「ビルドしてプレイ!LLM搭載のあなた自身のV&Lモデル!」
Build and play! Your own V&L model with LLM!
LLMを統合したGITビジョン言語モデルの開発
この記事の要約:
- Microsoftによって開発されたビジョン言語モデルであるGITの説明
- PyTorchとHugging FaceのTransformersを使用して、GITの言語モデルを大規模な言語モデル(LLM)で置き換える方法の紹介
- LoRAを使用してGIT-LLMモデルを微調整する方法の紹介
- 開発されたモデルのテストと議論
- GITの画像エンコーダによって埋め込まれた「画像埋め込み」が「テキスト埋め込み」と同じ空間で特定の文字を示すかどうかの調査
大規模な言語モデル(LLM)はますます価値を示しています。画像をLLMに組み込むことで、それらはさらに有用なビジョン言語モデルとなります。この記事では、GIT-LLMと呼ばれるシンプルで強力なビジョン言語モデルの開発について説明します。コードの説明など、一部は少し煩雑に感じるかもしれませんので、結果のセクションに直接移動しても問題ありません。さまざまな実験と分析を行ったので、達成した成果を見るのが楽しめると思います。
実装は公開されているので、ぜひお試しください。
GitHub – turingmotors/heron
GitHubでアカウントを作成してturingmotors/heronの開発に貢献してください。
github.com
GITをLLMに変換する
この技術ブログの主題について詳しく見ていきましょう。
GITとは何ですか?
Generative Image-to-text Transformer(GIT)は、Microsoftが提案したビジョン言語モデルです。
arXiv:https://arxiv.org/abs/2205.14100Code:https://github.com/microsoft/GenerativeImage2Text
そのアーキテクチャは非常にシンプルです。画像エンコーダから抽出された特徴ベクトルを射影モジュールを使用してテキストのように扱えるベクトルに変換します。これらのベクトルは、画像のキャプションを生成したり、Q&Aを実行したりするために言語モデルに入力されます。このモデルは同様にビデオを処理することもできます。
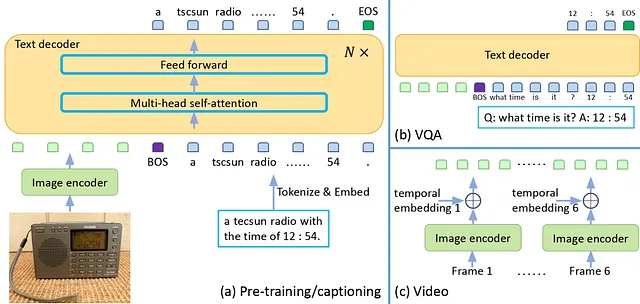
そのシンプルさにも関わらず、「Paper with code」のリーダーボードを見ると、多くのタスクで高い評価を受けていることがわかります。
https://paperswithcode.com/paper/git-a-generative-image-to-text-transformer
元々、GITは画像エンコーダとしてCLIPなどの強力なモデルを使用し、言語モデル部分をゼロからトレーニングしていました。しかし、この記事では、パワフルなLLMを使用して微調整することを試みます。ここでは、そのモデルを「GIT-LLM」と呼びます。
Hugging FaceのTransformersを使用したLLMの利用
私はHugging FaceのTransformersライブラリを使用してGIT-LLMを開発します。Transformersは、機械学習モデルの処理に使用するPythonライブラリです。多くの最先端の事前学習済みモデルを提供し、すぐに推論を実行できます。また、モデルのトレーニングや微調整のためのツールも提供しています。私は、Transformersが最近のLLM派生の開発に大きく貢献していると考えています。ほとんどの利用可能なLLMはTransformersで処理でき、それらから派生した多くのマルチモーダルモデルは、開発と微調整のための基盤としてTransformersを使用しています。
以下はTransformersのモデルを使用するための最もシンプルなコードです。AutoModelとAutoTokenizerを使用してLLMを簡単に試すことができます。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "facebook/opt-350m"model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "Hello, I'm am conscious and"input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")sample = model.generate(**input_ids, max_length=64)print(tokenizer.decode(sample[0]))# Hello, I'm am conscious and I'm a bit of a noob. I'm looking for a good place to start.OPTモデルが持つパラメータを確認しましょう。AutoModelForCausalLMによって作成されたモデルをプリントします。
OPTForCausalLM( (model): OPTModel( (decoder): OPTDecoder( (embed_tokens): Embedding(50272, 512, padding_idx=1) (embed_positions): OPTLearnedPositionalEmbedding(2050, 1024) (project_out): Linear(in_features=1024, out_features=512, bias=False) (project_in): Linear(in_features=512, out_features=1024, bias=False) (layers): ModuleList( (0-23): 24 x OPTDecoderLayer( (self_attn): OPTAttention( (k_proj): Linear(in_features=1024, out_features=1024, bias=True) (v_proj): Linear(in_features=1024, out_features=1024, bias=True) (q_proj): Linear(in_features=1024, out_features=1024, bias=True) (out_proj): Linear(in_features=1024, out_features=1024, bias=True) ) (activation_fn): ReLU() (self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) (fc1): Linear(in_features=1024, out_features=4096, bias=True) (fc2): Linear(in_features=4096, out_features=1024, bias=True) (final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) ) ) ) ) (lm_head): Linear(in_features=512, out_features=50272, bias=False))非常にシンプルです。initial embed_tokensの入力次元と、final lm_headの出力次元は50,272です。これはモデルのトレーニングに使用されたトークンの数を表しています。トークン化器の語彙サイズを確認しましょう:
print(tokenizer.vocab_size)# 50265bos_token、eos_token、unk_token、sep_token、pad_token、cls_token、mask_tokenなどの特殊トークンを含めて、50,272種類のトークンの次の単語の確率を予測します。
これらのモデルがどのように接続されているかは、実装を見ることで理解できます。シンプルな図では、次のようなフローを表現します:

構造とデータフローは非常にシンプルです。〇〇Modelと〇〇ForCausalLMは、異なる言語モデルでも似たようなフレームワークを持っています。〇〇Modelクラスは主に言語モデルの「Transformer」部分を表しています。例えば、テキスト分類のようなタスクを実行したい場合、この部分だけを使用します。〇〇ForCausalLMクラスはテキスト生成のためであり、Transformerで処理した後にトークンカウントのための分類器を適用します。損失の計算もこのクラスのforwardメソッド内で行われます。embed_positionsはプロジェクトインに追加される位置エンコーディングを示しています。
Transformersを使用したGITの使用方法
公式のGITドキュメントページを参考にして試してみましょう。画像の処理も行うため、Tokenizerも含むProcessorを使用します。
from PIL import Imageimport requestsfrom transformers import AutoProcessor, AutoModelForCausalLMmodel_name = "microsoft/git-base-coco"model = AutoModelForCausalLM.from_pretrained(model_name)processor = AutoProcessor.from_pretrained(model_name)# 画像のダウンロードと前処理url = "http://images.cocodataset.org/val2017/000000039769.jpg"image = Image.open(requests.get(url, stream=True).raw)pixel_values = processor(images=image, return_tensors="pt").pixel_values# テキストの前処理prompt = "これは何ですか?"inputs = processor( prompt, image, return_tensors="pt", max_length=64 )sample = model.generate(**inputs, max_length=64)print(processor.tokenizer.decode(sample[0]))# ソファで寝ている2匹の猫入力画像が「ソファで寝ている2匹の猫」という出力を生成しているため、うまく機能しているようです。
モデルの構造も見てみましょう:
GitForCausalLM( (git): GitModel( (embeddings): GitEmbeddings( (word_embeddings): Embedding(30522, 768, padding_idx=0) (position_embeddings): Embedding(1024, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (image_encoder): GitVisionModel( (vision_model): GitVisionTransformer( ... ) ) (encoder): GitEncoder( (layer): ModuleList( (0-5): 6 x GitLayer( ... ) ) ) (visual_projection): GitProjection( (visual_projection): Sequential( (0): Linear(in_features=768, out_features=768, bias=True) (1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) ) ) ) (output): Linear(in_features=768, out_features=30522, bias=True))少し長いですが、分解してみると非常にシンプルです。GitForCausalLM内にはGitModelがあり、その中に以下のモジュールがあります:
- embeddings (GitEmbeddings)
- image_encoder (GitVisionModel)
- encoder (GitEncoder)
- visual_projection (GitProjection)
- output (Linear)
OPTとの主な違いは、イメージをプロンプトのようなベクトルに変換するモジュールであるGitVisionModelとGitProjectionの存在です。言語モデルはOPTではデコーダーを使用し、GITではエンコーダーを使用しますが、これはアテンションマスクの構築方法の違いを示しているだけです。トランスフォーマーレイヤーにはわずかな違いがあるかもしれませんが、その機能は基本的に同じです。GITは、画像のすべての特徴に対してアテンションを適用し、テキストの特徴には因果マスクを使用するため、名前をエンコーダーとしています。
モデルの接続を見てみましょう:
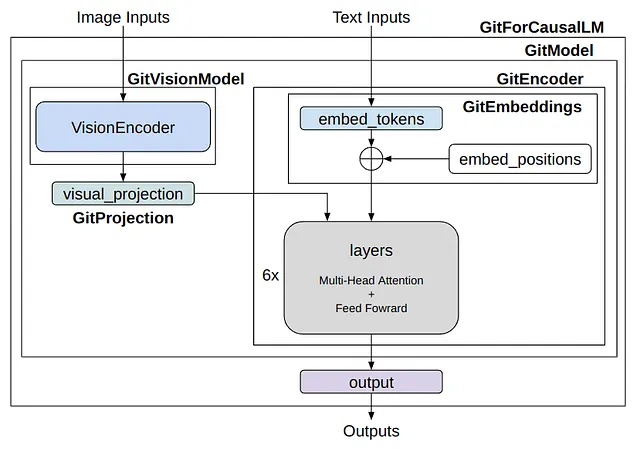
イメージ情報は、GitVisionModelとGitProjectionによってテキストの埋め込みと一致させるために処理されます。その後、テキストの埋め込みとともに言語モデルの「トランスフォーマー」レイヤーに入力されます。微妙な違いはありますが、言語モデルに関連する部分はほとんど同じように開発されています。
GITのアテンションマスク
通常の言語モデルとGIT言語モデルのアーキテクチャはほぼ同じですが、アテンションマスクの適用方法が異なります。
言語モデルでは、未来のトークンを予測する際に過去のトークンを見ないようにアテンションマスクを適用します。これは「因果アテンション」と呼ばれる方法で、以下の図の左側に対応します。最初の列のトークンは自身のみを参照し、後続の単語に対しては自己アテンションが適用されないようにします。2番目の列では、2番目の単語までの自己アテンションが適用され、3番目の単語以降は0になります。このようなマスキングにより、次の単語を効果的に予測するためにトレーニングすることができます。
GITの入力には、イメージトークンとテキストトークンの2種類のトークンがあります。すべてのイメージトークンは同時に使用され、次のトークンを予測するために使用されないため、因果アテンションは適していません。一方、テキストトークンには因果アテンションが必要です。右側の図のようなマスクがこれを実現するために設計されています。イメージ情報の上位3行では、すべてのトークン情報に対してセルフアテンションが適用されます。テキストトークンからは、一列下に移動すると参照できる単語数が増えます。
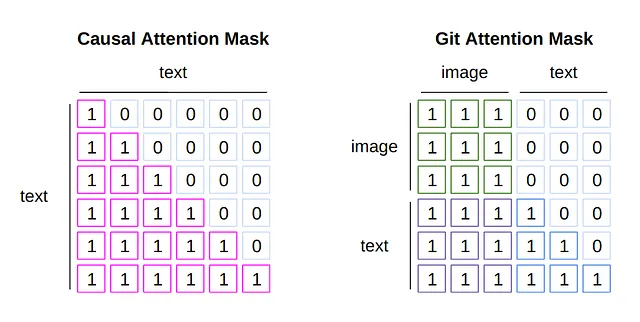
GITマスクを作成するためのコードも確認しましょう。GITマスクを作成するためのスニペットは次のようになります:
import torchdef create_git_attention_mask( tgt: torch.Tensor, memory: torch.Tensor,) -> torch.Tensor: num_tgt = tgt.shape[1] num_memory = memory.shape[1] # attentionを適用する領域は0、attentionを適用しない領域は-inf top_left = torch.zeros((num_memory, num_memory)) top_right = torch.full( (num_memory, num_tgt), float("-inf"), ) bottom_left = torch.zeros( (num_tgt, num_memory), ) # 因果的なアテンションマスク bottom_right = torch.triu(torch.ones(tgt.shape[1], tgt.shape[1]), diagonal=1) bottom_right = bottom_right.masked_fill(bottom_right == 1, float("-inf")) # マスクを連結 left = torch.cat((top_left, bottom_left), dim=0) right = torch.cat((top_right, bottom_right), dim=0) # マルチヘッド用の軸を追加 full_attention_mask = torch.cat((left, right), dim=1)[None, None, :] return full_attention_mask# batch_size, sequence, feature_dimvisual_feature = torch.rand(1, 3, 128)text_feature = torch.rand(1, 4, 128)mask = create_git_attention_mask(tgt=text_feature, memory=visual_feature)print(mask)"""tensor([[[[0., 0., 0., -inf, -inf, -inf, -inf], [0., 0., 0., -inf, -inf, -inf, -inf], [0., 0., 0., -inf, -inf, -inf, -inf], [0., 0., 0., 0., -inf, -inf, -inf], [0., 0., 0., 0., 0., -inf, -inf], [0., 0., 0., 0., 0., 0., -inf], [0., 0., 0., 0., 0., 0., 0.]]]])"""マスクを注意重みに追加します。したがって、セルフアテンションが行われる部分は0であり、アテンションに含まれていない部分は-infです。このマスクを提供することで、テキスト部分のみが因果的なアテンションを行うことができます。ビジョン言語モデルでは、このようにマスクを効果的に作成し使用することが重要です。
GITとOPTの接続
では、GITとOPTを接続しましょう。目標は、図に示すモデルを作成することです。

一般的な実装については、modeling_git.pyを参照してください。
最も重要な部分は、GitOPTModelです。この中で、ビジョンエンコーダーをLLMに接続する必要があります。いくつかのキーコンポーネントを説明します。
class GitOPTModel(OPTModel): def __init__(self, config: OPTConfig): super(GitOPTModel, self).__init__(config) self.image_encoder = CLIPVisionModel.from_pretrained(config.vision_model_name) self.visual_projection = GitProjection(config)__init__関数内では、さまざまなモジュールがインスタンス化されます。superはOPTModelを初期化します。GITでは、CLIPでトレーニングされた強力な画像エンコーダーを使用することが推奨されているため、CLIPでトレーニングされたViTと互換性があるようにしました。GitProjectionは、元のGITの実装から取得されます。
forward関数の内部を見てみましょう。この実装は、OPTDecoderのforward部分を基にしており、画像エンコーダーからの情報が追加されています。少し長くなっていますが、コードにコメントを追加しているので、各ステップに従ってください。
class GitOPTModel(OPTModel): ... def forward( self, input_ids: Optional[torch.Tensor] = None, attention_mask: Optional[torch.Tensor] = None, pixel_values: Optional[torch.Tensor] = None, ) -> BaseModelOutputWithPooling: seq_length = input_shape[1] # 1. ViTを使用して画像の特徴を抽出する visual_features = self.image_encoder(pixel_values).last_hidden_state # 2. ViTによって抽出された特徴をプロンプトのようなイメージ埋め込みに変換する projected_visual_features = self.visual_projection(visual_features) # 3. トークンをベクトル化する inputs_embeds = self.decoder.embed_tokens(input_ids) # 4. 位置エンコーディングを取得する pos_embeds = self.embed_positions(attention_mask, 0) # 5. OPTに特有のテキスト埋め込みの次元調整 inputs_embeds = self.decoder.project_in(inputs_embeds) # 6. テキスト埋め込み + 位置エンコーディング embedding_output = inputs_embeds + pos_embeds # 7. イメージ埋め込みとテキスト埋め込みを連結する hidden_states = torch.cat((projected_visual_features, embedding_output), dim=1) # 8. テキスト領域の因果的なアテンションマスクを作成する tgt_mask = self._generate_future_mask( seq_length, embedding_output.dtype, embedding_output.device ) # 9. GIT用のアテンションマスクを作成する combined_attention_mask = self.create_attention_mask( tgt=embedding_output, memory=projected_visual_features, tgt_mask=tgt_mask, past_key_values_length=0, ) # 10. デコーダーレイヤーを繰り返し通過させ、言語モデルの主要な部分 for idx, decoder_layer in enumerate(self.decoder.layers): layer_outputs = decoder_layer( hidden_states, attention_mask=combined_attention_mask, output_attentions=output_attentions, use_cache=use_cache, ) hidden_states = layer_outputs[0] # 11. OPTに特有のMLPの次元調整 hidden_states = self.decoder.project_out(hidden_states) # 12. 出力インターフェースを整列させる return BaseModelOutputWithPast( last_hidden_state=hidden_states, past_key_values=next_cache, hidden_states=all_hidden_states, attentions=all_self_attns, )複雑に見えるかもしれませんが、各ステップを進めていくと、図に示されたフローに従っていることがわかります。実際のコードはもう少し複雑に見えるかもしれませんが、まずは主要なプロセスを把握することで、他の部分の理解が容易になります。これは疑似コードですので、詳細な部分については公開された実装を参照してください。
最後に、GITOPTForCausalLMの部分について簡単に見てみましょう。
class GitOPTForCausalLM(OPTForCausalLM): def __init__( self, config, ): super(GitOPTForCausalLM, self).__init__(config) self.model = GitOPTModel(config) def forward( ... ) -> CausalLMOutputWithPast: outputs = self.model( ... ) sequence_output = outputs[0] logits = self.lm_head(sequence_output) loss = None if labels is not None: # タスクとして次の単語を予測する num_image_tokens = self.image_patch_tokens shifted_logits = logits[:, num_image_tokens:-1, :].contiguous() labels = labels[:, 1:].contiguous() loss_fct = CrossEntropyLoss() loss = loss_fct(shifted_logits.view(-1, self.config.vocab_size), labels.view(-1)) return CausalLMOutputWithPast( loss=loss, logits=logits, ... )モデル内部の処理はシンプルです。ラベルが提供される場合、つまり訓練中は、ロスの計算もforward内で行われます。shifted_logitsでは、テキストトークンの最初のトークンから最後から2番目のトークンまでのトークンが取得されます。そして、ラベルを1つずらしたものとのクロスエントロピーロスが計算されます。
注意すべき点は、初期化関数でGitOPTModelを割り当てる変数の名前をself.modelとすることです。親クラスOPTForCausalLMの実装を確認すると、superの初期化中に最初にself.modelにOPTが配置されることがわかります。このインスタンス変数の名前を変更すると、2つのOPTを保持することになり、メモリを圧迫する可能性があります。
LoRA拡張
LLMを効果的にファインチューニングするために、Parameter-Efficient Fine-Tuning(PEFT)というライブラリを使用します。これはHugging Faceによって開発されており、Transforsとシームレスに統合されています。PEFTにはさまざまな手法がありますが、今回は一般的に使用される手法であるLow-rank adaptation(LoRA)を使用していくつかの実験を行います。
モデルがPEFTをサポートしている場合、わずかな行数でLoRAを適用することができます。
from transformers import AutoModelForCausalLMfrom peft import get_peft_config, get_peft_model, LoraConfigmodel = AutoModelForCausalLM.from_pretrained('microsoft/git-base')peft_config = LoraConfig( task_type="CAUSAL_LM", r=8, lora_alpha=32, lora_dropout=0.1, target_modules=["v_proj"])peft_model = get_peft_model(model, peft_config)target_modules引数は、LoRAに変換したいモジュールを指定します。target_modulesとしてリストを指定すると、各文字列で終わるモジュールに対してLoRAに変換されるように実装されます。単純化のために、”value”(v_proj)のみがself attentionモジュールに対してLoRAが適用されます。
モデルでは、画像エンコーダ部分にViTが使用されています。注意が必要ですが、このように指定すると、ViTのself attention部分にもLoRAが適用される場合があります。少し手間がかかりますが、オーバーラップしないキー名の部分まで具体的に指定し、target_modulesに与えることでこれを回避することができます。
target_modules = [f"model.image_encoder.vision_model.encoder.{i}.self_attn.v_proj" for i in range(len(model.model.decoder))]結果として得られるモデルは、PeftModelForCausalLMクラスのインスタンスです。オリジナルのモデルがLoRAに変換されたものを保持するbase_modelというインスタンス変数があります。例として、ViTのself attentionのv_projにLoRAが適用されていることを示します。
(self_attn): GitVisionAttention( (k_proj): Linear(in_features=768, out_features=768, bias=True) (v_proj): Linear( in_features=768, out_features=768, bias=True (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=768, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=768, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() ) (q_proj): Linear(in_features=768, out_features=768, bias=True) (out_proj): Linear(in_features=768, out_features=768, bias=True))Linearモジュール内のv_projには、lora_Aやlora_Bなどの全結合層が追加されています。LoRA変換されたLinearモジュールは、PyTorchのLinearとLoraLayerを継承した同名のLinearクラスです。それはやや特殊なモジュールですので、詳細については実装をご覧ください。
PEFTで作成されたモデルは、デフォルトではLoRA部分以外の何も保存しません。merge_and_unloadメソッドを使用して保存する方法もありますが、Trainerを使用してトレーニング途中で保存されるすべてのモデルを保存したい場合は、別のアプローチが必要です。Trainerの_save_checkpointsメソッドをオーバーロードする方法もありますが、手間を省くために、今回はトレーニングフェーズ中にPeftModel内に保持されている元のモデル部分だけを取得する方法を採用しました。
model = get_peft_model(model, peft_config)model.base_model.model.lm_head = model.lm_headmodel = model.base_model.modelより効率的な方法があると思われますので、まだ研究中です。
GIT-LLMでの実験
これまでに開発したモデルを使用して、いくつかの実験を行いましょう。
トレーニングの設定やその他のセットアップの詳細については、公開された実装を参照してください。基本的には同じメソッドに従っています。
データセット:M3IT
実験のために、画像とテキストをペアにしたデータセットを使用し、簡単に統合できるデータセットを使用したかったです。Hugging FaceのDatasetsを調査していると、上海AI Labが開発したInstruction TuningのためのマルチモーダルデータセットであるM3ITに出会いました。Instruction Tuningは、データ量が限られていても印象的な結果をもたらす方法です。M3ITは、Instruction Tuningのために特に再注釈されたさまざまな既存のデータセットを持っているようです。
https://huggingface.co/datasets/MMInstruction/M3IT
このデータセットは使いやすいので、以下の実験に利用することにしました。
M3ITを使用してトレーニングするには、カスタムのPyTorchデータセットを作成する必要があります。
class SupervisedDataset(Dataset): def __init__( self, vision_model_name: str, model_name: str, loaded_dataset: datasets.GeneratorBasedBuilder, max_length: int = 128, ): super(SupervisedDataset, self).__init__() self.loaded_dataset = loaded_dataset self.max_length = max_length self.processor = AutoProcessor.from_pretrained("microsoft/git-base") # 各モデルに対応するProcessorの設定 self.processor.image_processor = CLIPImageProcessor.from_pretrained(vision_model_name) self.processor.tokenizer = AutoTokenizer.from_pretrained( model_name, padding_side="right", use_fast=False ) def __len__(self) -> int: return len(self.loaded_dataset) def __getitem__(self, index) -> dict: # cf: https://huggingface.co/datasets/MMInstruction/M3IT#data-instances row = self.loaded_dataset[index] # テキスト入力の作成 text = f'##Instruction: {row["instruction"]} ##Question: {row["inputs"]} ##Answer: {row["outputs"]}' # 画像の読み込み image_base64_str_list = row["image_base64_str"] # str (base64) img = Image.open(BytesIO(b64decode(image_base64_str_list[0]))) inputs = self.processor( text, img, return_tensors="pt", max_length=self.max_length, padding="max_length", truncation=True, ) # バッチサイズ1 -> アンバッチ inputs = {k: v[0] for k, v in inputs.items()} inputs["labels"] = inputs["input_ids"] return inputs__init__関数で、image_processorとtokenizerはそれぞれのモデルに対応しています。渡されるloaded_dataset引数は、MMInstruction/M3ITデータセットから取得する必要があります。
coco_datasets = datasets.load_dataset("MMInstruction/M3IT", "coco")test_dataset = coco_datasets["test"]COCO Instruction Tuningデータセットのトレーニング、検証、テストの分割は、元のデータセットと同じで、それぞれ566,747、25,010、25,010の画像-テキストペアです。VQAやVideoなどの他のデータセットも同様に扱うことができるため、検証目的の汎用的なデータセットとなっています。
サンプルデータは次のようになります:

この画像のキャプションは以下の通りです:
##指示:画像の要素、それらの関係、および注目すべき詳細をキャプチャする、簡潔な説明を書いてください。##質問:##回答:赤いヘルメットをかぶった男性が小さなモペットで土の道を走っています。
COCOデータセットでは、キャプションの部分は空白のままです。
プロセッサの動作について詳しく掘り下げましょう。基本的に、画像を正規化し、テキストをトークン化します。max_lengthより短い入力もパディングされます。プロセッサによって返される処理済みのデータは、以下の要素を含む辞書です:
- input_ids:トークン化されたテキストの配列。
- attention_mask:トークン化されたテキストのマスク(パディングは0)。
- pixel_values:正規化された画像の配列。また、チャネルを最初に変換されています。
これらのキー名は、モデルのforward関数の引数に対応しているため、変更しないでください。最後に、input_idsは、labelsというキーに直接渡されます。GitOPTForCausalLMのforward関数では、次のトークンを予測することで損失を計算します。
実験1:ファインチューニングの場所の決定
GITモデルの研究論文では、強力なビジョンエンコーダが使用され、言語モデルにはランダムなパラメータが採用されていると説明されています。今回は、最終的に7Bクラスの言語モデルを使用することが目標なので、事前学習済みモデルを言語モデルに適用します。ファインチューニングのために以下のモジュールが検討されます。GIT Projectionは初期化されたモジュールなので、常に含まれます。一部の組み合わせは冗長に見えるかもしれませんが、この試行ではあまり気にせずに探索されます。
トレーニングには、以下のモジュールが勾配を持つように設定され、他のモジュールは勾配を持たないように変更されます。
# Specifying the parameters to train (training all would increase memory usage)for name, p in model.model.named_parameters(): if np.any([k in name for k in keys_finetune]): p.requires_grad = True else: p.requires_grad = Falseこの試験で使用されるビジョンエンコーダとLLMは次のとおりです:
- openai/clip-vit-base-patch16
- facebook/opt-350m
トレーニングにはCOCOデータセットが使用され、5エポック続きます。
以下は各実験でトレーニングされるターゲットモジュールです:
- Proj:GIT Projection。ランダムに初期化されているため、常にトレーニングされます。
- LoRA:言語モデルのself attentionのQuery、Key、Valueが適用されました。
- OPT:すべてのレイヤーがトレーニングされました。
- ViT:すべてのレイヤーがトレーニングされました。
- Head:OPTの最終的なlm_headがトレーニングされました。
(注:LoRAはViTに適用することもできますが、実験を複雑にするのを避けるため、今回は含まれていません。)
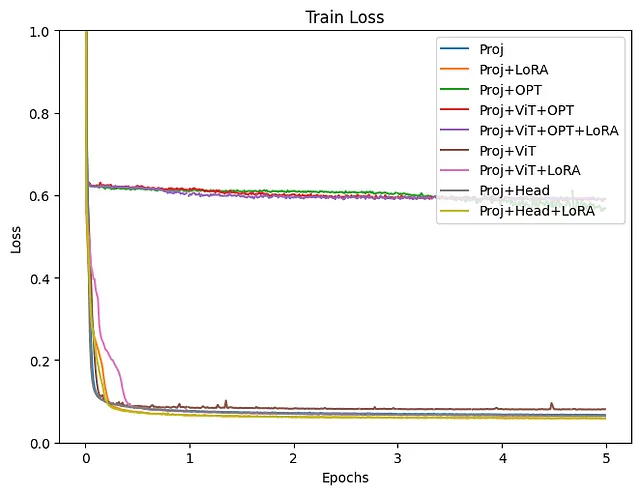
トレーニングの損失プロットに示されているように、一部のグループはうまく機能していないことが明らかです。これはOPTがトレーニングに含まれている場合の場合です。すべての実験はかなり似た条件の下で行われましたが、言語モデルのファインチューニングには学習率などのより詳細な調整が必要かもしれません。OPTがトレーニングに含まれていないモデルを除いた結果は、次に調べられます。
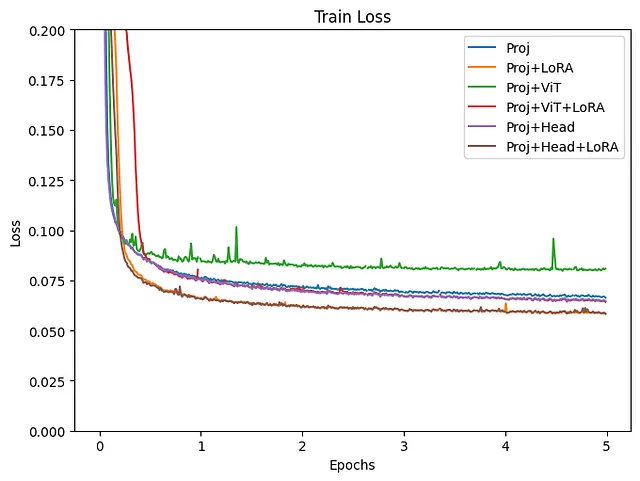
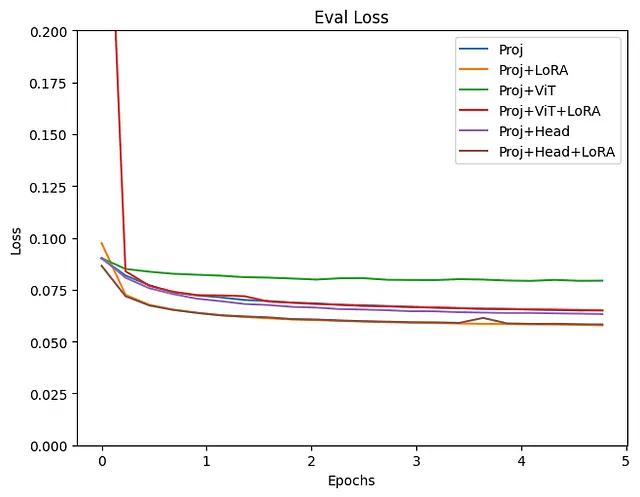
トレーニングと検証の損失の両方が、Projection+LoRAモデルで最も減少しました。最終的なHead層のファインチューニングでは、ほぼ同様の結果が得られました。ViTもトレーニングすると、損失がわずかに高くなり、結果が不安定になるようです。ViTトレーニング中にLoRAを追加しても、損失は依然として高くなりがちです。このデータを使用したファインチューニングでは、パラメータを更新せずに事前にトレーニングされたViTモデルを使用すると、より安定した結果が得られるようです。LoRAの有効性はさまざまな場所で認められており、この実験からもLLMにLoRAを追加することで、トレーニングと検証の損失が改善されることが明らかです。
いくつかのテストデータに対する推論結果を見直してみましょう:

OPT自体をトレーニングすると、損失の結果と同様に結果は悪く、モデルは言葉に詰まってしまいます。また、ViTをトレーニングすると、出力は意味的には正しいですが、与えられた画像とはまったく異なるものを説明します。ただし、他の結果は画像の特徴をある程度捉えているようです。たとえば、最初の画像では「cat」と「banana」が言及され、2番目の画像では「traffic sign」が識別されます。LoRAの有無で結果を比較すると、後者は類似した単語を繰り返し使用する傾向がありますが、LoRAを使用するとやや自然な結果になるようです。Headをトレーニングすると、「eating」の代わりに「playing」を使用するなど、興味深い出力が得られます。これらの結果にはいくつかの不自然な要素がありますが、画像の特徴を捉えるためにトレーニングは成功したと推測されます。
実験2:10億スケールモデルの比較
以前の実験でのファインチューニング条件では、わずかに小さな言語モデルであるOPT-350mを使用しました。今度は、言語モデルを7Bモデルに切り替える意図があります。OPTにとどまらず、より強力なLLMsであるLLaMAとMPTも導入されます。
これら2つのモデルを統合するには、OPTと同様の方法で行うことができます。LlamaModelとMPTModelのforward関数を参照して、プロジェクションされた画像ベクトルをテキストトークンと組み合わせ、マスクを因果的注意マスクからGITの注意マスクに変更します。注意すべき点は1つあります。MPTの場合、マスクは(0、-inf)ではなく(False、True)です。その後のプロセスは同様に実装できます。
OPTとともに7Bクラスのモデルを使用するには、モデル名をfacebook/opt-350mからfacebook/opt-6.7bに変更するだけです。
LLaMAの場合、LLaMA2が利用可能ですので、それが選択するモデルとなります。この事前トレーニング済みモデルを使用するには、MetaとHugging Faceの両方の承認が必要です。Hugging Faceのアカウントが必要ですので、準備を整えてください。承認は通常数時間以内に行われます。その後、トレーニングが実行される端末でHugging Faceにログインします。
huggingface-cli loginHugging Faceアカウント→設定→アクセストークンで作成されたトークンを使用してログインできます。
トレーニングパラメータは一貫していて、COCOデータセットを使用し、3エポック続行します。実験1の結果に基づいて、ファインチューニングに設定されたモジュールはProjection + LoRAでした。
結果を見てみましょう。
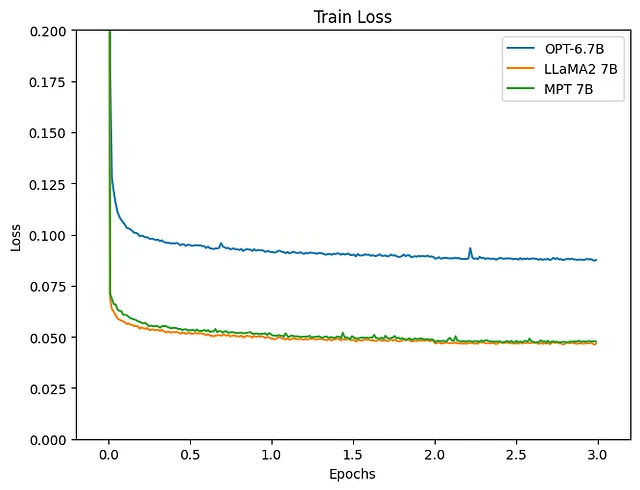
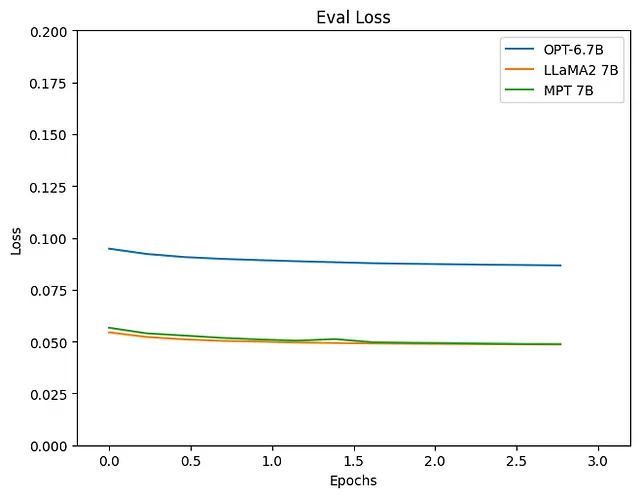
ロスを見ると、LLaMA2とMPTをLLMとして使用したモデルの方が満足のいく削減が見られます。推論結果も観察しましょう。

最初の画像に関しては、全てのモデルで表現がOPT-350mと比べてより自然に見えます。 “バナナとバナナのバナナ”のような奇妙な表現はありません。これはLLMの強みを示しています。2番目の画像に関しては、”信号機”や”建物”のようなフレーズにまだ苦労しています。このような複雑な画像には、ViTモデルのアップグレードを検討する必要があるかもしれません。
最後に、GPT-4で人気のある画像で推論を実行しましょう。

LLMを使用しているため、流暢な応答が期待されましたが、結果は非常にシンプルです。これは、モデルがCOCOだけで訓練されたためかもしれません。
実験3. データの増加
前の実験の結果が物足りなかったため、COCO以外のデータをトレーニングに取り入れることにしました。現在使用しているM3ITデータセットは非常に包括的であり、COCOと同じ形式の大量のデータを扱うことができます。
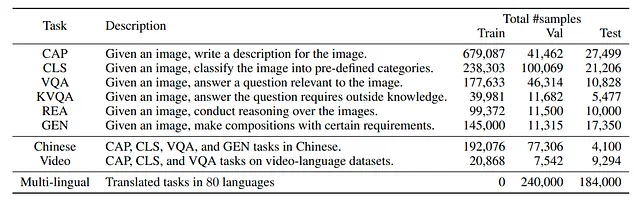
このソースからのデータを使用することが意図されており、「中国語」と「ビデオ」のカテゴリを除外しています。元々のCOCOトレーニングデータセットには566,747個のデータが含まれていました。これに追加のソースを組み合わせることで、データセットは1,361,650個に増加しました。サイズはほぼ2倍になりましたが、タスクの多様性が増したことにより、データセットの品質が向上したと考えられます。
複数のPytorchデータセットを扱うことは、ConcatDatasetを使用することで簡単に実現できます。
dataset_list = [ datasets.load_dataset("MMInstruction/M3IT", i) for i in m3it_name_list]train_dataset = torch.utils.data.ConcatDataset([d["train"] for d in dataset_list])トレーニングは1エポック行われ、LLaMA2モデルがプロジェクションとLoRAの微調整に使用されました(実験2と同様)。
今回は比較するロスがないため、すぐに推論結果に入りましょう。

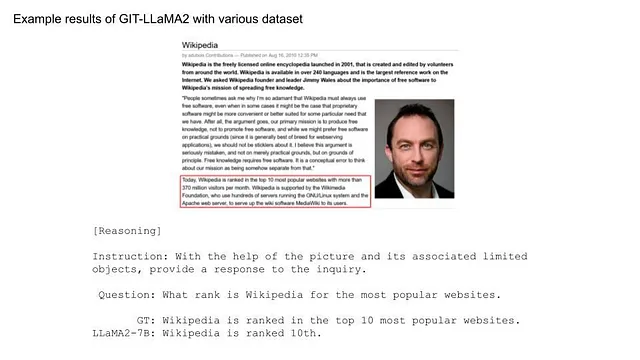

単純な問題の解決に加えて、モデルはより複雑な課題にも対応できるようになりました。キャプション付けだけでなく、より入り組んだタスクのためのデータセットを追加することで、その能力は大幅に拡大しました。たった1エポックのトレーニングでこのレベルの精度を達成することは驚くべきことでした。
以下の例の画像でテストしてみましょう。データセットの多様性が増したことに伴い、質問の提示方法がわずかに変更されました。

「傘」という説明はまだ変ですが、少しずつ改善されているようです。さらなる改善のためには、トレーニングエポックの数を増やし、より多様な種類やボリュームのデータセットを追加し、より強力なViTまたはLLMを活用する必要があります。それにしても、計算リソースやデータリソースを考えると、わずか半日でこのようなモデルが開発できたことは印象的です。
ボーナス実験。画像はテキストに変換されましたか?
GITの構造をもう一度見てみましょう。

図に示すように、ビジョンエンコーダによる特徴抽出後、画像はビジュアルプロジェクションを介してテキストと同等に扱われます。つまり、ビジュアルプロジェクションは画像ベクトルをテキストベクトルに変換している可能性があります。この実験では、ビジュアルプロジェクション後のベクトルがどのようになっているかを調査しました。
プロジェクション後のベクトルをテキストに戻すためのHeadを使用するオプションもありますが、Embeddingモジュールを使用してベクトル化されたベクトルでも、この方法では元のテキストに戻すことはできませんでした。したがって、LLMに入力される前のテキストベクトルに最も似ているベクトルに対して、対応する単語が割り当てられるべきです。トークナイザに登録されているすべてのトークンは、Embeddingモジュールを使用してベクトル化され、最も類似度の高いコサイン類似度を持つトークンが対象の単語として識別されました。
この実験で使用された画像は猫のものです。

さあ、解析を進めましょう(全体の解析はこちらでご覧いただけます)。まず、登録されたすべてのトークンをベクトル化します。
coco_datasets = datasets.load_dataset("MMInstruction/M3IT", "coco")test_dataset = coco_datasets["test"]supervised_test_dataset = SupervisedDataset(model_name, vision_model_name, test_dataset, 256)ids = range(supervised_test_dataset.processor.tokenizer.vocab_size)all_ids = torch.tensor([i for i in ids]).cuda()token_id_to_features = model.model.embed_tokens(all_ids)次に、ViTとプロジェクションによって単語に変換されたであろう画像ベクトルを抽出します。
inputs = supervised_test_dataset[0] # サンプルを適当に選ぶpixel_values = inputs["pixel_values"]out_vit = model.model.image_encoder(pixel_values).last_hidden_stateout_vit = model.model.visual_projection(out_vit)これらのベクトルと単語ベクトルの内積を計算し、最大値の結果を関連するトークンIDとしてデコードしました。
# ドット積nearest_token = out_vit[0] @ token_id_to_features.T# 最大値のインデックスは関連するトークンIDに対応visual_out = nearest_token.argmax(-1).cpu().numpy()decoded_text = supervised_test_dataset.processor.tokenizer.batch_decode(visual_out)print(decoded_text)"""['otr', 'eg', 'anto', 'rix', 'Nas', ...]"""printed decoded_textに表示されているように、いくつかの見慣れない単語が現れました。単語が繰り返されるため、カウントされました。
print(pd.Series(decoded_text).value_counts())"""mess 43atura 29せ 10Branch 10Enum 9bell 9worden 7..."""多くの見慣れない単語が現れたようです。位置によっては、意味のある情報を伝えるかもしれません。単語をキャット画像にプロットしてみましょう。
n_patches = 14IMAGE_HEIGHT = 468IMAGE_WIDTH = 640y_list = np.arange(15, IMAGE_HEIGHT, IMAGE_HEIGHT//n_patches)x_list = np.arange(10, IMAGE_WIDTH, IMAGE_WIDTH//n_patches)plt.figure()plt.axis("off")plt.imshow(np.array(image), alpha=0.4)for index in np.arange(n_patches ** 2): y_pos = index // n_patches x_pos = index - y_pos * n_patches y = y_list[y_pos] x = x_list[x_pos] # 最初のトークンはbosトークンなので除外されます word = decoded_text[index + 1] # 色で単語を区別するために plt.annotate(word, (x, y), size=7, color="blue")plt.show()plt.clf()plt.close()
頻繁に現れる単語は色分けされています。結果は、単に意味のある単語に投影されているわけではないことを示唆しています。単語「Cat」はキャット画像に重ねられているかもしれませんが、その意味は不明です。
この実験の結果は、高いコサイン類似度を持つ単語を強制的に選択することが原因であるかもしれません。いずれにせよ、このアプローチは単に単語をキャストして画像プロンプトを作成することではありません。画像から抽出されたベクトルは、トークン空間のベクトルに変換され、意味的な類似性を持ち、神秘的なプロンプトとして機能します。これ以上深く探求することは避けた方が良いかもしれません。
結論
この技術ブログ投稿では、LLMsをビジョン言語モデルGITに統合する方法を紹介しました。さらに、開発されたモデルを使用してさまざまな実験を行いました。成功と失敗がありましたが、ビジョン言語モデルを用いた実験を続けて洞察を蓄積していきたいと思います。この記事を参考にして、自分自身のビジョン言語モデルを作成し、その可能性を探求してみてください。

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
