「KafkaとRisingwaveを使用したFormula 1のストリーミングデータパイプラインの構築」
Building a Formula 1 streaming data pipeline with Kafka and Risingwave
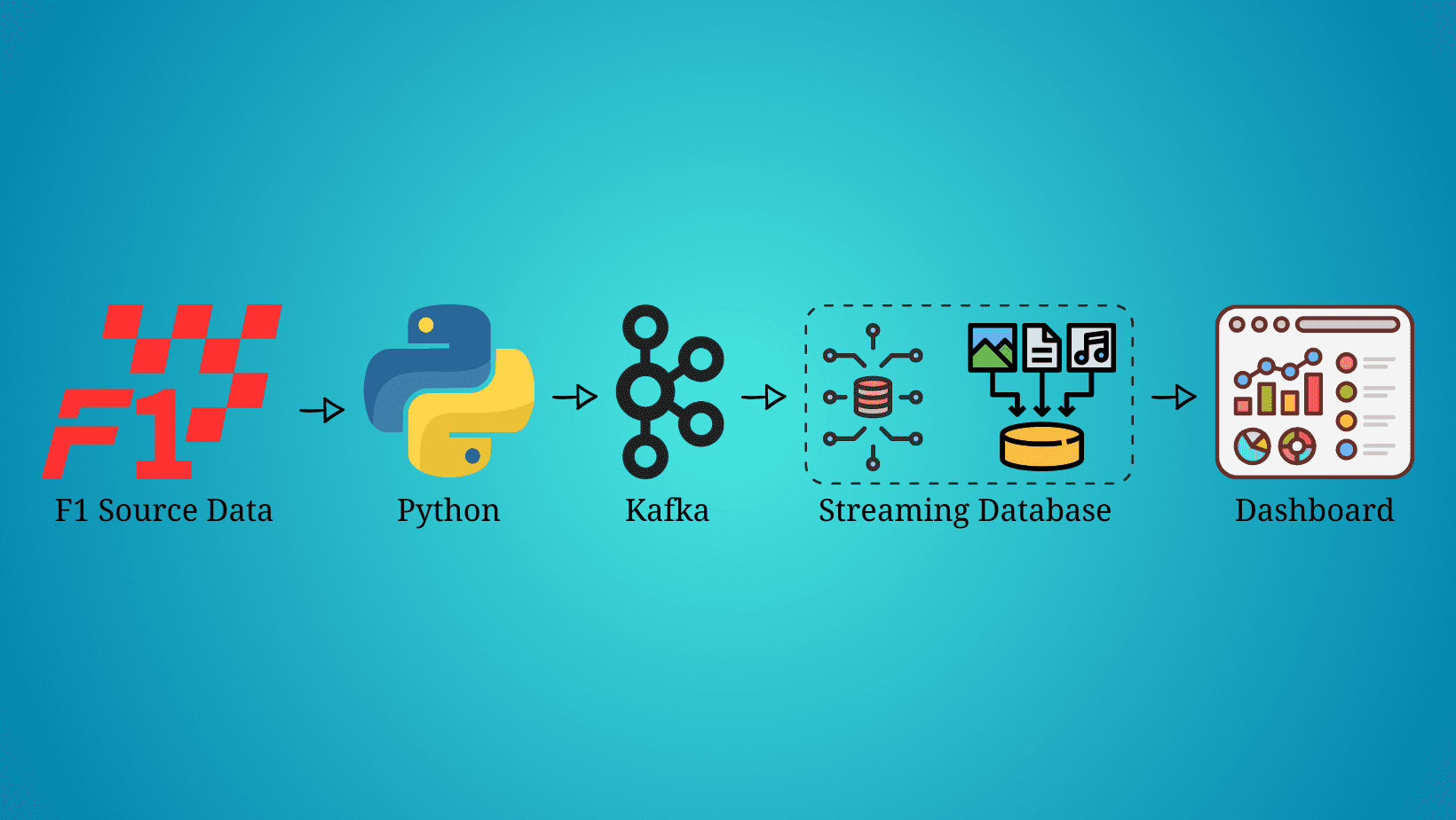
リアルタイムデータが到着し、そしてここにあります。毎日ストリーミングデータの量が指数関数的に増加していることは疑いの余地がありません。そのデータを抽出、処理、可視化する最良の方法を見つける必要があります。例えば、各フォーミュラ1カーは1.5テラバイトのデータをレースの週末に生成します(出典)。
この記事では、車のデータをストリーミングするわけではありませんが、フォーミュラ1レースをライブでシミュレートし、レースのデータをストリーミング、処理、可視化する方法について説明します。ただし、各技術の詳細についてではなく、ストリーミングデータパイプラインでそれらを実装する方法に焦点を当てますので、Python、Kafka、SQL、およびデータ可視化に関する知識が必要です。
前提条件
- F1ソースデータ:このデータストリーミングパイプラインで使用されるフォーミュラ1データは、Kaggleからダウンロードされ、Formula 1 World Championship(1950年-2023年)として見つけることができます。
- Python:このパイプラインを構築するためにPython 3.9を使用しましたが、3.0以上のバージョンであれば動作するはずです。Pythonのダウンロードとインストール方法の詳細は、公式のPythonのウェブサイトで確認できます。
- Kafka:Kafkaはこのストリーミングパイプラインで使用される主要な技術の1つですので、開始する前にインストールする必要があります。このストリーミングパイプラインはMacOSで構築されているため、Kafkaをインストールするためにbrewを使用しました。詳細は公式のbrewウェブサイトで確認できます。また、PythonでKafkaを使用するためのライブラリも必要です。このパイプラインではkafka-pythonを使用しています。インストールの詳細は公式のウェブサイトで確認できます。
- RisingWave(ストリーミングデータベース):マーケットには複数のストリーミングデータベースがありますが、この記事で使用されているもので最も優れているのはRisingWaveです。RisingWaveの始め方は非常に簡単で、数分で完了します。始め方の詳細なチュートリアルは公式のウェブサイトで確認できます。
- Grafanaダッシュボード:このストリーミングパイプラインでは、リアルタイムでフォーミュラ1データを可視化するためにGrafanaを使用しました。始め方の詳細はこのウェブサイトで確認できます。
ソースデータのストリーミング
前提条件が整ったので、いよいよフォーミュラ1データストリーミングパイプラインの構築を始めましょう。ソースデータはJSONファイルに格納されているため、それを抽出してKafkaのトピックを介して送信する必要があります。そのために、以下のPythonスクリプトを使用します。
コード by Author
Kafkaのセットアップ
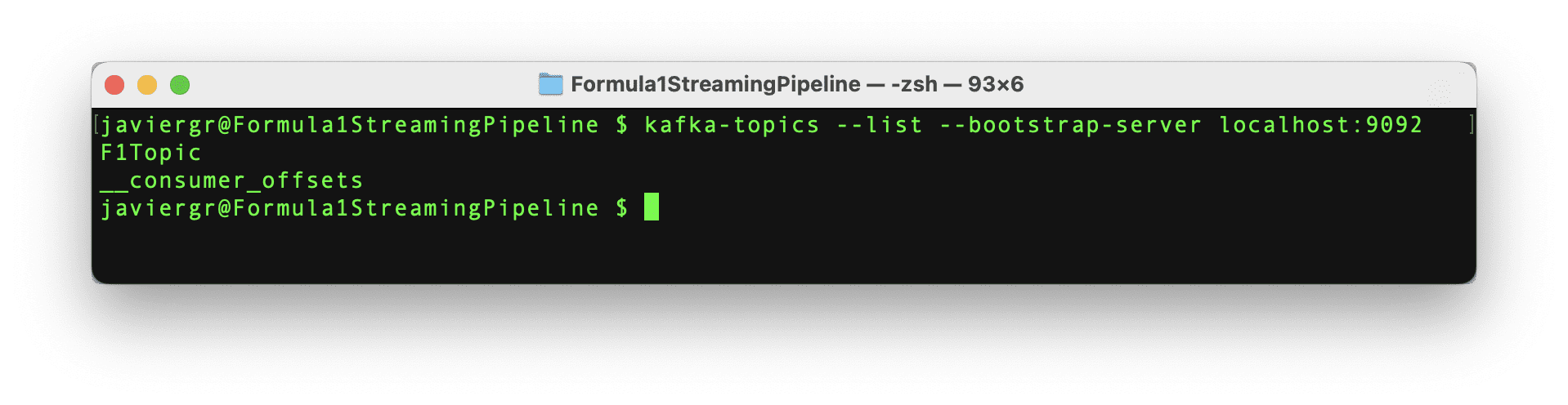
データのストリーミングを開始するためのPythonスクリプトはすべて準備されましたが、KafkaのトピックF1Topicはまだ作成されていませんので、作成しましょう。まず、Kafkaを初期化する必要があります。そのためには、Zookeperを起動し、Kafkaを起動し、最後に以下のコマンドでトピックを作成する必要があります。ZookeperとKafkaは別々のターミナルで実行している必要があることを忘れないでください。
コード by Author
ストリーミングデータベースRisingWaveのセットアップ
RisingWaveがインストールされたら、簡単に起動できます。まず、データベースを初期化し、次にPostgresの対話型ターミナルpsqlを介してそれに接続する必要があります。ストリーミングデータベースRisingWaveを初期化するには、以下のコマンドを実行する必要があります。
コード by Author
上記のコマンドは、データが一時的にメモリに格納されるプレイグラウンドモードでRisingWaveを起動します。このサービスは、30分間の非アクティビティ後に自動的に終了し、終了時に格納されたデータは削除されます。この方法はテスト用に推奨されており、本番環境ではRisingWave Cloudを使用する必要があります。
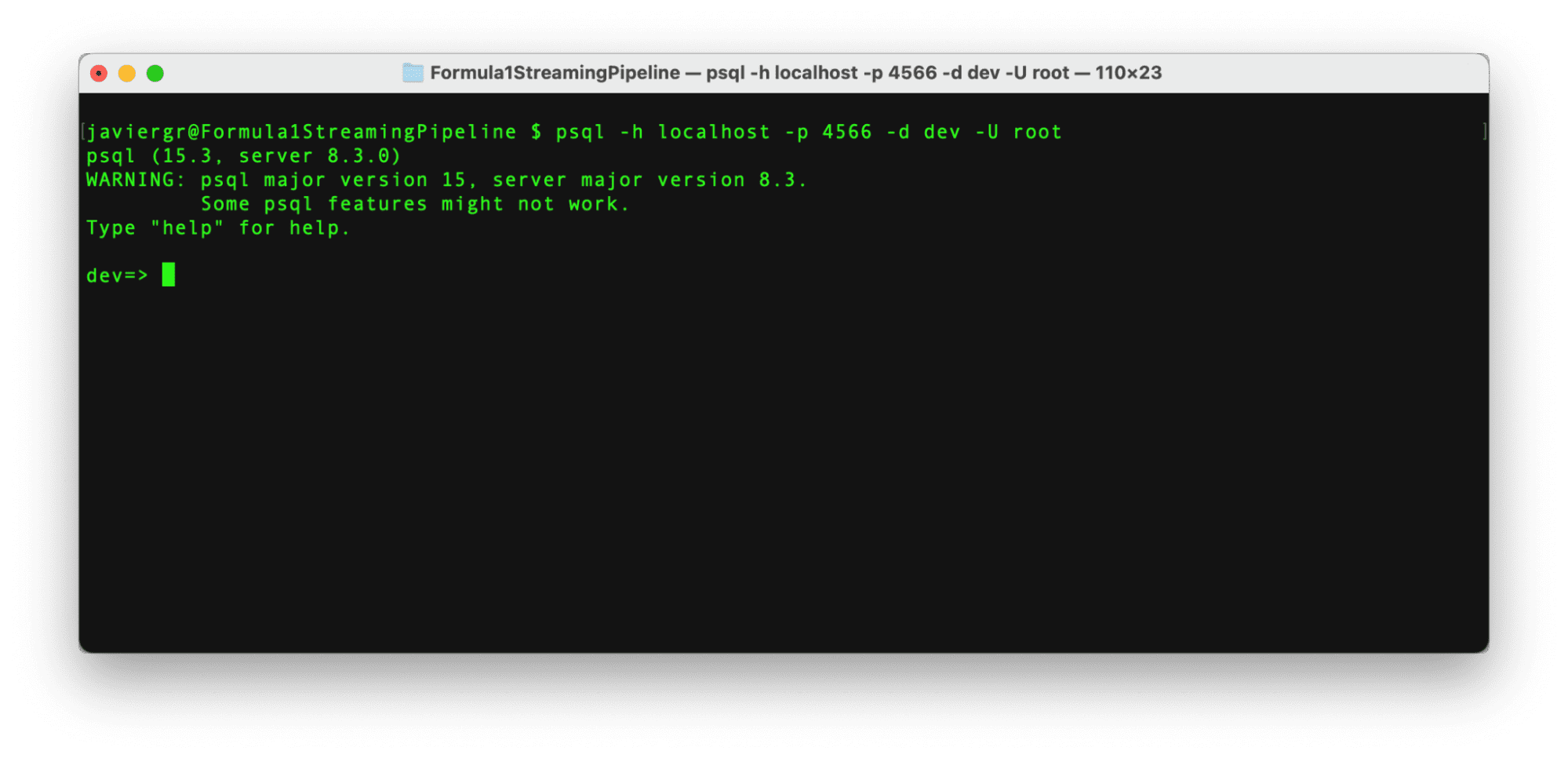
RisingWaveが起動して実行されたら、新しいターミナルでPostgressの対話型ターミナルを使用してそれに接続する時間です。以下のコマンドを使用します。
著者によるコード
接続が確立したら、Kafkaトピックからデータを取得する準備が整いました。RisingWaveにストリーミングデータを取り込むためには、ソースを作成する必要があります。このソースはKafkaトピックとRisingWaveの間の通信を確立しますので、以下のコマンドを実行しましょう。
著者によるコード
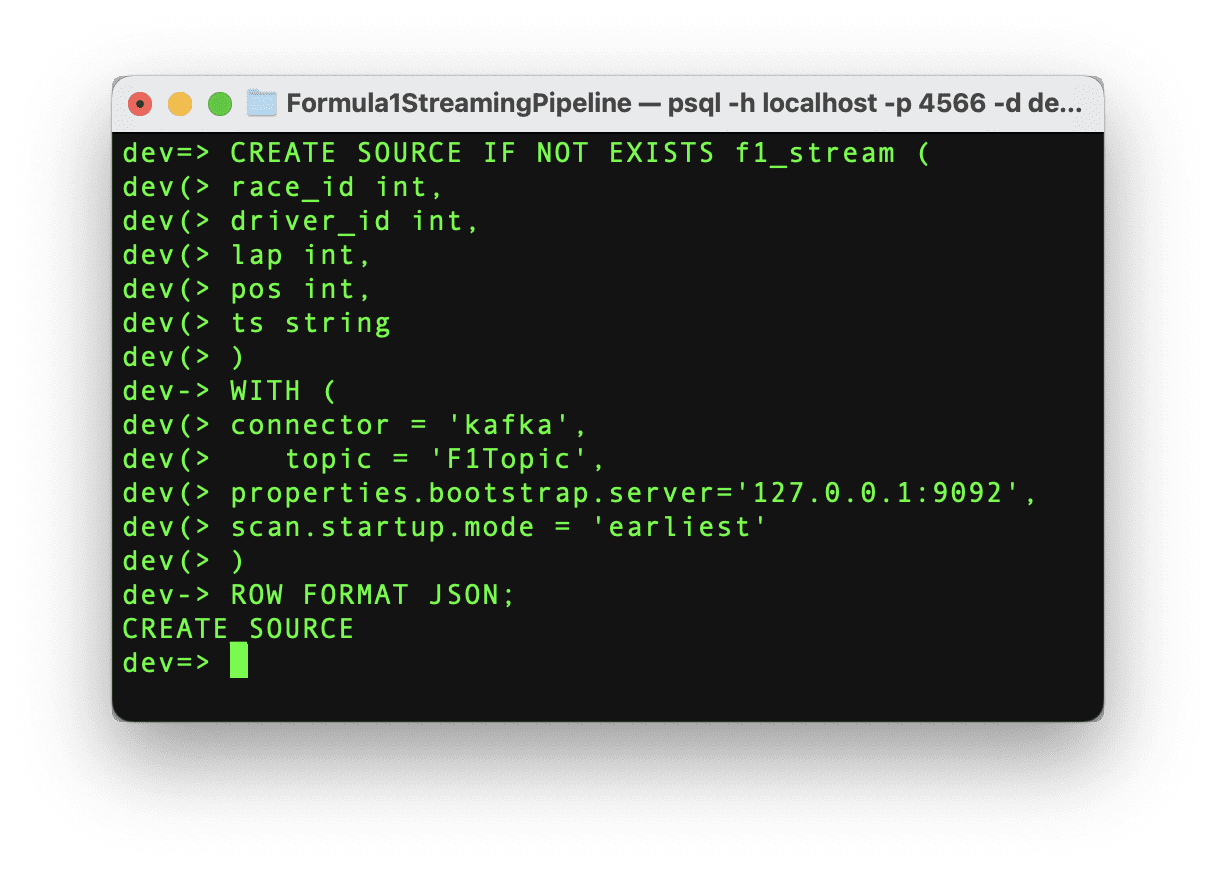
コマンドが正常に実行された場合、「CREATE SOURCE」というメッセージとソースの作成が表示されます。重要な点として、ソースが作成されると、データは自動的にRisingWaveに取り込まれるわけではありません。データの移動を開始するためには、マテリアライズドビューを作成する必要があります。このマテリアライズドビューは、次のステップでGrafanaダッシュボードを作成するのにも役立ちます。
以下のコマンドを使用して、ソースデータと同じスキーマを持つマテリアライズドビューを作成しましょう。
著者によるコード
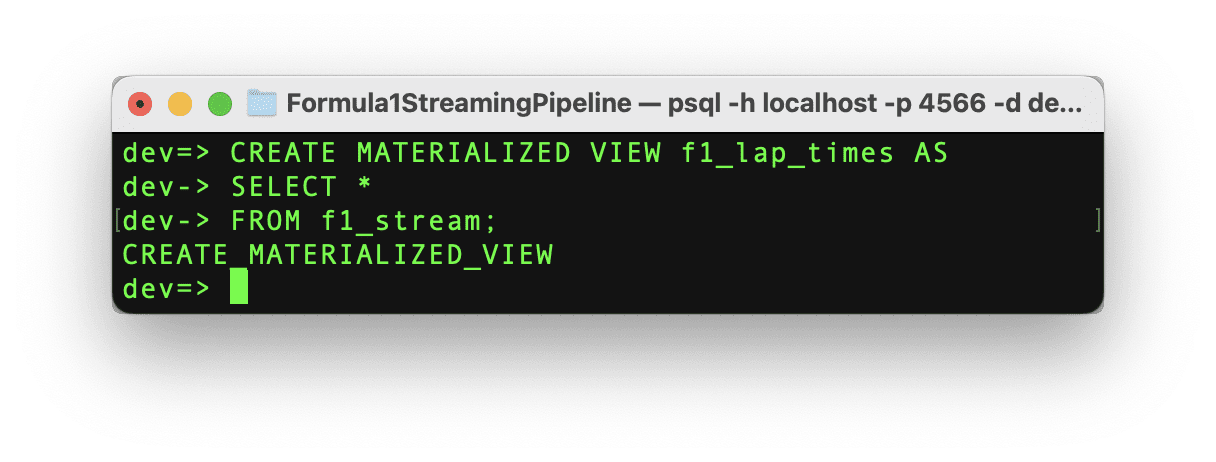
コマンドが正常に実行された場合、「CREATE MATERIALIZED_VIEW」というメッセージとマテリアライズドビューの作成が表示されます。これでテストの時間です!
Pythonスクリプトを実行してデータのストリーミングを開始し、RisingWaveのターミナルでリアルタイムにデータをクエリしましょう。RisingWaveはPostgres互換のSQLデータベースなので、PostgreSQLや他のSQLデータベースに慣れている場合は、ストリーミングデータをクエリするためのすべてがスムーズに進みます。
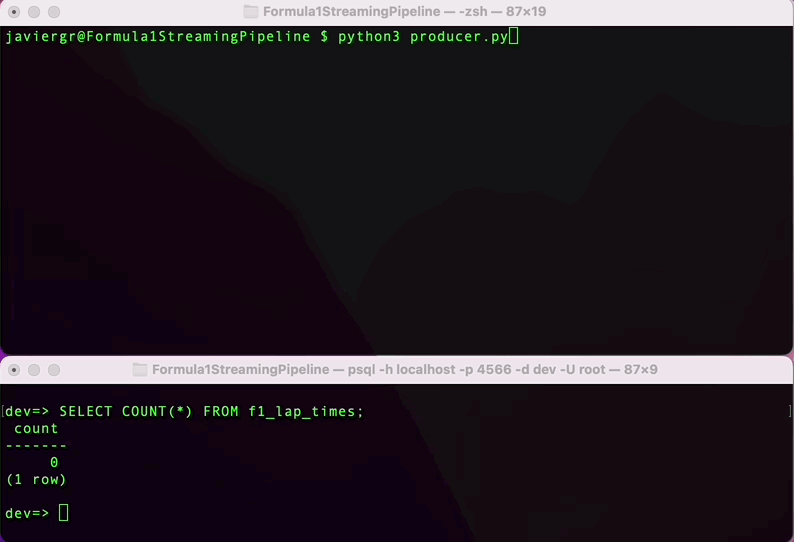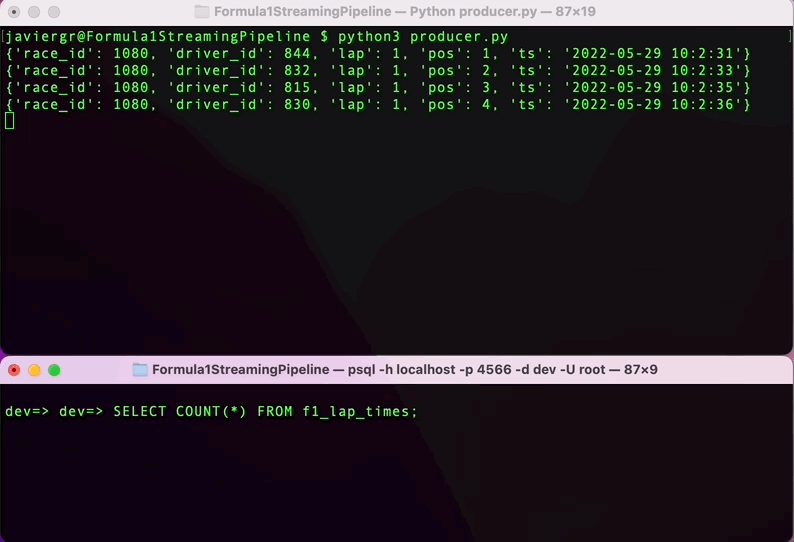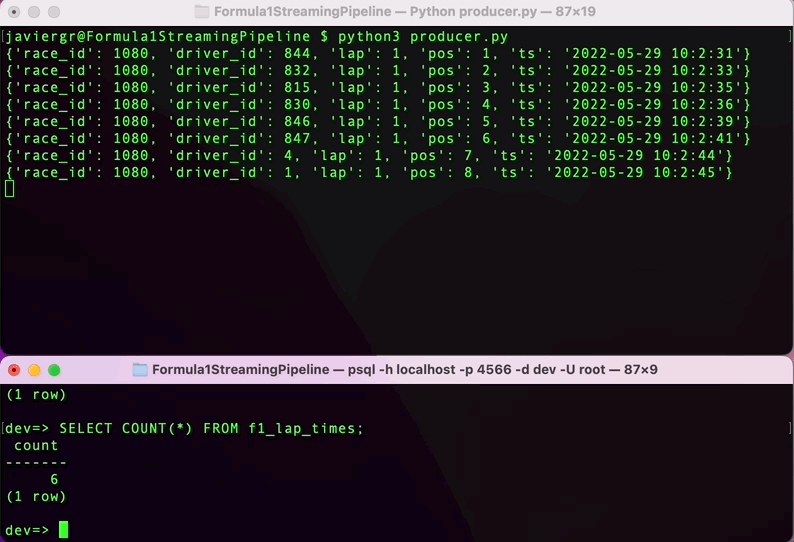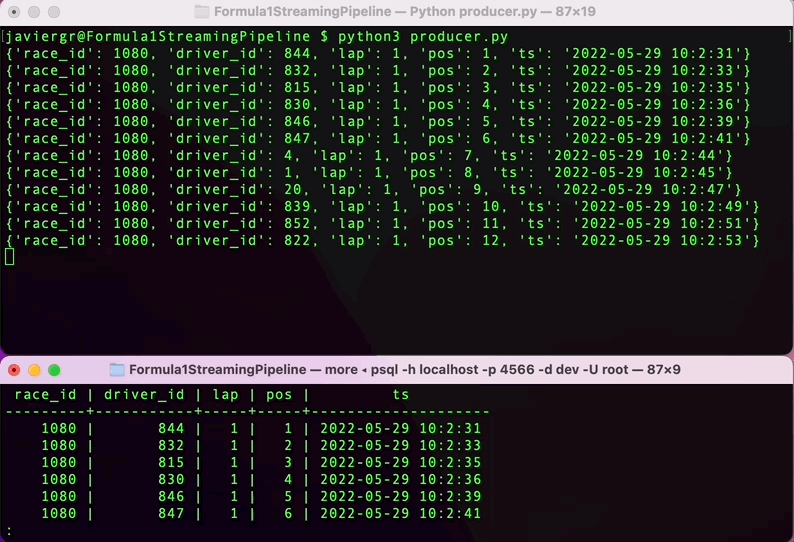
ストリーミングパイプラインが稼働していることがわかりますが、ストリーミングデータベースRisingWaveのすべての利点を活用していません。リアルタイムでデータを結合し、完全に機能するアプリケーションを構築するために、さらにテーブルを追加することができます。
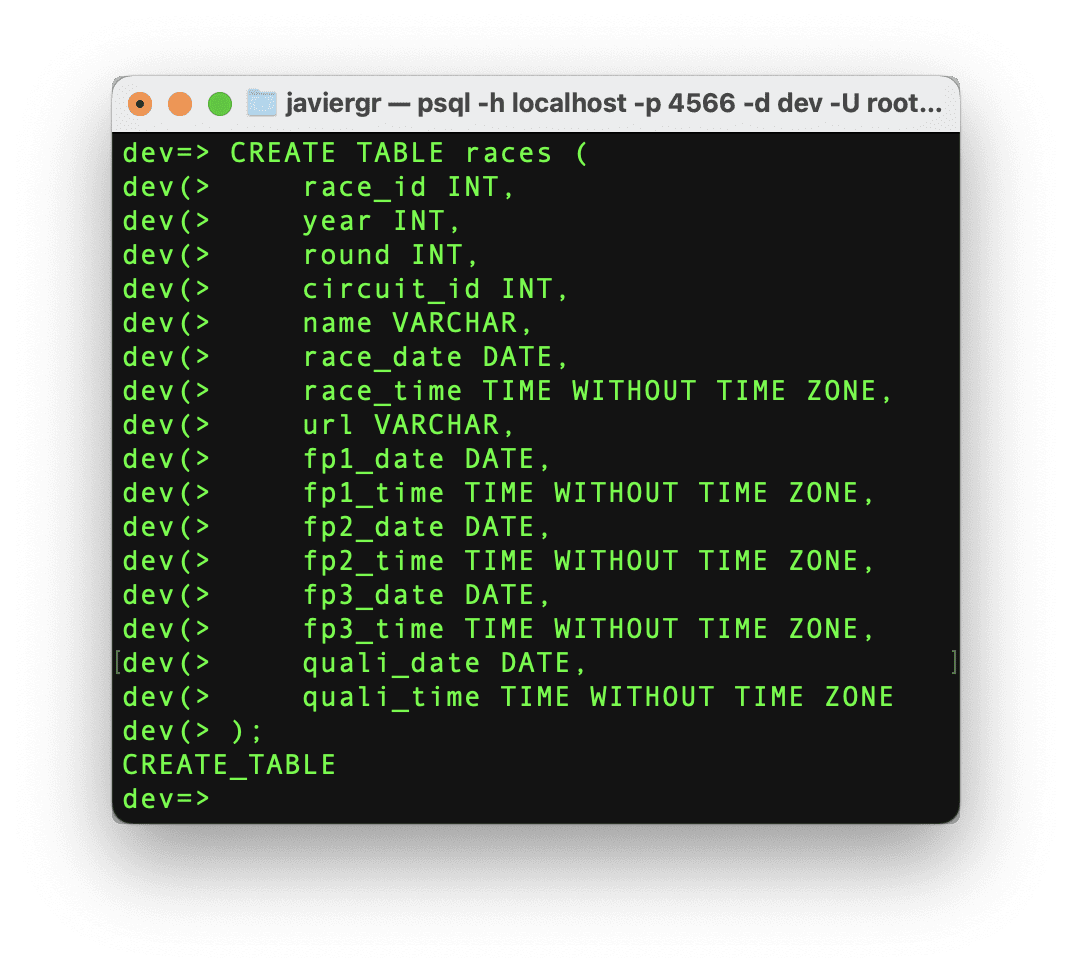
レーステーブルを作成して、ストリーミングデータをレーステーブルと結合し、レースIDではなく実際のレース名を取得できるようにしましょう。
著者によるコード
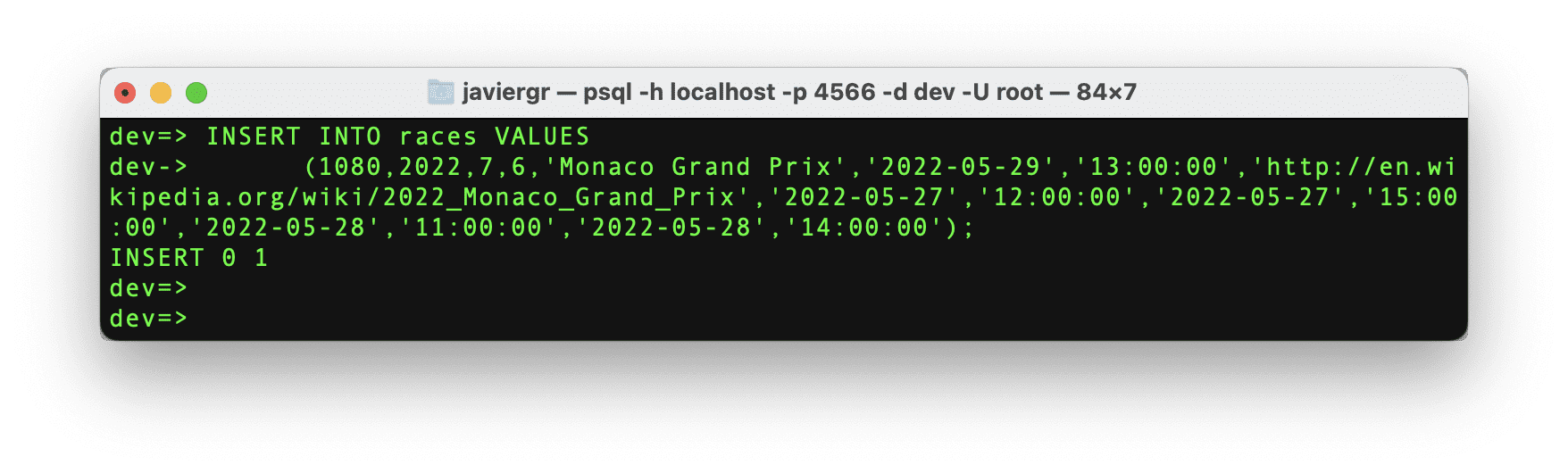
それでは、必要な特定のレースIDのデータを挿入しましょう。
著者によるコード
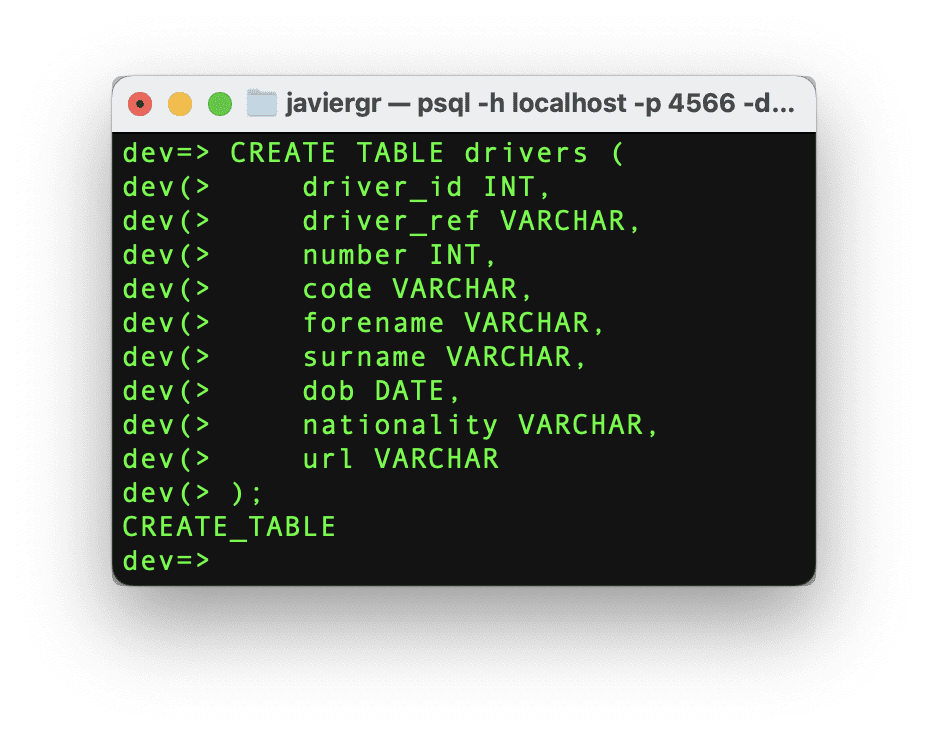
同じ手順をドライバーテーブルでも行いましょう。
著者によるコード
最後に、ドライバーのデータを挿入しましょう。
著者によるコード
データを結合するためのテーブルは準備ができていますが、魔法が起こるマテリアライズドビューが必要です。ドライバーIDとレースIDを結合して実際の名前を取得するためのリアルタイムでトップ3の位置を表示するマテリアライズドビューを作成しましょう。
著者によるコード
最後に、レース全体でドライバーが1位を獲得した回数を表示するために、最後のマテリアライズドビューを作成しましょう。
著者によるコード
それでは、Grafanaダッシュボードを作成し、マテリアライズドビューのおかげでリアルタイムに結合されたデータを表示する時間です。
Grafanaダッシュボードの設定
このストリーミングデータパイプラインの最後のステップは、リアルタイムのダッシュボードでストリーミングデータを視覚化することです。Grafanaダッシュボードを作成する前に、以下の手順に従ってGrafanaとストリーミングデータベースRisingWaveの間の接続を確立するためのデータソースを作成する必要があります。
- 「Configuration」→「Data sources」に移動します。
- 「Add data source」ボタンをクリックします。
- サポートされているデータベースのリストから「PostgreSQL」を選択します。
- 以下のようにPostgreSQL接続のフィールドを入力します。
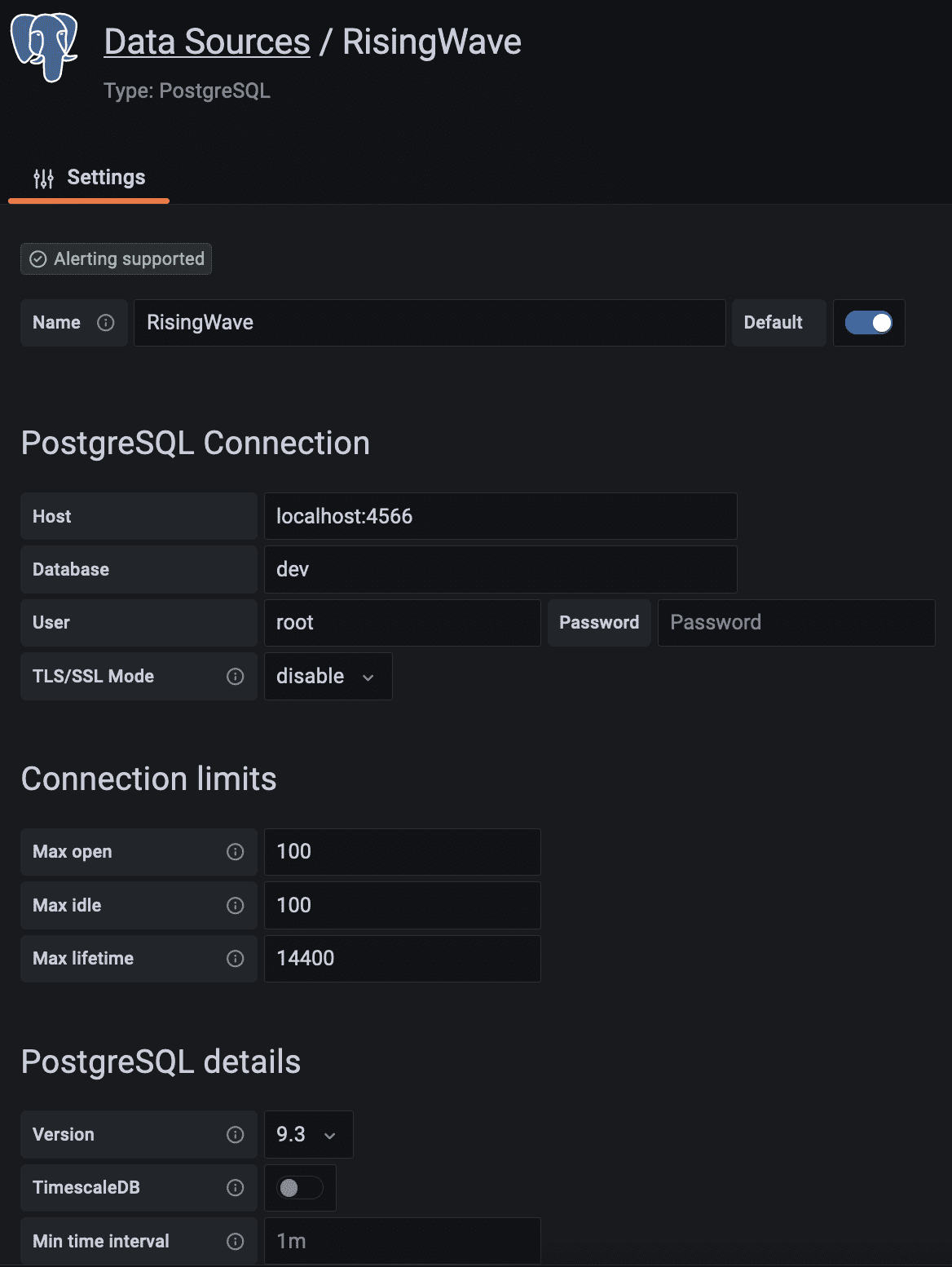
スクロールして保存してテストボタンをクリックします。データベース接続が確立されました。
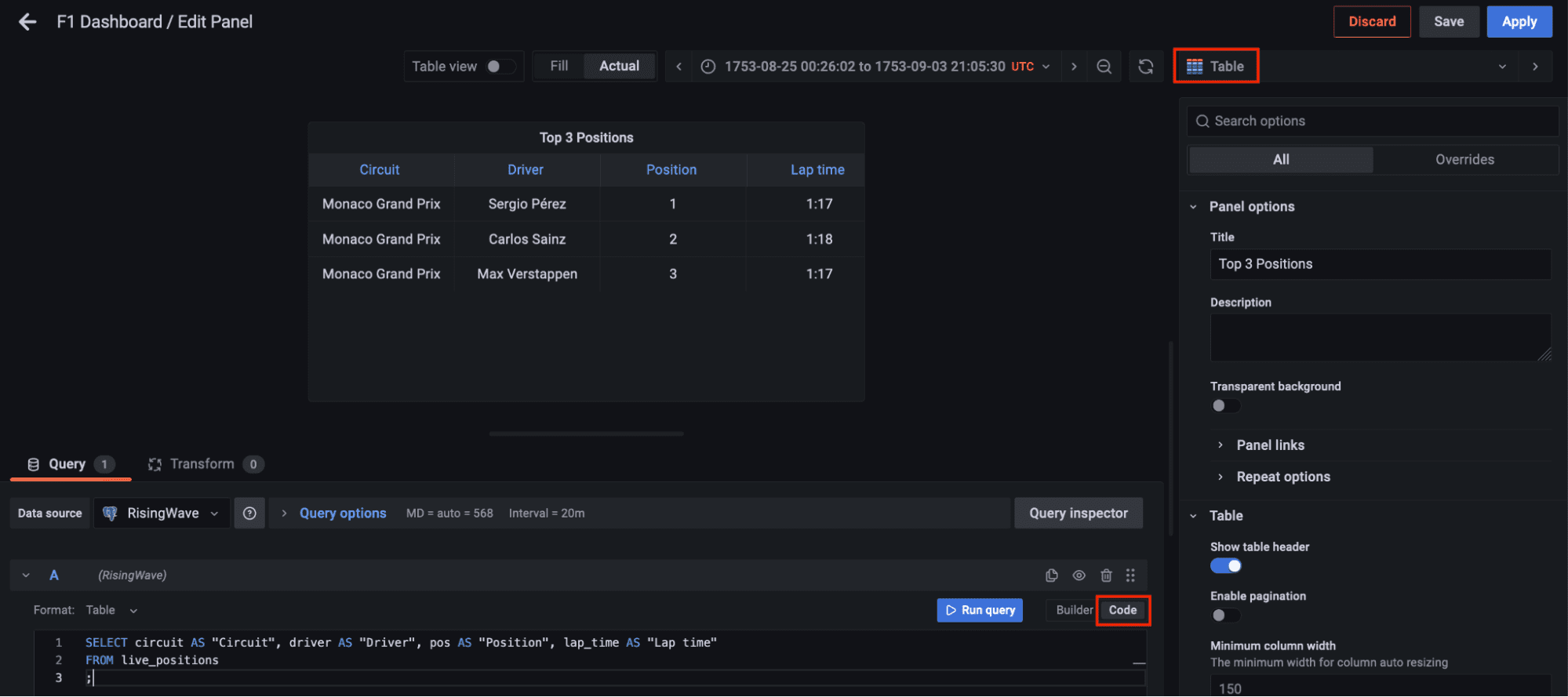
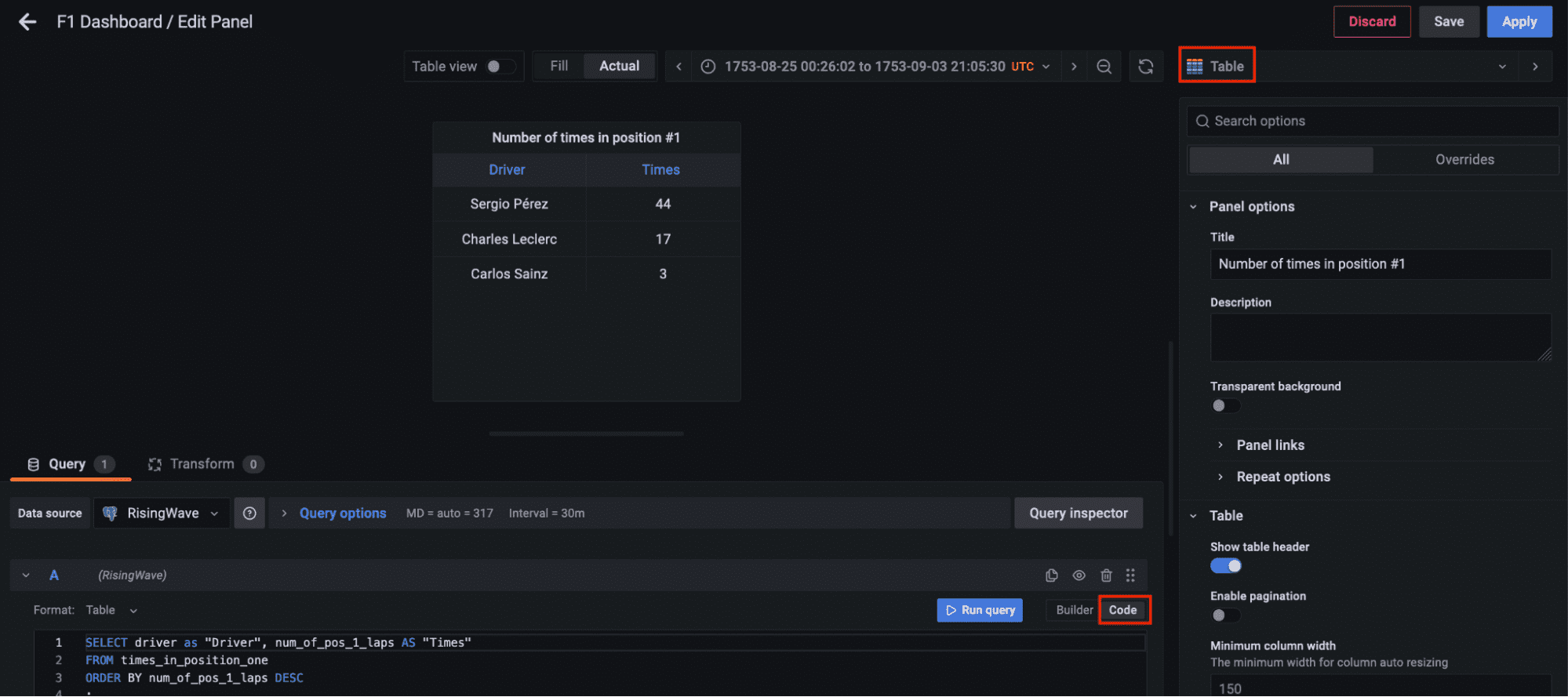
今、左のパネルのダッシュボードに移動し、新しいダッシュボードオプションをクリックして新しいパネルを追加します。テーブルの可視化を選択し、コードタブに切り替えてmaterialized view live_positions をクエリして、上位3つのポジションの結合データを表示しましょう。
コード: 著者
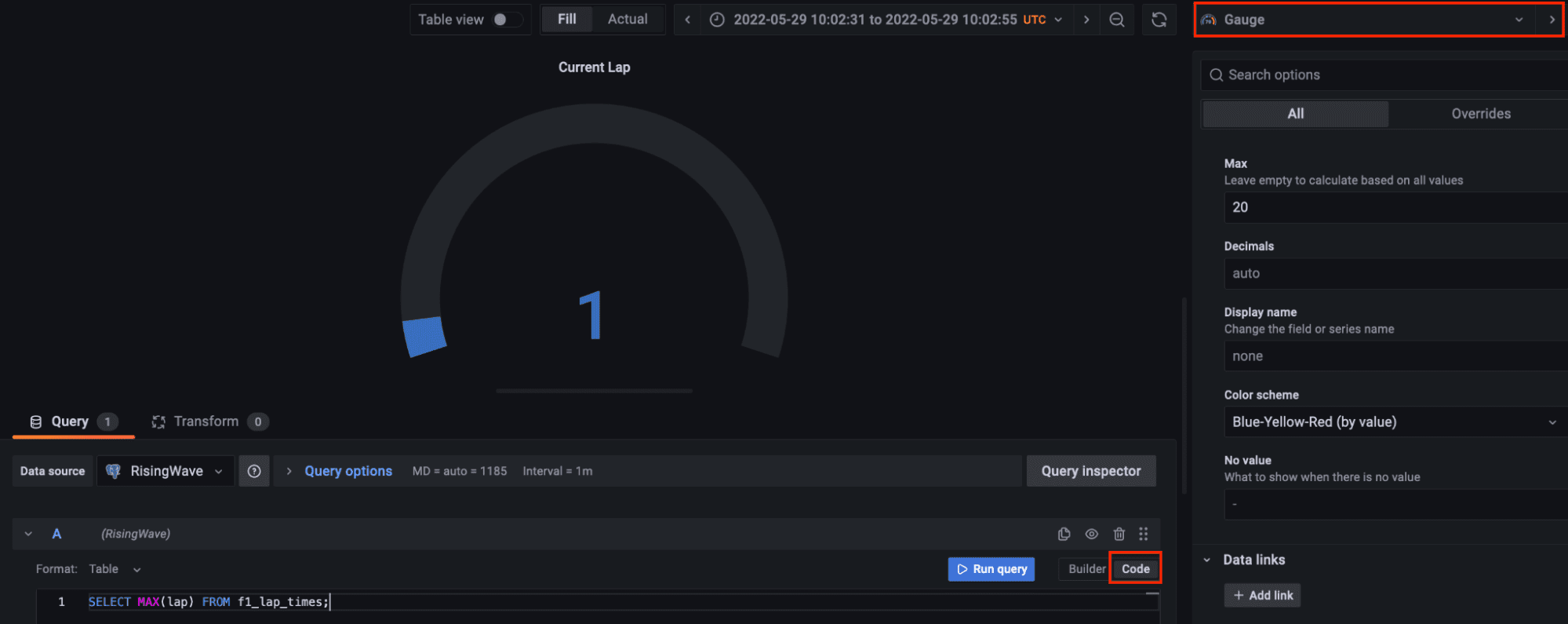
現在のラップを可視化するために、別のパネルを追加しましょう。ゲージの可視化を選択し、コードタブでストリーミングデータで利用可能な最大ラップをクエリしてください。ゲージのカスタマイズはあなた次第です。
コード: 著者
最後に、materialized view times_in_position_one をクエリして、レース全体でドライバーが1位になった回数をリアルタイムで表示するための別のパネルを追加しましょう。
コード: 著者
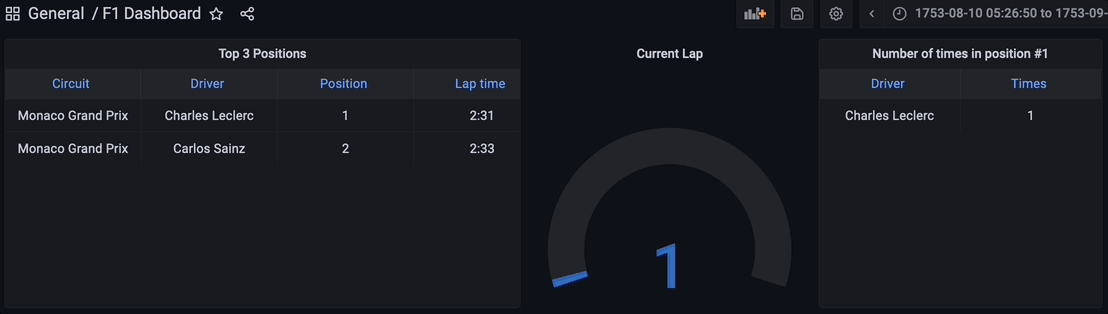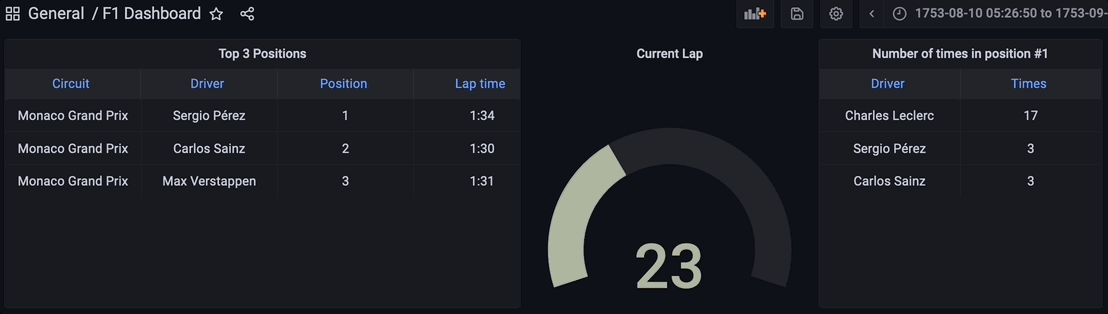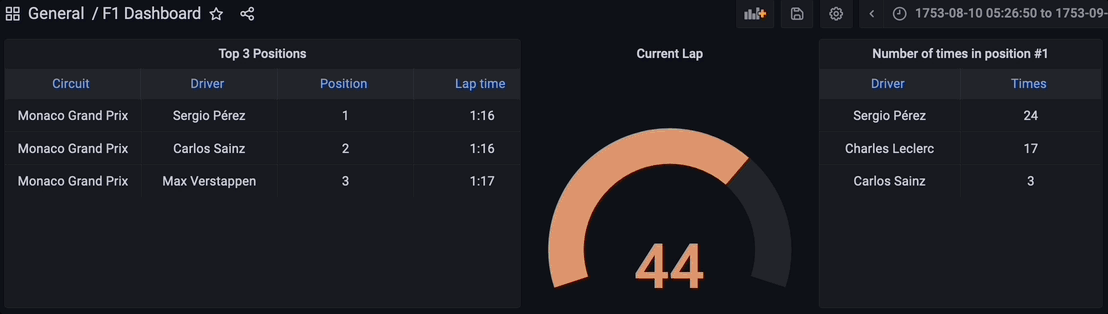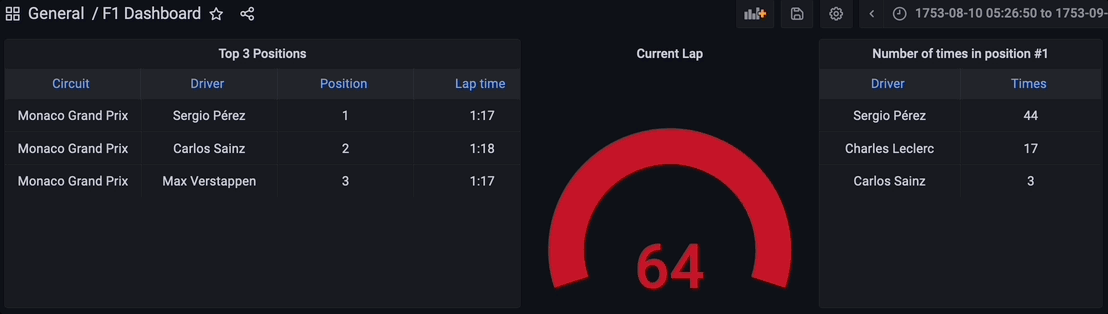
結果の可視化
最終的に、ストリーミングデータパイプラインのすべてのコンポーネントが起動しています。PythonスクリプトはKafkaトピックを介してデータをストリーミングし始めるために実行され、ストリーミングデータベースRisingWaveはデータをリアルタイムで読み取り、処理し、結合します。materialized view f1_lap_times はKafkaトピックからデータを読み取り、Grafanaダッシュボードの各パネルはリアルタイムでデータを結合して詳細なデータを表示するための異なるmaterialized viewです。materialized viewsはレースとドライバーのテーブルへの結合によって処理を簡素化し、Grafanaダッシュボードはmaterialized viewsをクエリし、すべての処理を簡素化しています。これはストリーミングデータベースRisingWaveで処理されたmaterialized viewsのおかげです。
Javier Granados はデータパイプラインについて読んだり書いたりするのが好きなシニアデータエンジニアです。彼は主にAWS上のクラウドパイプラインに特化していますが、常に新しい技術やトレンドを探求しています。VoAGIで彼に会えます https://medium.com/@JavierGr
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
