BQMLを使用した多変量時系列予測
BQMLを使用した時系列予測
去年の冬、ウズベキスタンの首都タシケントで開催されたGDG DevFest Tashkent 2022で、「BQMLによるより予測可能な時系列モデル」というテーマでプレゼンテーションを行いました。
プレゼンテーションで使用した資料とコードをDevFest後に共有する予定でしたが、時間が経ち、BQMLには一部内容が重複する新機能がリリースされました。
そのため、代わりに新機能と有効な内容の一部について簡単に言及します。
- 魅力的な方法:AIが人々がドイツ語や他の言語をマスターするのを助ける方法
- 『RAPとLLM Reasonersに会いましょう:LLMsを活用した高度な推論のための類似概念に基づく2つのフレームワーク』
- 「フューショットラーニングの力を解き放つ」
時系列モデルとBQML
「時系列データ」は、多くの組織でさまざまな目的に使用されており、「予測分析」は時間における「未来」に関するものであることを理解しておくことが重要です。時系列の予測分析は、短期から長期までさまざまな目的で使用されており、不正確さやリスクはあるものの、着実に改善されています。
「予測」というものが非常に有用であるため、時系列データを持っている場合は時系列予測モデルを適用しようとするかもしれません。しかし、時系列予測モデルは通常、計算量が多く、データが多い場合はさらに計算量が多くなります。そのため、処理や分析のために煩雑で難しい作業が必要です。
データ管理にGoogle BigQueryを使用している場合、簡単で簡便な方法でデータに機械学習アルゴリズムを適用するために、BQML(BigQuery ML)を使用することができます。多くの人々が大量のデータを処理するためにBigQueryを使用しており、その多くは時系列データです。そして、BQMLは時系列モデルもサポートしています。
BQMLで現在サポートされている時系列モデルの基礎は、自己回帰和分移動平均(ARIMA)モデルです。ARIMAモデルは既存の時系列データのみを使用して予測を行い、短期予測性能が良いことで知られており、ARとMAを組み合わせるため、幅広い時系列モデルをカバーすることができる人気のあるモデルです。
ただし、このモデルは全体的に計算量が多く、正規性を持つ時系列データのみを利用するため、傾向や季節性のある場合には使用するのが難しいです。そのため、BQMLのARIMA_PLUSでは、いくつかの追加のオプションとして時系列分解、季節要因、スパイクとディップ、係数の変化などをモデルに追加することができます。また、これらを個別に進めてモデルを手動で調整することもできます。また、日付に関連する情報を手動で追加する必要がないプラットフォームを使用する利点の一つとして、自動的に休日オプションを組み込むことで周期性を調整することもできます。
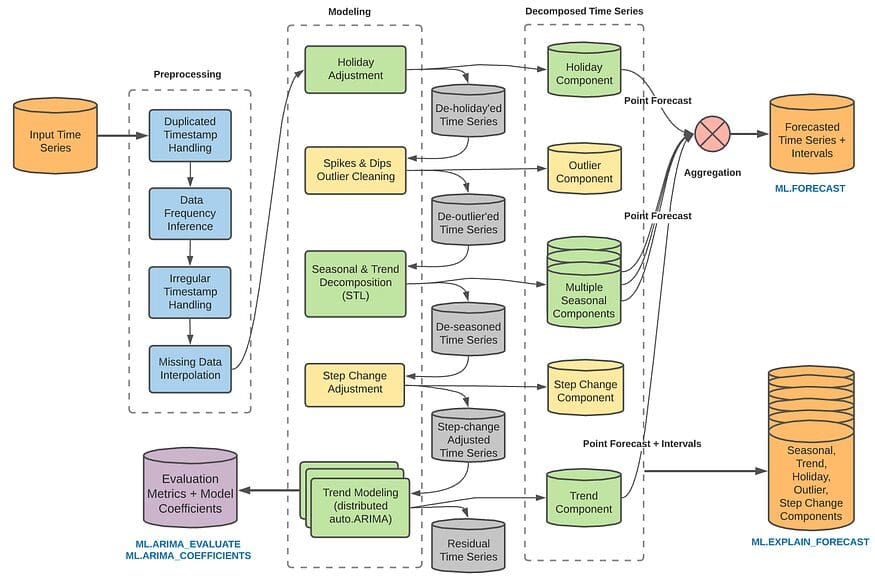
詳細はこちらのページを参照してください。
ただし、実際のアプリケーションにおいては、時系列予測はこれほど単純ではありません。もちろん、ARIMA_PLUSでは複数のサイクルを特定し、複数の時系列に介入を追加することができますが、時系列データには多くの外部要因が関連しており、ほとんどの場合、単独で起こるイベントはわずかです。時系列データにおける定常性を見つけることは難しい場合があります。
元のプレゼンテーションでは、これらの現実世界の時系列データを取り扱うための方法について、時系列を分解し、分解されたデータを整理し、Pythonにインポートし、他の変数と組み合わせて多変量時系列関数を作成し、因果関係を推定して予測モデルに組み込み、イベントの変化に伴う効果の程度を推定する方法について説明しました。
新機能: ARIMA_PLUS_XREG
そして、ここ数か月間で、外部変数(ARIMA_PLUS_XREG、XREG)を使用して多変量時系列関数を作成するための新機能がBQMLに追加されました。
詳細はこちらのページを参照してください(プレビュー版として2023年7月現在ですが、おそらく今年後半に利用可能になると思われます)。
公式のチュートリアルを適用して、伝統的な単変量時系列モデルと比較してみることにしました。その動作を確認してみましょう。
手順はチュートリアルと同じですので、重複することはありませんが、以下に私が作成した2つのモデルを紹介します。まず、伝統的なARIMA_PLUSモデルを作成し、次に同じデータを使用して気温と風速を追加したXREGモデルを作成しました。
# ARIMA_PLUS
# ARIMA_PLUS
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_plus_model
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25') AS
SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
#ARIMA_PLUS_XREG
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_xreg_model
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS_XREG',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25') AS
SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
これらの複数のデータを使用するモデルは、次のようなものになります
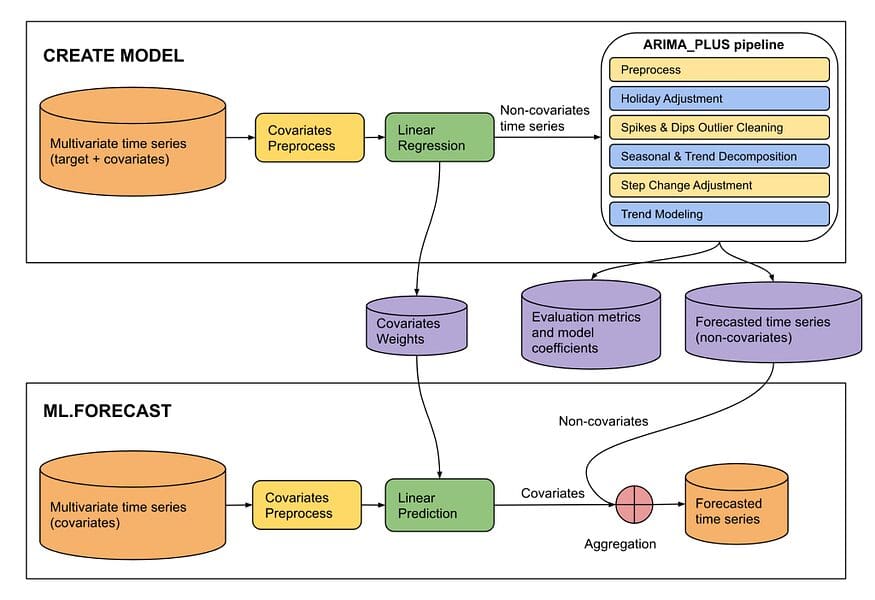
2つのモデルはML.Evaluateで比較されます。
SELECT *
FROM ML.EVALUATE
( MODEL test_dt_us.seattle_pm25_plus_model,
( SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date > DATE('2020-12-31') ))
SELECT *
FROM ML.EVALUATE
( MODEL test_dt_us.seattle_pm25_xreg_model,
( SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date > DATE('2020-12-31') ),
STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
結果は以下の通りです。
ARIMA_PLUS

ARIMA_PLUS_XREG

XREGモデルはMAE、MSE、MAPEなどの基本的なパフォーマンス指標で優れていることがわかります。(もちろん、これは完璧な解決策ではなく、データに依存するものですが、別の有用なツールを手に入れたと言えます。)
多変量時系列分析は、多くの場合必要な選択肢ですが、さまざまな理由で適用が難しいことがあります。しかし、データと分析手法の要因がある場合には、これを利用することができるようになりました。多くの場面で役立つオプションがあることを知ることは良いことです。また、それが役立つことを願っています。 JeongMin Kwon は、10年以上の実務経験を持つフリーランスのシニアデータサイエンティストです。機械学習モデルとデータマイニングを活用しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Keras 3.0 すべてを知るために必要なこと」
- 「MC-JEPAに会おう:動きと内容の特徴の自己教師あり学習のための共同埋め込み予測アーキテクチャ」
- 「新しいHADARベースのイメージングツールにより、暗闇でもクリアに見ることができます」
- 中国のこのAI論文は、HQTrackというビデオ内のあらゆるものを高品質で追跡するためのAIフレームワークを提案しています
- 『Stack OverflowがOverflowをリリース:開発者コミュニティとAIの統合』
- Scikit-Learnのパイプラインを使用して、機械学習モデルのトレーニングと予測を自動化する
- 適切なバランスを取る:機械学習モデルにおける過学習と過小適合の理解