「ビッグデータの取り扱い:ツールと技術」
Big Data Handling Tools and Techniques

ビジネスにおいて、あなたの「小さな黒い本」に必要なデータがすべて含まれている時代は過去のものです。デジタル革命の時代においては、古典的なデータベースだけでは十分ではありません。
ビッグデータを扱うことは、ビジネスとともにデータサイエンティストにとっても重要なスキルとなりました。ビッグデータはそのボリューム、速度、多様性によって特徴づけられ、従来にないパターンやトレンドについての洞察を提供します。
このようなデータを効果的に扱うには、専門のツールと技術の使用が必要です。
ビッグデータとは何ですか?
いいえ、単にたくさんのデータではありません。
ビッグデータは、主に以下の3つのVで特徴づけられます:
- ボリューム: 生成および保存されるデータのサイズが特徴の1つです。ビッグデータとして特徴づけるためには、データのサイズがペタバイト(1,024テラバイト)およびエクサバイト(1,024ペタバイト)で測定される必要があります。
- 多様性: ビッグデータは、構造化データだけでなく、半構造化データ(JSON、XML、YAML、電子メール、ログファイル、スプレッドシート)や非構造化データ(テキストファイル、画像や動画、音声ファイル、ソーシャルメディアの投稿、ウェブページ、衛星画像、地震波形データ、または生の実験データなどの科学データ)から構成され、非構造化データに焦点が当てられます。
- 速度: データの生成および処理のスピードです。
ビッグデータのツールと技術
前述のビッグデータの特徴は、ビッグデータを扱うために使用するツールと技術に影響を与えます。
ビッグデータの技術について話すとき、それらは単にデータを処理、分析、管理するために使用する方法、アルゴリズム、アプローチです。表面上では、通常のデータと同じです。ただし、前述したビッグデータの特徴により、異なるアプローチとツールが必要とされます。
以下に、ビッグデータ領域で使用されるいくつかの主要なツールと技術を示します。
1. ビッグデータ処理
それは何ですか?: データ処理は、生データを意味のある情報に変換する操作や活動を指します。データのクリーニングや構造化から複雑なアルゴリズムや分析の実行までのタスクを含みます。
ビッグデータは時にバッチ処理されますが、データストリーミングがより一般的です。
主な特徴:
- 並列処理: 複数のノードまたはサーバーにタスクを分散してデータを同時に処理し、計算を高速化します。
- リアルタイム対バッチ処理: データはリアルタイム(生成されると同時に)またはバッチ(スケジュールされた間隔でデータのチャンクを処理)で処理することができます。
- スケーラビリティ: ビッグデータツールは、さまざまなリソースやノードを追加することによって膨大なデータを処理します。
- 障害耐性: ノードが失敗してもシステムは処理を続行し、データの整合性と可用性を確保します。
- 多様なデータソース: ビッグデータは、構造化データベース、ログ、ストリーム、非構造化データリポジトリなど、多くのソースから生成されます。
使用されるビッグデータツール: Apache Hadoop MapReduce、Apache Spark、Apache Tez、Apache Kafka、Apache Storm、Apache Flink、Amazon Kinesis、IBM Streams、Google Cloud Dataflow
ツールの概要: 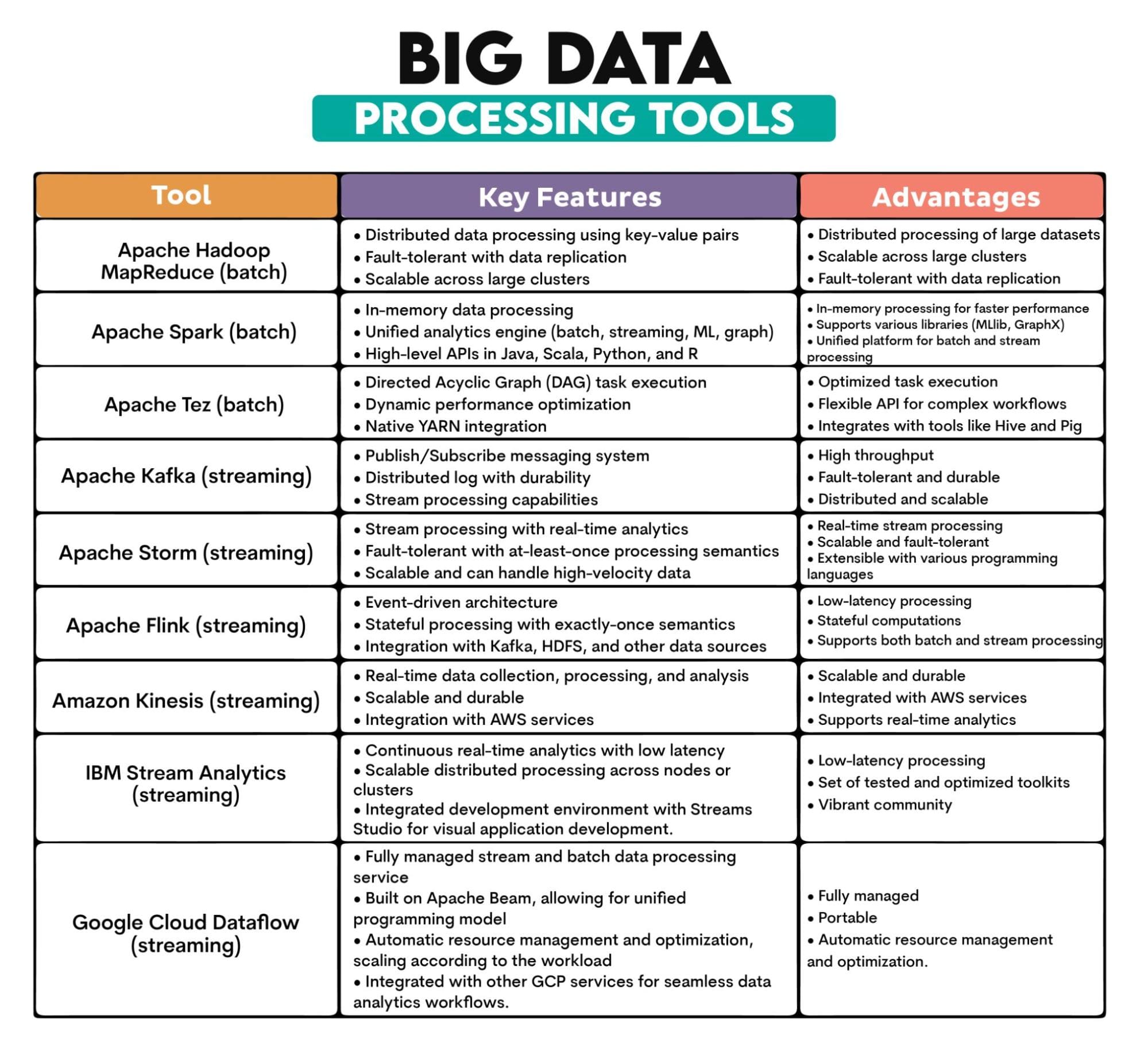
2. ビッグデータETL
それは何ですか?: ETLは、さまざまなソースからデータを抽出し、構造化および利用可能な形式に変換し、分析や他の目的のためにデータストレージシステムにロードすることを指します。
ビッグデータの特徴から、ETLプロセスはより多くのソースからより多くのデータを処理する必要があります。データは通常、構造化データとは異なる方法で変換および格納されます。
ビッグデータのETLは通常、リアルタイムでデータを処理する必要があります。
主要特徴:
- データ抽出:データは、データベース、ログ、API、フラットファイルなど、さまざまな異種ソースから取得されます。
- データ変換:抽出したデータをクエリ、分析、レポート作成に適した形式に変換します。データのクリーニング、エンリッチメント、集約、再フォーマットなどが含まれます。
- データローディング:変換されたデータをターゲットシステム(データウェアハウス、データレイク、データベースなど)に格納します。
- バッチまたはリアルタイム:ビッグデータでは、リアルタイムのETLプロセスがバッチ処理よりも一般的です。
- データ統合:ETLは異なるソースからデータを統合し、組織全体で統一されたデータのビューを確保します。
使用されるビッグデータツール:Apache NiFi、Apache Sqoop、Apache Flume、Talend
ツールの概要:
| ビッグデータETLツール | ||
| ツール | 主な特徴 | 利点 |
| Apache NiFi |
• ウェブベースのUIを使用したデータフローデザイン • データの起源を追跡する機能 • プロセッサを使用した拡張性のあるアーキテクチャ |
• ビジュアルインターフェース:データフローの設計が容易 • データの起源をサポート • 幅広いプロセッサで拡張可能 |
| Apache Sqoop |
• Hadoopとデータベース間の大量データ転送 • 並列インポート/エクスポート • 圧縮および直接インポート機能 |
• Hadoopとリレーショナルデータベース間の効率的なデータ転送 • 並列インポート/エクスポート • 増分データ転送機能 |
| Apache Flume |
• イベント駆動型で設定可能なアーキテクチャ • 信頼性の高いデータ配信 • Hadoopエコシステムとのネイティブ統合 |
• スケーラブルで分散型 • 障害耐性のアーキテクチャ • カスタムソース、チャネル、シンクで拡張可能 |
| Talend |
• ビジュアルデザインインターフェース • データベース、アプリなどへの広範な接続性 • データ品質およびプロファイリングツール |
• 様々なデータソースに対する幅広いコネクタ • データ統合プロセスの設計に使用するグラフィカルインターフェース • データ品質とマスターデータ管理をサポート |
3. ビッグデータストレージ
概要:ビッグデータストレージは、高速でさまざまな形式で生成される膨大なデータを格納する必要があります。
ビッグデータを格納するための最も特徴的な方法は、NoSQLデータベース、データレイク、データウェアハウスです。
NoSQLデータベースは、固定スキーマのない大量の構造化および非構造化データを処理するために設計されています(NoSQL – Not Only SQL)。これにより、データ構造の進化に適応できます。
従来の縦方向にスケーラブルなデータベースとは異なり、NoSQLデータベースは水平方向にスケーラブルであり、データを複数のサーバーに分散できます。システムへのマシンの追加によりスケーリングが容易になります。耐障害性があり、低レイテンシ(リアルタイムデータアクセスを必要とするアプリケーションで評価される)であり、スケールにおいてコスト効率が高いです。
データレイクは、大量の生データをそのままの形式で格納するストレージリポジトリです。これにより、データアクセスと分析が容易になります。
データレイクはスケーラブルでコスト効率が高く、柔軟性があります(データはそのままの形式で取り込まれ、データを分析する際に構造が定義されます)。バッチおよびリアルタイムデータ処理をサポートし、データ品質ツールと統合できるため、より高度な分析とより豊かな洞察を提供します。
データウェアハウスは、分析処理に最適化された集中型のリポジトリであり、複数のソースからデータを取り込んで分析とレポート作成に適した形式に変換して保存するものです。
データウェアハウスは、膨大な量のデータを保存し、さまざまなソースから統合し、データに時間の次元があるため、過去の分析を可能にするために設計されています。
主な特徴:
- スケーラビリティ:ノードまたはユニットを追加することによってスケールアウトするように設計されています。
- 分散アーキテクチャ:データは複数のノードまたはサーバーに分散して保存され、高い可用性と耐障害性が確保されています。
- さまざまなデータ形式:構造化データ、半構造化データ、非構造化データを扱うことができます。
- 耐久性:保存されたデータは、ハードウェアの障害にもかかわらず、完全で利用可能な状態で保持されます。
- コスト効率:多くのビッグデータストレージソリューションは、コモディティハードウェア上で実行されるように設計されており、規模に応じてより手頃な価格で利用することができます。
使用されるビッグデータツール:MongoDB(ドキュメントベース)、Cassandra(カラムベース)、Apache HBase(カラムベース)、Neo4j(グラフベース)、Redis(キーバリューストア)、Amazon S3、Azure Data Lake、Hadoop Distributed File System(HDFS)、Google Big Lake、Amazon Redshift、BigQuery
ツールの概要: 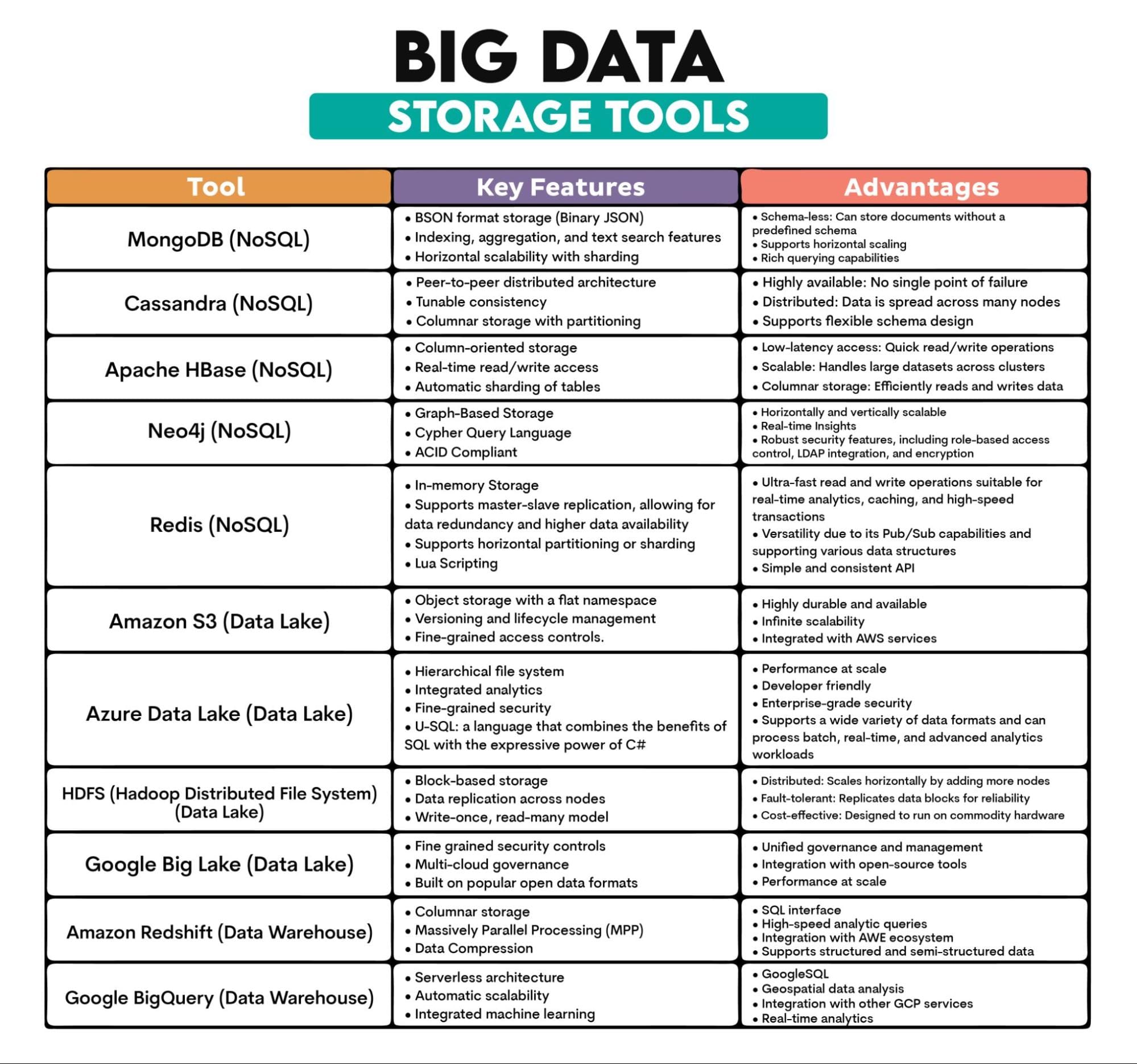
4. ビッグデータマイニング
それは何ですか?:大規模なデータセットでのパターン、相関関係、異常値、統計的関係を発見することです。これには、機械学習、統計学、データベースシステムを使用してデータから洞察を抽出するなどの専門分野が関与します。
マイニングされるデータの量は膨大であり、その大量性によって、小規模なデータセットでは明らかにならないパターンが明らかになることがあります。ビッグデータは通常、さまざまなソースから得られ、半構造化データまたは非構造化データであることが多いため、より高度な前処理と統合技術が必要です。通常、ビッグデータはリアルタイムで処理されます。
ビッグデータマイニングのために使用されるツールは、これらすべてを処理する必要があります。そのため、分散コンピューティングを適用し、データ処理を複数のコンピュータに分散させます。
一部のアルゴリズムはビッグデータマイニングには適していない場合があります。スケーラブルな並列処理アルゴリズム(例:SVM、SGD、またはGradient Boosting)が必要です。
ビッグデータマイニングは探索的データ分析(EDA)技術も採用しています。EDAはデータセットを分析してその主な特徴を要約し、統計グラフィック、プロット、情報テーブルを使用することが一般的です。そのため、ビッグデータマイニングとEDAツールについても話をします。
主な特徴:
- パターン認識:大規模データセット内の規則性やトレンドの特定。
- クラスタリングと分類:類似性や事前定義された基準に基づいてデータポイントをグループ化。
- 関連分析:大規模データベース内の変数間の関係の発見。
- 回帰分析:変数間の関係を理解しモデリングする。
- 異常検出:異常なパターンの特定。
使用されるビッグデータツール:Weka、KNIME、RapidMiner、Apache Hive、Apache Pig、Apache Drill、Presto
ツールの概要: 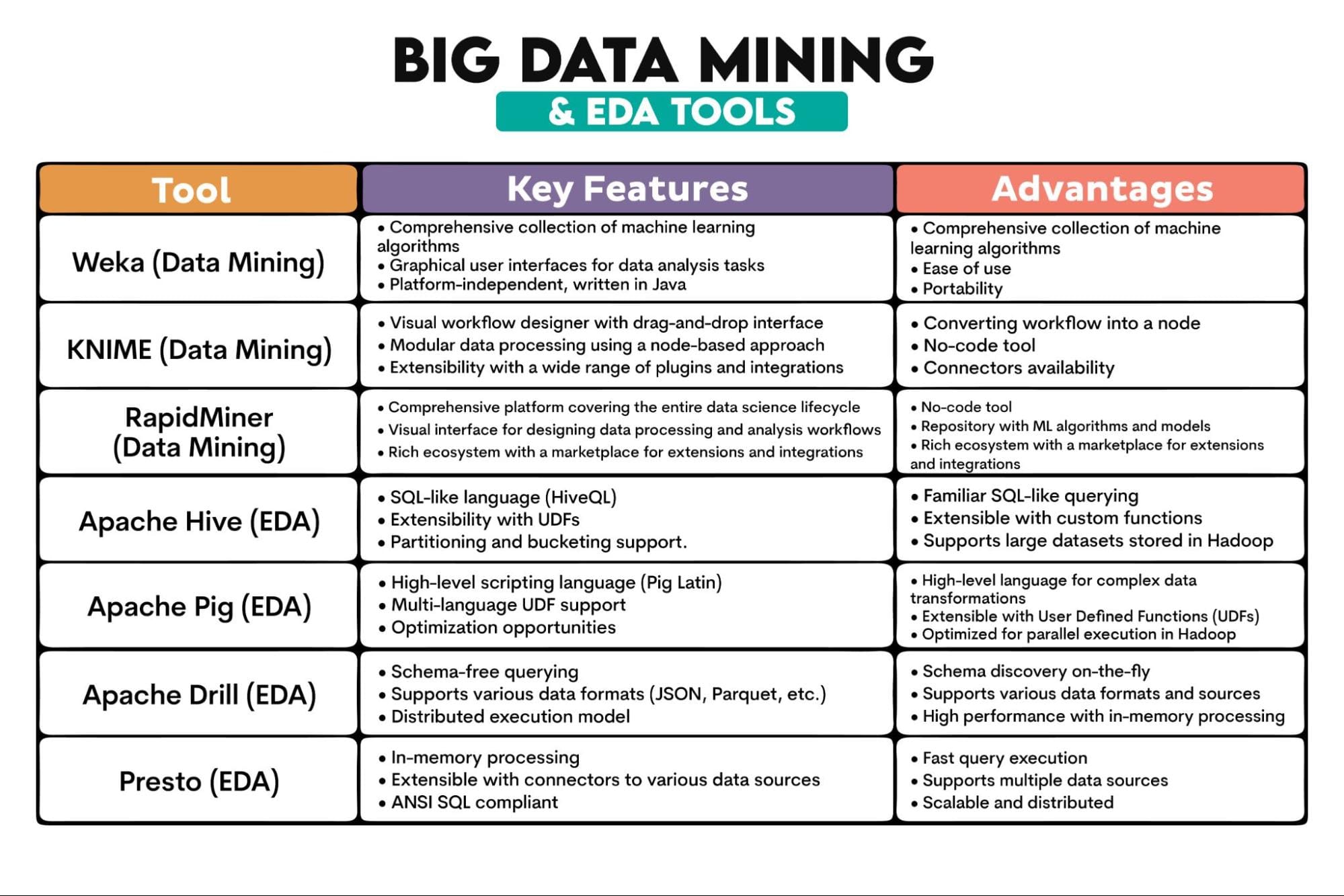
5. ビッグデータの可視化
それは何ですか?:広範なデータセットから抽出された情報とデータの視覚的な表現です。チャート、グラフ、地図などの視覚的要素を使用して、データのパターン、外れ値、トレンドを理解するためのアクセス可能な方法を提供するデータ可視化ツールです。
ビッグデータの特性(サイズや複雑さなど)により、通常のデータ可視化とは異なる方法が必要です。
主な特徴:
- インタラクティビティ:ビッグデータの可視化には、ユーザーが具体的な内容にドリルダウンし、データをダイナミックに探索できるインタラクティブなダッシュボードとレポートが必要です。
- スケーラビリティ:大規模なデータセットを効率的に処理し、パフォーマンスを損なうことなく扱う必要があります。
- 多様な可視化タイプ:ヒートマップ、ジオスペーシャル可視化、複雑なネットワークグラフなど。
- リアルタイム可視化:多くのビッグデータアプリケーションでは、リアルタイムのデータストリーミングと可視化が必要です。
- ビッグデータプラットフォームとの統合:可視化ツールは、しばしばビッグデータプラットフォームとシームレスに統合されます。
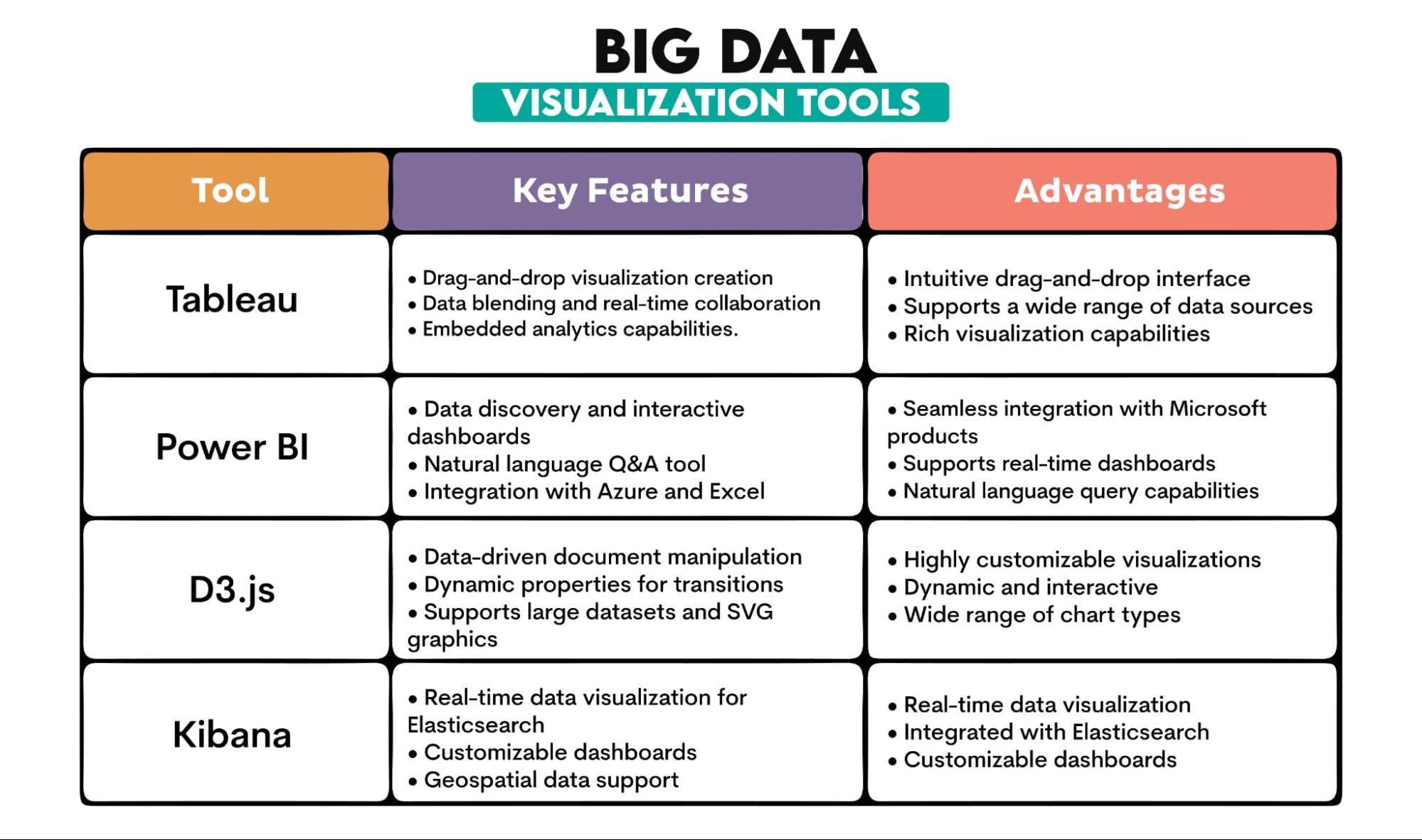
使用されたビッグデータツール:Tableau、PowerBI、D3.js、Kibana
ツールの概要:
結論
ビッグデータは通常のデータと非常に似ていますが、同時にまったく異なるものです。データの取り扱いの技術は共有していますが、ビッグデータの特性のために、これらの技術は名前だけで同じです。それ以外の場合、完全に異なるアプローチとツールが必要です。
ビッグデータに取り組むためには、さまざまなビッグデータツールを使用する必要があります。これらのツールの概要は、あなたにとって良い出発点になるはずです。Nate Rosidiはデータサイエンティストであり、製品戦略を担当しています。また、トップ企業からの実際の面接質問を使ってデータサイエンティストが面接の準備をするためのプラットフォームであるStrataScratchの創設者でもあり、分析を教える非常勤講師でもあります。彼とTwitterまたはLinkedInでつながってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
