「紙からピクセルへ:手書きテキストのデジタル化のための最良の技術の評価」
Best technology evaluation for digitization of handwritten text From paper to pixels
OCR、Transformerモデル、およびPromptエンジニアリングベースのアンサンブル技術に関する比較的深い探求
著者:Sohrab Sani および Diego Capozzi
組織は長い間、歴史的な手書き文書をデジタル化するという手間のかかる作業に取り組んできました。以前は、Optical Character Recognition(OCR)技術、例えばAWS Textract(TT)[1]やAzure Form Recognizer(FR)[2]などがその先頭を切って進められていました。これらのオプションは広く利用可能なものかもしれませんが、多くの欠点もあります。価格が高く、長時間のデータ処理/クリーニングが必要であり、最適な精度を出すことができない場合もあります。画像セグメンテーションと自然言語処理の最新のディープラーニングの進歩により、トランスフォーマベースのアーキテクチャを利用したOCRフリーの技術、例えばDocument Understanding Transformer(Donut)[3]モデルが開発されました。
本研究では、手書きのフォームから作成されたカスタムデータセットを使用して、このデジタル化プロセスにおけるOCRとTransformerベースの技術を比較します。この比較的簡単なタスクのベンチマークは、より長い手書き文書に対するより複雑な応用に向けて進むためのものです。精度を向上させるために、TTとファインチューニングされたDonutモデルの出力を組み合わせるために、gpt-3.5-turbo Large Language Model(LLM)を使用したPromptエンジニアリングを利用したアンサンブル手法も検討しました。
この作業のコードはこちらのGitHubリポジトリで閲覧することができます。データセットはこちらのHugging Faceリポジトリで利用可能です。
目次:
・ データセット作成
・ 方法 ∘ Azure Form Recognizer(FR) ∘ AWS Textract(TT) ∘ Donut ∘ アンサンブル手法:TT、Donut、GPT
・ モデルのパフォーマンス測定 ∘ FLA ∘ CBA ∘ データカバレッジ ∘ コスト
・ 結果
・ 追加の考慮事項 ∘ Donutモデルのトレーニング ∘ Promptエンジニアリングの変動性
・ 結論
・ 次のステップ
・ 参考文献
・ 謝辞
データセットの作成
この研究では、NIST Special Database 19データセット[4]から2100枚の手書きフォーム画像を使用してカスタムデータセットを作成しました。図1はこれらのフォームのサンプル画像を示しています。最終的なコレクションには2099枚のフォームが含まれています。このデータセットをキュレートするために、各NISTフォームの上部セクションをトリミングし、DATE、CITY、STATE、およびZIP CODE(以下「ZIP」と呼ぶ)キーを赤いボックスでハイライトしました[図1]。このアプローチにより、比較的簡単なテキスト抽出タスクでベンチマークプロセスが開始され、データセットの選択と手動ラベリングを迅速に行うことができました。執筆時点では、JSONキー-フィールドテキスト抽出に使用できる手書きフォームのラベル付き画像が公開されているとは知られていません。
私たちは、ドキュメントから各キーの値を手動で抽出し、正確性を確認しました。合計で、少なくとも1つの判読不能な文字を含む68枚のフォームが破棄されました。フォームからの文字は、スペルミスやフォーマットの不一致に関係なく、そのまま記録されました。
Donutモデルをミスデータに対してファインチューニングするために、これらの空のフィールドのトレーニングを可能にするために、67枚の空のフォームが追加されました。フォーム内の欠損値は、JSON出力では「None」という文字列で表されます。
図2aはデータセットからのサンプルフォームを表示し、図2bはそのフォームにリンクされる対応するJSONを共有しています。
表1は、各キーのデータセット内の可変性の内訳を提供しています。最も可変性が高いのはZIP、次いでCITY、DATE、そしてSTATEの順です。すべての日付は1989年内にあり、DATEの可変性全体を減らす可能性があります。また、アメリカ合衆国は50州しかないため、STATEの可変性は個々の州の略語や大文字小文字のスペルを使用したことによって増加しました。
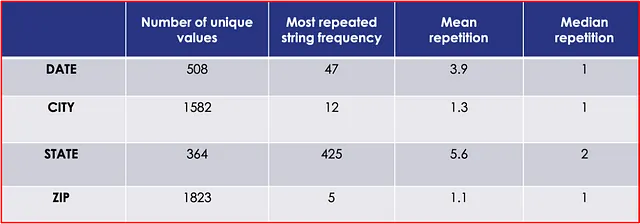
表2は、データセットのさまざまな属性の文字数を要約しています。
上記のデータからわかるように、CITYのエントリが最も長い文字数を持ち、STATEのエントリが最も短いことがわかります。各エントリの中央値は、それぞれの平均値に近く、各カテゴリの平均値周りでの文字数の比較的均一な分布を示しています。
データの注釈付け後、それをトレーニング、検証、およびテストの3つのサブセットに分割しました。それぞれのサンプルサイズは、トレーニングが1400、検証が199、テストが500です。こちらには、このために使用したノートブックへのリンクがあります。
メソッド
ここでは、テストした各メソッドについて詳しく説明し、詳細なPythonコードへのリンクを提供します。メソッドの適用は、まず個別に説明されます(つまり、FR、TT、Donut)、そして次にTT + GPT + Donutアンサンブルアプローチで説明されます。
Azure Form Recognizer(FR)
図3は、Azure FRを使用してフォーム画像から手書きテキストを抽出するワークフローを示しています:
- 画像の保存:これは、ローカルドライブやS3バケット、Azure Blob Storageなどの別のソリューションに保存されることがあります。
- Azure SDK:各画像をストレージからロードし、Azure SDKを介してFR APIに転送するためのPythonスクリプト。
- 事後処理:市販のメソッドを使用する場合、最終出力はしばしば微調整が必要です。以下に、さらなる処理が必要な21の抽出されたキーが示されています:[ ‘DATE’、 ‘CITY’、 ‘STATE’、 ‘DATE’、 ‘ZIP’、 ‘NAME’、 ‘E ZIP’、 ‘·DATE’、 ‘ .DATE ‘、 ‘ NAMR ‘、 ‘ DATE® ‘、 ‘ NAMA ‘、 ‘ _ZIP ‘、 ‘ .ZIP ‘、 ‘ print the following shopsataca i ‘、 ‘ -DATE ‘、 ‘ DATE. ‘、 ‘ No. ‘、 ‘ NAMN ‘、 ‘ STATE\nZIP ‘ ]一部のキーには余分なドットやアンダースコアがあり、削除が必要です。フォーム内のテキストの配置が近いため、抽出された値が誤って関連付けられる場合があります。これらの問題は、ある程度対処されます。
- 結果の保存:結果をピクル形式でストレージスペースに保存します。
AWS Textract(TT)
図4は、AWS TTを使用してフォーム画像から手書きテキストを抽出するワークフローを示しています:
- 画像の保存:画像はS3バケットに保存されます。
- SageMakerノートブック:ノートブックインスタンスは、TT APIとの対話を容易にし、スクリプトの事後処理クリーニングを実行し、結果を保存します。
- TT API:AWSが提供する市販のOCRベースのテキスト抽出APIです。
- 事後処理:市販のメソッドを使用する場合、最終出力はしばしば微調整が必要です。TTは、FRアプローチの21列よりも多い68列のデータセットを生成しました。これは、フィールドと思われる画像内の追加のテキストの検出によるものです。これらの問題は、ルールベースの事後処理中に対処されます。
- 結果の保存:洗練されたデータは、ピクル形式を使用してS3バケットに保存されます。
ドーナツ
既製のOCRベースの手法とは異なり、カスタムフィールドと/またはモデル再学習を介した特定のデータ入力に適応できないため、このセクションではトランスフォーマーモデルアーキテクチャに基づくドーナツモデルを使用してOCRフリーの手法を洗練させます。
まず、JSON形式で手書きテキストを抽出するために、Donutモデルをデータに適用する前に、モデルをファインチューニングしました。モデルを効率的に再学習し、過学習を抑制するために、PyTorch LightningのEarlyStoppingモジュールを使用しました。バッチサイズは2で、トレーニングは14エポック後に終了しました。以下はDonutモデルのファインチューニングプロセスの詳細です:
- トレーニングには1,400枚の画像を割り当て、検証には199枚、残りの500枚をテストに使用しました。
- 基礎モデルとしてnaver-clova-ix/donut-baseを使用しました。このモデルはHugging Faceで利用可能です。
- このモデルはQuadro P6000 GPU(24GBメモリ)を使用してファインチューニングされました。
- トレーニング全体の所要時間は約3.5時間でした。
- 詳細な構成については、リポジトリの
train_nist.yamlを参照してください。
このモデルはHugging Faceのスペースリポジトリからもダウンロードできます。
アンサンブル手法: TT, Donut, GPT
さまざまなアンサンブル手法が試されましたが、TT、Donut、GPTの組み合わせが最も優れた結果を示しました。
TTとDonutを個別に適用して得られたJSON出力をGPTに渡すことで、GPTを使用してこれらのJSON入力の情報とGPTの文脈情報を組み合わせ、より信頼性と精度の高い新しい/クリーナーなJSON出力を生成することを目指しました([表3])。図5は、このアンサンブル手法の視覚的な概要を提供しています。
このタスクのための適切なGPTプロンプトの作成は反復的であり、アドホックなルールを導入する必要がありました。GPTプロンプトをこのタスクに合わせて調整すること(およびデータセットに合わせて調整すること)は、この研究の探索を必要とする側面です(追加の考慮事項セクションを参照)。
モデルの性能評価
この研究では、主に2つの異なる精度指標を使用してモデルの性能を測定しました:
- フィールドレベル精度(FLA)
- 文字ベースの精度(CBA)
カバレッジやコストなどの追加の数量も測定され、関連する文脈情報が提供されました。すべての指標について説明します。
FLA
これはバイナリの測定です。予測されたJSON内のキーのすべての文字が参照JSON内の文字と一致する場合、FLAは1です。ただし、1つの文字でも一致しない場合、FLAは0です。
例を考えてみましょう:
JSON1 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42171'}JSON2 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42071'}JSON1とJSON2をFLAで比較すると、ZIPが一致しないためスコアは0になります。しかし、JSON1を自身と比較すると、FLAスコアは1になります。
CBA
この精度指標は以下のように計算されます:
- 対応する値のペアごとにレーベンシュタイン編集距離を計算する。
- すべての距離を合計し、それぞれの値の総文字列長で割ることで正規化されたスコアを取得する。
- このスコアをパーセンテージに変換する。
2つの文字列のレーベンシュタイン編集距離とは、1つの文字列を他の文字列に変換するために必要な変更の回数です。これには置換、挿入、削除が含まれます。例えば、「marry」を「Murray」に変換する場合、2つの置換と1つの挿入が必要で、合計3つの変更が必要です。これらの変更はさまざまな順序で行うことができますが、少なくとも3つのアクションが必要です。この計算には、NLTKライブラリのedit_distance関数を使用しました。
以下は、説明されたアルゴリズムの実装を示すコードの一部です。この関数は2つのJSON入力を受け取り、精度のパーセンテージを返します。
def dict_distance (dict1:dict, dict2:dict) -> float: distance_list = [] character_length = [] for key, value in dict1.items(): distance_list.append(edit_distance(dict1[key].strip(), dict2[key].strip())) if len(dict1[key]) > len(dict2[key]): character_length.append((len(dict1[key]))) else: character_length.append((len(dict2[key]))) accuracy = 100 - sum(distance_list)/(sum(character_length))*100 return accuracy関数の理解を深めるために、以下の例での動作を見てみましょう:
JSON1 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42171'}JSON2 = {'DATE': 'None', 'CITY': 'None', 'STATE': 'None', 'ZIP': 'None'}JSON3 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'None', 'ZIP': 'None'}dict_distance(JSON1, JSON1): 100% JSON1とJSON1の間には差異がないため、100%の完全なスコアを得ます。dict_distance(JSON1, JSON2): 0% JSON2のすべての文字を変更してJSON1と一致させる必要があるため、0%のスコアになります。dict_distance(JSON1, JSON3): 59% JSON3のSTATEとZIPのキーのすべての文字をJSON1と一致させる必要があり、これにより59%の精度スコアが得られます。
次に、解析された画像サンプルのCBAの平均値に焦点を当てます。これらの精度測定は、検査された文字列がすべて一致するかどうかを測定するため、非常に厳格です。FLAはそのバイナリ的な性質から、部分的に正しいケースに対して盲目的です。CBAはFLAよりも保守的ではありますが、部分的に正しいインスタンスを特定する能力がありますが、テキストの大文字と小文字も考慮し、テキストの内容を回復するか、書かれたコンテンツの正確な形式を保持するかによって重要度が異なる場合があります。全体的に、私たちはテキスト抽出の正確さをテキストの意味論よりも優先するため、より保守的なアプローチのためにこれらの厳格な測定値を使用することにしました。
カバレッジ
この数量は、フォーム画像のフィールドがすべて出力JSONから抽出された割合と定義されます。これは、正確性に関係なく、フォームからすべてのフィールドを抽出する能力を総合的に監視するのに役立ちます。カバレッジが非常に低い場合、特定のフィールドが抽出プロセスから常に抜け落ちていることを示します。
コスト
これは各メソッドをテストデータセット全体に適用することによって発生するコストの簡単な見積もりです。DonutモデルのファインチューニングにかかるGPUのコストは含まれていません。
結果
テストデータセット(500サンプルを含む)ですべてのメソッドのパフォーマンスを評価しました。このプロセスの結果は表3にまとめられています。
FLAを使用する場合、伝統的なOCRベースのメソッドであるFRとTTのパフォーマンスは類似しており、比較的低い精度(FLA〜37%)を示しています。これは理想的ではありませんが、これはFLAの厳しい要件によるものかもしれません。一方、すべてのJSONキーを考慮した平均CBA値であるCBA Totalを使用すると、TTとFRのパフォーマンスははるかに受け入れられるものになり、値が77%を超えます。特に、TT(CBA Total = 89.34%)はFRよりも約15%優れたパフォーマンスを発揮します。この動作は、DATEとCITYのカテゴリの値[表3]や、2099枚の画像のサンプル全体に対して測定されるFLAとCBA Totalでも同様に見られます(TT:FLA = 40.06%、CBA Total = 86.64%、FR:FLA = 35.64%、CBA Total = 78.57%)。これらの2つのモデルを適用するためのコスト値は同じですが、TTはフィールドのすべてを抽出する能力がFRよりも高くなり、カバレッジ値は約9%高くなります。
これらのより伝統的なOCRベースのモデルのパフォーマンスを定量化することで、純粋なDonutアプローチとTTおよびGPTを組み合わせたアプローチの利点を評価しました。TTをベンチマークとして使用しました。
このアプローチを利用する利点は、1400枚の画像とそれに対応するJSONで微調整されたDonutモデルから改善されたメトリックによって示されます。TTの結果と比較して、このモデルのグローバルFLAは54%、CBA合計は95.23%であり、それぞれ38%および6%の改善を表しています。FLAにおいて最も大きな増加が見られ、テストサンプルの半分以上のフォームフィールドを正確に取得できることを示しています。
モデルの微調整に使用される画像の数が限られているにもかかわらず、CBAの増加は注目に値します。Donutモデルは、カバレッジとキーベースのCBAメトリックの全体的な値が改善されたことから利点があることを示しており、これらは2%から24%の間で増加しました。カバレッジは100%を達成し、モデルがすべてのフォームフィールドからテキストを抽出できることを示しており、このようなモデルの本番化における後処理の手間を減らすことができます。
このタスクとデータセットに基づくと、OCRモデルによって生成される結果よりも、微調整されたDonutモデルの使用が優れていることが示されています。最後に、アンサンブル方法を探索し、さらなる改善が可能かどうかを評価しました。
TTと微調整されたDonutを組み合わせたアンサンブルのパフォーマンスは、gpt-3.5-turboによってパワーアップされます。FLAなどの特定のメトリックを選択する場合、改善が可能です。このモデルのすべてのメトリック(CBA Stateとカバレッジを除く)は、微調整されたDonutモデルと比較して、約0.2%から約10%の範囲で増加しています。唯一のパフォーマンスの低下は、CBA Stateで見られ、微調整されたDonutモデルと比較して約3%低下しています。これは、このメトリックを改善するためにさらに微調整が可能なGPTプロンプトの使用によるものかもしれません。最後に、カバレッジの値は100%のままです。
その他の個別フィールドと比較した場合、日付の抽出(CBA Dateを参照)はより高い効率性が示されました。これは、すべての日付が1989年に起源があるため、日付フィールドの変動が限られているためと考えられます。
パフォーマンス要件がかなり保守的であれば、FLAの10%の増加は重要であり、より複雑なインフラの構築と維持の高いコストを正当化するかもしれません。これは、LLMプロンプトの修正によって導入される変動のソースも考慮する必要があります。ただし、パフォーマンス要件が厳しくない場合、このアンサンブル手法によってもたらされるCBAメトリックの改善は、追加のコストと労力に値しないかもしれません。
総じて、当社の研究は、個別のOCRベースのメソッド(FRとTT)にはそれぞれ長所がある一方、1400のサンプルのみで微調整されたDonutモデルがそれらの精度のベンチマークを容易に上回ることを示しています。さらに、gpt-3.5-turboプロンプトによってTTと微調整されたDonutモデルをアンサンブル化することで、FLAメトリックによる精度がさらに向上します。次に、Donutモデルの微調整プロセスとGPTプロンプトに関する追加の考慮事項について調べます。
追加の考慮事項
Donutモデルのトレーニング
Donutモデルの精度を向上させるために、3つのトレーニングアプローチを試行しました。それぞれは、推論の精度を向上させながら、トレーニングデータに対するオーバーフィッティングを防ぐことを目指しています。Table 4には、結果の要約が表示されています。
1. 30エポックの訓練: Donutモデルを30エポック訓練しました。DonutのGitHubリポジトリで提供される設定を使用しました。この訓練セッションは約7時間続き、FLAは50.0%となりました。異なるカテゴリのCBA値は異なり、CITYは90.55%、ZIPは98.01%を達成しました。しかし、val_metricを調べたところ、19エポック目以降でモデルが過学習を始めていることに気付きました。
2. 19エポックの訓練: 初期の訓練中に得られた知見に基づいて、モデルを19エポックのみで微調整しました。結果として、FLAが55.8%に大幅に改善されました。全体的なCBAおよびキーベースのCBAも精度が向上しました。しかし、これらの有望なメトリクスにも関わらず、val_metricによって過学習の兆候が検出されました。
3. 14エポックの訓練: モデルをさらに改善し、過学習を抑制するために、PyTorch LightningのEarlyStoppingモジュールを使用しました。このアプローチにより、14エポック後に訓練が終了しました。結果として、FLAは54.0%となり、19エポックの訓練と比較して、CBAは同等またはそれ以上の精度を示しました。
これらの3つの訓練セッションの結果を比較すると、19エポックの訓練がわずかに優れたFLAを示しているものの、14エポックの訓練のCBAメトリクスが全体的に優れていることがわかります。また、val_metricは19エポックの訓練に対する懸念を強調し、過学習の傾向があることを示しています。
結論として、EarlyStoppingを使用して14エポックで微調整されたモデルが最も堅牢で費用効率が良いと結論づけました。
プロンプトエンジニアリングの変動性
データ抽出効率を向上させるために、微調整されたDonutモデルとTTの結果を組み合わせることで、プロンプトエンジニアリングの2つのアプローチ(ver1とver2)を行いました。モデルを14エポック訓練した後、プロンプトver1はFLAが59.6%であり、すべてのキーのCBAメトリクスが高い結果となりました[Table 5]。一方、プロンプトver2はFLAが54.4%に低下しました。CBAメトリクスの詳細な分析では、ver2のすべてのカテゴリの精度スコアがver1と比較してわずかに低下していることが示され、この変更がもたらす重要な違いが強調されました。
データセットの手動ラベリングプロセスでは、TTとFRの結果を利用し、フォームからのテキストの注釈付けを行いながら、プロンプトver1を開発しました。プロンプトver2は先行バージョンと本質的に同じですが、若干の修正が加えられました。プロンプトver1に含まれる空行や冗長なスペースを削除して、プロンプトを洗練させることが主な目的でした。
要約すると、私たちの実験は、ささいな調整の微妙な影響を示しています。プロンプトver1はより高い精度を示していますが、それをプロンプトver2に洗練化するプロセスは、あらゆるメトリクスでパフォーマンスを低下させる結果となりました。これはプロンプトエンジニアリングの複雑な性質と、使用するプロンプトを最終的に確定する前に入念なテストが必要であることを強調しています。
プロンプトver1はこのノートブックで利用可能であり、プロンプトver2のコードはこちらで確認できます。
結論
手書きフォームの画像からテキストを抽出するためのベンチマークデータセットを作成しました。このデータセットは4つのフィールド(DATE、CITY、STATE、ZIP)を含む手書きフォームの画像を手動でJSON形式に注釈付けしました。このデータセットを使用して、OCRベースのモデル(FRとTT)と、我々のデータセットを使用して微調整されたDonutモデルの性能評価を行いました。最後に、TTと我々の微調整されたDonutモデルの出力を使用して、アンサンブルモデルを構築しました。
TTがFRよりも優れたパフォーマンスを発揮したことを確認し、これをベンチマークとして、Donutモデルの単独での性能向上やTTおよびGPTとの組み合わせによって生じる可能性のある改善を評価しました。モデルの性能メトリクスによれば、この微調整されたDonutモデルは明確な精度向上を示しており、OCRベースのモデルに対して採用することを正当化しています。アンサンブルモデルはFLAの大幅な改善を示しましたが、より高いコストがかかり、より厳しいパフォーマンス要件のあるケースでの使用を検討することができます。一貫した基盤モデルであるgpt-3.5-turboを使用しているにもかかわらず、プロンプトのわずかな変更によって出力JSON形式に注目すべき違いが生じることを観察しました。このような予測できない性質は、製品で市販のLLMを使用する際の重要な欠点です。私たちは現在、この問題に対処するために、オープンソースのLLMに基づいたよりコンパクトなクリーニングプロセスを開発しています。
次のステップ
- Table 2の価格列から分かるように、この作業で最も高価な認知サービスはOpenAI APIの呼び出しでした。したがって、コストを最小限に抑えるために、フルファインチューニング、プロンプトチューニング[5]、QLORA [6]などの手法を利用して、seq2seqタスクのためのLLMの微調整に取り組んでいます。
- プライバシーの理由から、データセットの画像の名前ボックスは黒い四角で隠されています。この問題に対処するために、データセットにランダムな名字と名前を追加する作業を行っています。これにより、データ抽出フィールドは4つから5つに増えます。
- 将来的には、この研究を拡張し、フォーム全体やより詳細なドキュメントのテキスト抽出も含めたテキスト抽出タスクの複雑さを高める予定です。
- ドーナツモデルのハイパーパラメータ最適化を調査します。
参考文献
- Amazon Textract, AWS Textract
- Form Recognizer, Form Recognizer (now Document Intelligence)
- Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, JeongYeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun, OCR-free Document Understanding Transformer (2022), European Conference on Computer Vision (ECCV)
- Grother, P. and Hanaoka, K. (2016) NIST Handwritten Forms and Characters Database (NIST Special Database 19). DOI: http://doi.org/10.18434/T4H01C
- Brian Lester, Rami Al-Rfou, Noah Constant, The Power of Scale for Parameter-Efficient Prompt Tuning (2021), arXiv:2104.08691
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer, QLoRA: Efficient Finetuning of Quantized LLMs (2023), https://arxiv.org/abs/2305.14314
謝辞
このプロジェクトに関する継続的なサポートと議論について、同僚のDr. David Rodriguesに感謝します。また、Kainosにもサポートいただきました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






