Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
Benfordの法則を使用して、機械学習との組み合わせで偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタルランドスケープにおいて、ユーザーの信頼性は重要な懸念事項です。Twitterなどのプラットフォームが成長するにつれて、偽アカウントの増殖も増えています。これらのアカウントは真のユーザーの活動を模倣し、データにノイズを生じさせ、デジタルエコシステムの信頼性に影を落とします。
偽アカウントを検出するための従来の方法は、複雑な機械学習アルゴリズムに頼ることが多いです。しかし、興味深い代替ツールとして、ベンフォードの法則という数学的な原理が存在します。ベンフォードの法則は、多くの数値データセットの先頭桁の頻度分布を説明する数学的な原理です。この記事では、ベンフォードの法則の力を機械学習の技術と組み合わせて、偽のTwitterフォロワーを明らかにする方法について探求します。
ベンフォードの法則:概要
さて、さまざまなデータセットにおいて特定の数字が先頭桁としてどのように頻出するか、考えてみましょう。たとえば、お気に入りのオンラインマーケットプレイスの商品の価格データセットがあるとします。その価格の先頭桁で最も一般的な数字は何になるでしょうか?
直感的には、1から9までの各数字が先頭桁になる確率が等しいと思うかもしれません。なぜなら、分布は一様であるべきだからです。驚くべきことに、この仮定は誤りです。ベンフォードの法則によると、最も頻出する数字は1で、次に2、3と続き、9が最も少ない数字です。
- ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
- 将来のアプリケーションを支える大規模言語モデル(LLM)の力
- AIハイパーソナライゼーションとは何ですか?利点、事例、倫理的懸念
では、具体的にベンフォードの法則とは何でしょうか?
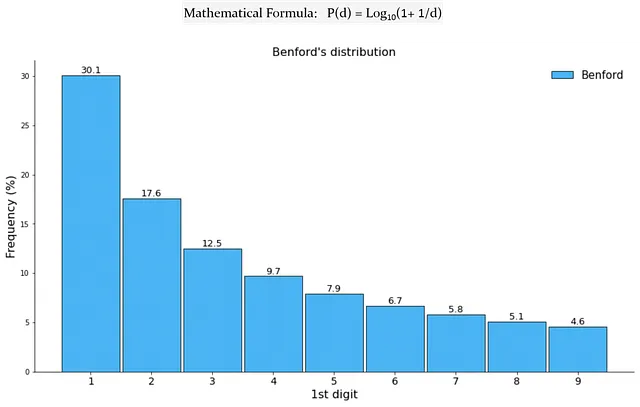
ベンフォードの法則は、異常な数字または第一桁の法則¹とも呼ばれます。これは、自然数の集合において第一桁dが出現する確率を提供します。この法則によると、第一桁の位置に1が現れる確率は30.1%であり、9になると4.6%になります。
次のような質問をします:“米国の各郡の人口データを含むデータがあるとします。ランダムな人口数の先頭桁が1から始まる確率は何%でしょうか?” これに対する答えは、約30%であることが分かります。
この興味深い現象は、私たちの従来の期待を覆し、広範な影響をもたらします。これは、製品価格や人口数だけでなく、財務諸表、株価、スポーツ統計、TikTokのいいね数、科学的測定など、さまざまなデータセットでも観察されています。ベンフォードの法則の理解と活用は、さまざまな領域での異常や異常値の検出能力を向上させ、ソーシャルメディア分析(偽のTwitterフォロワーの特定など)を含む貴重な洞察を得ることができます。
このブログでは、ベンフォードの法則と機械学習の魅力的な交差点について掘り下げ、この数学的原理を先進的なアルゴリズムと組み合わせて、偽のTwitterフォロワーの存在を明らかにし、対抗する方法を探求します。
データのソースと説明
この研究を行うために、公開されているTwitterアカウントデータの非合成ラベル付きデータセットを利用しました。
TwitterユーザーデータのソースはBot Repositoryのウェブサイト²で、Twitterユーザーアカウントデータのコレクションを保管しています。
このステップでは、少なくともベンフォードの法則に必要な主要な仮定のうちの1つを満たさないため、利用可能な公開データのほとんどがデータの制限の問題が発生しました。そのため、私が見つけた唯一の利用可能なデータセットは、cresci-2015データセットでした。
cresci-2015データセットには、元の著者によって手動で注釈付けされた、本物と偽物のTwitterアカウントのコレクションが含まれています³。
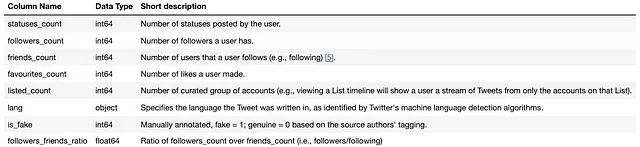
データセットをダウンロードした後、私は5301のアカウント(行)と8の特徴(列)を収集して利用しました。データセットには他の列も含まれていましたが、この研究に関連するのは以下の列のみです:
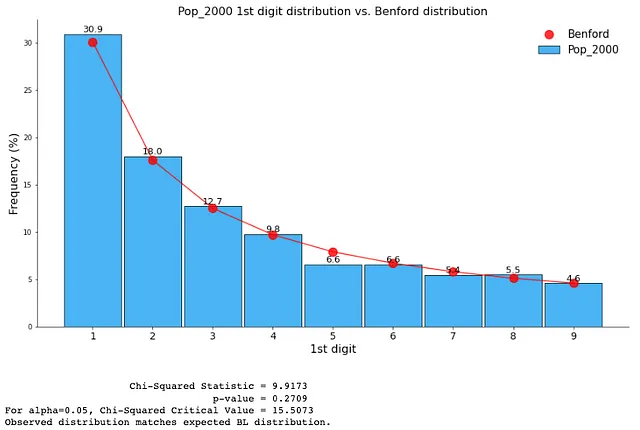
ベンフォードの法則のサンプルイラストのために使用される別のデータセットは、ベンフォードの法則の書籍の著者であるMark Nigriniのウェブサイト⁴からの14_Census_2000_2010.csvです。
主な仮定と例
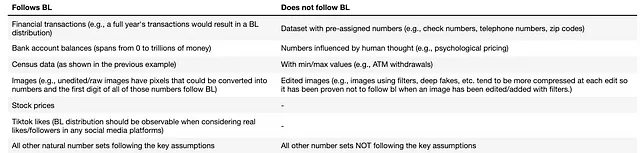
ベンフォードの法則の例と応用に入る前に、主な仮定を見直しましょう:
- 数字のセットは制限されていません。(先頭の数字は1から9まで可能です)
- 数字は複数の桁数で表されます(1-10、10-100、100-1000、少なくとも4桁の数字が最適です)
- サンプルサイズは非常に大きいです(可能な限り全体の集団を使用してください。1,000以下のサンプルサイズでは信頼性のある結果が得られません。)
ベンフォードの法則(BL)に従うまたは従わないいくつかの例のデータセットは以下の通りです⁶:
ベンフォードの法則の主な機械学習への応用
- 詐欺/異常検出
- 画像フォレンジック
- ボット/偽フォロワーの検出
特徴量エンジニアリング
機械学習モデルに取り組む前に、まず、偽フォロワーアカウントのソーシャルコネクションが不自然であるため、followers/friendsの比率の特徴量を作成しました。偽フォロワーの主な特徴の1つは、他の偽フォロワーアカウントをフォローしようとすることですが、平均的には、彼らがフォローするアカウントの数(正味の友達)は、彼らのフォロワーの数(正味のフォロワー)よりもはるかに多いです。
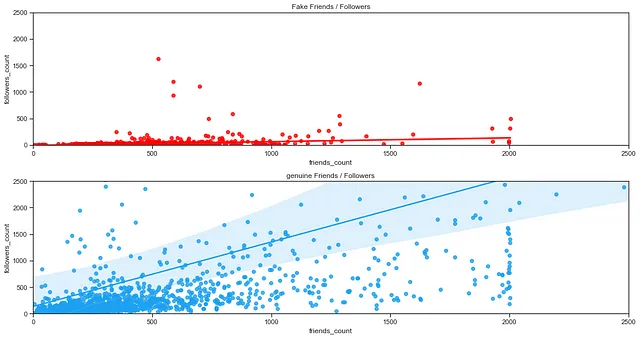
上記の画像からも分かるように、偽アカウントのフォロワー数は通常、友達の数よりも低いです(友達とは、アカウントがフォローしているユーザーの数を指します⁵)。偽フォロワーがより多くのアカウントをフォローするのは理解しやすいですが、それは彼らの主な目的です。これらの偽フォロワーアカウントは相互作用のために設計されていないため、通常、フォロワー数は低くなります。
ベンフォードの法則との一致確認
上記の議論とグラフに基づくと、ボットや偽フォロワーによって行われるソーシャルコネクションは不自然であり、そのため、ベンフォードの法則に違反する傾向があります。
Twitterのデータセットの各サブセットにおける不正や偽フォロワーの指標をチェックするために、私は仮説検定を行いました:
- 帰無仮説:データのサブセットはベンフォードの法則の分布に従います。
- 対立仮説:データのサブセットはベンフォードの法則の分布に従いません。
私は観測されたデータにどれだけ提案されたモデルが適合するかを判断するために、α=0.05のカイ二乗検定を使用しました。
上記のテストを各データサブセット(本物のみ、偽のみ、および結合されたデータフレーム)に適用した結果は次のとおりです:
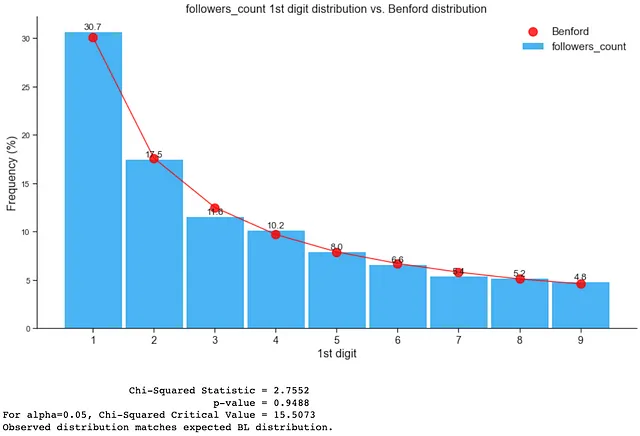
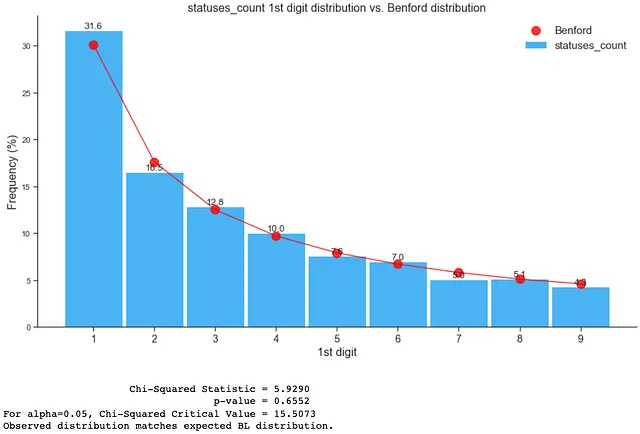
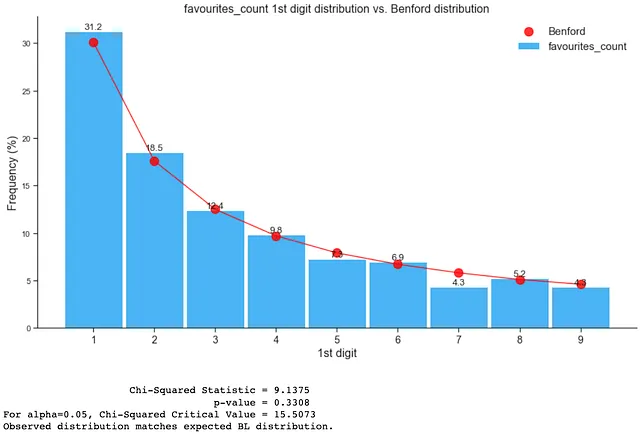
1. 本物のアカウントにおけるベンフォードの法則
このブログのキーアサンプションと例のセクションで考慮されるキーアサンプションに従えば、以下の特徴のみを使用してベンフォードの法則の適合性をチェックできます:
- followers_count
- statuses_count
- favourites_count
以下のように、本物のアカウントはベンフォードの分布に従います:
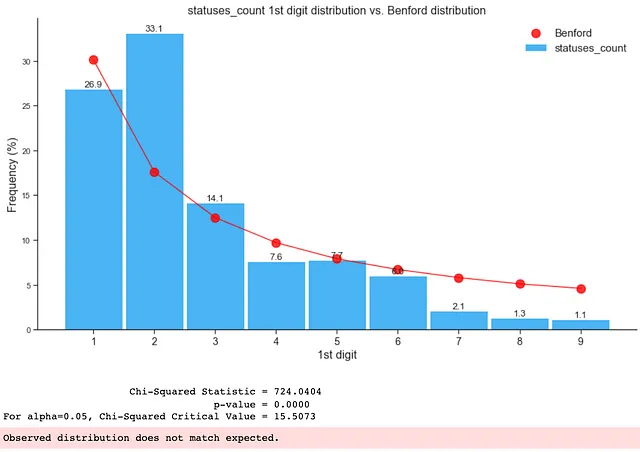
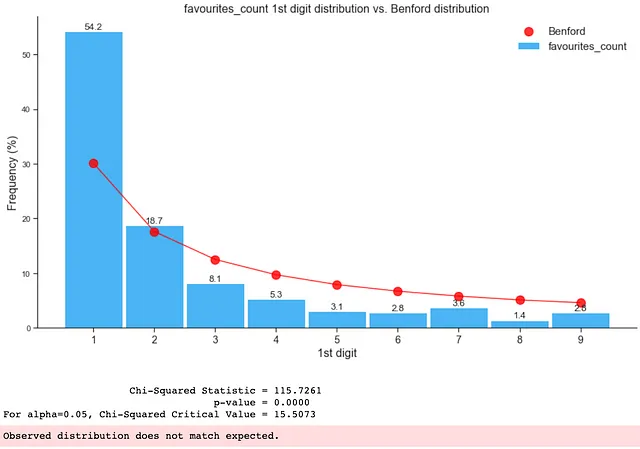
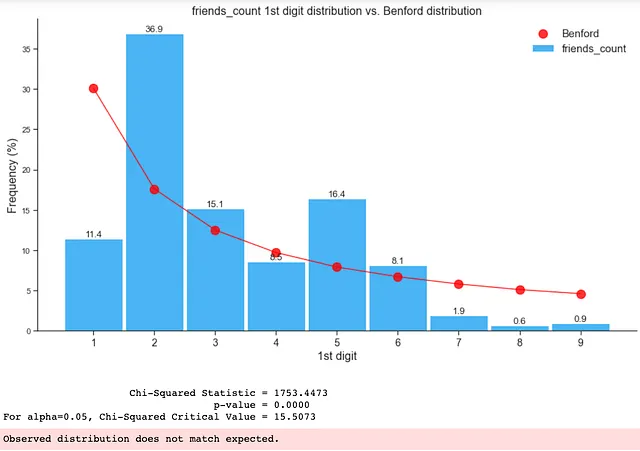
2. フェイクフォロワーアカウントにおけるベンフォードの法則
このブログのキーアサンプションと例のセクションで考慮されるキーアサンプションに従えば、以下の特徴のみを使用してベンフォードの法則の適合性をチェックできます:
- followers_count
- statuses_count
- favourites_count
- friends_count
以下のように、フェイクデータの分布はベンフォードの法則に適合していません:

3. 全データセット(本物とフェイクの組み合わせ)におけるベンフォードの法則
このブログのキーアサンプションと例のセクションで考慮されるキーアサンプションに従えば、以下の特徴のみを使用してベンフォードの法則の適合性をチェックできます:
- followers_count
- statuses_count
- favourites_count
- friends_count
以下のように、データフレーム全体に偽のフォロワーが存在するため、ベンフォード分布に準拠していませんでした:
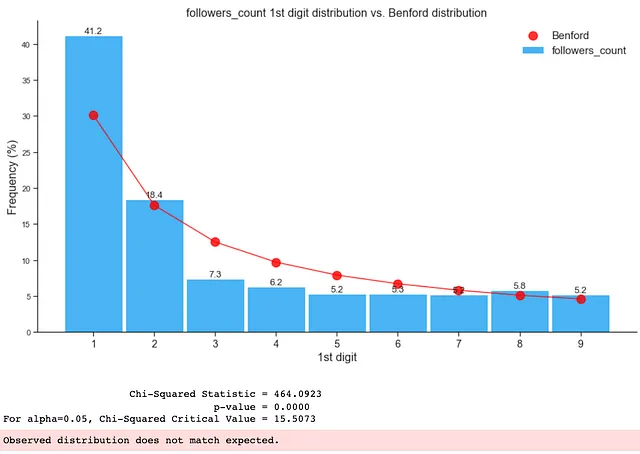
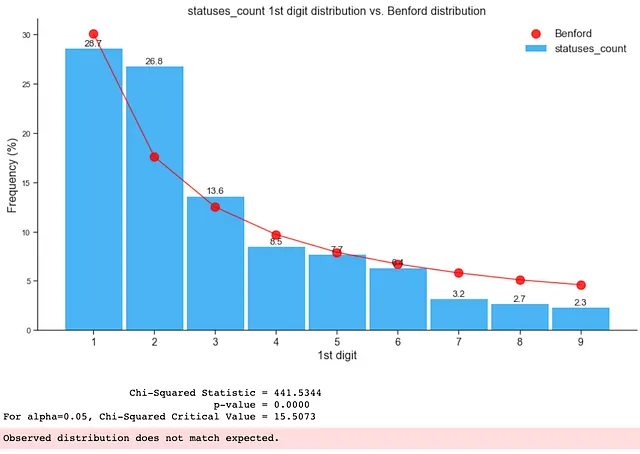
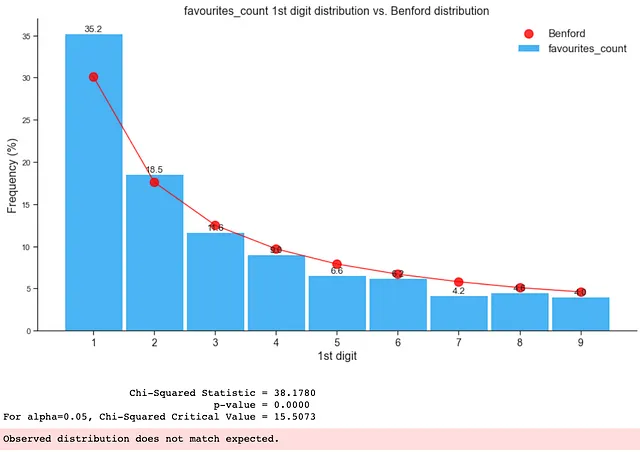
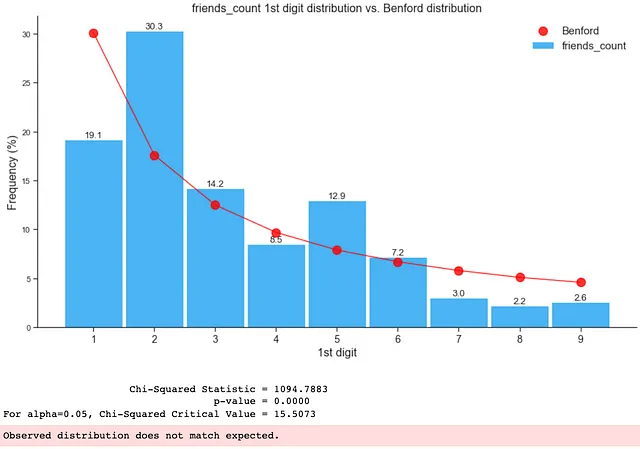
上記のように、データセットまたはデータサブセットの1桁目の分布をチェックすることで、データセット内の異常や偽のフォロワー、さらにはボットの存在をすぐに確認することができます。このような洞察を活用して、研究の目的がデータセットに報告された不正や偽のフォロワーなどの異常や操作、非自然な数字の存在を特定する場合には、どのグループのデータセットまたはサブセットを優先してチェックするかを知ることができます(この研究では詐欺や偽のフォロワー)。
機械学習モデル
このセクションでは、Twitterのデータセット内の偽のフォロワーの存在を特定するための機械学習モデルを探索します。焦点は、これらの偽アカウントのソーシャルコネクション、特にフォロワー対友達の比率が異常であるかどうかを確認することです。
この分類タスクを実行するために、勾配ブースティング、ランダムフォレスト、k最近傍法(kNN)などの機械学習モデルのスイートを使用しました。自動機械学習分類器で特定された主要な予測変数を使用して、偽のTwitterフォロワーを検出するための結果をベンフォードの法則の結果と比較しました。
ベースライン:比例チャンス基準(PCC)は53%であり、正確性を67%(1.25 x PCC)上回る必要があります。
自動機械学習(Auto-ML):作成した自動機械学習関数を実行し、偽のTwitterフォロワーを検出するためのトップ予測変数を取得し、その結果をBLの結果と比較します:
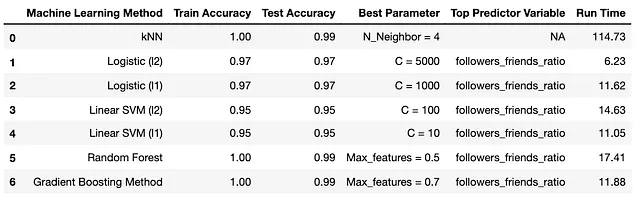
観察
予想どおり、分析の結果、フォロワー/友達比率が常に最も重要な予測変数として浮かび上がり、ベンフォードの法則の結果と一致しました。これは、ユーザーのフォロワーと友達の比率がアカウントの真正性を判断するための重要な要素であるという初期の仮説を支持しています。さらに、自然発生のデータセットである本物のフォロワーはベンフォードの法則に従っていました。この法則を適用することで、偽のフォロワーがいるデータセットではベンフォードの法則から逸脱していることが特定できました。
結論
この研究では、ベンフォードの法則とその機械学習への適用をcresci-2015データセットを使用して紹介しました。ベンフォードの法則の適用に必要な前提条件を満たす非合成のデータセットを見つけることが主な課題でした。フォロワーカウント、友達カウントなどの特徴は、偽と真のアカウントの間の識別要素として特定されました。これらの特性を用いてベンフォードの法則と機械学習モデルを適用し、ユーザーを分類しました。モデルは偽のフォロワーの識別において高い検出精度(99%以上)を示しました。
偽フォロワーは本物の活動を模倣しようとしますが、その不自然な行動はベンフォードの法則に違反します。彼らの先頭桁の分布にわずかな変動があるだけで、データ全体がベンフォードの法則の分布から逸脱する可能性があります。
ベンフォードの法則を適用することで、データセットに偽フォロワーの存在を検出しました。すべての本物のアカウントはベンフォードの法則に従っていましたが、偽フォロワーが含まれるデータセット(偽のデータフレームや結合/全体のデータフレームなど)は従いませんでした。
さらに、自動機械学習(auto-ML)はベンフォードの法則の結果と一致する結果を提供しました。フォロワー数と友達数の比率は、使用されたすべての機械学習モデルで一貫して上位の予測変数でした。これにより、ユーザーのフォロワーと友達(フォロー)の比率がアカウントが本物か偽物かを判断する上で重要な要素であるという初期の仮定が確認されました。
自然発生するデータセットはベンフォードの法則に従います。ベンフォードの法則の単純な可視化は、異常を検出するためのパイプラインの一部として使用することも、データセットのエラーや不正、操作的なバイアス、処理効率の問題を特定するための探索的データ分析の一部として使用することもできます。さらに、ベンフォードの法則は、偽フォロワーの存在の初期指標としても単独で適用できるため、おおまかながら貴重な予備の識別ツールとなります。最後に、大規模なデータセットでは、機械学習モデリングプロセスの開始前にサブセットで逸脱を検出するための高度に焦点を絞ったテストの実施にベンフォードの法則を活用することができます。
今後の研究のための推奨事項
この研究は、ベンフォードの法則がデータセットの不正や操作の兆候について簡単で即時の洞察を提供する方法を紹介するために主に実施されたものであり、今後の研究で実装できる改善点がたくさんあります。分析と結論から得られた洞察に基づいて、次の項目が今後の研究に強く推奨されます:
- より大きなデータセットの使用:ベンフォードの法則をMLパイプラインの補完または一部として、または単にEDAの一部として使用する場合、データセットのサイズが大きいほどベンフォードの法則の結果はより正確になる傾向があるため、より大きなデータセットを使用することが最適です。
- リアルタイムの偽フォロワー検出:このブログで議論された結果を考慮すると、ユーザーが使用しているアプリ内の偽フォロワーやボットの存在を即座に検出するために、ベンフォードの法則と機械学習の偽フォロワー検出をリアルタイムでウェブやアプリのアドインとして利用することは非常に有益です。
- より強力なモデルのための他の非数値特徴の考慮:自然言語処理や情報検索などのモデルを使用して、ユーザーが行った実際のツイートなどの非数値特徴を処理してベンフォードの法則と前述のML手順と組み合わせることで、データセットの適合率と再現率を強化することができます。
偽フォロワーを検出するためのMLモデルの改善に関連するベンフォードの法則のさらなる探索と研究は、Twitterや他のソーシャルメディアアプリケーションをすべての本物のユーザーにとってより安全な環境にするのに役立ちます。
ソースコード
このプロジェクトのより詳細な分析とコードを探索したい場合は、このリンクをクリックして私のGitHubリポジトリを訪問してください。ありがとうございました!
参考文献
[1] Benford, F. (1938). The Law of Anomalous Numbers. Proceedings of the American Philosophical Society, 78(4), 551–572. https://www.jstor.org/stable/984802
[2] Bot Repository developers. (2022, November). Bot Repository Website. https://botometer.osome.iu.edu/bot-repository/datasets.html .
[3] Cresci, S., Di Pietro, R., Petrocchi, M., Spognardi, A., & Tesconi, M. (2015). Fame for sale: efficient detection of fake Twitter followers. arXiv:1509.04098 09/2015. Elsevier Decision Support Systems, Volume 80, December 2015, Pages 56–71.
[4] Nigrini, M. (Wiley, 2012). Benford’s Law. https://nigrini.com/benfords-law/
[5] Twitter Developers. (2022, November). Follow, search, and get users. https://developer.twitter.com/en/docs/twitter-api/v1/accounts-and-users/follow-search-get-users/overview
[6] National Association of State Auditors, Comptrollers and Treasurers. (2017). Fraud Analysis and Detection: Using Benfords Law and Other Effective Techniques. https://www.youtube.com/watch?v=9tpGVq5DcTw&t=4961s
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






