Amazon SageMakerを使用してOpenChatkitモデルを利用したカスタムチャットボットアプリケーションを構築する
Build a custom chatbot application using the OpenChatkit model using Amazon SageMaker.
オープンソースの大規模言語モデル(LLMs)は人気を博し、研究者、開発者、および組織がこれらのモデルにアクセスしてイノベーションと実験を促進することができます。これにより、オープンソースコミュニティから協力を得て、LLMsの開発と改善に貢献することができます。オープンソースLLMsは、モデルアーキテクチャ、トレーニングプロセス、およびトレーニングデータの透明性を提供するため、研究者がモデルの動作を理解し、潜在的なバイアスを特定し、倫理的な懸念を解決することができます。これらのオープンソースLLMsにより、先進的な自然言語処理(NLP)技術を用いて、使命遂行に必要なビジネスアプリケーションを構築するために、広範なユーザーに利用可能になっています。GPT-NeoX、LLaMA、Alpaca、GPT4All、Vicuna、Dolly、およびOpenAssistantは、人気のあるオープンソースLLMsの一部です。
OpenChatKitは、Together Computerが2023年3月にApache-2.0ライセンスでリリースした汎用および特殊用途のチャットボットアプリケーションを構築するために使用されるオープンソースLLMです。このモデルにより、開発者はチャットボットの動作をより細かく制御し、特定のアプリケーションに合わせることができます。OpenChatKitは、完全にカスタマイズされた強力なチャットボットを構築するためのツール、ベースボット、およびビルディングブロックを提供します。主なコンポーネントは次のとおりです。
- EleutherAIのGPT-NeoX-20Bからの対話スタイルのデータに焦点を当てた
GPT-NeoXT-Chat-Base-20Bモデルを使用した、チャットに最適化されたLLM - タスクの高精度を実現するためにモデルを微調整するためのカスタマイズレシピ
- 文書リポジトリ、API、またはその他のライブ更新情報ソースからの情報でボットの応答を強化するための拡張可能な検索システム
- 質問に応答するボットをフィルタリングするためにGPT-JT-6Bから微調整されたモデレーションモデル
深層学習モデルの規模とサイズの増加は、生成AIアプリケーションにこれらのモデルを正常に展開するための障壁を生み出しています。低レイテンシと高スループットの要件を満たすために、モデル並列処理と量子化などの高度な方法を採用することが不可欠になってきます。これらの方法のアプリケーションに熟練していないため、多くのユーザーは、生成AIユースケースのためにサイズの大きなモデルをホストすることを開始するのに苦労しています。
この記事では、Amazon SageMakerでDJL ServingとDeepSpeedおよびHugging Face Accelerateなどのオープンソースモデル並列ライブラリを使用してOpenChatKitモデル(GPT-NeoXT-Chat-Base-20BおよびGPT-JT-Moderation-6B)モデルを展開する方法を示します。DJL Servingは、プログラミング言語に依存しない高性能なユニバーサルモデルサービングソリューションであり、Deep Java Library(DJL)で動作します。Hugging Face Accelerateライブラリを使用することで、大規模なモデルを複数のGPUに展開することを簡素化し、LLMsを分散して実行する負担を軽減できます。さあ、始めましょう!
- Amazon SageMaker で大規模なモデル推論 DLC を使用して Falcon-40B をデプロイする
- Amazon SageMakerを使用した生成型AIモデルにおいて、Forethoughtがコストを66%以上削減する方法
- BrainPadがAmazon Kendraを使用して内部の知識共有を促進する方法
拡張可能な検索システム
拡張可能な検索システムは、OpenChatKitの主要なコンポーネントの1つです。これにより、クローズドドメインの知識ベースに基づいてボットの応答をカスタマイズできます。LLMsは、モデルパラメータに事実上の知識を保持でき、微調整された場合にはダウンストリームのNLPタスクで驚異的なパフォーマンスを発揮することができますが、クローズドドメインの知識にアクセスし、正確に予測する能力は制限されています。したがって、知識集約的なタスクが与えられた場合、タスク固有のアーキテクチャに劣ることがあります。OpenChatKit検索システムを使用することで、Wikipedia、ドキュメントリポジトリ、API、およびその他の情報源などの外部知識源から応答に知識を追加できます。
検索システムにより、特定のクエリに対する関連情報を取得することで、チャットボットが現在の情報にアクセスし、回答を生成するために必要なコンテキストを提供できます。この検索システムの機能を説明するために、Wikipedia記事のインデックスをサポートし、情報検索のためにWeb検索APIを呼び出す方法の例コードを提供します。提供されたドキュメントに従って、推論プロセス中に検索システムを任意のデータセットまたはAPIに統合し、チャットボットが動的に更新されたデータを回答に組み込むことができます。
モデレーションモデル
モデレーションモデルは、チャットボットアプリケーションにおいてコンテンツフィルタリング、品質管理、ユーザーの安全、法的およびコンプライアンス上の理由で重要です。モデレーションは難しく主観的なタスクであり、チャットボットアプリケーションのドメインに大きく依存します。OpenChatKitは、チャットボットアプリケーションをモデレートし、入力テキストのプロンプトを監視して不適切なコンテンツをフィルタリングするためのツールを提供します。モデレーションモデルは、様々なニーズに合わせて適応およびカスタマイズされる良好なベースラインを提供します。
OpenChatKitは、6兆パラメータのモデレーションモデル GPT-JT-Moderation-6B を持っており、このモデルを使用してチャットボットをモデレートして、対象をモデレートされた主題に限定することができます。モデル自体にはある程度のモデレーションが組み込まれていますが、TogetherComputerは Ontocord.ai の OIG-moderation データセットを使用して GPT-JT-Moderation-6B モデルをトレーニングしました。このモデルはメインのチャットボットと並行して実行され、ユーザーの入力とボットからの回答に不適切な結果が含まれていないことを確認します。また、チャットボットのドメインに含まれない質問がある場合には、オーバーライドして対処することもできます。
以下の図は、OpenChatKitのワークフローを示しています。
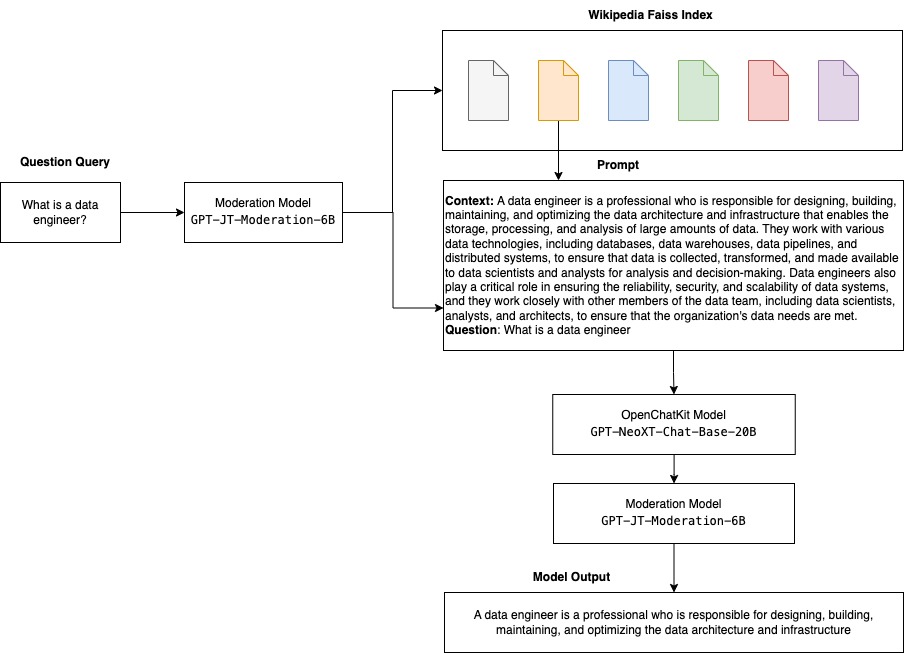
拡張可能な検索システムの使用例
この技術をさまざまな産業に適用して生成型AIアプリケーションを構築することができますが、ここでは金融産業での使用例について説明します。検索によって補完された生成は、特定の企業、業界、または金融商品に関する研究レポートを自動的に生成するために金融研究で使用することができます。内部の知識ベース、金融アーカイブ、ニュース記事、研究論文から関連情報を取得することで、主要な洞察、財務指標、市場動向、投資推奨をまとめた包括的なレポートを生成することができます。このソリューションを使用して、金融ニュース、市場のセンチメント、トレンドを監視および分析することもできます。
ソリューション概要
OpenChatKitモデルを使用してチャットボットを構築し、SageMakerに展開するには、以下の手順が必要です。
- チャットベースの
GPT-NeoXT-Chat-Base-20Bモデルをダウンロードし、モデルアーティファクトをAmazon Simple Storage Service(Amazon S3)にアップロードする。 - SageMakerの大規模モデルインファレンス(LMI)コンテナを使用し、プロパティを構成し、カスタムインファレンスコードを設定して、このモデルを展開する。
- モデルの分割を定義するためにモデルパラレル技術を構成し、DJLサービングプロパティでインファレンス最適化ライブラリを使用する。 DJLサービングのエンジンとしてHugging Face Accelerateを使用します。さらに、テンソルパラレル構成を定義してモデルを分割します。
- SageMakerモデルとエンドポイント構成を作成し、SageMakerエンドポイントを展開する。
GitHubリポジトリでノートブックを実行して、手順に従うことができます。
OpenChatKitモデルのダウンロード
まず、OpenChatKitベースモデルをダウンロードします。 huggingface_hub を使用し、snapshot_downloadを使用してモデルをダウンロードします。snapshot_downloadは、指定されたリビジョンでリポジトリ全体をダウンロードするものです。ダウンロードは並行して行われ、プロセスを高速化します。次のコードを参照してください。
from huggingface_hub import snapshot_download
from pathlib import Path
import os
# - This will download the model into the current directory where ever the jupyter notebook is running
local_model_path = Path("./openchatkit")
local_model_path.mkdir(exist_ok=True)
model_name = "togethercomputer/GPT-NeoXT-Chat-Base-20B"
# Only download pytorch checkpoint files
allow_patterns = ["*.json", "*.pt", "*.bin", "*.txt", "*.model"]
# - Leverage the snapshot library to donload the model since the model is stored in repository using LFS
chat_model_download_path = snapshot_download(
repo_id=model_name,#A user or an organization name and a repo name
cache_dir=local_model_path, #Path to the folder where cached files are stored.
allow_patterns=allow_patterns, #only files matching at least one pattern are downloaded.
)DJLサービングプロパティ
SageMaker LMIコンテナを使用すると、カスタムインファレンスコードを提供せずにカスタム大規模生成型AIモデルをホストすることができます。これは、入力データのカスタム前処理やモデルの予測のカスタム後処理がない場合に非常に便利です。カスタムインファレンスコードを使用してモデルを展開することもできます。この記事では、カスタムインファレンスコードを使用してOpenChatKitモデルを展開する方法を説明します。
SageMakerは、モデルアーティファクトをtar形式で期待しています。各OpenChatKitモデルを次のファイルで作成します:serving.properties および model.py 。
serving.properties 構成ファイルは、DJLサービングにどのモデル並列化およびインファレンス最適化ライブラリを使用するかを示します。この構成ファイルで使用する設定のリストを以下に示します。
openchatkit/serving.properties
engine = Python
option.tensor_parallel_degree = 4
option.s3url = {{s3url}}これには以下のパラメータが含まれています:
- engine – DJLが使用するエンジン。
- option.entryPoint – エントリーポイントPythonファイルまたはモジュール。これは使用されているエンジンに合わせる必要があります。
- option.s3url – モデルを含むS3バケットのURIを設定します。
- option.modelid – huggingface.coからモデルをダウンロードする場合、
option.modelidをhuggingface.coのモデルリポジトリ内にホストされている事前学習済みモデルのモデルIDに設定できます(https://huggingface.co/models)。コンテナは、このモデルIDを使用して、huggingface.coの対応するモデルリポジトリをダウンロードします。 - option.tensor_parallel_degree – DeepSpeedがモデルを分割する必要のあるGPUデバイスの数を設定します。このパラメータは、DJL Servingが実行されるときに起動されるモデルごとのワーカーの数も制御します。たとえば、8つのGPUマシンがある場合、8つのパーティションを作成している場合、リクエストを処理するために1つのモデルごとに1つのワーカーがあります。並列度を調整し、特定のモデルアーキテクチャとハードウェアプラットフォームに最適な値を特定する必要があります。これを推論適応並列性と呼びます。
詳細なオプションのリストについては、構成と設定を参照してください。
OpenChatKitモデル
OpenChatKitベースモデルの実装には、次の4つのファイルがあります:
- model.py – このファイルは、メインのOpenChatKit GPT-NeoXモデルの処理ロジックを実装します。推論入力リクエストを受け取り、モデルをロードし、Wikipediaインデックスをロードし、レスポンスを提供します。詳細については、
model.py(ノートブックの一部として作成)を参照してください。model.pyは、次の主要なクラスを使用します:- OpenChatKitService – これは、GPT-NeoXモデル、Faiss検索、および会話オブジェクトの間でデータを渡すことを処理します。
WikipediaIndexおよびConversationオブジェクトが初期化され、入力チャット会話がインデックスに送信されてWikipediaから関連するコンテンツを検索します。これにより、Amazon DynamoDBにプロンプトを保存するために必要な場合には一意のIDが生成されます。 - ChatModel – このクラスは、モデルとトークナイザをロードし、レスポンスを生成します。
tensor_parallel_degreeを使用して複数のGPUにモデルを分割し、dtypesおよびdevice_mapを構成します。プロンプトはモデルに渡され、レスポンスが生成されます。生成には、停止基準StopWordsCriteriaが構成されており、推論でボットのレスポンスのみを生成します。 - ModerationModel –
ModerationModelクラスで2つのモデレーションモデルを使用します。入力モデルは、入力が不適切であることをチャットモデルに指示して、推論結果を上書きするために使用されます。出力モデルは、推論結果を上書きするために使用されます。入力プロンプトと出力レスポンスは、次の可能なラベルで分類されます:- casual
- needs caution
- needs intervention (this is flagged to be moderated by the model)
- possibly needs caution
- probably needs caution
- OpenChatKitService – これは、GPT-NeoXモデル、Faiss検索、および会話オブジェクトの間でデータを渡すことを処理します。
- wikipedia_prepare.py – このファイルは、Wikipediaインデックスのダウンロードと準備を処理します。この投稿では、Hugging Faceデータセットで提供されるWikipediaインデックスを使用しています。Wikipediaドキュメントを検索するには、インデックスをHugging Faceからダウンロードする必要があるため、他の場所にはパッケージされていません。
wikipedia_prepare.pyファイルは、インポート時にダウンロードを処理します。複数のプロセスが推論の実行中に実行されている場合、1つのプロセスだけがリポジトリをクローンできます。残りは、ファイルがローカルファイルシステムに存在するまで待機します。 - wikipedia.py – このファイルは、文脈的に関連するWikipediaドキュメントを検索するために使用されます。入力クエリはトークン化され、
mean_poolingを使用して埋め込みが作成されます。クエリ埋め込みとWikipediaインデックスの間のコサイン類似度距離メトリックを計算して、文脈的に関連するWikipedia文を取得します。実装の詳細については、wikipedia.pyを参照してください。
#mean_pooling関数を使用して文埋め込みを作成する
def mean_pooling(token_embeddings, mask):
token_embeddings = token_embeddings.masked_fill(~mask[..., None].bool(), 0.0)
sentence_embeddings = token_embeddings.sum(dim=1) / mask.sum(dim=1)[..., None]
return sentence_embeddings
#2つの埋め込み間のコサイン類似度距離を計算する関数
def cos_sim_2d(x, y):
norm_x = x / np.linalg.norm(x, axis=1, keepdims=True)
norm_y = y / np.linalg.norm(y, axis=1, keepdims=True)
return np.matmul(norm_x, norm_y.T)- conversation.py – このファイルは、DynamoDBに会話スレッドを保存および取得して、モデルとユーザーに渡すために使用されます。
conversation.pyは、オープンソースのOpenChatKitリポジトリから適応されています。このファイルは、人間とモデルの会話ターンを保存するオブジェクトを定義する責任があります。これにより、モデルは会話のセッションを保持し、ユーザーが以前のメッセージを参照できるようになります。SageMakerエンドポイントの呼び出しはステートレスであるため、この会話はエンドポイントインスタンスの外部にある場所に保存する必要があります。起動時に、インスタンスはDynamoDBテーブルを作成します(存在しない場合)。その後、session_idキーに基づいて、会話のすべての更新はDynamoDBに保存されます。このキーはエンドポイントによって生成されます。セッションIDを持つ呼び出しは、関連する会話文字列を取得し、必要に応じて更新します。
カスタム依存関係を持つLMI推論コンテナをビルドする
インデックス検索には、FacebookのFaissライブラリを使用して類似度検索を実行します。これはベースのLMIイメージに含まれていないため、コンテナを適応してこのライブラリをインストールする必要があります。以下のコードは、Faissをソースからインストールすると同時に、ボットエンドポイントで必要な他のライブラリを定義するDockerfileを定義しています。Amazon SageMaker Studioからsm-dockerユーティリティを使用して、イメージをビルドしてAmazon Elastic Container Registry(Amazon ECR)にプッシュします。詳細については、Amazon SageMaker StudioのノートブックからコンテナイメージをビルドするためのAmazon SageMaker Studio Image Build CLIの使用を参照してください。
DJLコンテナにはCondaがインストールされていないため、Faissはソースからクローンしてコンパイルする必要があります。Faissをインストールするには、BLAS APIとPythonサポートを使用するための依存関係をインストールする必要があります。これらのパッケージがインストールされた後、FaissはAVX2とCUDAを使用するように構成され、Python拡張がインストールされた後にコンパイルされます。
その後、pandas、fastparquet、boto3、git-lfsがインストールされます。これらは、インデックスファイルをダウンロードして読み取るために必要です。
FROM 763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.21.0-deepspeed0.8.0-cu117
ARG FAISS_URL=https://github.com/facebookresearch/faiss.git
RUN apt-get update && apt-get install -y git-lfs wget cmake pkg-config build-essential apt-utils
RUN apt search openblas && apt-get install -y libopenblas-dev swig
RUN git clone $FAISS_URL && \
cd faiss && \
cmake -B build . -DFAISS_OPT_LEVEL=avx2 -DCMAKE_CUDA_ARCHITECTURES="86" && \
make -C build -j faiss && \
make -C build -j swigfaiss && \
make -C build -j swigfaiss_avx2 && \
(cd build/faiss/python && python -m pip install )
RUN pip install pandas fastparquet boto3 && \
git lfs install --skip-repo && \
apt-get clean allモデルを作成する
Amazon ECRにDockerイメージがあるので、OpenChatKitモデルのSageMakerモデルオブジェクトを作成できます。GPT-JT-Moderation-6Bを使用してGPT-NeoXT-Chat-Base-20B入力および出力モデレーションモデルをデプロイします。詳細については、create_modelを参照してください。
from sagemaker.utils import name_from_base
chat_model_name = name_from_base(f"gpt-neoxt-chatbase-ds")
print(chat_model_name)
create_model_response = sm_client.create_model(
ModelName=chat_model_name,
ExecutionRoleArn=role,
PrimaryContainer={
"Image": chat_inference_image_uri,
"ModelDataUrl": s3_code_artifact,
},
)
chat_model_arn = create_model_response["ModelArn"]
print(f"Created Model: {chat_model_arn}")エンドポイントを設定する
次に、OpenChatKitモデルのエンドポイント設定を定義します。ml.g5.12xlargeインスタンスタイプを使用してモデルをデプロイします。詳細については、create_endpoint_configを参照してください。
chat_endpoint_config_name = f"{chat_model_name}-config"
chat_endpoint_name = f"{chat_model_name}-endpoint"
chat_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=chat_endpoint_config_name,
ProductionVariants=[
{
"VariantName": "variant1",
"ModelName": chat_model_name,
"InstanceType": "ml.g5.12xlarge",
"InitialInstanceCount": 1,
"ContainerStartupHealthCheckTimeoutInSeconds": 3600,
},
],
)エンドポイントをデプロイする
最後に、前の手順で定義したモデルとエンドポイント設定を使用してエンドポイントを作成します。
chat_create_endpoint_response = sm_client.create_endpoint(
EndpointName=f"{chat_endpoint_name}", EndpointConfigName=chat_endpoint_config_name
)
print(f"Created Endpoint: {chat_create_endpoint_response['EndpointArn']},")OpenChatKitモデルから推論を実行する
今度は、推論リクエストをモデルに送信し、レスポンスを取得する時です。入力テキストプロンプトとtemperature、top_k、max_new_tokensなどのモデルパラメータを渡します。チャットボットの応答の品質は、指定されたパラメータに基づいています。したがって、モデルのパフォーマンスをこれらのパラメータに対してベンチマークテストし、使用ケースに最適な設定を見つけることをお勧めします。最初に入力プロンプトは入力モデレーションモデルに送信され、出力はChatModelに送信され、応答を生成します。このステップでは、モデルはWikipediaインデックスを使用して、モデルにとってコンテキスト上適切なセクションを取得して、ドメイン固有の応答を生成します。最後に、モデルの応答は出力モデレーションモデルに送信されて分類され、応答が返されます。以下のコードを参照してください。
def chat(prompt, session_id=None, **kwargs):
if session_id:
chat_response_model = smr_client.invoke_endpoint(
EndpointName=chat_endpoint_name,
Body=json.dumps(
{
"inputs": prompt,
"parameters": {
"temperature": 0.6,
"top_k": 40,
"max_new_tokens": 512,
"session_id": session_id,
"no_retrieval": True,
},
}
),
ContentType="application/json",
)
else:
chat_response_model = smr_client.invoke_endpoint(
EndpointName=chat_endpoint_name,
Body=json.dumps(
{
"inputs": prompt,
"parameters": {
"temperature": 0.6,
"top_k": 40,
"max_new_tokens": 512,
},
}
),
ContentType="application/json",
)
response = chat_response_model["Body"].read().decode("utf8")
return response
prompts = "What does a data engineer do?"
chat(prompts)以下は、サンプルのチャットインタラクションです。
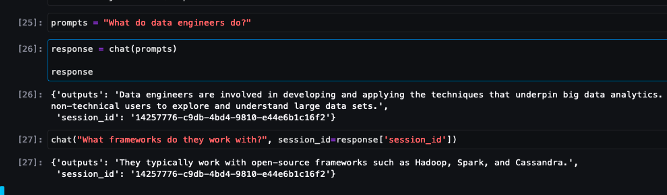
クリーンアップ
この記事の一部として提供されたリソースを削除するために、クリーンアップセクションの手順に従ってください。推論インスタンスのコストについては、Amazon SageMaker Pricingを参照してください。
結論
この記事では、オープンソースLLMsの重要性と、SageMakerでOpenChatKitモデルを展開して次世代のチャットボットアプリケーションを構築する方法について説明しました。OpenChatKitモデル、モデレーションモデルの様々なコンポーネント、および外部知識源(Wikipediaなど)を使用して検索増強生成(RAG)ワークフローを作成する方法について説明しました。GitHubノートブックでステップバイステップの手順を確認できます。あなたが構築している素晴らしいチャットボットアプリケーションについてお知らせください。乾杯!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful





