予測の作成:Pythonにおける線形回帰の初心者ガイド
Beginner's Guide to Linear Regression in Python for Prediction

線形回帰は、データサイエンスのキャリアをスタートする際にデータサイエンティストが最初に学ぶ最も人気のある機械学習アルゴリズムです。 それは、他のすべての高度な機械学習アルゴリズムの構築ブロックを設定するため、最も重要な教師あり学習アルゴリズムです。 それがなぜ、このアルゴリズムを非常に明確に学び理解する必要があるのです。
この記事では、線形回帰について、数学的および幾何学的直感、およびPythonの実装を基礎からカバーします。 唯一の前提条件は、学ぶ意欲とPython構文の基本的な知識です。 さあ始めましょう。
線形回帰とは何ですか?
線形回帰は、回帰問題を解決するために使用される教師あり機械学習アルゴリズムです。 回帰モデルは、他の要因に基づいて連続的な出力を予測するために使用されます。 たとえば、利益率、総時価総額、年間成長率などを考慮して、組織の来月の株価を予測する。 線形回帰は、天気、株価、販売目標などの予測にも使用できます。
- PyTorchを使った転移学習の実践ガイド
- ChatGPTのバイアスを解消するバックパック:バックパック言語モデルはトランスフォーマーの代替AI手法です
- DeepMindのAIマスターゲーマー:2時間で26のゲームを学習
名前が示すように、線形回帰は2つの変数の間に線形関係を開発します。 アルゴリズムは、独立変数(x)に基づいて従属変数(y)を予測できる最適な直線(y = mx + c)を見つけます。 予測変数は従属またはターゲット変数と呼ばれ、予測に使用される変数は独立変数または特徴と呼ばれます。 独立変数が1つだけ使用される場合、単変量線形回帰と呼ばれます。 それ以外の場合、多変量線形回帰と呼ばれます。
この記事を簡単にするために、2D平面上で簡単に視覚化できるように、独立変数(x)を1つしか取らないことにします。 次のセクションでは、その数学的直感について説明します。
数学的直感
さて、線形回帰の幾何学と数学を理解します。 XとYの値のサンプルペアのセットがあると仮定します。
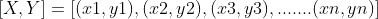
これらの値を使用して、学習関数を学び、未知の(x)を与えると、学習に基づいて(y)を予測できるようにする必要があります。 回帰では、予測に多くの関数が使用される場合がありますが、線形関数はそれらの中で最も単純です。
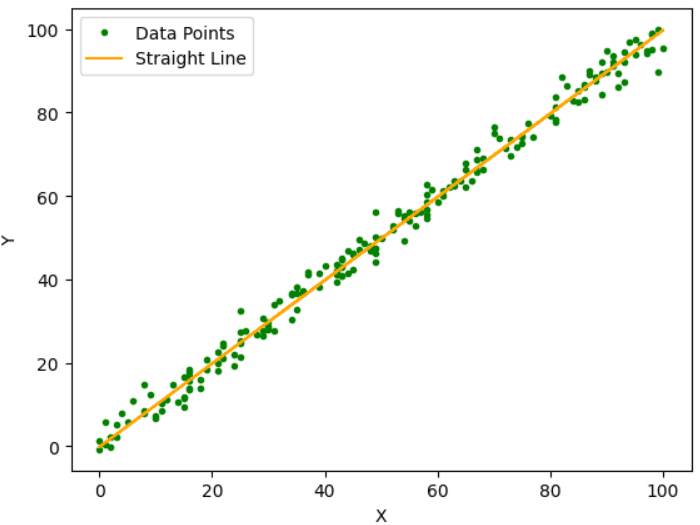
このアルゴリズムの主な目的は、上図に示されるように、これらのデータポイントの中で最小の残差誤差を与える最適な適合直線を見つけることです。 残差誤差は、予測値と実際値の差です。
線形回帰の仮定
前進する前に、正確な予測を得るために注意する必要がある線形回帰のいくつかの仮定を説明する必要があります。
- 線形性:線形性は、独立変数と従属変数が線形関係に従う必要があることを意味します。 そうでない場合、直線を取得することは困難になります。 また、データポイントは互いに独立している必要があります。つまり、1つの観測値のデータが他の観測値のデータに依存しないことを意味します。
- 等分散性:残差誤差の分散は一定でなければなりません。 つまり、誤差項の分散は一定であり、独立変数の値が変化しても変化しない必要があります。 また、モデルのエラーは正規分布に従う必要があります。
- 多重共線性のないこと:多重共線性は、独立変数間に相関があることを意味します。 したがって、線形回帰では、独立変数は互いに相関していてはなりません。
仮説関数
依存変数(Y)と独立変数(X)の間に線形関係が存在するという仮説を立てます。 線形関係は次のように表すことができます。

直線がパラメータΘ0とΘ1に依存することがわかります。 最適な適合直線を取得するために、これらのパラメータを調整する必要があります。 これらはモデルの重みとも呼ばれます。 そして、これらの値を計算するために、損失関数、またはコスト関数を使用します。 それは予測値と実際値の間の平均二乗誤差を計算します。 私たちの目標は、このコスト関数を最小化することです。 コスト関数が最小化されるΘ0とΘ1の値が最適な適合直線を形成します。 コスト関数は(J)で表されます。
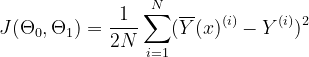
ここで、
Nはサンプルの総数です
負の値(つまり、予測値が実際の値よりも低い場合)を処理するために、二乗誤差関数が選択されます。また、関数は微分プロセスを簡略化するために2で割られています。
オプティマイザー(勾配降下法)
オプティマイザーは、最適な適合直線を実現するために、重みや学習率などのモデルの属性を反復的に更新するアルゴリズムです。線形回帰では、勾配降下法アルゴリズムを使用して、Θ0とΘ1の値を更新することにより、コスト関数を最小化します。
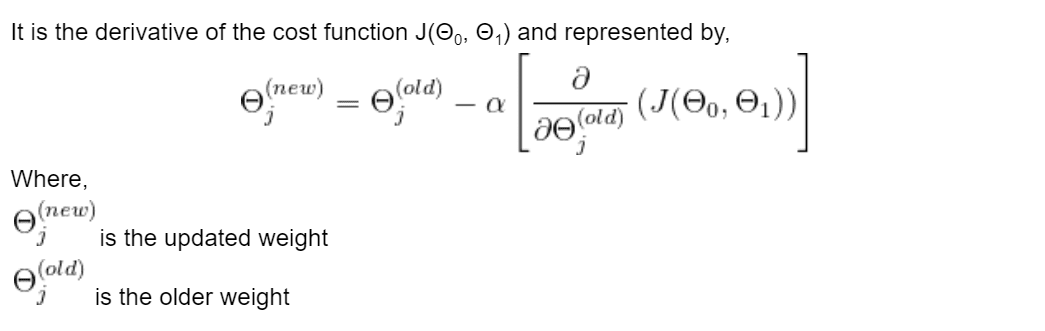
は、学習率と呼ばれるハイパーパラメーターです。これにより、重みが勾配損失に対してどの程度調整されるかが決定されます。学習率の値は最適である必要があり、高すぎるとモデルがグローバル最小値に収束するのが難しくなり、小さすぎると収束に時間がかかります。
コスト関数と重みの間にグラフをプロットして、最適なΘ0とΘ1を見つけます。
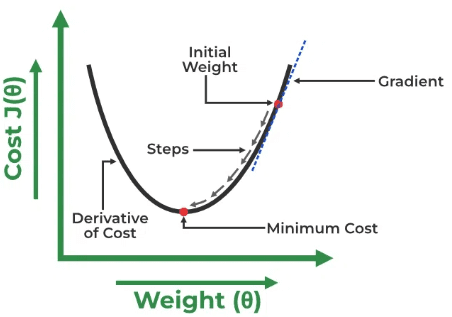
最初に、Θ0とΘ1にランダムな値を割り当て、コスト関数と勾配を計算します。負の勾配(コスト関数の導関数)の場合、Θ1を増加させる方向に移動して最小値に到達する必要があります。正の勾配の場合、グローバル最小値に到達するために後退する必要があります。勾配がほぼゼロに等しいポイントを見つけることを目指します。この点で、コスト関数の値が最小になります。
今までに、線形回帰の動作と数学について理解しました。次のセクションでは、Pythonを使用してサンプルデータセット上でそれをスクラッチから実装する方法を説明します。
線形回帰Python実装
このセクションでは、Numpy、Pandas、Matplotlibなどの基本的なライブラリのみを使用して、線形回帰アルゴリズムをスクラッチから実装する方法を学びます。1つの独立変数と1つの従属変数しか含まない単変量線形回帰を実装します。
使用するデータセットには、約700の(X、Y)のペアが含まれており、Xは独立変数であり、Yは従属変数です。Ashish Jangraがこのデータセットを提供しており、ここからダウンロードできます。
ライブラリのインポート
# 必要なライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.axes as ax
from IPython.display import clear_outputPandasはCSVファイルを読み取り、データフレームを取得します。Numpyは基本的な数学および統計操作を実行します。Matplotlibはグラフや曲線をプロットする責任があります。
データセットの読み込み
# データセットリンク:
# https://github.com/AshishJangra27/Machine-Learning-with-Python-GFG/tree/main/Linear%20Regression
df = pd.read_csv("lr_dataset.csv")
df.head()
# null値の削除
df = df.dropna()
# 訓練データとテストデータの分割
N = len(df)
x_train, y_train = np.array(df.X[0:500]).reshape(500, 1), np.array(df.Y[0:500]).reshape(
500, 1
)
x_test, y_test = np.array(df.X[500:N]).reshape(N - 500, 1), np.array(
df.Y[500:N]
).reshape(N - 500, 1)まず、データフレームdfを取得し、null値を削除します。その後、データをトレーニングとテストx_train、y_train、x_test、y_testに分割します。
モデルの構築
class LinearRegression:
def __init__(self):
self.Q0 = np.random.uniform(0, 1) * -1 # 切片
self.Q1 = np.random.uniform(0, 1) * -1 # Xの係数
self.losses = [] # 各イテレーションの損失を格納する
def forward_propogation(self, training_input):
predicted_values = np.multiply(self.Q1, training_input) + self.Q0 # y = mx + c
return predicted_values
def cost(self, predictions, training_output):
return np.mean((predictions - training_output) ** 2) # 損失の計算
def finding_derivatives(self, cost, predictions, training_input, training_output):
diff = predictions - training_output
dQ0 = np.mean(diff) # d(J(Q0, Q1))/d(Q0)
dQ1 = np.mean(np.multiply(diff, training_input)) # d(J(Q0, Q1))/d(Q1)
return dQ0, dQ1
def train(self, x_train, y_train, lr, itrs):
for i in range(itrs):
# 予測値の計算(線形方程式y=mx+cを使用)
predicted_values = self.forward_propogation(x_train)
# 損失の計算
loss = self.cost(predicted_values, y_train)
self.losses.append(loss)
# 逆伝搬(重みの導関数の求め方)
dQ0, dQ1 = self.finding_derivatives(
loss, predicted_values, x_train, y_train
)
# 重みの更新
self.Q0 = self.Q0 - lr * (dQ0)
self.Q1 = self.Q1 - lr * (dQ1)
# 直線のプロットを動的に更新する
line = self.Q0 + x_train * self.Q1
clear_output(wait=True)
plt.plot(x_train, y_train, "+", label="実際の値")
plt.plot(x_train, line, label="線形方程式")
plt.xlabel("Train-X")
plt.ylabel("Train-Y")
plt.legend()
plt.show()
return (
self.Q0,
self.Q1,
self.losses,
) # 最終的なモデルの重みと損失を返すLinearRegression()という名前のクラスを作成し、必要なすべての関数が組み込まれています。
__init__ : これはコンストラクタであり、このクラスのオブジェクトが作成されるときに重みをランダムな値で初期化します。
forward_propogation() : この関数は、直線の方程式を使用して予測出力を見つけます。
cost() : これは、予測された値に関連する残差エラーを計算します。
finding_derivatives() : この関数は、重みの導関数を計算し、後で最小のエラーのために重みを更新するために使用できます。
train() : この関数は、トレーニングデータ、学習率、および総イテレーション数から入力を受け取ります。指定されたイテレーション数までバックプロパゲーションを使用して重みを更新します。最後に、最適な適合直線の重みを返します。
モデルのトレーニング
lr = 0.0001 # 学習率
itrs = 30 # イテレーション回数
model = LinearRegression()
Q0、Q1、losses = model.train(x_train、y_train、lr、itrs)
# 出力 イテレーション数vs損失
for itr in range(len(losses)):
print(f"Iteration = {itr+1}, Loss = {losses[itr]}")出力:
Iteration = 1, Loss = 6547.547538061649
Iteration = 2, Loss = 3016.791083711492
Iteration = 3, Loss = 1392.3048668536044
Iteration = 4, Loss = 644.8855797373262
Iteration = 5, Loss = 301.0011032250385
Iteration = 6, Loss = 142.78129818453215
.
.
.
.
Iteration = 27, Loss = 7.949420840198964
Iteration = 28, Loss = 7.949411555664398
Iteration = 29, Loss = 7.949405538972356
Iteration = 30, Loss = 7.9494010258889491回目のイテレーションでは、損失が最大であり、後続のイテレーションではこの損失が減少し、30回目のイテレーションで最小値に達します。
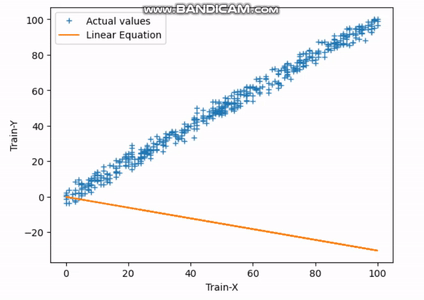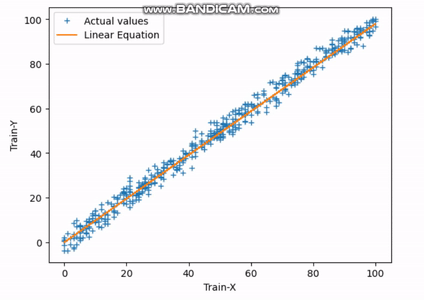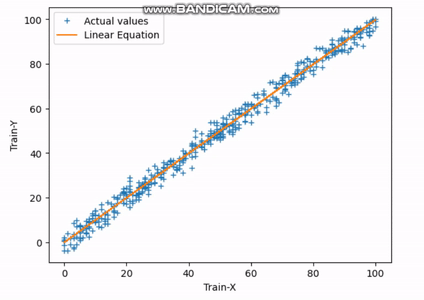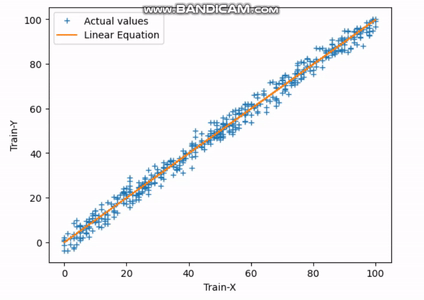 図3 最適フィット直線の検索 | Image by Author
図3 最適フィット直線の検索 | Image by Author
上記のGIFは、30回のイテレーションを完了した後、直線が最適な適合直線に達する様子を示しています。
最終予測
# テストデータに対する予測
y_pred = Q0 + x_test * Q1
print(f"Best-fit Line: (Y = {Q1}*X + {Q0})")
# 回帰線と実際のデータ点のプロット
plt.plot(x_test, y_test, "+", label="Data Points")
plt.plot(x_test, y_pred, label="Predited Values")
plt.xlabel("X-Test")
plt.ylabel("Y-Test")
plt.legend()
plt.show()これが最適な適合直線の最終式です。
Best-fit Line: (Y = 1.0068007107347927*X + -0.653638673779529)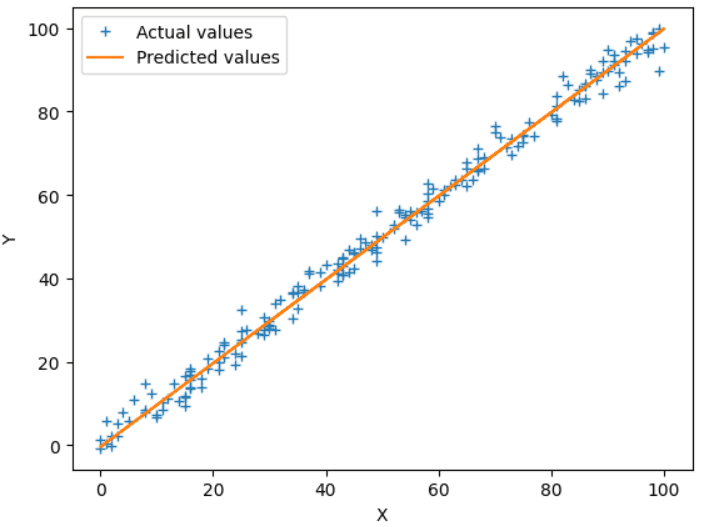 図4 実際の出力 vs 予測出力 | Image by Author
図4 実際の出力 vs 予測出力 | Image by Author
上記のプロットは、テストセットの最適な適合直線(オレンジ)と実際の値(青い+)を示しています。精度と正確性を高めるために、学習率やイテレーション数などのハイパーパラメータを調整することもできます。
線形回帰(Sklearnライブラリを使用)
前のセクションでは、一元線形回帰をスクラッチから実装する方法を見てきました。しかし、線形回帰を直接実装するために使用できるsklearnという組み込みライブラリもあります。簡単に説明しましょう。
同じデータセットを使用しますが、別のデータセットを使用することもできます。次のように2つの追加ライブラリをインポートする必要があります。
# 追加ライブラリのインポート
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_splitデータセットの読み込み
df = pd.read_csv("lr_dataset.csv")
# null値を削除
df = df.dropna()
# 訓練データとテストデータに分割
Y = df.Y
X = df.drop("Y", axis=1)
x_train, x_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=42
)以前はnumpyライブラリを使用して手動で訓練-テスト分割を実行する必要がありましたが、sklearnのtrain_test_split()を使用すると、テストサイズを指定するだけでデータを直接訓練セットとテストセットに分割できるようになりました。
モデルの訓練と予測
model = LinearRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
# 実際のデータポイントと回帰直線をプロット
plt.plot(x_test, y_test, "+", label="実際の値")
plt.plot(x_test, y_pred, label="予測値")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
plt.show()今では、順伝播、逆伝播、コスト関数などのコードを書く必要はありません。 LinearRegression()クラスを直接使用して、入力データに対してモデルを訓練できます。以下は、訓練されたモデルからテストデータで得られたプロットです。 結果は、独自にアルゴリズムを実装した場合と同様です。
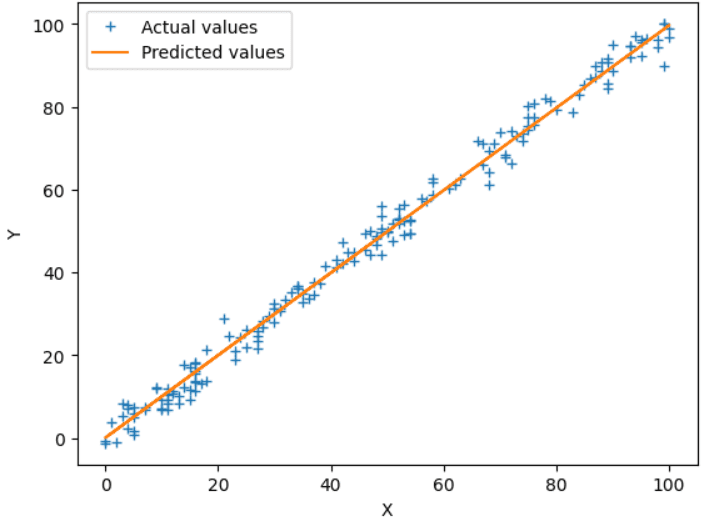 図5 Sklearnモデル出力|作者による画像
図5 Sklearnモデル出力|作者による画像
参考文献
- GeeksForGeeks: ML Linear Regression
まとめ
完全なコードのGoogle Colabリンク – 線形回帰チュートリアルコード
この記事では、線形回帰とは何か、その数学的直感と、スクラッチからの実装とsklearnライブラリの使用を詳しく説明しました。このアルゴリズムは直感的でわかりやすいため、初心者が堅牢な基盤を築くのに役立ち、Pythonを使用して正確な予測を行うための実用的なコーディングスキルを習得するのにも役立ちます。
お読みいただきありがとうございます。 Aryan Gargは、現在、電気工学のB.Tech。学生であり、学部の最終年度です。彼の興味はWeb開発と機械学習の分野にあります。 彼はこの興味を追求し、より多くの方向での作業に熱心に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 単一モダリティとの友情は終わりました – 今やマルチモダリティが私の親友です:CoDiは、合成可能な拡散による任意から任意への生成を実現できるAIモデルです
- AWSが開発した目的に特化したアクセラレータを使用することで、機械学習ワークロードのエネルギー消費を最大90%削減できます
- Sealとは、大規模な3Dポイントクラウドに対して自己教示学習のための2Dビジョンファウンデーションモデルを活用し、「任意のポイントクラウドシーケンスをセグメント化する」AIフレームワークです
- NVIDIA CEO:クリエイターは生成的AIによって「スーパーチャージ」されるでしょう
- 量産自動運転におけるBEVパーセプション
- PyTorchモデルのパフォーマンス分析と最適化—Part2
- あなたのLLMアプリケーションは公開に準備ができていますか?




