ReactとExpressを使用してChatGPTパワードおよび音声対応のアシスタントを構築する
Build a ChatGPT-powered and voice-enabled assistant using React and Express.

大規模な言語モデルが今日の世界でますます人気を集めているため、開発のための使用方法に関心が高まっていますが、どこから始めればよいかを理解するのはいつも簡単ではありません。
この記事では、ChatGPT言語モデル(この場合はgpt-35-turbo)を利用して、リアルなアプリケーションでこれらのモデルを実装する方法を理解するために、シンプルなチャットボットを構築する方法を説明します。開発するチャットボットは、主にTypeScriptで書かれたシンプルなWebアプリケーションで構成されます。モデルにアクセスするためにAzure OpenAIサービスを使用し、音声をテキストに変換する機能やテキストを音声に変換する機能を有効にするためにAzure AI Speechを使用し、APIリクエストとチャットボットとAzureサービスの間の通信を処理するためにExpressサーバーを使用し、最後にReactフロントエンドを使用します。
アプリケーションのクイックデモ。
GPTは「Generative Pre-trained Transformer」の略です。これは、与えられた文脈で単語やフレーズが現れる可能性を予測するために、大規模なテキストデータのコーパスでトレーニングされた機械学習モデルです。 GPTモデルは、言語翻訳、テキスト要約、チャットボット開発など、さまざまな自然言語処理のタスクに使用できます。このタイプのモデルの詳細な動作については深入りせず、Beatriz Stollnitzが書いた素晴らしい、非常に詳細な記事にお任せします。
アプリケーションは、このGitHubリポジトリ:github.com/gcordido/VoiceEnabledGPTで見つけることができます。このリポジトリには、インストールと実行方法の手順、Prompt Engineeringのヒント、モデルを正確な結果にするための最良の準備方法が記載されています。
このアプリケーションを開発するためには、まず「アーキテクチャ」を考慮する必要があります。これに対処するために、次の質問に答える必要があります。チャットボットのインターフェースはどのように見えますか?ユーザーはボットに入力をどのように提供しますか?アプリケーションはモデルとどのように通信しますか?入力はどのようになりますか?モデルからユーザーへの情報の取得方法は?
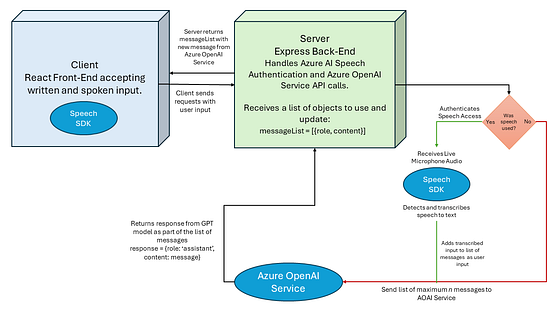
アプリケーションアーキテクチャダイアグラム
まず、チャットウィンドウがどのように表示されるかをスケッチしてみましょう。この文脈では、ウィンドウにはメッセージのリストが表示され、ユーザーのメッセージが右側に表示され、チャットボットの応答が左側に表示されます。これを実現するために、Reactコンポーネントを使用してチャットインターフェースをレンダリングします。これには、入力ボックス、音声テキストボタン、展開可能なチャット本体などの要素が含まれます。
アプリケーションとモデル間の通信は、APIを使用して行われます。Azure OpenAIサービスは、エンドポイントとAPIキーの形式でシークレットを使用して、これらのモデルへのアクセスを提供します。後者はシークレットであるため、API呼び出しを実行する際にこれらが公開されないようにする必要があります。したがって、APIリクエストを処理するためにExpressサーバーを作成します。
サーバーは、ユーザーが「送信」ボタンを押すと、チャットボットのメインインターフェースから呼び出しを受け取り、以前のメッセージのリストを受け取って、API呼び出し時にこれらをモデルにフィードします。最新のメッセージではなく、以前のメッセージのリストと述べたことに注意してください。これは意図的なものであり、GPTモデルの最も興味深い機能の1つは、提供される限りの会話全体の文脈を維持できる能力です。このリストは、2つのプロパティを持つオブジェクトのリストとしてコード化されます。 ‘role’プロパティは、ユーザーとアシスタントのメッセージを区別し、’content’プロパティにはメッセージのテキストが含まれます。
アプリケーションとGPTモデル間の通信プロセスが定義されたので、最後のステップはオーディオサポートを追加することです。これには、JavaScript用の使いやすいSDKを提供するAzure AI Speechを使用します。SDKには、ライブマイクのオーディオを検出し、音声を認識し、テキストから音声を合成するためのメソッドが提供されます。
クライアントからSpeech SDKとそのメソッドにアクセスするためには、認証トークンが必要です。このトークンは、サーバーサイドでAzure AI SpeechサービスのAPIキーとリージョンを使用して、アプリケーションを認証することで生成されます。トークンを取得すると、SpeechRecognizerメソッドを使用してマイクからオーディオを検出および転写できます。この転写は、ユーザーの入力としてメッセージリストに追加され、書かれた入力と同じ方法でサーバーに送信されます。
応答を生成すると、モデルの出力はサーバーによってチャットインターフェースに送信されます。アシスタントの役割のメッセージリストに新しいエントリが追加され、チャットウィンドウは新しいエントリを反映したチャットボットのメッセージで更新されます。この新しいエントリは、Speech SDKのSpeechSynthesizerメソッドを通じて渡すことができ、アプリケーションはスピーカーを通じてチャットボットの応答を音声で読み上げることができます。
アプリケーションはさらに進むことはありませんが、モデルとのコミュニケーション方法や応答方法を変更するための手法はまだたくさんあります。
実践を通じた学習を強く信じる者として、リポジトリをクローンしてアプリケーションパラメータを試してみることを強くお勧めします。例えば、モデルが散文や俳句で応答するようにするために「システムプロンプト」(初期の指示)を変更したり、音声合成言語をスペイン語に変更したり、コンテキストに保持されるメッセージの数を制限してモデルの応答を確認してみたりしてみてください!
元の記事はこちらから投稿されました。許可を得て再投稿しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






