「LangChainとGPT-3を使用して、ドキュメント用の透明な質問応答ボットを構築しましょう」
Build a transparent question-answering bot for documents using LangChain and GPT-3.
情報提供型QAボットの開発ガイド:使用されたソースを表示する

Question Answeringシステムは、大量のデータやドキュメントを分析する際に非常に役に立ちます。しかし、モデルが回答を生成するために使用したソース(つまり、ドキュメントの一部)は通常、最終的な回答に表示されません。
回答の文脈と起源を理解することは、正確な情報を求めるユーザーだけでなく、QAボットを継続的に改善したい開発者にとっても価値があります。回答にソースが含まれていることで、開発者はモデルの意思決定プロセスに関する貴重な知見を得ることができ、反復的な改善と微調整を容易にします。
この記事では、LangChainとGPT-3(text-davinci-003)を使用して、回答の生成に使用されたソースを表示する透明なQuestion-Answeringボットを作成する方法を2つの例を使用して紹介します。
最初の例では、質問に答えるためにウェブサイトのコンテンツを活用する透明なQAボットの作成方法を学びます。2番目の例では、異なるYouTubeの動画のトランスクリプトを使用し、タイムスタンプのあるものとないものの両方を探求します。
- オーストラリアのチームが、人工知能と人間の脳細胞を融合させるための助成金を獲得しました
- 「EU AI法案:AIの未来における有望な一歩か、危険なギャンブルか?」
- 時間シリーズのフーリエ変換:画像畳み込みとSciPyについて
データを処理してベクトルストアを作成する
GPT-3のようなLMMの機能を最大限に活用するためには、ドキュメント(例:ウェブサイトのコンテンツやYouTubeのトランスクリプト)を正しい形式(最初にチャンク、次に埋め込み)で処理し、ベクトルストアに格納する必要があります。以下の図1は、左から右への処理フローを示しています。
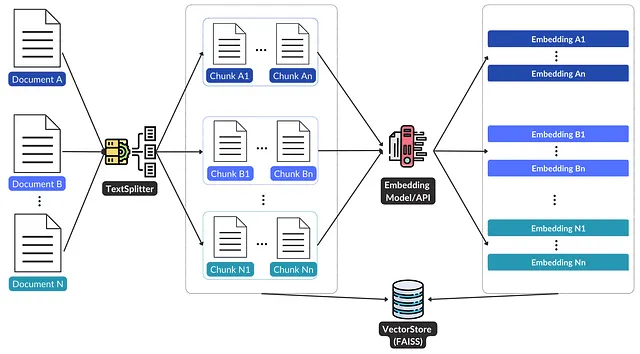
ウェブサイトのコンテンツの例
この例では、特にLinuxに焦点を当てたオープンソース技術に特化したウェブポータルであるIt’s FOSSのコンテンツを処理します。
まず、処理してベクトルストアに格納するすべての記事のリストを取得する必要があります。以下のコードは、すべての記事へのリンクが含まれるsitemap-posts.xmlファイルを読み込みます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






