「AWSを基にしたカスケーディングデータパイプラインの構築方法」
Building a Cascading Data Pipeline based on AWS
自動的でスケーラブルかつ強力
今日は、常に誇りに思っているデータエンジニアリングプロジェクトの構築経験を共有します。なぜ私がツールやAWSのコンポーネントを使用したのか、そしてアーキテクチャをどのように設計したのかを学ぶことができます。
免責事項: このテキストの内容は、無名のエンティティとの経験に触発されています。ただし、商業上の重要な利益や詳細は意図的に架空のデータ/コードで置き換えたり、省略したりして機密性とプライバシーを維持するために行われています。したがって、実際の商業上の利益の全体的かつ正確な範囲は予約されています。
前提条件
- Pythonの知識
- DynamoDB、Lambdaサーバーレス、SQS、CloudWatchなどのAWSコンポーネントの理解
- YAMLおよびSAM CLIでの快適なコーディング経験
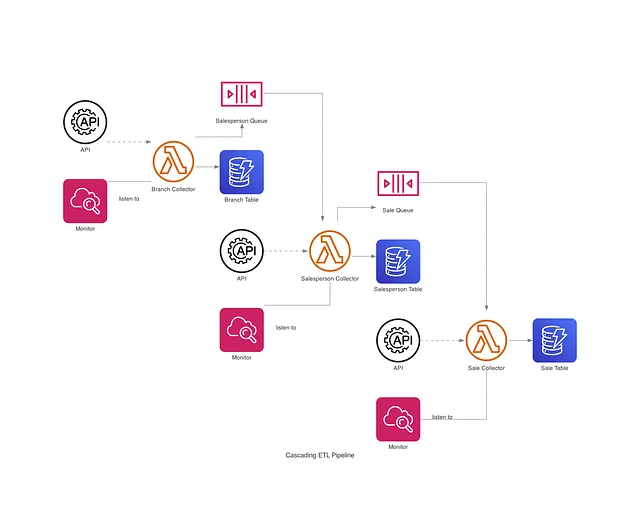
背景
データエンジニアであり、常にデータウェアハウスのデータを更新する必要があるとします。例えば、定期的にダンダー・ミフリン・ペーパー社の販売記録と同期する責任があります。(これは現実的なシナリオではありませんが、楽しんでください 🙂 !)データはベンダーのAPI経由で送信され、支店の情報、従業員(実際には営業員のみが考慮されます)、および売上が最新であることを確認する責任があります。提供されるAPIには次の3つのパスがあります:
/branches:指定された支店のメタデータを取得するためのクエリパラメータとして支店名を受け入れます;/employees:特定の支店のすべての従業員の情報を取得するためのクエリパラメータとして支店IDを受け入れます。応答には従業員の職種を示すキーバリューペアが含まれます;/sales:販売員のIDをクエリパラメータとして受け入れ、販売員の過去の売上記録を取得します。応答にはトランザクションが完了した時点を示すキーバリューペアが含まれます。
一般的に言って、APIの返り値は次のようになります:
- 「Pythonのタイピングに関するデータサイエンティストのガイド:コードの明瞭さを向上させるための手引き」
- 「データサイエンスプロジェクトを変革する:YAMLファイルに変数を保存する利点を見つけよう」
- Pythonを使用した探索的データ分析(EDA)の実践ガイド
/branches パス:
{ "result": [ { "id": 1, "branch_name": "スクラントン"…We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- テキストのポテンシャルを引き出す:プリエンベッドテキストクリーニング方法の詳細な調査
- 「生データから洗練されたデータへ:データの前処理を通じた旅 – パート1」
- 「ソフトウェア開発におけるAIの活用:ソリューション戦略と実装」
- 「Med-PaLM Multimodal(Med-PaLM M)をご紹介します:柔軟にエンコードし、解釈するバイオメディカルデータの大規模なマルチモーダル生成モデル」
- 「BI-LSTMを用いた次の単語予測のマスタリング:包括的なガイド」
- 「研究論文メタデータの簡単な説明」
- 「Scikit-Learnクラスを使用したカスタムトランスフォーマを作成するためのシンプルなアプローチ」
