BERTopicを使用したクラスごとのトピック
BERTopicのクラスごとのトピック
カテゴリごとのテキストの違いを理解する方法
現在、製品分析を行うにあたり、多くの自由形式のテキストに遭遇します:
- ユーザーがAppStoreやGoogle Play、他のサービスにコメントを残す;
- クライアントがカスタマーサポートに連絡し、自然言語を使用して問題を説明する;
- さらなるフィードバックを得るために自分自身で調査を行い、ほとんどの場合、いくつかの自由形式の質問があります。
数十万ものテキストがあります。すべてを読んで洞察を得るには年がかかるでしょう。幸いにも、このプロセスを自動化するのに役立つ多くのDSツールがあります。そのようなツールの一つがトピックモデリングであり、今日はそれについて話したいと思います。
基本的なトピックモデリングは、テキスト(たとえば、レビュー)の主要なトピックとその混合を理解するのに役立ちます。ただし、1つのポイントに基づいて決定を下すのは難しいです。たとえば、レビューの14.2%がアプリ内の広告が多すぎることに関するものです。これは良いことなのか悪いことなのか?それについて調べるべきでしょうか?実を言うと、私にはわかりません。
しかし、顧客をセグメント化してみれば、この割合がAndroidユーザーでは34.8%、iOSでは3.2%であることがわかるでしょう。その場合、Androidで広告を表示しすぎるか、またはAndroidユーザーの広告に対する耐性が低いかを調査する必要があることが明らかになります。
- 「NVIDIAがインドの巨大企業と提携し、世界最大の人口を持つ国でAIを進める」
- 「VAST DataのプラットフォームがAIイノベーションの障壁を取り除く方法」
- 「Pythonを使用して、複数のファイル(またはURL)を並列でダウンロードする」
そのため、トピックモデルを構築する方法だけでなく、カテゴリ間でトピックを比較する方法も共有したいと思います。最終的には、各トピックごとに洞察に富んだグラフを取得します。
データ
自由形式のテキストの最も一般的な現実のケースは、レビューの一種です。したがって、この例では、ロンドンのいくつかのホテルチェーンに関連するコメントを使用しましょう。
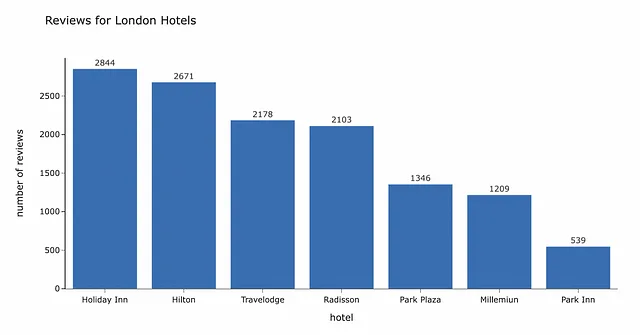
データのテキスト分析を開始する前に、データの概要を把握する価値があります。合計で、7つの異なるホテルチェーンに関する12,890件のレビューがあります。
BERTopic
さて、データが揃ったので、新しい素敵なツールであるトピックモデリングを適用して洞察を得ることができます。冒頭で言及したように、このテキスト分析には、トピックモデリングと強力で使いやすいBERTopicパッケージ(ドキュメント)を使用します。
トピックモデリングとは何かと思われるかもしれません。それは自然言語処理に関連する教師なしの機械学習技術です。テキスト(通常はドキュメントと呼ばれる)内の隠れた意味的なパターンを見つけ、それらに「トピック」を割り当てることができます。事前にトピックのリストを持つ必要はありません。アルゴリズムが自動的に定義します。通常、最も重要な単語(トークン)またはNグラムの袋の形で。
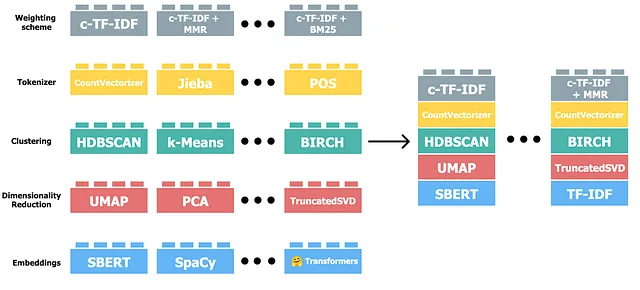
BERTopicは、HuggingFace transformersとクラスベースのTF-IDFを使用したトピックモデリングのためのパッケージです。BERTopicは非常に柔軟なモジュール型のパッケージであり、必要に応じて調整することができます。
それがどのように機能するかをより良く理解したい場合は、このライブラリの作者によるこのビデオを見ることをお勧めします。
前処理
GitHubで完全なコードを見つけることができます。
ドキュメントによると、通常、ドキュメントに意味を持たないHTMLタグやその他のマークダウンなどのノイズが多くない限り、データの前処理は必要ありません。これは、BERTopicの大きな利点です。なぜなら、多くのNLPメソッドでは、データの前処理には多くの定型作業が必要だからです。どのようなものか興味がある場合は、LDAを使用したトピックモデリングのためのこのガイドを参照してください。
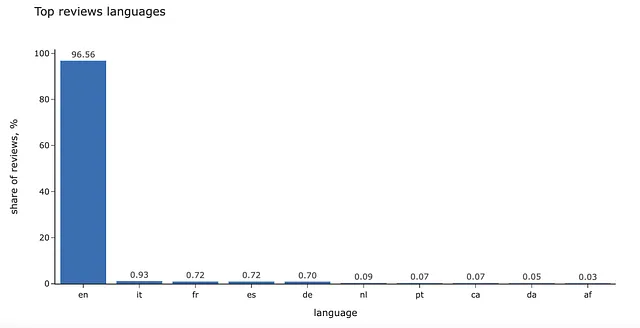
複数の言語のデータを使用して、BERTopicを使用することができます。BERTopic(language= "multilingual")を指定します。しかし、私の経験から言うと、テキストを1つの言語に翻訳した方がモデルの動作が少し良くなります。そのため、すべてのコメントを英語に翻訳します。
翻訳にはdeep-translatorパッケージを使用します(PyPIからインストールできます)。
また、言語ごとの分布を見るのも興味深いかもしれません。その場合は、langdetectパッケージを使用することができます。
import langdetectfrom deep_translator import GoogleTranslatordef get_language(text): try: return langdetect.detect(text) except KeyboardInterrupt as e: raise(e) except: return '<-- エラー -->' def get_translation(text): try: return GoogleTranslator(source='auto', target='en')\ .translate(str(text)) except KeyboardInterrupt as e: raise(e) except: return '<-- エラー -->'df['language'] = df.review.map(get_language)df['reviews_transl'] = df.review.map(get_translation)私たちの場合、コメントの95%以上が既に英語です。
データをより良く理解するために、レビューの長さの分布を見てみましょう。非常に短い(おそらく有意義でないコメント)が多くあります。レビューの約5%が20文字未満です。
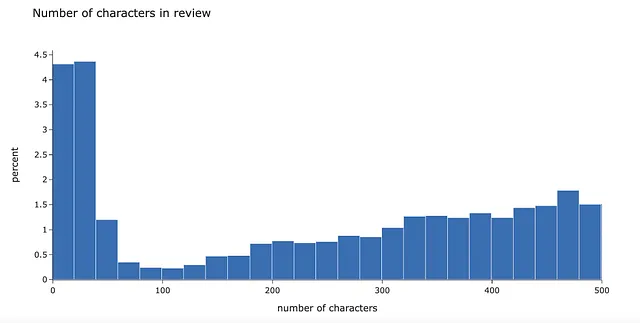
このようなコメントにはあまり情報がないことを確認するために、最も一般的な例を見ることができます。
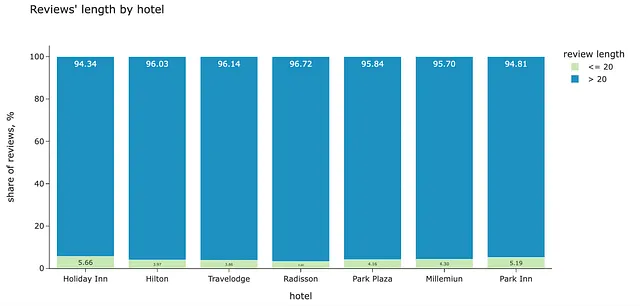
df.reviews_transl.map(lambda x: x.lower().strip()).value_counts().head(10)reviewsnone 74<-- エラー --> 37great hotel 12perfect 8excellent value for money 7good value for money 7very good hotel 6excellent hotel 6great location 6very nice hotel 5したがって、20文字未満のコメントをすべてフィルタリングすることができます。12,890件のレビューのうち556件(4.3%)です。その後、より文脈のある長い文のみを分析します。これは例に基づいた任意の閾値であり、いくつかのレベルを試してフィルタリングされるテキストを確認できます。
このフィルタがいくつかのホテルに対して不均衡な影響を与えていないか確認する価値があります。短いコメントの割合は、異なるカテゴリに対して非常に近いです。したがって、データは問題ありません。
最も単純なトピックモデル
さあ、最初のトピックモデルを構築しましょう。ライブラリの動作を理解するために、最も基本的なものから始めて改善していきます。
少なくとも1つのMLパッケージを使用したことのある人なら誰でも簡単に理解できるコード行数でトピックモデルを学習することができます。
from bertopic import BERTopicdocs = list(df.reviews.values)topic_model = BERTopic()topics, probs = topic_model.fit_transform(docs)デフォルトのモデルは113のトピックを返します。トップのトピックを見てみましょう。
topic_model.get_topic_info().head(7).set_index('Topic')[ ['Count', 'Name', 'Representation']]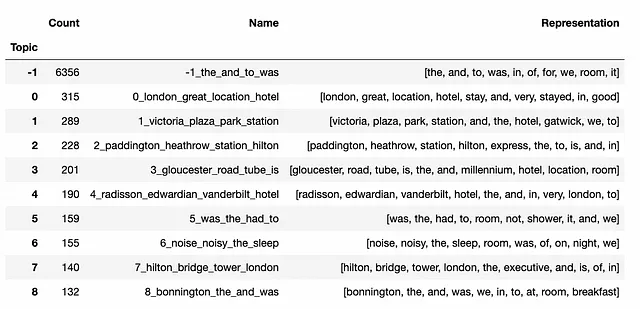
最も大きなグループはTopic -1であり、外れ値に対応します。デフォルトでは、BERTopicはクラスタリングにHDBSCANを使用し、すべてのデータポイントをクラスタの一部にすることはありません。私たちの場合、6,356件のレビューが外れ値です(すべてのレビューの約49.3%)。これはデータのほぼ半分であり、後でこのグループで作業します。
トピック表現は通常、このトピックに固有の最も重要な単語のセットであり、他の単語とは異なります。したがって、トピックを理解する最良の方法は、主要な用語を見ることです(BERTopicでは、クラスベースのTF-IDFスコアを使用して単語をランク付けする方法が使用されます)。
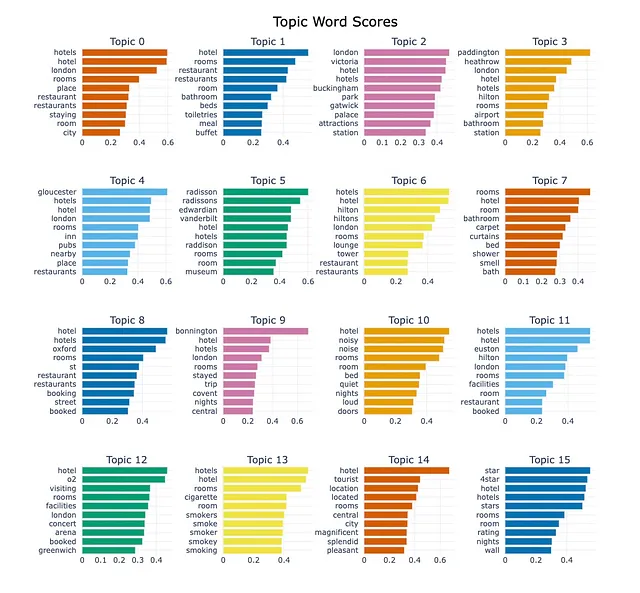
topic_model.visualize_barchart(top_n_topics = 16, n_words = 10)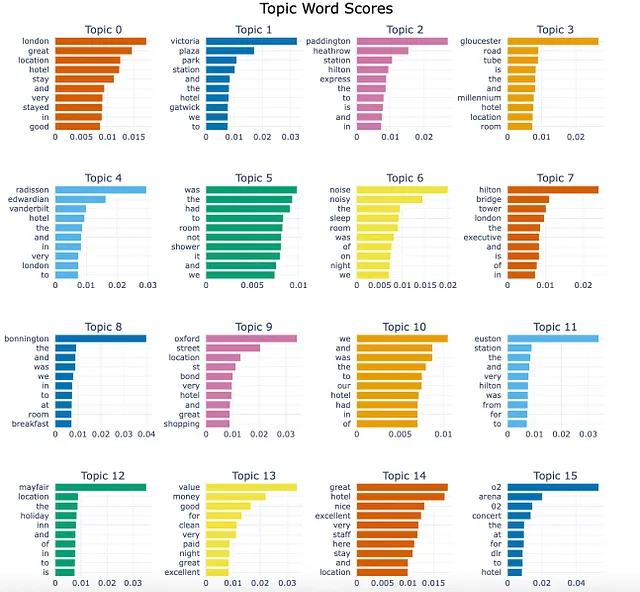
BERTopicには、コースレビューの違いを理解するためのクラスごとのトピック表現もあります。
topics_per_class = topic_model.topics_per_class(docs, classes=filt_df.hotel)topic_model.visualize_topics_per_class(topics_per_class, top_n_topics=10, normalize_frequency = True)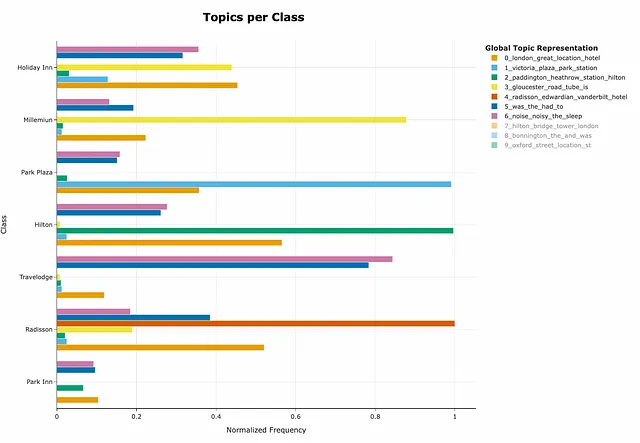
このグラフの解釈方法について疑問がある場合は、あなただけではありません – 私も推測できませんでした。ただし、著者はこのパッケージを親切にサポートしており、GitHubには多くの回答があります。議論から、現在の正規化アプローチはクラスごとの異なるトピックの割合を表示しないことがわかりました。したがって、初期のタスクは完全に解決されていません。
ただし、10行未満のコードで最初のイテレーションを行いました。素晴らしいですが、改善の余地もあります。
外れ値の取り扱い
前述のように、データポイントのほぼ50%が外れ値と見なされます。かなり多いですので、何ができるか見てみましょう。
ドキュメントには、外れ値の取り扱いに関する4つの異なる戦略が提供されています:
- トピック-ドキュメントの確率に基づくもの
- トピック分布に基づくもの
- c-TF-IFD表現に基づくもの
- ドキュメントとトピックの埋め込みに基づくもの
さまざまな戦略を試して、データに最適なものを見つけることができます。
外れ値の例を見てみましょう。これらのレビューは比較的短いですが、複数のトピックを含んでいます。

BERTopicはクラスタリングを使用してトピックを定義します。つまり、1つのドキュメントに対して複数のトピックが割り当てられることはありません。ほとんどの実生活の場合、テキストには複数のトピックの混合が含まれる場合があります。複数のトピックを持つドキュメントにトピックを割り当てることができないことがあります。
幸いなことに、それには解決策があります – トピック分布を使用します。この方法では、各ドキュメントをトークンに分割します。次に、サブセンテンス(スライディングウィンドウとストライドで定義される)を形成し、そのようなサブセンテンスごとにトピックを割り当てます。
このアプローチを試して、トピックのない外れ値の数を減らすことができるかどうかを見てみましょう。
トピックモデルの改善
ただし、トピック分布は適合したトピックモデルに基づいているため、それを向上させましょう。
まず第一に、CountVectorizerを使用できます。これにより、ドキュメントがトークンに分割される方法が定義されます。また、to、not、theなどの意味のない単語を取り除くのにも役立ちます(最初のモデルには多くのこのような単語が含まれています)。
さらに、トピックの表現を改善し、さまざまなモデルを試すこともできます。私はKeyBERTInspiredモデル(詳細はこちら)を使用しましたが、他のオプション(例:LLMs)も試すことができます。
from sklearn.feature_extraction.text import CountVectorizerfrom bertopic.representation import KeyBERTInspired, PartOfSpeech, MaximalMarginalRelevancemain_representation_model = KeyBERTInspired()aspect_representation_model1 = PartOfSpeech("en_core_web_sm")aspect_representation_model2 = [KeyBERTInspired(top_n_words=30), MaximalMarginalRelevance(diversity=.5)]representation_model = { "Main": main_representation_model, "Aspect1": aspect_representation_model1, "Aspect2": aspect_representation_model2 }vectorizer_model = CountVectorizer(min_df=5, stop_words = 'english')topic_model = BERTopic(nr_topics = 'auto', vectorizer_model = vectorizer_model, representation_model = representation_model)topics, ini_probs = topic_model.fit_transform(docs)トピックの数を減らすために、nr_topics = 'auto'を指定しました。その後、類似度が閾値を超えるすべてのトピックが自動的にマージされます。この機能により、99のトピックが得られました。
トップのトピックとその割合を取得するための関数を作成しましたので、より簡単に分析することができます。新しいトピックセットを見てみましょう。
def get_topic_stats(topic_model, extra_cols = []): topics_info_df = topic_model.get_topic_info().sort_values('Count', ascending = False) topics_info_df['Share'] = 100.*topics_info_df['Count']/topics_info_df['Count'].sum() topics_info_df['CumulativeShare'] = 100.*topics_info_df['Count'].cumsum()/topics_info_df['Count'].sum() return topics_info_df[['Topic', 'Count', 'Share', 'CumulativeShare', 'Name', 'Representation'] + extra_cols]get_topic_stats(topic_model, ['Aspect1', 'Aspect2']).head(10)\ .set_index('Topic')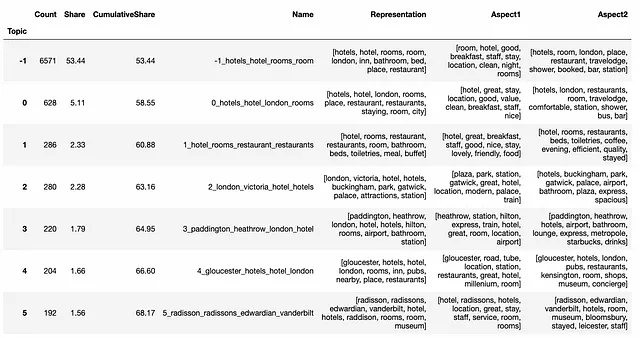
クラスター間の関係をより理解するために、Interoptic距離マップを見ることもできます。例えば、いくつかのクラスターがお互いに近いかどうかを確認することができます。また、親トピックとサブトピックを定義するためにも使用することができます。これは階層的トピックモデリングと呼ばれ、他のツールでも使用することができます。
topic_model.visualize_topics()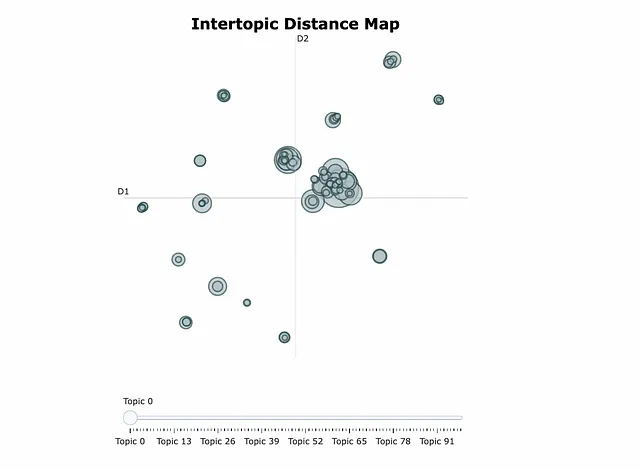
トピックをよりよく理解するための別の方法は、visualize_documentsグラフ(ドキュメント)を見ることです。
トピックの数が大幅に減少したことがわかります。また、トピックの表現には無意味なストップワードがありません。
トピック数の削減
ただし、結果には類似したトピックがまだ見られます。このようなトピックを調査し、手動でマージすることができます。
そのために、類似度行列を作成します。私はn_clustersを指定し、トピックをクラスタリングして視覚化しました。
topic_model.visualize_heatmap(n_clusters = 20)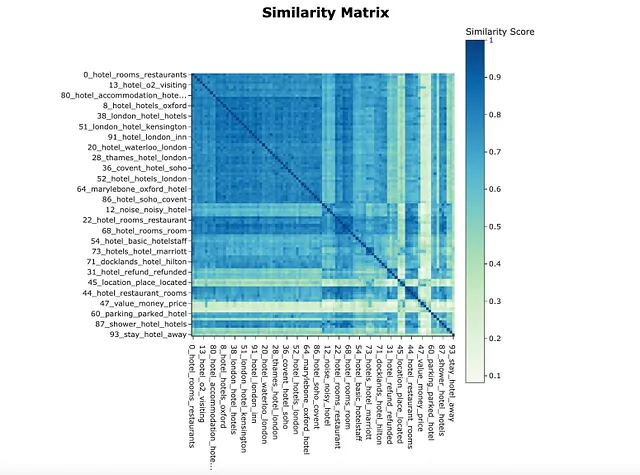
いくつかの非常に近いトピックがあります。ペアの距離を計算し、トップのトピックを見てみましょう。
from sklearn.metrics.pairwise import cosine_similaritydistance_matrix = cosine_similarity(np.array(topic_model.topic_embeddings_))dist_df = pd.DataFrame(distance_matrix, columns=topic_model.topic_labels_.values(), index=topic_model.topic_labels_.values())tmp = []for rec in dist_df.reset_index().to_dict('records'): t1 = rec['index'] for t2 in rec: if t2 == 'index': continue tmp.append( { 'topic1': t1, 'topic2': t2, 'distance': rec[t2] } )pair_dist_df = pd.DataFrame(tmp)pair_dist_df = pair_dist_df[(pair_dist_df.topic1.map( lambda x: not x.startswith('-1'))) & (pair_dist_df.topic2.map(lambda x: not x.startswith('-1')))]pair_dist_df = pair_dist_df[pair_dist_df.topic1 < pair_dist_df.topic2]pair_dist_df.sort_values('distance', ascending = False).head(20)GitHubの議論で距離行列を取得する方法についてのガイダンスを見つけました。
今、コサイン類似度によるトップのトピックのペアが見えます。意味が近いトピックをマージすることができます。

topic_model.merge_topics(docs, [[26, 74], [43, 68, 62], [16, 50, 91]])
df['merged_topic'] = topic_model.topics_注意:マージ後、すべてのトピックのIDと表現が再計算されるため、使用している場合は更新する価値があります。
さて、私たちは初期モデルを改善し、次に進む準備ができました。
実際のタスクでは、最適な結果を得るために、トピックのマージに時間をかけることや、表現やクラスタリングの異なるアプローチを試すことが価値があります。
もう1つの潜在的なアイデアは、コメントがかなり長いため、レビューを個々の文に分割することです。
トピック分布
トピックとトークンの分布を計算しましょう。ウィンドウは4(著者は4-8トークンを使用することを勧めています)で、ストライドは1です。
topic_distr, topic_token_distr = topic_model.approximate_distribution(docs, window = 4, calculate_tokens=True)例えば、このコメントはサブセンテンス(または4つのトークンのセット)に分割され、既存のトピックの中で最も近いものが各サブセンテンスに割り当てられます。そして、これらのトピックは集計され、文全体の確率を計算するために使用されます。詳細はドキュメントを参照してください。

このデータを使用すると、各レビューの異なるトピックの確率を取得できます。
topic_model.visualize_distribution(topic_distr[doc_id], min_probability=0.05)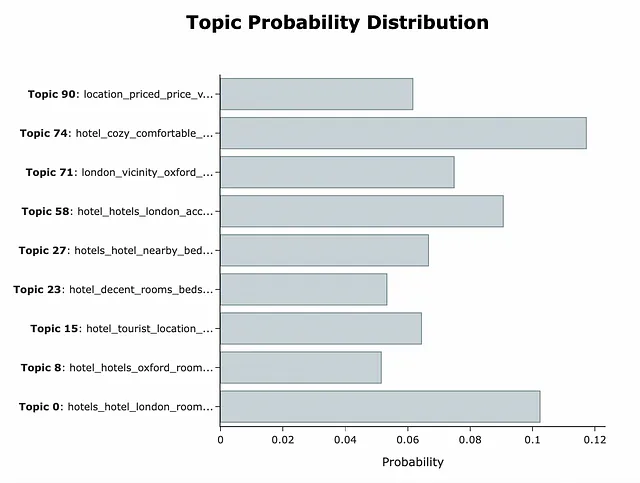
さらに、各トピックの用語の分布を見ることもでき、なぜこの結果が得られたのかを理解することができます。この例では、best very beautifulがトピック74の主要な用語であり、location close toがいくつかの関連する場所に関連するトピックを定義しています。
vis_df = topic_model.visualize_approximate_distribution(docs[doc_id], topic_token_distr[doc_id])vis_df
この例は、まだかなり似ているトピックがあるため、トピックのマージにさらに時間をかける必要があるかもしれないことも示しています。
さて、各トピックとレビューに確率があります。次のタスクは、確率が低すぎる関係のないトピックをフィルタリングするための閾値を選択することです。
通常の方法で行うことができます。異なる閾値レベルごとに、レビューごとに選択されたトピックの分布を計算しましょう。
tmp_dfs = []# 異なる閾値レベルを反復処理for thr in tqdm.tqdm(np.arange(0, 0.35, 0.001)):# 各ドキュメントごとに閾値以上の確率を持つトピックの数を計算する tmp_df = pd.DataFrame(list(map(lambda x: len(list(filter(lambda y: y >= thr, x))), topic_distr))).rename(columns = {0: 'num_topics'}) tmp_df['num_docs'] = 1 tmp_df['num_topics_group'] = tmp_df['num_topics']\ .map(lambda x: str(x) if x < 5 else '5+') # 統計情報を集計 tmp_df_aggr = tmp_df.groupby('num_topics_group', as_index = False).num_docs.sum() tmp_df_aggr['threshold'] = thr tmp_dfs.append(tmp_df_aggr)num_topics_stats_df = pd.concat(tmp_dfs).pivot(index = 'threshold', values = 'num_docs', columns = 'num_topics_group').fillna(0)num_topics_stats_df = num_topics_stats_df.apply(lambda x: 100.*x/num_topics_stats_df.sum(axis = 1))# 可視化colormap = px.colors.sequential.YlGnBupx.area(num_topics_stats_df, title = 'トピック数の分布', labels = {'num_topics_group': 'トピック数', 'value': 'レビューの割合, %'}, color_discrete_map = { '0': colormap[0], '1': colormap[3], '2': colormap[4], '3': colormap[5], '4': colormap[6], '5+': colormap[7] })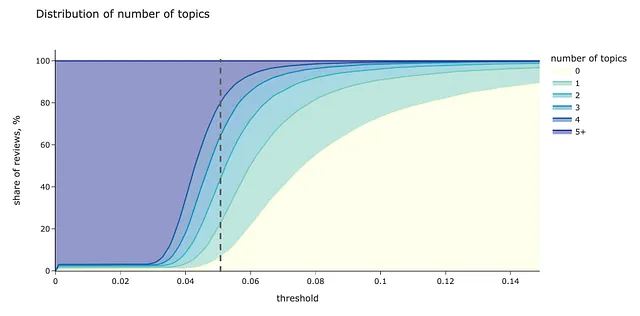
threshold = 0.05は良い候補のようです。このレベルでは、トピックのないレビューの割合がまだ十分に低い(6%未満)一方、4つ以上のトピックを持つコメントの割合も高すぎません。
このアプローチにより、外れ値の割合を53.4%から5.8%に減らすことができました。したがって、複数のトピックを割り当てることは外れ値を処理する効果的な方法となります。
この閾値で各文書のトピックを計算しましょう。
threshold = 0.13# 各文書の確率が0.13以上のトピックを定義df['multiple_topics'] = list(map( lambda doc_topic_distr: list(map( lambda y: y[0], filter(lambda x: x[1] >= threshold, (enumerate(doc_topic_distr))) )), topic_distr))# docid、topictmp_data = []for rec in df.to_dict('records'): if len(rec['multiple_topics']) != 0: mult_topics = rec['multiple_topics'] else: mult_topics = [-1] for topic in mult_topics: tmp_data.append( { 'topic': topic, 'id': rec['id'], 'course_id': rec['course_id'], 'reviews_transl': rec['reviews_transl'] } ) mult_topics_df = pd.DataFrame(tmp_data)ホテルごとの分布の比較
これで、各レビューに複数のトピックがマッピングされ、異なるホテルチェーンのトピックの混合を比較することができます。
特定のホテルに対してトピックの割合が高すぎるか低すぎる場合を見つけましょう。そのために、各トピック+ホテルの組について、そのホテルに関連するコメントの割合と他のすべてのホテルに関連するコメントの割合を計算します。
tmp_data = []for hotel in mult_topics_df.hotel.unique(): for topic in mult_topics_df.topic.unique(): tmp_data.append({ 'hotel': hotel, 'topic_id': topic, 'total_hotel_reviews': mult_topics_df[mult_topics_df.hotel == hotel].id.nunique(), 'topic_hotel_reviews': mult_topics_df[(mult_topics_df.hotel == hotel) & (mult_topics_df.topic == topic)].id.nunique(), 'other_hotels_reviews': mult_topics_df[mult_topics_df.hotel != hotel].id.nunique(), 'topic_other_hotels_reviews': mult_topics_df[(mult_topics_df.hotel != hotel) & (mult_topics_df.topic == topic)].id.nunique() }) mult_topics_stats_df = pd.DataFrame(tmp_data)mult_topics_stats_df['topic_hotel_share'] = 100*mult_topics_stats_df.topic_hotel_reviews/mult_topics_stats_df.total_hotel_reviewsmult_topics_stats_df['topic_other_hotels_share'] = 100*mult_topics_stats_df.topic_other_hotels_reviews/mult_topics_stats_df.other_hotels_reviewsただし、すべての差異が私たちにとって有意義ではありません。トピックの分布の違いが注目に値すると言えるのは、
- 統計的な有意性 – 差異が偶然ではないこと、
- 実用的な有意性 – 差異がX%ポイント(私は1%を使用しました)よりも大きいこと。
from statsmodels.stats.proportion import proportions_ztestmult_topics_stats_df['difference_pval'] = list(map( lambda x1, x2, n1, n2: proportions_ztest( count = [x1, x2], nobs = [n1, n2], alternative = 'two-sided' )[1], mult_topics_stats_df.topic_other_hotels_reviews, mult_topics_stats_df.topic_hotel_reviews, mult_topics_stats_df.other_hotels_reviews, mult_topics_stats_df.total_hotel_reviews))mult_topics_stats_df['sign_difference'] = mult_topics_stats_df.difference_pval.map( lambda x: 1 if x = -sign_percent) and (d <= sign_percent): return '差異なし' if d sign_percent: return '高い' mult_topics_stats_df['diff_significance_total'] = list(map( get_significance, mult_topics_stats_df.topic_hotel_share - mult_topics_stats_df.topic_other_hotels_share, mult_topics_stats_df.sign_difference))すべてのトピックとホテルの統計データを持っており、最後のステップは、カテゴリごとにトピックのシェアを比較する可視化を作成することです。
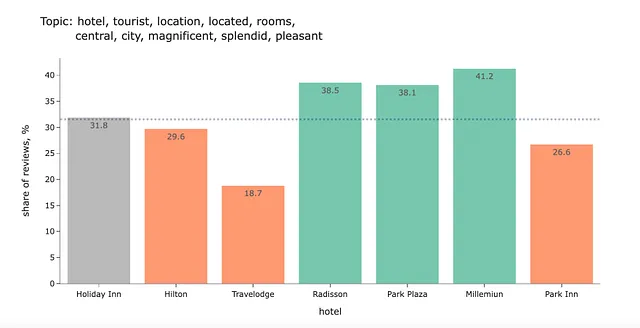
import plotly# define color depending on difference significancedef get_color_sign(rel): if rel == 'no diff': return plotly.colors.qualitative.Set2[7] if rel == 'lower': return plotly.colors.qualitative.Set2[1] if rel == 'higher': return plotly.colors.qualitative.Set2[0]# return topic representation in a suitable for graph title formatdef get_topic_representation_title(topic_model, topic): data = topic_model.get_topic(topic) data = list(map(lambda x: x[0], data)) return ', '.join(data[:5]) + ', <br> ' + ', '.join(data[5:])def get_graphs_for_topic(t): topic_stats_df = mult_topics_stats_df[mult_topics_stats_df.topic_id == t]\ .sort_values('total_hotel_reviews', ascending = False).set_index('hotel') colors = list(map( get_color_sign, topic_stats_df.diff_significance_total )) fig = px.bar(topic_stats_df.reset_index(), x = 'hotel', y = 'topic_hotel_share', title = 'トピック:%s' % get_topic_representation_title(topic_model, topic_stats_df.topic_id.min()), text_auto = '.1f', labels = {'topic_hotel_share': 'レビューのシェア、 %'}, hover_data=['topic_id']) fig.update_layout(showlegend = False) fig.update_traces(marker_color=colors, marker_line_color=colors, marker_line_width=1.5, opacity=0.9) topic_total_share = 100.*((topic_stats_df.topic_hotel_reviews + topic_stats_df.topic_other_hotels_reviews)\ /(topic_stats_df.total_hotel_reviews + topic_stats_df.other_hotels_reviews)).min() print(topic_total_share) fig.add_shape(type="line", xref="paper", x0=0, y0=topic_total_share, x1=1, y1=topic_total_share, line=dict( color=colormap[8], width=3, dash="dot" ) ) fig.show()その後、トップのトピックリストを計算し、それらに対してグラフを作成できます。
top_mult_topics_df = mult_topics_df.groupby('topic', as_index = False).id.nunique()top_mult_topics_df['share'] = 100.*top_mult_topics_df.id/top_mult_topics_df.id.sum()top_mult_topics_df['topic_repr'] = top_mult_topics_df.topic.map( lambda x: get_topic_representation(topic_model, x))for t in top_mult_topics_df.head(32).topic.values: get_graphs_for_topic(t)以下は、結果のチャートのいくつかの例です。このデータに基づいていくつかの結論を導きましょう。
Holiday Inn、Travelodge、Park Innは、HiltonやPark Plazaと比較して価格と価値が優れていることがわかります。
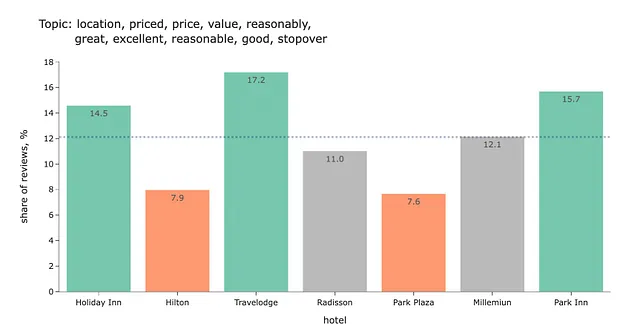
もう1つの洞察は、Travelodgeでは騒音が問題となる可能性があるということです。
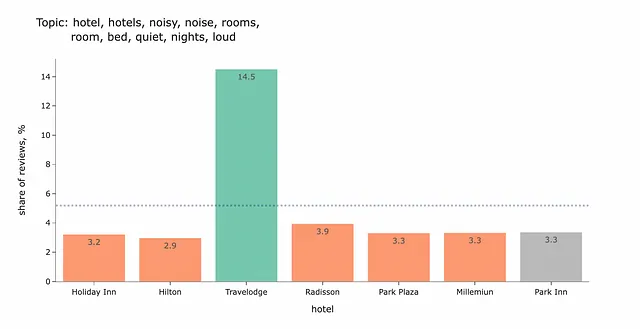
この結果を解釈するのは少し難しいです。このトピックが何についてのものかはわかりません。
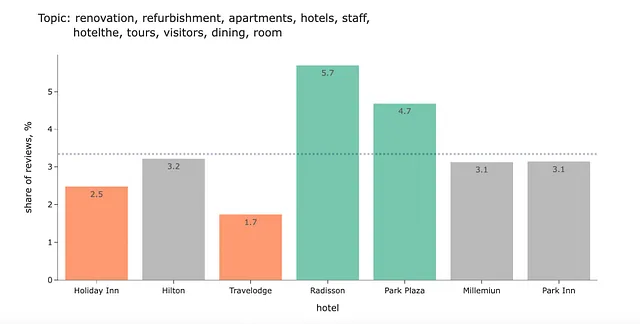
このような場合のベストプラクティスは、いくつかの例を見ることです。
- 私たちは東のタワーに滞在しましたが、エレベーターが改装中で、1つしか動作していませんが、サービス用のエレベーターの案内が表示されており、それも使用できます。
- ただし、カーペットと家具は改装される必要があります。
- これはクイーンズウェイ駅の上に建設されています。この駅は1年間の改装のために閉鎖されますので、騒音レベルを考慮する必要があります。
さて、このトピックは、ホテル滞在中の一時的な問題や家具の状態が最適でない場合の事例についてです。
GitHubで完全なコードを見つけることができます。
概要
今日、エンドツーエンドのトピックモデリング分析を行いました:
- BERTopicライブラリを使用して基本的なトピックモデルを構築しました。
- その後、外れ値を処理し、トピックが割り当てられていないレビューはわずか5.8%となりました。
- 自動的におよび手動でトピックの数を減らし、簡潔なリストを作成しました。
- ほとんどの場合、テキストには複数のトピックが含まれるため、各ドキュメントに複数のトピックを割り当てる方法を学びました。
最後に、異なるコースのレビューを比較し、魅力的なグラフを作成し、いくつかの洞察を得ることができました。
この記事を読んでいただき、ありがとうございます。あなたにとって有益な情報であったことを願っています。ご質問やコメントがある場合は、コメントセクションにお書きください。
データセット
Ganesan, Kavita and Zhai, ChengXiang. (2011). OpinRank Review Dataset. UCI Machine Learning Repository. https://doi.org/10.24432/C5QW4W
BERTopicをさらに掘り下げる場合
- Maarten Grootendorstによる記事「Interactive Topic Modelling with BERTopic」
- Maarten Grootendorstによる記事「Topic Modelling with BERT」
- Maarten Grootendorstによる論文「BERTopic: Neural topic modeling with a class-based TF-IDF procedure」
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
