppo_role['name']}の役割を担う)と意見を交換します。 発言するたびに、{argument_num_dict[self.proficiency_level]}文を超えてはいけません。"""else: raise KeyError('現在サポートされていない学習モードです!')5️⃣ 誰が最初に話すか?
最後に、チャットボットに最初に話すか、相手AIからの返答を待つかを指示します:
# Give bot instructionsif self.starter: # 現在のボットが最初に話す場合 prompt += f"あなたは{self.learning_mode}のリーダーです。 \n"else: # 現在のボットが2番目に話す場合 prompt += f"{self.oppo_role['name']}の発言を待ちます。"これでプロンプトの設計が完了しました 🎉 以下は、これまでに開発したものの簡単なまとめです:
3.2 デュアルチャットボットシステムの開発
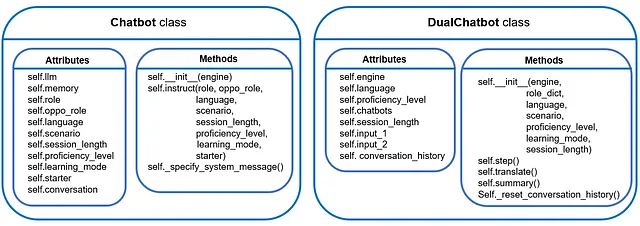
ついに、エキサイティングな部分に到着しました!このサブセクションでは、2つのチャットボットが相互作用できるように、デュアルチャットボットクラスを開発します 💬💬
🏗️ クラスデザイン
以前に開発されたシングルChatbotクラスのおかげで、クラスコンストラクタ内で簡単に2つのチャットボットをインスタンス化できます:
class DualChatbot: """LangChainで作成されたデュアルチャットボットインタラクションシステムのクラス定義""" def __init__(self, engine, role_dict, language, scenario, proficiency_level, learning_mode, session_length): # 2つのチャットボットをインスタンス化 self.engine = engine self.proficiency_level = proficiency_level self.language = language self.chatbots = role_dict for k in role_dict.keys(): self.chatbots[k].update({'chatbot': Chatbot(engine)}) # 2つのチャットボットに役割を割り当てる self.chatbots['role1']['chatbot'].instruct(role=self.chatbots['role1'], oppo_role=self.chatbots['role2'], language=language, scenario=scenario, session_length=session_length, proficiency_level=proficiency_level, learning_mode=learning_mode, starter=True) self.chatbots['role2']['chatbot'].instruct(role=self.chatbots['role2'], oppo_role=self.chatbots['role1'], language=language, scenario=scenario, session_length=session_length, proficiency_level=proficiency_level, learning_mode=learning_mode, starter=False) # セッションの長さを追加 self.session_length = session_length # 会話を準備する self._reset_conversation_history()self.chatbotsは、両方のボットに関連する情報を格納するために設計された辞書です:
# "会話"モードの場合self.chatbots= { 'role1': {'name': '顧客', 'action': '食事の注文', 'chatbot': Chatbot()}, 'role2': {'name': 'ウェイター', 'action': '注文を取る', 'chatbot': Chatbot()} }# "討論"モードの場合self.chatbots= { 'role1': {'name': '主張者', 'chatbot': Chatbot()}, 'role2': {'name': '対立者', 'chatbot': Chatbot()} }self._reset_conversation_historyは、新鮮な会話履歴を初期化し、チャットボットに初期の指示を提供するためのものです:
def _reset_conversation_history(self): """会話履歴をリセットする。 """ # 会話履歴のプレースホルダ self.conversation_history = [] # 2つのチャットボットの入力 self.input1 = "会話を開始します。" self.input2 = "" 2つのチャットボット間の対話を容易にするために、self.step()メソッドを使用します。このメソッドにより、2つのボット間で1ラウンドの対話が可能になります:
def step(self): """2つのチャットボット間で1つの交換ラウンドを行います。 """ # チャットボット1が話す output1 = self.chatbots['role1']['chatbot'].conversation.predict(input=self.input1) self.conversation_history.append({"bot": self.chatbots['role1']['name'], "text": output1}) # チャットボット1の出力をチャットボット2の入力に渡す self.input2 = output1 # チャットボット2が話す output2 = self.chatbots['role2']['chatbot'].conversation.predict(input=self.input2) self.conversation_history.append({"bot": self.chatbots['role2']['name'], "text": output2}) # チャットボット2の出力をチャットボット1の入力に渡す self.input1 = output2 # 応答を翻訳する translate1 = self.translate(output1) translate2 = self.translate(output2) return output1, output2, translate1, translate2注意してください。 self.translate()という名前のメソッドが埋め込まれていることに注意してください。このメソッドの目的は、スクリプトを英語に翻訳することです。この機能は、対象言語で生成された会話の意味を理解できるようにするため、言語学習者にとって役立つかもしれません。
翻訳機能を実現するために、基本的なLLMChainを使用できます。これには、バックエンドLLMモデルと指示のプロンプトが必要です:
def translate(self, message): """生成されたスクリプトを英語に翻訳します。 """ if self.language == '英語': # 翻訳は実行されません translation = '翻訳: ' + message else: # 翻訳をインスタンス化する if self.engine == 'OpenAI': # 注意:openAI APIキーを設定する必要があります # (環境変数OPENAI_API_KEYを介して) self.translator = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.7 ) else: raise KeyError("現在サポートされていない翻訳モデルタイプです!") # 指示を指定する instruction = """{src_lang}から以下の文を{trg_lang}に翻訳してください。 以下は、ソース言語での文です: \n {src_input}。""" prompt = PromptTemplate( input_variables=["src_lang", "trg_lang", "src_input"], template=instruction, ) # 言語チェーンを作成する translator_chain = LLMChain(llm=self.translator, prompt=prompt) translation = translator_chain.predict(src_lang=self.language, trg_lang="英語", src_input=message) return translation最後に、生成された会話スクリプトの主要な言語学習ポイント、つまり主要な語彙、文法ポイント、または機能的なフレーズの要約を言語学習者に提供することが有益であるかもしれません。そのために、self.summary()メソッドを含めることができます:
def summary(self, script): """生成されたスクリプトから主要な言語学習ポイントを抽出する。 """ # サマリーボットをインスタンス化する if self.engine == 'OpenAI': # 注意:OpenAI APIキーを設定する必要があります # (例:環境変数OPENAI_API_KEYを使用) self.summary_bot = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.7 ) else: raise KeyError("現在、サポートされていないサマリーモデルタイプです!") # 指示を指定する instruction = """以下のテキストは{src_lang}での模擬会話です。このテキストの目的は、{src_lang}のリアルライフでの使用法を学ぶことを目的としています。したがって、与えられたテキストに基づいて、主要な単語、文法ポイント、および機能的なフレーズを要約することがあなたのタスクです。あなたのサマリーは英語で行う必要がありますが、適当な場合は元の言語のテキストから例を使用してください。あなたの対象学生は{src_lang}で{proficiency}の熟練度を持っています。あなたの要約は彼らの熟練度レベルに合わせる必要があります。 会話は次のとおりです:\n {script}。""" prompt = PromptTemplate( input_variables=["src_lang", "proficiency", "script"], template=instruction, ) # 言語チェーンを作成する summary_chain = LLMChain(llm=self.summary_bot, prompt=prompt) summary = summary_chain.predict(src_lang=self.language, proficiency=self.proficiency_level, script=script) return summaryself.translate()メソッドと同様に、所望のタスクを実行するために、基本的なLLMChainを使用しました。言語モデルに、ユーザーの熟練度レベルに基づいて主要な言語学習ポイントを要約するように明示的に指示することに注意してください。
これにより、デュアルチャットボットクラスの開発が完了しました 🥂 まとめると、これまでに開発したものは次のとおりです:
4. Streamlitを使用したアプリケーションインターフェースの設計
ユーザーインターフェースの開発に備えて準備が整いました🖥️このプロジェクトでは、Streamlitライブラリを使用してフロントエンドを構築します。
Streamlitは、データサイエンスや機械学習に焦点を当てたインタラクティブなWebアプリケーションを作成するためのオープンソースのPythonライブラリです。簡単に使えるAPI、インスタントアップデートのためのライブコードリロード、ユーザー入力用のインタラクティブなウィジェット、データ可視化ライブラリのサポート、豊富なメディアの組み込み機能などを提供することで、アプリケーションの構築と展開のプロセスを簡素化します。
まず、新しいPythonスクリプトapp.pyを開始し、必要なライブラリをインポートします:
import streamlit as stfrom streamlit_chat import messagefrom chatbot import DualChatbotimport timefrom gtts import gTTSfrom io import BytesIO主要なstreamlitライブラリに加えて、チャットボットUIを作成するために特に設計されたコミュニティビルトのStreamlitコンポーネントであるstreamlit_chatライブラリもインポートします。以前に開発したDualChatbotクラスは、chatbot.pyファイルに格納されているため、それもインポートする必要があります。最後に、このプロジェクトでボットが生成する会話スクリプトに音声を追加するために、Googleテキストから音声に変換するgTTSもインポートします。
Streamlitのインターフェースを構成する前に、言語学習の設定を定義しましょう:
# 言語学習の設定を定義するLANGUAGES = ['英語', 'ドイツ語', 'スペイン語', 'フランス語']SESSION_LENGTHS = ['短い', '長い']PROFICIENCY_LEVELS = ['初心者', '中級者', '上級者']MAX_EXCHANGE_COUNTS = { '短い': {'会話': 8, 'ディベート': 4}, '長い': {'会話': 16, 'ディベート': 8}}AUDIO_SPEECH = { '英語': 'en', 'ドイツ語': 'de', 'スペイン語': 'es', 'フランス語': 'fr'}AVATAR_SEED = [123, 42]# バックボーンを定義するllmengine = 'OpenAI'AVATAR_SEEDは、異なるチャットボットの異なるアバターアイコンを生成するために使用されます。
まず、ユーザーインターフェースの基本レイアウトを設定し、ユーザーが選択できるオプションを確立することから始めます:
# アプリのタイトルを設定するst.title('Language Learning App 🌍📖🎓')# アプリの説明を設定するst.markdown("""This app generates conversation or debate scripts to aid in language learning 🎯 Choose your desired settings and press 'Generate' to start 🚀""")# 学習モードの選択ボックスを追加するlearning_mode = st.sidebar.selectbox('Learning Mode 📖', ('Conversation', 'Debate'))if learning_mode == 'Conversation': role1 = st.sidebar.text_input('Role 1 🎭') action1 = st.sidebar.text_input('Action 1 🗣️') role2 = st.sidebar.text_input('Role 2 🎭') action2 = st.sidebar.text_input('Action 2 🗣️') scenario = st.sidebar.text_input('Scenario 🎥') time_delay = 2 # ロール辞書を設定する role_dict = { 'role1': {'name': role1, 'action': action1}, 'role2': {'name': role2, 'action': action2} }else: scenario = st.sidebar.text_input('Debate Topic 💬') # ロール辞書を設定する role_dict = { 'role1': {'name': 'Proponent'}, 'role2': {'name': 'Opponent'} } time_delay = 5language = st.sidebar.selectbox('Target Language 🔤', LANGUAGES)session_length = st.sidebar.selectbox('Session Length ⏰', SESSION_LENGTHS)proficiency_level = st.sidebar.selectbox('Proficiency Level 🏆', PROFICIENCY_LEVELS)time_delay変数の導入に注意してください。これは、2つの連続したメッセージを表示する間の待機時間を指定するために使用されます。この遅延がゼロに設定されている場合、2つのチャットボット間で生成された交換がアプリに迅速に表示されます(OpenAIの応答時間に限定されます)。しかし、ユーザーエクスペリエンスのために、次の交換が表示される前に生成されたメッセージを十分に読むための時間を許可することが有益である場合があります。
次に、Streamlitセッション状態を初期化して、Streamlitアプリ内でユーザー固有のセッションデータを保存するために使用します:
if "bot1_mesg" not in st.session_state: st.session_state["bot1_mesg"] = []if "bot2_mesg" not in st.session_state: st.session_state["bot2_mesg"] = []if 'batch_flag' not in st.session_state: st.session_state["batch_flag"] = Falseif 'translate_flag' not in st.session_state: st.session_state["translate_flag"] = Falseif 'audio_flag' not in st.session_state: st.session_state["audio_flag"] = Falseif 'message_counter' not in st.session_state: st.session_state["message_counter"] = 0ここで2つの質問に答えます:
1️⃣ まず、なぜ「session_state」が必要なのですか?
Streamlitでは、ユーザーがアプリとやり取りするたびに、Streamlitはスクリプト全体を最初から最後まで再実行し、アプリの出力を更新します。しかし、Streamlitのこの反応的な性質は、ユーザー固有のデータを維持したり、アプリ内の異なるやり取りやページ間で状態を保持したりする場合に課題を提起することがあります。Streamlitは、ユーザーのアクションごとにスクリプトを再読み込みするため、通常のPython変数は値を失い、アプリは初期状態にリセットされます。
ここで、session_stateが登場します。Streamlitのセッション状態は、ユーザーがアプリを再読み込みしたり、異なるコンポーネントやページ間を移動したりしても、セッション全体を通じて永続化されるデータを保存および取得する方法を提供します。それにより、状態情報を維持し、各ユーザーのアプリのコンテキストを保持できます。
2️⃣ さらに、session_stateに保存されている変数は何ですか?
「bot1_mesg」は、リストであり、リストの各要素は、最初のチャットボットによって話されたメッセージを保持する辞書です。次のキーを持ちます。「役割」、「コンテンツ」、「翻訳」。同じ定義が「bot2_mesg」にも適用されます。
「batch_flag」は、会話の交換が一度に表示されるか、時間遅延で表示されるかを示すブールフラグです。現在の設計では、2つのボットのチャットが最初に生成されたとき、それらの会話は時間遅延で表示されます。その後、ユーザーは生成された会話の翻訳を見たり、オーディオを追加したりするかもしれませんし、保存された会話メッセージ(「bot1_mesg」および「bot2_mesg」にある)は一度に表示されます。これは、コストとレイテンシを削減するためにOpenAI APIを再び呼び出す必要がないため、有益です。
「translate_flag」と「audio_flag」は、翻訳と/または音声が元の会話の隣に表示されるかどうかを示すために使用されます。
「message_counter」は、チャットボットからのメッセージが表示されるたびに1を追加するカウンターです。アイデアは、Streamlitが各UIコンポーネントに固有のIDを持つ必要があるため、このカウンターでメッセージIDを割り当てることです。
今度は、2つのチャットボットが相互作用して会話を生成できるようにするロジックを紹介できます:
if 'dual_chatbots' not in st.session_state: if st.sidebar.button('Generate'): # Add flag to indicate if this is the first time running the script st.session_state["first_time_exec"] = True with conversation_container: if learning_mode == 'Conversation': st.write(f"""#### The following conversation happens between {role1} and {role2} {scenario} 🎭""") else: st.write(f"""#### Debate 💬: {scenario}""") # Instantiate dual-chatbot system dual_chatbots = DualChatbot(engine, role_dict, language, scenario, proficiency_level, learning_mode, session_length) st.session_state['dual_chatbots'] = dual_chatbots # Start exchanges for _ in range(MAX_EXCHANGE_COUNTS[session_length][learning_mode]): output1, output2, translate1, translate2 = dual_chatbots.step() mesg_1 = {"role": dual_chatbots.chatbots['role1']['name'], "content": output1, "translation": translate1} mesg_2 = {"role": dual_chatbots.chatbots['role2']['name'], "content": output2, "translation": translate2} new_count = show_messages(mesg_1, mesg_2, st.session_state["message_counter"], time_delay=time_delay, batch=False, audio=False, translation=False) st.session_state["message_counter"] = new_count # Update session state st.session_state.bot1_mesg.append(mesg_1) st.session_state.bot2_mesg.append(mesg_2)スクリプトを初めて実行すると、セッション状態に「dual_chatbots」キーが保存されないため(まだデュアルチャットボットが作成されていないため)、ユーザーがサイドバーの「Generate」ボタンをクリックしたときに上記のコードスニペットが実行されます。2つのチャットボットが指定された回数チャットし、すべての会話メッセージがセッション状態に記録されます。 show_message()関数は、メッセージ表示の唯一のインターフェースとして設計されたヘルパー関数です。このセクションの最後に戻ります。
現在、ユーザーがアプリとやり取りしていくつかの設定を変更すると、Streamlitはトップからスクリプトを再実行します。必要な会話スクリプトをすでに生成しているため、OpenAI APIを再度呼び出す必要はありません。代わりに、単に保存された情報を取得できます:
if 'dual_chatbots' in st.session_state: # Show translation if translate_col.button('Translate to English'): st.session_state['translate_flag'] = True st.session_state['batch_flag'] = True # Show original text if original_col.button('Show original'): st.session_state['translate_flag'] = False st.session_state['batch_flag'] = True # Append audio if audio_col.button('Play audio'): st.session_state['audio_flag'] = True st.session_state['batch_flag'] = True # Retrieve generated conversation & chatbots mesg1_list = st.session_state.bot1_mesg mesg2_list = st.session_state.bot2_mesg dual_chatbots = st.session_state['dual_chatbots'] # Control message appearance if st.session_state["first_time_exec"]: st.session_state['first_time_exec'] = False else: # Show complete message with conversation_container: if learning_mode == 'Conversation': st.write(f"""#### {role1} and {role2} {scenario} 🎭""") else: st.write(f"""#### Debate 💬: {scenario}""") for mesg_1, mesg_2 in zip(mesg1_list, mesg2_list): new_count = show_messages(mesg_1, mesg_2, st.session_state["message_counter"], time_delay=time_delay, batch=st.session_state['batch_flag'], audio=st.session_state['audio_flag'], translation=st.session_state['translate_flag']) st.session_state["message_counter"] = new_countセッションステートには「first_time_exec」というフラグがあることに注意してください。これは、最初に生成されたスクリプトがアプリに表示されたかどうかを示すために使用されます。このチェックを削除すると、アプリを初めて実行するときに同じメッセージが二度表示されます。
残りの唯一のことは、UIに主要な学習ポイントの概要を含めることです。そのために、st.expanderを使用できます。Streamlitでは、st.expanderは、初めは表示されていない大量のコンテンツや情報をコンパクトに表示するために有用です。ユーザーがエクスパンダーをクリックすると、それに含まれるコンテンツが展開または折りたたまれ、追加の詳細が表示または非表示になります。
# Create summary for key learning points summary_expander = st.expander('Key Learning Points') scripts = [] for mesg_1, mesg_2 in zip(mesg1_list, mesg2_list): for i, mesg in enumerate([mesg_1, mesg_2]): scripts.append(mesg['role'] + ': ' + mesg['content']) # Compile summary if "summary" not in st.session_state: summary = dual_chatbots.summary(scripts) st.session_state["summary"] = summary else: summary = st.session_state["summary"] with summary_expander: st.markdown(f"**Here is the learning summary:**") st.write(summary)主要な学習ポイントの概要もOpenAI APIを呼び出して生成されるため、生成された概要をsession_stateに保存して、スクリプトが2回目に実行された場合にコンテンツを取得できるようにします。
最後に、ヘルパー関数show_messageを使用してStreamlit UIデザインを完成させましょう:
def show_messages(mesg_1, mesg_2, message_counter, time_delay, batch=False, audio=False, translation=False): """Display conversation exchanges. This helper function supports displaying original texts, translated texts, and audio speech. Output: ------- message_counter: updated counter for ID key """ for i, mesg in enumerate([mesg_1, mesg_2]): # Show original exchange () message(f"{mesg['content']}", is_user=i==1, avatar_style="bottts", seed=AVATAR_SEED[i], key=message_counter) message_counter += 1 # Mimic time interval between conversations # (this time delay only appears when generating # the conversation script for the first time) if not batch: time.sleep(time_delay) # Show translated exchange if translation: message(f"{mesg['translation']}", is_user=i==1, avatar_style="bottts", seed=AVATAR_SEED[i], key=message_counter) message_counter += 1 # Append autio to the exchange if audio: tts = gTTS(text=mesg['content'], lang=AUDIO_SPEECH[language]) sound_file = BytesIO() tts.write_to_fp(sound_file) st.audio(sound_file) return message_counterいくつかのポイントについては、さらに説明が必要です。
1️⃣ message()オブジェクト
これは、streamlit_chatライブラリの一部であり、メッセージを表示するために使用されます。最も単純な形式では、次のようになります:
import streamlit as stfrom streamlit_chat import messagemessage("Hellp, I am a Chatbot, how may I help you?") message("Hey, what's a chatbot", is_user=True) 
ここで、引数is_userは、メッセージを左寄せまたは右寄せにするかどうかを決定します。 show_messageのコードスニペットでは、2つのチャットボットのアバターアイコンを設定するためにavatar_styleとseedを指定しています。 key引数は、Streamlitで必要な一意のIDを各メッセージに割り当てるためのものです。
2️⃣ テキスト読み上げ
ここでは、生成されたスクリプトに基づいて、gTTSライブラリを使用して目標言語でオーディオ音声を作成します。このライブラリは使いやすいですが、制限があります。ユーザーは1つの音声しか持てません。オーディオオブジェクトが生成された後、アプリ内の各メッセージにオーディオプレーヤーを作成するためにst.audioを使用できます。
素晴らしい!UIデザインが完了しました 🙂 ターミナルで以下のコマンドを入力してください:
streamlit run app.pyブラウザでアプリを見ることができ、インタラクションもできるはずです。よくできました!
5. 学びと今後の拡張
最後に、このプロジェクトから得た主な学びと今後の拡張の方向性を紹介します。
1️⃣ 会話を止める方法は?
この問題は、正しく行うには思われるほど簡単ではありません。理想的には、会話を自然に終了させたいところです。しかし、いくつかの実験で、チャットボットが会話の終わりにお互いに「ありがとう」や「さようなら」と言い続けることがあったため、会話が不必要に長引いてしまいました。この問題に対するいくつかの解決策は次のとおりです。
- 交換ラウンドの硬い制限: これはおそらく最も簡単な解決策であり、このプロジェクトで採用した方法でもあります。ただし、会話を早期に終了させる可能性があるため、常に理想的な解決策とは限りません。回避策として、
SystemMessageでボットに会話を一定数の交換で終了するよう指示しました。 - 「シグナルワード」の使用: チャットボットは、自然に会話が終了したと判断した場合に特定の「シグナルワード」(例:「会話終了」)を発話するようにプログラムできます。その後、これらの「シグナルワード」を検出してループを終了するためのロジックを実装できます。
- 会話のポスト処理: チャットボットが会話を生成した後、別のLLMを「エディター」として展開して会話を整理することができます。これは効果的なアプローチになりますが、その欠点は、追加のプロンプトの設計、OpenAI APIを再度呼び出すことによる追加のコスト、およびレイテンシを増加させることが含まれます。
2️⃣ 言語の複雑さを制御する方法は?
開発されたチャットボットは、チャットで使用される言語の複雑さに関する指示に従うのが困難なようです。たとえば、「初心者」の熟練度レベルが設定されているにもかかわらず、「中級」レベルの言語使用が現れることがよくあります。その原因の1つは、現在のプロンプト設計が、異なる複雑度レベルのニュアンスを指定するには十分ではないことです。
この問題に対処するには、まず「コンテキストでの学習」を実行することができます。つまり、チャットボットに例を提供し、異なる複雑度レベルに対してどのような言語使用を望むかを示します。前述の方法と似た方法として、会話の複雑さを調整するために別のLLMを使用することもできます。この追加のLLMは、生成されたスクリプトを出発点として使用し、ユーザーの希望する熟練度レベルに合わせて新しいスクリプトを書き換えることができます。
3️⃣ より良いテキスト読み上げライブラリは?
現在のプロジェクトでは、単純なgTTSライブラリのみを使用して音声を合成しましたが、改善の余地があります。より高度なライブラリには、多言語サポート、複数話者サポート、より自然な音声などがあります。例えば、pyttsx3、Amazon Polly、IBM Watson TTS、Microsoft Azure Cognitive Services TTS、Coqui.ai-TTS、最近リリースされたMetaのVoiceboxなどがあります。
4️⃣ 異なるシナリオでのより多くのテストは?
時間の制約のため、チャットボットが意味のある会話を生成できるかどうかを確認するために、わずかなシナリオしかテストしていません。これらのテストは、最初のプロンプト設計に問題があることを特定し、改善の機会を提供しました。追加のシナリオテストによって、見落とされた領域が明らかになり、プロンプトを強化する方法が示唆される可能性があります。典型的な「会話」シナリオと「議論」トピックの包括的なリストをまとめました。試して、現在のプロンプト設計のパフォーマンスを評価してください。
5️⃣ 他の形式の生成AIを含める?
このプロジェクトは主にテキスト対テキスト(チャットボット)およびテキスト対音声の生成AI技術を探求しました。私たちは、テキストから画像またはテキストからビデオなど、他の形式の生成AIを利用することで、ユーザーエクスペリエンスをさらに向上させることができます。
- テキストから画像:ユーザーが入力するシナリオごとに、テキストから画像モデルを使用して対応する図を作成できます。生成された会話の横にこれらの図を表示することで、視覚的なコンテキストを提供し、言語学習のエンゲージメントを高めることができます。この目的には、StableDiffusion、Midjourney、およびDALL-Eなどのモデルを使用できます。
- テキストからビデオ:アプリをよりマルチメディアにするために、入力シナリオに基づいてビデオを生成することができます。このためには、RunwayMLというツールが役立ちます。さらに、会話を提示するためにデジタルヒューマンを作成することも試みることができ、正しく実行されればユーザーエクスペリエンスを大幅に向上させることができます。Synthesiaはこの目的に適したツールかもしれません。
6️⃣ より多くの言語学習設定?
現在、私たちのアプリは主に「会話」と「ディベート」学習モードに焦点を当てています。しかし、成長の可能性は大きいです。例えば、他の学習モードを導入することができます。例えば、「ストーリーテリング」と「文化学習」などです。また、チャットボットの対話をより専門的で技術的なシナリオに対応するように拡大することもできます。これらには、ミーティング、交渉などの設定、または営業、マーケティング、法律、エンジニアリングなどのセクターが含まれる場合があります。この機能は、プロフェッショナルな言語能力を向上させたい言語学習者に役立つ可能性があります。
6. 結論
わあ、どんな旅でしょう!ここまでおつきあいいただきありがとうございます 🤗 プロンプトの設計からチャットボットの作成まで、私たちは確かに多くのことをカバーしました。LangChainとStreamlitを使用して、言語学習に使用できる機能的なデュアルチャットボットシステムを構築しました。悪くありません!
私たちの冒険があなたの好奇心を刺激し、アイデアを思いつかせてくれたことを願っています。一緒に探求、革新、学習を続けましょう。Happy coding!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






