SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
Better than GPT-4 in SQL queries NSQL (fully open source).
NSQLは、SQL生成タスクに特化したオープンソースの大規模基盤モデル(FM)の新しいファミリーです
ChatGPTや他のLLMを使用してSQLクエリを生成しようとしたことがある方、手を挙げてください。私はしています!しかし、嬉しいお知らせがあります。SQL生成タスクに特化したオープンソースの大規模基盤モデル(FM)の新しいファミリーがリリースされました。その名前はNSQLです。NSQL-350M、NSQL-2B、NSQL-6Bといった複数のバージョンがあります。NSQL-6Bは、標準SQLベンチマークやChatGPT、GPT3、GPT3.5、GPT4などの商用一般モデルを上回る性能を発揮しています。
既製品 vs ファインチューニング?
なぜSQLを使うのか?SQLはまだ最も一般的に使用されている言語です。Oracle、MySQL、PostgreSQL、MSSQLなど、さまざまなフレーバーのSQLを使用しているかもしれませんが、SQLは普遍的に使われています。大規模な言語モデルにSQLクエリを質問してSQLクエリを書くことができれば、素晴らしいことではないでしょうか?それによって、多くの作業が軽減され、ほぼ全員がインサイトにアクセスできるようになるかもしれません。
それを実現するにはどうすればよいのでしょうか?通常、既製品のモデルか、特定のタスクに対してファインチューニングされた基盤モデルのどちらかを考えます。どちらにも長所と短所があります。既製品モデルは公開データでトレーニングされており、組織固有の知識を持っていません。
私と同じような方なら、何を言っているか理解していると思います。企業、ビジネスユニット、そして時にはエンジニア(残念ながら)ごとに、さまざまなデータベース、スキーマ、テーブル名、フィールドの命名規則があることがあります。各フィールドがどのような意味を持つかを知ることは、トレーニングプロセスの最初の3〜6ヶ月で私たちが苦労する戦いの80%を占めています。しかし、冗談はさておき、これは公開データを使用して開発されたオープンソースモデルの本当の問題です。組織固有のデータを使用してこれらのモデルをカスタマイズすることは、データサイエンティストにとっての課題であり、ビジネスにとっての機会です。これにより、各組織が提供するデータにより柔軟なモデルにすることができます。
GPTのような巨大なモデルを使用して、単にコンテキストを提供すれば動作すると考えるかもしれませんが、それは完全に間違っているわけではありませんが、モデルが幻覚を起こす回数(temperature=0の設定でも)に驚くでしょう。また、500Bのパラメータを持つ一般的なモデルに特定のSQLクエリを書かせるというのは、使用されるリソースに合わせていない仕事かもしれません。では、解決策とは何でしょうか?
SQLタスクに特化した完全オープンソースのFM
AIは急速に進化しており、企業でのAIの採用は比較的遅れています。一部の産業はAIの採用に適していますが、専門知識、インフラストラクチャ、そして一般的な意思決定におけるAIを基にしたデータソリューションへの投資意欲には大きな遅れがあります。実際、ごく一部の企業しか独自のコードFMを構築する能力を持っていません。つまり、彼らはギャップを埋めるためにオープンソースまたはクローズドソースの代替品が必要です。そのような既製品のモデルを使用する際にはいくつかの特定のギャップがあります。
前述したように、個別のカスタマイズが不足しています。各企業のデータとそのコードベースはほぼ常にユニークです。つまり、一つのモデルがすべてに適しているという考え方は最善のアイデアではないかもしれません。
さらに、企業のさまざまな部門で使用されているプログラミング言語は多岐にわたります。多くの言語を処理するために開発されたモデルは一般的なタスクには適していますが、専門的なタスクには適していません。これは、「ほぼ」答えが得られることもあるが、「ほぼ」のためにそれが完全に使い物にならなくなることを意味します。
プライバシーも大きな問題の一つです。企業はしばしばAIを提供する会社との情報共有を避ける傾向にあります。つまり、特化したタスクを実際に構築することは困難です。もしアンケートを行ったら、今日のほとんどの企業は、プライバシーに焦点を当てたタスクであれば、3rdパーティーではなく自社のハードウェアを使用したいと思うでしょう。
NSQLが質問に答えるアプローチ

NSQLは以下のソリューションを実行しました。最初のステップは、大量のデータを収集することでした。これは、自己教師あり学習を使用してウェブから収集された一般的なSQLコードのコーパスです。モデルトレーニングプロセスへの入力データには、SQLコードとラベル付けされたテキストからSQLへのペアとしてのデータスキーマの両方が含まれています。これは、一般的なSQLモデルがデータベースに対して最も一般的な要求に合わせるための微調整プロセスです。
NSQL:データとトレーニングの詳細
NSQLをトレーニングするために2つのデータセットが作成されました。
- 一般的なSQLクエリで構成された事前トレーニングデータセット(データはこちらのHuggingFaceで利用可能です https://huggingface.co/datasets/bigcode/the-stack )
- テキストからSQLへのペアで構成された微調整データセット(これらのラベル付きテキストからSQLへのペアは、ウィリSQLからMIMIC_IIIなどの医療データまで、ウェブ上の20の異なる公開ソースから提供されました(MIMICシリーズについてはこちらで詳しく読むことができます https://medium.com/mlearning-ai/what-is-mimic-iv-newer-better-modular-release-of-mimic-4083e3cb14fe )
以下は、微調整データベースの完全なリストです

このデータは、スキーマの拡張、SQLのクリーニング、およびより良い命令の生成と共に増強されました。合計で30万のサンプルが微調整データに含まれています。データはHuggingFaceで利用可能になります。
トレーニングは、2段階のプロセスで行われ、最初のステップではSQLコードのみを使用して事前トレーニングが行われ、次にスキーマを持つテキストからSQLへのペアを使用して微調整が行われました。
パフォーマンス
NSQLは2つの標準的なテキストからSQLへのベンチマークで評価されました:
The Spider
The Spiderベンチマークには、俳優から車に至るまで、200以上のさまざまなデータベースの質問が含まれています。詳細はこちらで確認してください https://yale-lily.github.io/spider 。
Geoquery
GeoQueryは、米国の地理に関する質問に焦点を当てています。GeoQueryについてはこちらで詳しく読むことができます。
結論
NSQLバージョン6Bは、既存のオープンソースモデルよりも、Spider Execution Accuracyベンチマークで最大6ポイント優れています。

クローズドソースモデルと比較して、6Bバージョンは、Spider Execution AccuracyベンチマークにおいてChatGPTと比較して9ポイントのリードを持ってさらに良い結果を示しています。Salesforce CodeGenモデルと比較しても、事前トレーニング(微調整されていない)NSQLは35-60%、NSQL instruct(微調整された)モデルは100-400%優れています。

質的分析:
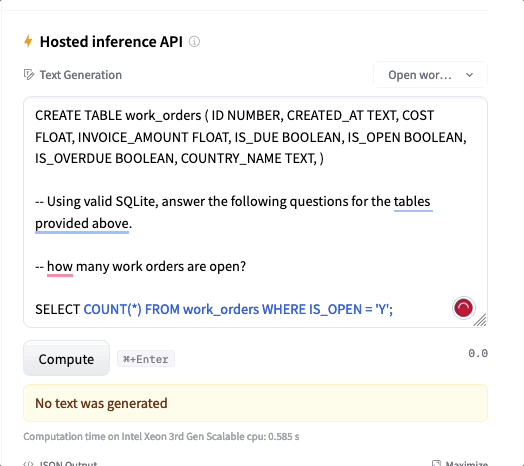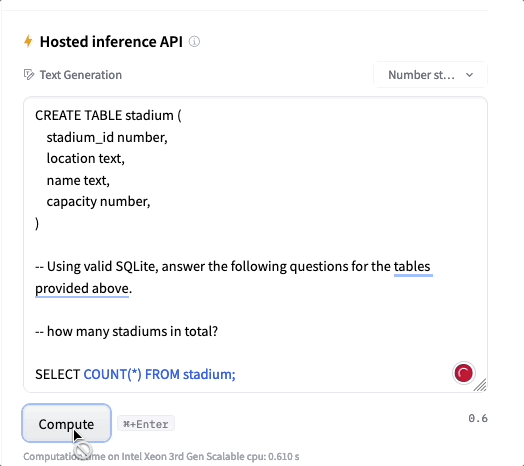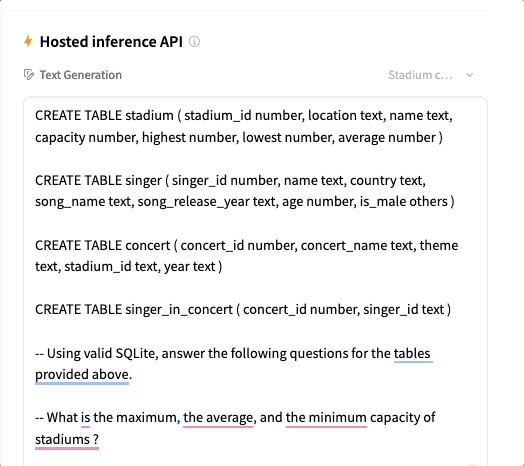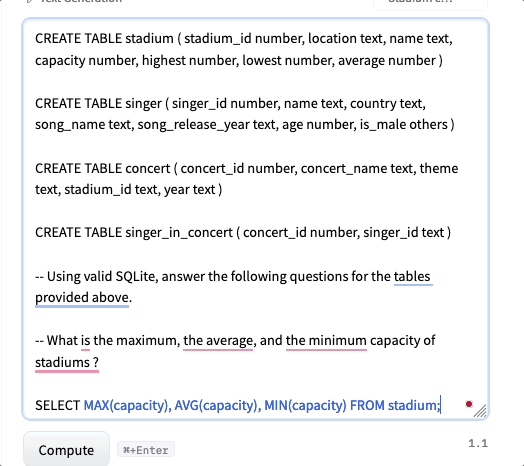
研究者はまた、質的な手法を用いてモデルの評価も行いました。そのような評価の結果、NSQLモデルは既存のモデルよりも指示に従う能力が高く、さらに幻想を生じることが少ないことがわかりました。特に、スキーマがコンテキストとして提供される場合には、NSQLモデルの機能が向上します。明示的な命令がある場合、NSQLモデルはより優れたパフォーマンスを発揮します。以下は、モデルがうまく機能したケースと(5,6)コンテキストで収益が定義されていないためにモデルがかなり失敗したケースの例です。
スキーマ作成コード —

質的評価。

これはどういう意味ですか?
数日前、誰かが私に連絡してきて「こんにちは、私たちは医療業界で働いており、データを他のパーティに送ることはできません。ユーザーの入力に基づいてクエリを生成したいと思っています。市販のモデルを使用してそれを行うことができると自信を持っていましたが、今では確信を持ってそれを行うことができると思っています。
おそらくこのプレトレーニングモデルの性能は私の期待するものよりも低いかもしれませんが、会社のデータを使用して微調整するか、単に従業員にトレーニングを提供してツールを正しく使用できるようにすることができます。
すべてのクレジットは、NnumbersStation.aiがNSQLの力を人々にもたらしたために与えられます。このリリースは、学術的および商業的な作業の両方に完全に無料であり、それを使って遊ぶのに非常に柔軟なモデルです。また、人々の力も忘れないでください。 LLaMaのウェイトが漏れたとき、私たちはKindom Mammaliaからすべての動物モデルを手に入れました! NSQLのこのリリースからは、たくさんの派生モデルが期待されると思います。
どこでモデルを試すことができますか?
NSQL-350M、NSQL-2B、およびNSQL-6BはすべてHuggingFaceで利用可能です。350Mモデルを使用してプレイグラウンドを利用することができます(他のモデルは推論APIに読み込むには大きすぎます)
NumbersStation (NumbersStation)
Hugging FaceのNumbersStationの組織プロフィール、未来を築くAIコミュニティ。
huggingface.co
どこでスターターコードを見つけることができますか?
GitHubで、PostgresとSqliteのSQLフレーバーのセットアップと作業を説明するノートブックを見つけることができます。リポジトリと例はうまくセットアップされていませんので、要件でマニフェストパッケージのバージョンが0.1.9と指定されていますが、利用可能なバージョンは0.1.8までです。SQLiteを使用してローカルで実行する前に調整を行ってください(Postgresデータベースとユーザを作成する必要はありませんので、SQLiteをお勧めします)。
幸運を祈ります!そして楽しんでください。
ここまで読んでくれた方々へ — ありがとう!あなたはヒーローです!今回は短く、おそらく急いで書かれた記事で申し訳ありません。私は「AIの世界での興味深い出来事」を読者の皆さんにお伝えするよう心がけていますので、🔔拍手 | フォロー | 購読をお願いします。
私の紹介を使ってメンバーになる: https://ithinkbot.com/membership
Linkedinで私を見つけてください: https://www.linkedin.com/in/mandarkarhade/
GPT-4: 8つのモデルを1つに;秘密が明かされました
GPT4は競争を避けるためにモデルを秘密にしていましたが、今は秘密が明かされました!
pub.towardsai.net
Salesforce XGen-7Bによる完全オープンソースの基盤モデルに会いましょう
このモデルは、最大8Kトークンの長いシーケンスを完全に無料で許可します
pub.towardsai.net
MPT-30Bに会いましょう:GPT-3を凌駕する完全オープンソースのLLM
MPT-30Bの上に構築された、MPT-30B-InstructとMPT-30B-Chatの2つの微調整バリアントをリリースします
pub.towardsai.net
LAMPスタックを忘れてください:LLMスタックがここにあります!
Huggingfaceは、NLP / LLMエコシステムで新しい標準スタックとして位置づけられています。今、企業は求めています…
pub.towardsai.net
Gorillaに会ってください:API呼び出しに最適化された完全なオープンソースLLM
アプリケーションプログラミングインターフェースの呼び出しを書く際に、幻覚が少なく、GPT-4よりも優れています
pub.towardsai.net
Lightening-AIによるLit-Parrotを使用してGPTモードを微調整する
データを持ち込んで、GPUでトレーニングしましょう!
pub.towardsai.net
WizardLM:完全オープンソースの自動化された指示データ生成ツール
指示ベースのトレーニングデータの生成の手間を省く
pub.towardsai.net
Falcon-40B:完全オープンソースのFoundation LLM
各コントリビューターは、永続的かつ非排他的かつ無効の著作権ライセンスをあなたに付与します…
pub.towardsai.net
H2Oaiが完全オープンソースのGPTをリリース
h2oGPT-20B、h2oGPT-12B v1、およびh2oGPT-12B v2モデルは、Apache 2.0ライセンスでリリースされました(完全に無料で…
pub.towardsai.net

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
