BERTopicとHugging Face Hubの統合をご紹介します
'BERTopicとHugging Face Hubの統合を紹介します'
![]()
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。
トピックモデリングとは何ですか?
トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。
各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。
BERTopicとは何ですか?
BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。
BERTopicライブラリの概要
BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。
BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。
Hugging Face Hubを使用したBERTopicモデルの管理
最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。
BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます
from bertopic import BERTopic
topic_model = BERTopic("english")
topics, probs = topic_model.fit_transform(docs)
topic_model.push_to_hf_hub('davanstrien/transformers_issues_topics')その後、このモデルを2行でロードし、新しいデータに対して予測に使用することができます。
from bertopic import BERTopic
topic_model = BERTopic.load("davanstrien/transformers_issues_topics")Hugging Face Hubのパワーを活用することで、BERTopicのユーザーはトピックモデルを簡単に共有、バージョン管理、共同作業することができます。ハブは中央リポジトリとして機能し、ユーザーがモデルを格納し、整理することができるため、製品でのモデルの展開、同僚との共有、さらにはNLPコミュニティ全体にモデルを展示することが容易になります。
ハブでlibrariesフィルタを使用してBERTopicモデルを検索することができます。
BERTopicモデルに興味がある場合は、ハブの推論ウィジェットを使用してモデルを試し、自分のユースケースに適しているかどうかを確認できます。
トレーニング済みのトピックモデルがある場合は、1行でハブにプッシュすることができます。ハブにモデルをプッシュすると、トピックが作成されたモデルの概要を含む初期モデルカードが自動的に作成されます。以下は、ArXivデータでトレーニングされたモデルから得られたトピックの例です。
すべてのトピックの概要はこちらをクリックしてください。
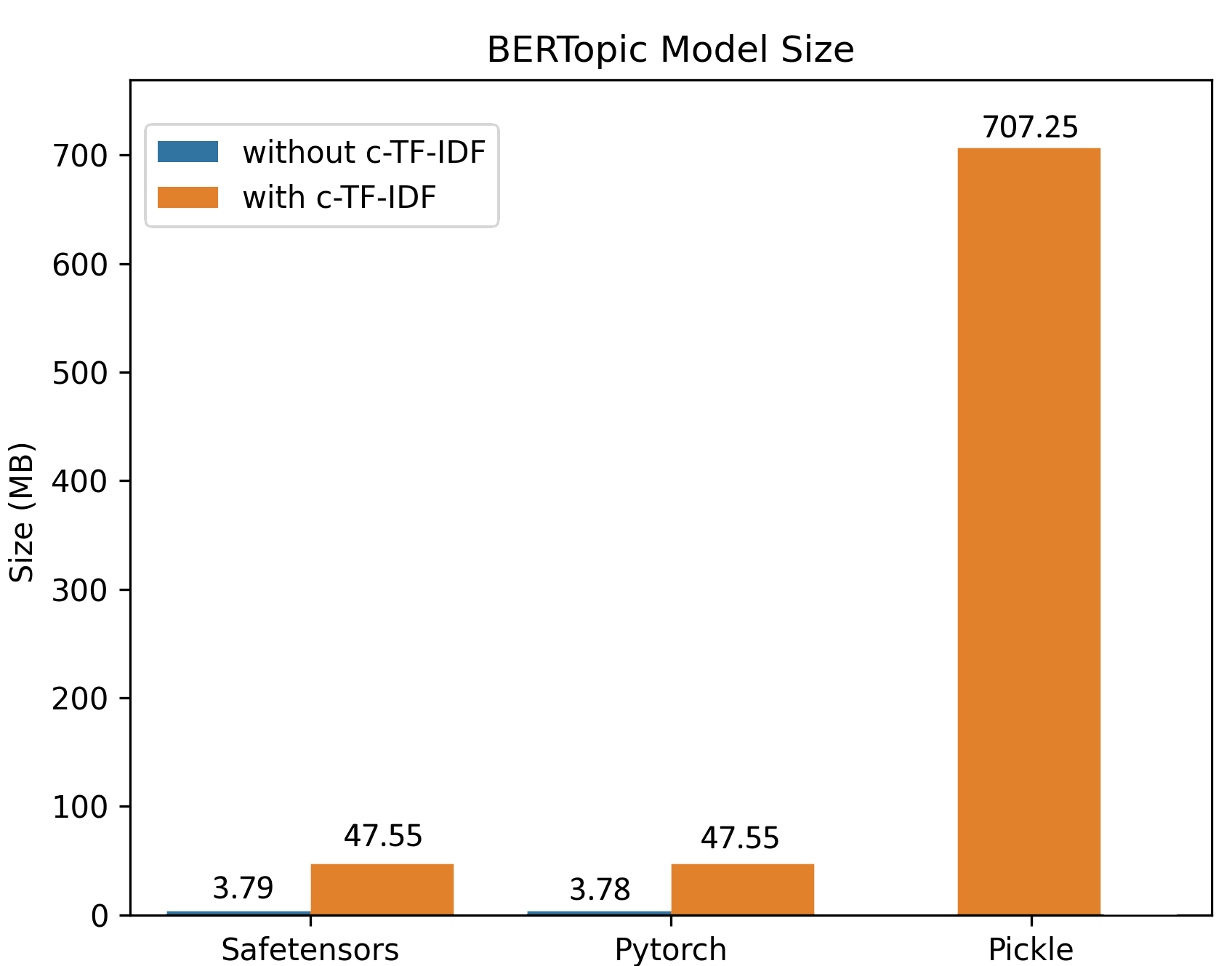
改善された保存手順により、大規模なデータセットでのトレーニングは小さなモデルサイズを生成します。以下の例では、10万のドキュメントでトレーニングされたBERTopicモデルが、元のモデルの機能をすべて保持しながら、約50MBのモデルを生成しました。推論では、モデルをさらに3MBに縮小することができます!
 この統合の利点は、特に本番環境で顕著です。ユーザーはBERTopicモデルを既存のアプリケーションやシステムに簡単に展開でき、データパイプライン内でのシームレスな統合を保証します。この効率化されたワークフローにより、より迅速な反復と効率的なモデルの更新が可能となり、異なる環境間での一貫性も確保されます。
この統合の利点は、特に本番環境で顕著です。ユーザーはBERTopicモデルを既存のアプリケーションやシステムに簡単に展開でき、データパイプライン内でのシームレスな統合を保証します。この効率化されたワークフローにより、より迅速な反復と効率的なモデルの更新が可能となり、異なる環境間での一貫性も確保されます。
safetensors:安全なモデル管理の確保
Hugging Face Hubの統合に加えて、BERTopicはsafetensorsライブラリを使用したシリアライズもサポートしています。Safetensorsは、テンソルを安全に格納するための新しいシンプルな形式であり(pickleの代わりに)、依然として高速(ゼロコピー)です。私たちは、このブログ投稿でライブラリの最近の監査について詳しく読むことができます。
BERTopicを使用してRLFHデータセットを探索する例
BERTopicのパワーを示すために、チャットモデルのトレーニングに使用されるデータセットのトピックの変化を監視する方法の例を見てみましょう。
昨年は、人間のフィードバックを用いた強化学習のためのいくつかのデータセットが公開されました。そのうちの1つがOpenAssistant Conversationsデータセットです。このデータセットは、世界中の13,500以上のボランティアを巻き込んだ大規模なクラウドソーシングの取り組みによって作成されました。このデータセットには既に毒性、品質、ユーモアなどのスコアがいくつかありますが、このデータセットにどのような種類の会話が含まれているのかをより深く理解したいと考えるかもしれません。
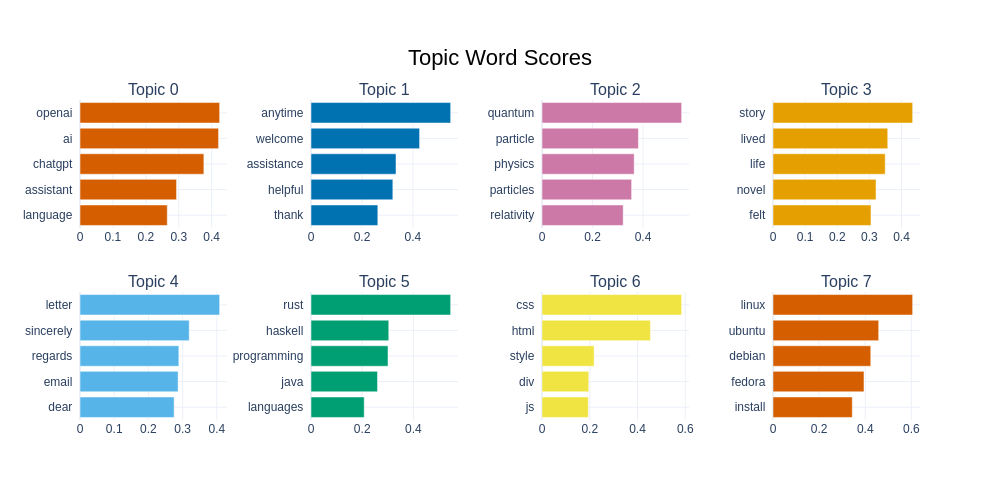
BERTopicは、このデータセットのトピックをより深く理解するための1つの方法を提供しています。この場合、データセットの英語のアシスタント応答部分でモデルをトレーニングします。結果として、75のトピックを持つトピックモデルが得られます。
BERTopicは、データセットを視覚化するさまざまな方法を提供しています。以下にトップ8のトピックとそれに関連する単語が表示されます。2番目に頻度が高いトピックは、主に「応答単語」で構成されており、チャットモデルから頻繁に見られるものです。つまり、「礼儀正しく」「助けになる」応答です。また、プログラミングやコンピューティングのトピック、物理学、レシピ、ペットに関連するトピックも多く見られます。
databricks/databricks-dolly-15kは、RLFHモデルのトレーニングに使用できる別のデータセットです。このデータセットの作成方法は、OpenAssistant Conversationsデータセットとは異なり、ボランティアを介したクラウドソーシングではなく、Databricksの従業員によって作成されました。おそらく、トレーニングされたBERTopicモデルを使用して、これら2つのデータセット間のトピックを比較することができるでしょう。
新しいBERTopic Hubの統合により、このトレーニング済みモデルをロードし、新しい例に適用することができます。
topic_model = BERTopic.load("davanstrien/chat_topics")単一の例文に対して予測することができます:
example = "Stalemate is a drawn position. It doesn't matter who has captured more pieces or is in a winning position"
topic, prob = topic_model.transform(example)予測されたトピックに関する詳細情報を取得することができます:
topic_model.get_topic_info(topic)ここで予測されたトピックは、意味があるように思われます。これをデータセット全体に対して比較するように拡張したいかもしれません。
from datasets import load_dataset
dataset = load_dataset("databricks/databricks-dolly-15k")
dolly_docs = dataset['train']['response']
dolly_topics, dolly_probs = topic_model.transform(dolly_docs)次に、両データセット間のトピックの分布を比較することができます。BERTopicモデルによれば、dollyデータセットのトピックはより広範な分布を示しています。これは、両データセットの作成方法の違いによるものかもしれません(この点を確認するために、両データセットを対象としてBERTopicを再トレーニングする必要があります)。
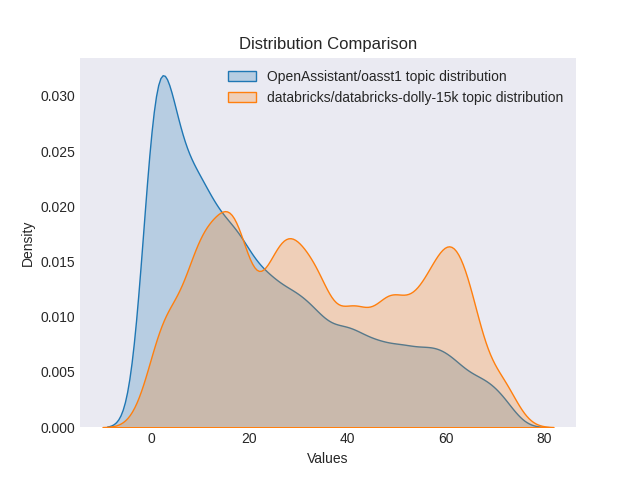
データセット間のトピックの分布の比較
トピックモデルを製品環境で使用して、トピックが予想される分布から大きく逸脱していないかを監視することができます。これは、元のトレーニングデータと製品で見られる会話の種類との間にドリフトがあったことを示すシグナルとなります。また、トピックモデリングを使用してトレーニングデータを収集する際に、特に関心のあるトピックの例を取得していることを確認するためにも使用できます。
BERTopicとHugging Face Hubの使い方
BERTopicの使用方法に関するクイックスタートガイドは公式ドキュメントをご覧ください。
こちらのスターターColabノートブックでは、BERTopicモデルのトレーニング方法とHubへのプッシュ方法を示しています。
Hubにすでに存在するBERTopicモデルのいくつかの例:
- MaartenGr/BERTopic_ArXiv:1991年以降の約30,000件のArXiv計算および言語記事(cs.CL)でトレーニングされたモデル。
- MaartenGr/BERTopic_Wikipedia:100万件の英語のWikipediaページでトレーニングされたモデル。
- davanstrien/imdb_bertopic:IMDBデータセットの非教師あり分割でトレーニングされたモデル
ライブラリのフィルターを使用して、Hub上のBERTopicモデルの完全な概要を見つけることができます
この新しい統合の可能性を探索し、ハブ上でトレーニングされたモデルを共有することをお勧めします!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





