量産自動運転におけるBEVパーセプション
BEV perception in mass-produced automated driving.
Xpeng MotorsのXNetのレシピ
このブログ投稿は、バンクーバーで開催されたCVPR 2023のEnd-to-end Autonomous Driving Workshopでの招待講演に基づいています。タイトルは「中国における大量生産自動運転の実践」と題されています。
過去数年間、BEVパーセプションは大きな進歩を遂げています。自動運転車両の周囲の環境を直接感知します。BEVパーセプションは、エンド・トゥー・エンド・パーセプションシステムと見なすことができ、エンド・トゥー・エンド自動運転システムに向けた重要なステップです。ここでは、生のセンサーデータを入力として高レベルな運転計画または低レベルの制御アクションを出力する完全に微分可能なパイプラインとして、エンド・トゥー・エンド自動運転システムを定義します。
CVPR 2023 Autonomous Driving Workshop | OpenDriveLab
今年は、パートナーであるVision-Centricとの協力により、4つの全く新しいチャレンジを発表することを誇りに思っています…
opendrivelab.com
自動運転コミュニティは、エンド・トゥー・エンドのアルゴリズムフレームワークを採用するアプローチの急速な成長を目撃しています。最初の原則からエンド・トゥー・エンド・アプローチの必要性について説明します。次に、XpengのBEVパーセプションアーキテクチャであるXNetの開発を例に挙げ、大量生産車両にBEVパーセプションアルゴリズムを展開する取り組みについて説明します。最後に、完全にエンド・トゥー・エンド自動運転に向けたBEVパーセプションの将来についてブレストします。
エンド・トゥー・エンド・システムの必要性
どんなエンジニアリングの問題を解決するにしても、実用的な解決策を迅速に見つけるために分割統治アプローチを使用することがしばしば必要になります。この戦略は、大きな問題を小さな比較的明確に定義されたコンポーネントに分解して、独立して解決できるようにすることを含みます。このアプローチは、完全な製品を迅速に提供するのに役立ちますが、局所最適解で立ち往生するリスクを高めます。全体最適解に到達するためには、すべてのコンポーネントをエンド・トゥー・エンドの方法で最適化する必要があります。
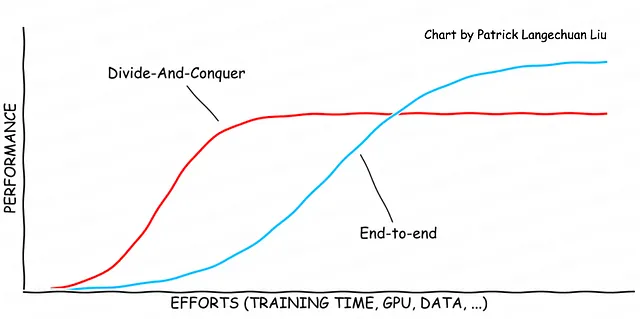
80-20の法則は、望ましいパフォーマンスの80%が全体の努力の20%で達成できるという概念を強化します。分割統治アプローチを使用する利点は、最小限の努力で迅速に作業できることです。ただし、この方法はしばしばパフォーマンス上限の80%で停滞することがあります。パフォーマンス上限を克服し、局所最適解から脱出するために、開発者は特定のコンポーネントを一緒に最適化する必要があります。これは、エンド・トゥー・エンドのソリューションを開発するための最初のステップです。このプロセスは、グローバル最適解が近似されるまで、何度も繰り返す必要があります。得られる曲線は、グローバル最適解が近似されるまで、シグモイド曲線のシリーズの形を取る場合があります。エンド・トゥー・エンドのソリューションに向けた取り組みの1つの例は、BEVパーセプションアルゴリズムの開発です。
パーセプション2.0:エンド・トゥー・エンド・パーセプション
従来の自動運転スタックでは、2D画像がパーセプションモジュールに供給され、2Dの結果が生成されます。センサーフュージョンが複数のカメラからの2Dの結果を推論し、これらを3Dに昇格します。その結果得られた3Dオブジェクトは、予測や計画などの下流コンポーネントに送信されます。
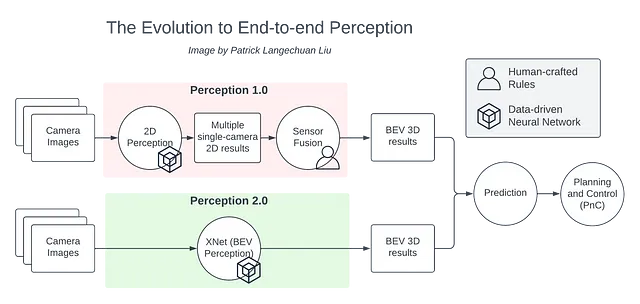
しかし、センサーフュージョンステップでは、複数のカメラストリームからのパーセプション結果を融合するために多くの手作業のルールが必要になります。各カメラは観察対象の一部しか認識できないため、得られた情報を組み合わせるには、融合ロジックの注意深い調整が必要です。私たちは、エンジニアの頭を通じて逆伝播を行っています。さらに、これらのルールを開発および維持することによって、複雑な都市環境で多数の問題が発生する一連の複雑さが生じます。
この課題に対処するために、Bird’s Eye View(BEV)認識モデルを適用して、BEV空間で環境を直接認識することができます。BEV認識スタックは、2つの別々のコンポーネントを1つのソリューションに統合することで、脆弱な人工的に作られたロジックを排除します。BEV認識は、本質的にはエンドツーエンドの認識ソリューションです。これは、エンドツーエンドの自律走行システムに向けた重要な一歩となります。
Xpeng MotorsのBEV Perception Stack:XNet
XpengのBEV認識アーキテクチャは、XNetというコードネームを持っています。それは、2022年のXpeng 1024 Tech Dayで初めて公に紹介されました。以下の図は、オンボードのXNet認識アーキテクチャがラウンドアバウトをナビゲートする自律走行車両を中心に、周囲の静的環境を完全に検出している様子を示しています。HDマップは使用されていません。XNetは、車両周辺の広範囲の動的および静的なオブジェクトを正確に検出していることがわかります。
Xpeng AIチームは、XNetアーキテクチャを2年以上前(2021年初頭)から実験し始め、現在の形に至るまで何度か改良を加えています。私たちは畳み込みニューラルネットワーク(CNN)バックボーンを利用して画像特徴を生成し、マルチカメラ特徴はトランスフォーマー構造を介してBEV空間に転置されます。具体的には、クロスアテンションモジュールが使用されています。複数の過去フレームのBEV特徴は、自己位置と空間的・時間的に融合され、融合された特徴から動的および静的な要素をデコードします。

ビジョン中心のBEV認識アーキテクチャは、自律走行ソリューションの大量展開のコスト効率を改善し、より高価なハードウェアコンポーネントの必要性を減らします。正確な3D検出と速度は冗長性の新しい次元を展開し、LiDARやレーダーに対する依存度を低減します。さらに、リアルタイムの3D感覚環境認識により、HDマップに対する依存度が低減されます。両方の機能が、より信頼性の高いコスト効率の高い自律走行ソリューションに重要な貢献をしています。
XNetの課題
このようなニューラルネットワークを製品車両に展開することは、いくつかの課題があります。まず第一に、XNetを学習するために数百万のマルチカメラ動画クリップが必要です。これらのクリップには、注釈が必要な約10億のオブジェクトが含まれます。現在の注釈効率に基づくと、約2,000人年が注釈に必要です。Xpengの注釈チームには約1000人がいるため、このようなタスクを完了するには約2年かかります。モデルトレーニングの観点からは、単一のマシンを使用してこのようなネットワークをトレーニングするには約1年かかります。さらに、NVIDIA Orinプラットフォームに最適化せずにこのようなネットワークを展開すると、1つのチップの計算パワーの122%が必要になります。
これらのすべての問題には、このような複雑で大規模なモデルのトレーニングと展開の成功に対処する必要があります。
オートラベル
注釈効率を改善するために、私たちは高効率のオートラベルシステムを開発しました。このオフライン・センサー・フュージョン・スタックは、効率を45,000倍に向上させ、200人年の注釈タスクをわずか17日で完了することができます。

上記は、LiDARベースのオートラベルシステムであり、ビジョンセンサーに完全に依存するシステムも開発しています。これにより、LiDARを持たない顧客フリートから得られたクリップを注釈することができます。これは、データクローズドループの重要な部分であり、自己進化する認識システムの開発を促進します。
大規模トレーニング
XNetのトレーニングパイプラインを2つの観点から最適化しました。まず第一に、混合精度トレーニングとオペレータ最適化技術を適用して、単一ノードでのトレーニングプロセスを合理化し、トレーニング時間を10倍に短縮しました。次に、Alicloudと提携して、計算能力が600 PFLOPSのGPUクラスタを構築し、トレーニングを単一のマシンから複数のマシンにスケールアップすることができました。これにより、トレーニング時間がさらに短縮されましたが、トレーニング手順を注意深く調整して、ほぼ線形パフォーマンススケーリングを実現する必要がありました。全体として、XNetのトレーニング時間を276日からわずか11時間に短縮しました。トレーニングプロセスにさらにデータを追加すると、トレーニング時間が自然に増加するため、追加の最適化が必要になります。スケールアウトの最適化は、継続的かつ重要な取り組みとなります。

Orin上での効率的な展開
最適化なしでNvidia Orinチップ上でXNetを実行すると、チップの計算能力の122%が必要になることに気付きました。最初に表示されたプロファイリングチャートを分析すると、トランスフォーマーモジュールがランタイムの大部分を消費していることがわかりました。これは、Orinチップの初期設計段階ではトランスフォーマーモジュールに注目されていなかったためです。その結果、トランスフォーマーモジュールとアテンションメカニズムをOrinプラットフォームに対応するように再設計する必要があり、3倍の高速化を実現しました。
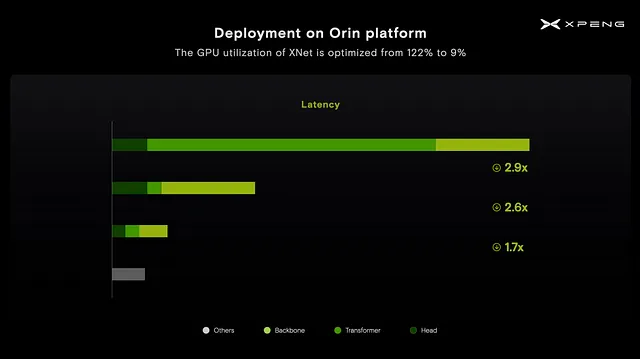
更なる最適化を促進するために、プルーニングを用いてネットワークを最適化し、2.6倍の高速化を実現しました。最後に、GPUとDLAの間でワークロードバランシングを採用し、さらに1.7倍の高速化を実現しました。
これらのさまざまな最適化技術により、XNetのGPU利用率を122%からわずか9%に減らすことができました。これにより、Orinプラットフォーム上での新しいアーキテクチャの可能性を探索することができました。
自己進化型データエンジン
XNetアーキテクチャの実装により、モデルのパフォーマンスを向上させるためのデータ駆動型の反復を開始できるようになりました。これを実現するために、まず車両の特殊なケースを特定し、それに関連する画像を収集するための設定可能なトリガーを顧客フリートに展開します。その後、自然言語の短い説明または画像自体に基づいて、収集されたデータから画像を取得します。これにより、大規模言語モデルの最近の進歩を活用して、データセットのキュレーションと注釈化の効率を向上させることができます。
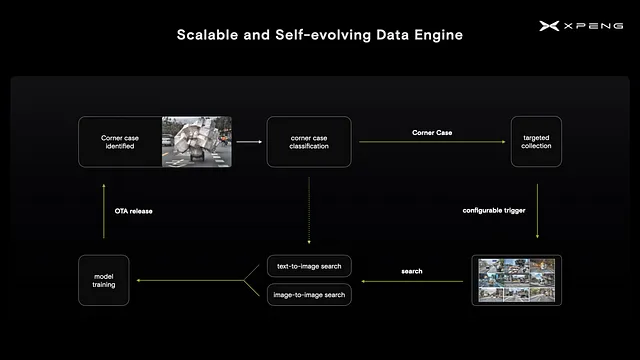
XNetアーキテクチャとデータエンジンにより、スケーラブルかつ自己進化型の知覚システムを作成しました。
将来
Xpeng Highway NGP 2.0の最新バージョンでは、高速道路と市街地のパイロットソリューションが統合され、ユーザーは別の都市でピンをドロップして、開始から終了までスムーズな体験をすることができます。この統合は、すべてのシナリオにわたる統一されたスタックの堅固な基盤を提供するXNetによって可能になります。最終的な目標は、ポイントツーポイントのユーザーエクスペリエンスを実現し、エンドツーエンドの自動運転を実現することです。
エンドツーエンドの自動運転システムを実現するためには、もう一つの重要な欠落している要素は、機械学習ベースの計画スタックです。学習ベースの計画ソリューションは、模倣学習または強化学習アプローチに大きく分けることができます。最近の大規模言語モデル(LLM)の進歩も、この重要なトピックの進歩に大きな可能性をもたらしています。以下のGithubリポジトリは、エンドツーエンドの自動運転の新興分野で関連する作業をリアルタイムで収集する場所です。
GitHub – OpenDriveLab/End-to-end-Autonomous-Driving: All you need for End-to-end Autonomous Driving
エンドツーエンド自動運転のために必要なすべて。OpenDriveLab/End-to-end-Autonomous-Driving開発に貢献するには…
github.com
まとめ
- 分割と征服は、20%の努力で80%のパフォーマンスに達します。エンドツーエンドアプローチは、より高いコストで80%のパフォーマンス上限を破ることを目指しています。
- XNetはエンドツーエンドの知覚システムであり、エンドツーエンドのフルスタックソリューションに向けた重要なステップです。80-20ルールによると、それには大きなエンジニアリング努力(80%)が必要です。
- XNetの大量の注釈付けには、人間の注釈付けは不可能なため、自動注釈付けが必要です。自動ラベルシステムにより、効率を45000倍に向上させることができます。
- 大規模なトレーニングには、単一のマシンでのトレーニングの最適化、および1台のマシンから複数のマシンへのスケーリングが必要です。
- Nvidia Orinプラットフォーム上でのXNetの展開には、トランスフォーマーモジュールのリファクタが必要です。
このブログのすべてのチャートと動画は、著者によって作成されています。
参考文献
- 中国における大量生産の自動運転展開における困難については、以下のリンクを参照してください。これは、CVPR 2023での同じ招待講演の一部でもありました。
中国における大量生産の自動運転の課題
そして、XPengの回答
VoAGI.com
- Xpeng 1024 Tech Day 2022: https://www.youtube.com/watch?v=0dEoctcK09Q
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 量子AI:量子コンピューティングの潜在能力を機械学習で解き明かす
- SRGANs:低解像度と高解像度画像のギャップを埋める
- このGoogleのAI論文は、さまざまなデバイスで大規模な拡散モデルを実行するために画期的なレイテンシー数値を集めるための一連の最適化を提示しています
- LLM-Blenderに会いましょう:複数のオープンソース大規模言語モデル(LLM)の多様な強みを活用して一貫して優れたパフォーマンスを達成するための新しいアンサンブルフレームワーク
- WAYVE社がGAIA-1を発表:ビデオ、テキスト、アクション入力を活用して現実的な運転ビデオを作成する自律性のための新しい生成AIモデル
- MIT教授が議会に語る「AIにおいて私たちは転換点にあります」
- 宇宙における私たちの位置を理解する





