「医療AIの基礎モデル」
Basic model for medical AI
PLIPを紹介します – 病理学のための基礎モデル

はじめに
進行中のAI革命は、あらゆる方向で革新をもたらしています。OpenAI GPT(s)モデルは、開発をリードし、基礎モデルが実際に私たちの日常のタスクを容易にすることができることを示しています。私たちの仕事をサポートし、タスクを合理化するAI製品は、次の数年間で最も重要なツールの1つになるでしょう。
私たちの前には多くの機会が広がっています。仕事の中で私たちを助けることができるAI製品は、最も重要なツールの1つになるでしょう。
最もインパクトのある変化はどこで起こるのでしょうか?人々がタスクをより早く達成できるようにサポートできるのはどこでしょうか?AIモデルにとって最もエキサイティングな道の一つは、医療AIツールです。
このブログ投稿では、病理学のための最初の基礎モデルであるPLIP(Pathology Language and Image Pre-Training)について説明します。PLIPは、画像とテキストを同じベクトル空間に埋め込むことができるビジョン言語モデルであり、マルチモーダルなアプリケーションを可能にします。PLIPは、OpenAIが2021年に提案した元のCLIPモデルに基づいており、最近、Nature Medicineで発表されました。
- メディアでの顔のぼかしの力を解き放つ:包括的な探索とモデルの比較
- 「教師付き学習の実践:線形回帰」
- 「トランスフォーマーとサポートベクターマシンの関係は何ですか? トランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする」
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T., Zou, J., 医療Twitterを使用した病理画像解析のためのビジュアル・ランゲージ・ファウンデーション・モデル。2023年、Nature Medicine。
冒険を始める前に、いくつかの有用なリンクを紹介します:
- HuggingFace Weights;
- Nature Medicine論文;
- GitHubリポジトリ。
対照的な事前トレーニング101
私たちは、ソーシャルメディアでのデータ収集といくつかの追加のテクニックを用いることで、アノテーションされたデータが不要なまま、医療AI病理学のタスクに使用できるモデルを構築できることを示しています。
PLIP(CLIPから派生したモデル)とその対照的な損失について紹介することは、このブログ投稿の範囲外ですが、最初の紹介/復習をするのは良いことです。CLIPの背後にある非常にシンプルなアイデアは、画像とテキストを「画像とその説明が近くなるようなベクトル空間に配置するモデルを構築できる」というものです。
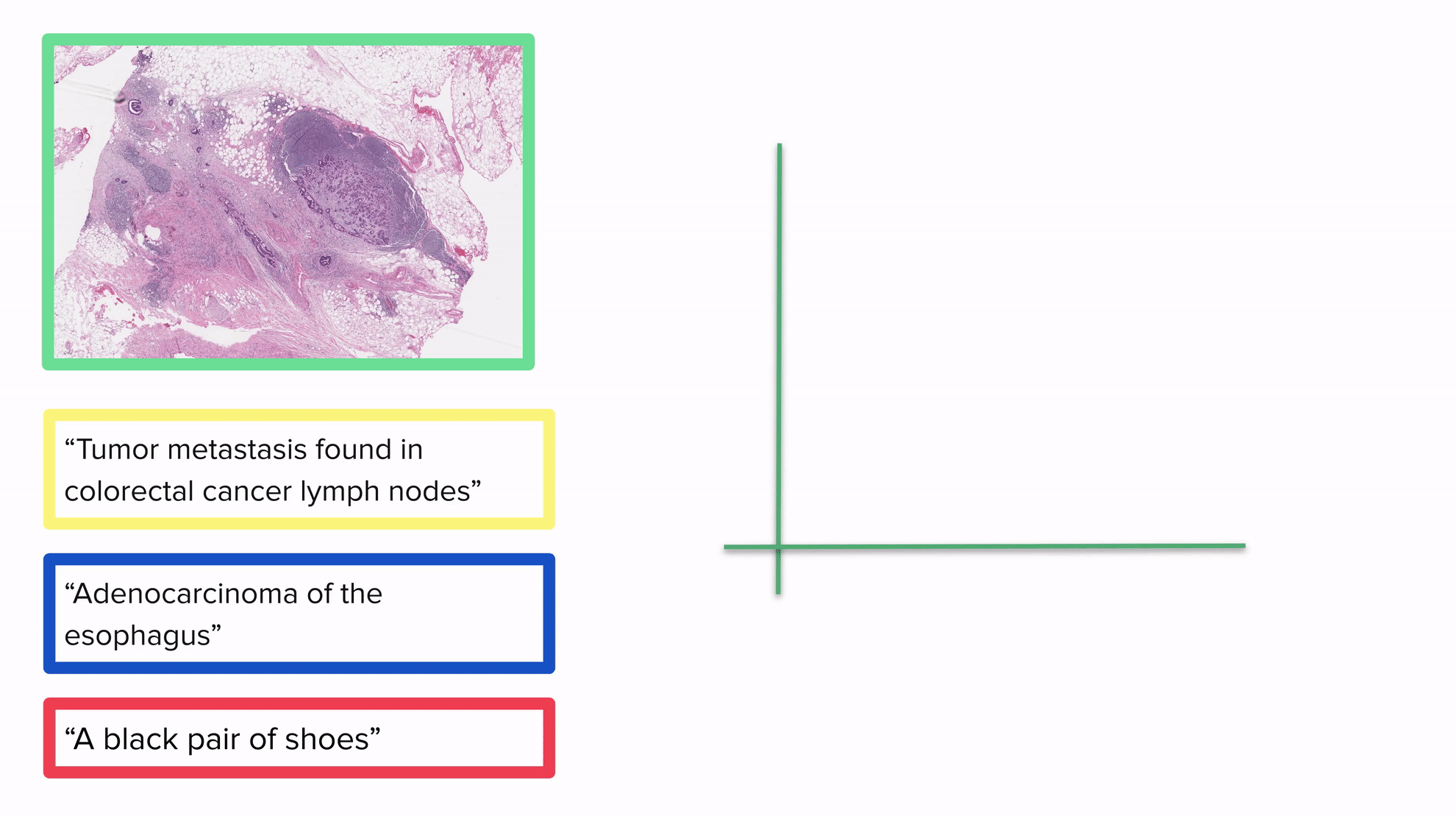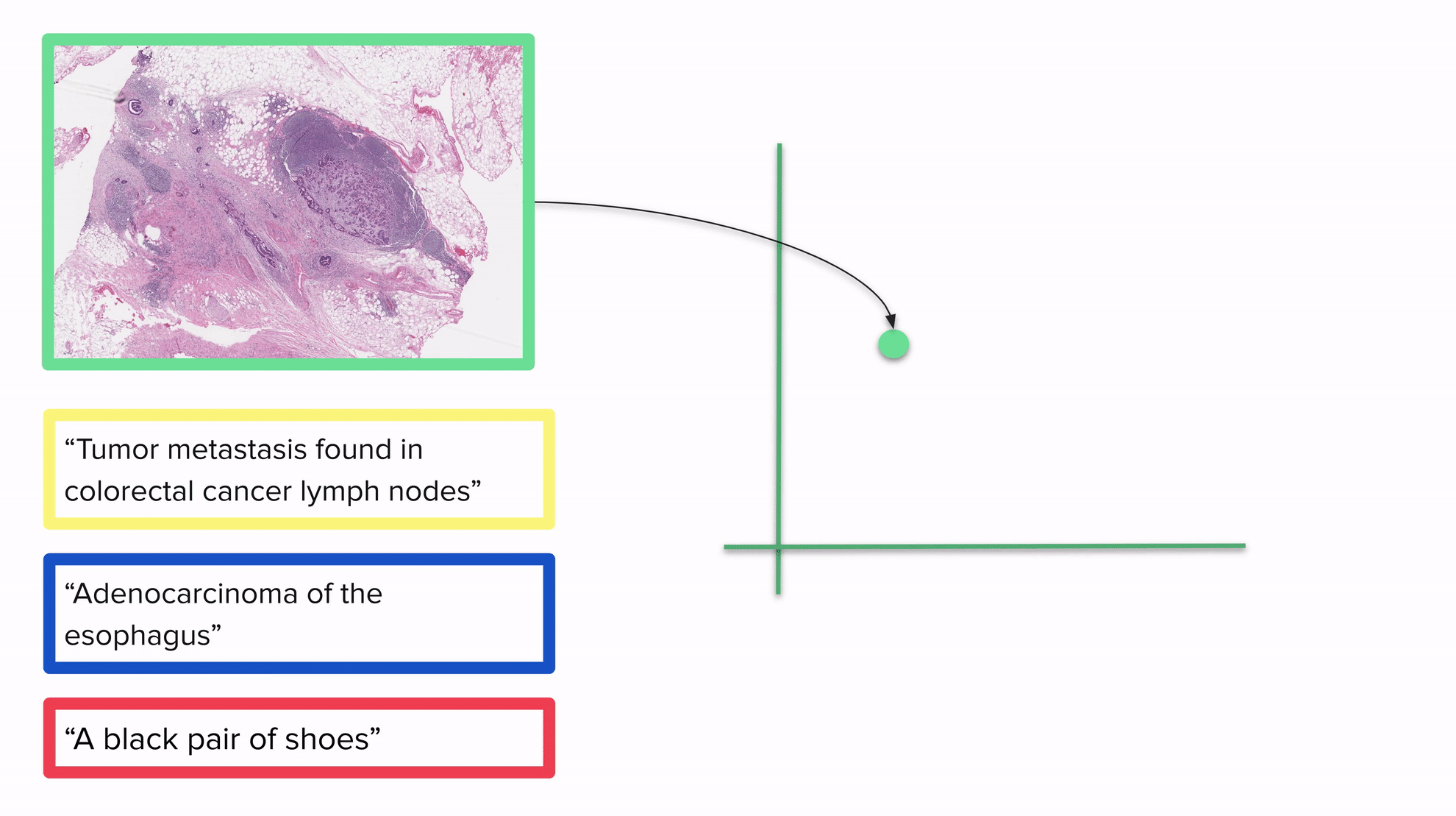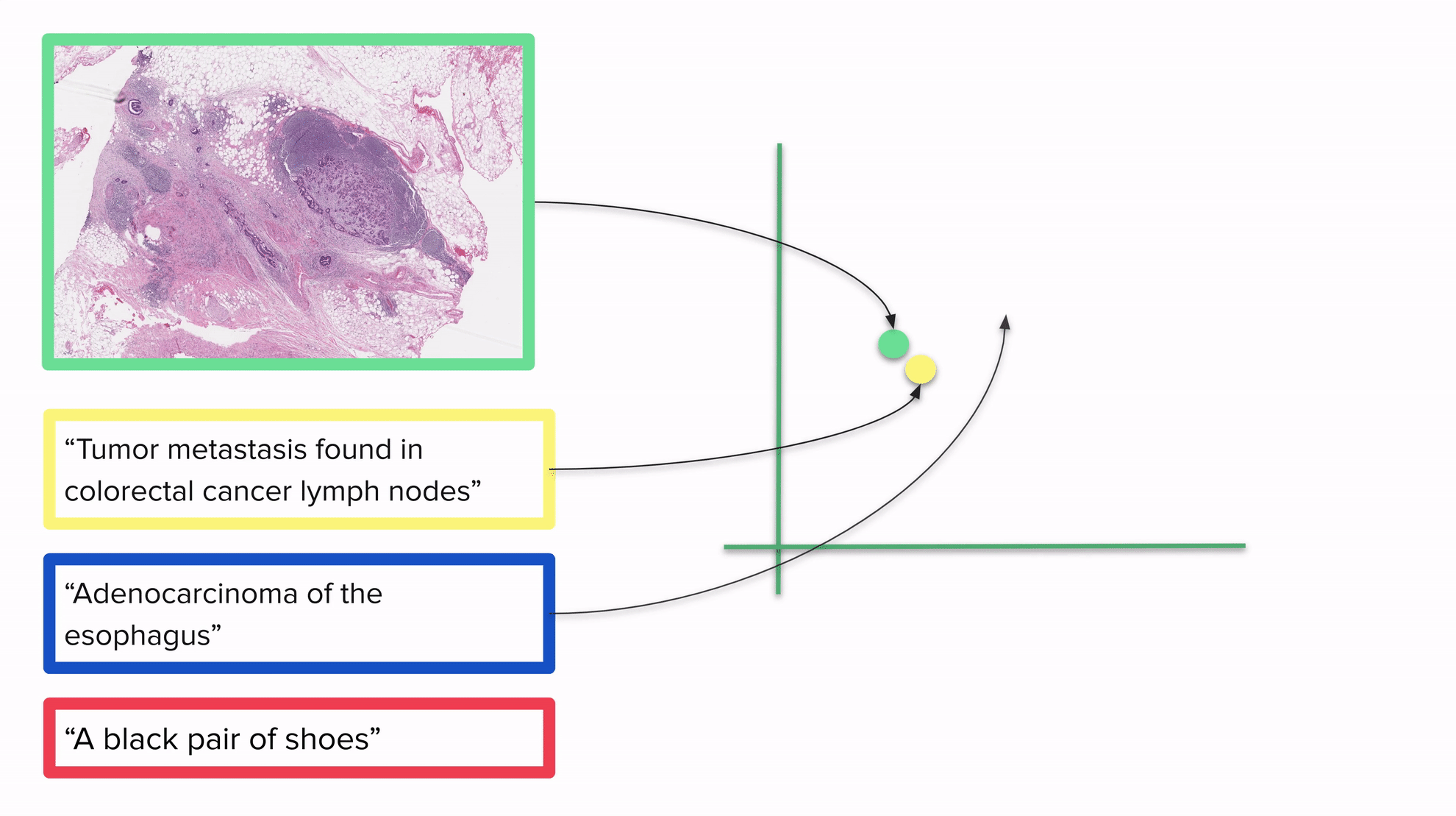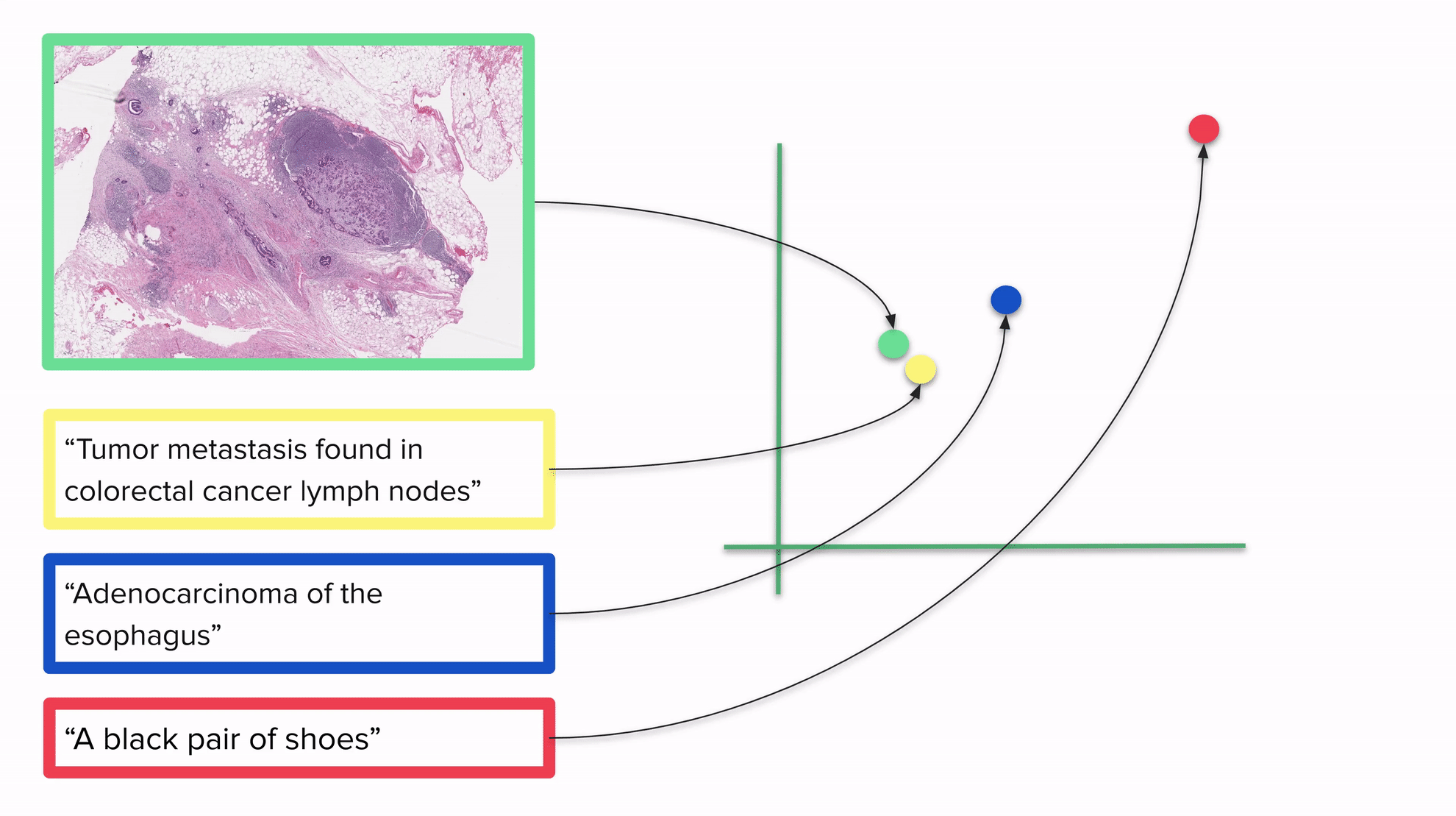
上記のGIFは、画像とテキストを同じベクトル空間に埋め込むモデルが分類にどのように使用できるかの例を示しています:すべてを同じベクトル空間に配置することで、距離を考慮して各画像を1つ以上のラベルに関連付けることができます。説明が画像に近いほど、より良い結果が得られます。最も近いラベルが画像の実際のラベルであると予想されます。
明確にするために:CLIPがトレーニングされた後、画像やテキストを埋め込むことができます。このGIFは2D空間を示していますが、一般的にCLIPで使用される空間ははるかに高次元です。
つまり、画像とテキストが同じベクトル空間にあると、多くのことができるのです:ゼロショット分類(画像に最も似ているテキストラベルを見つける)から検索(与えられた説明に最も似ている画像を見つける)まで、さまざまなことが可能です。
CLIPの訓練方法はどのようなものですか?簡単に言うと、モデルにはたくさんの画像とテキストのペアが与えられ、似たようなマッチングアイテムを近くに配置し(上の画像のように)、その他のアイテムは遠くに配置するように試みます。画像とテキストのペアが多ければ多いほど、学習する表現がより良くなります。
CLIPの背景についてはここまでにします。これでこの投稿の残りを理解するのに十分です。CLIPについてのより詳しいブログ投稿はTowards Data Scienceにあります。
CLIPの訓練方法
CLIPの紹介とHuggingFaceコミュニティウィーク中のイタリア語への微調整について
towardsdatascience.com
CLIPは非常に汎用的な画像テキストモデルとして訓練されていますが、特定のユースケース(例:ファッション(Chia et al.、2022))ではうまく機能せず、CLIPが性能を下回り、ドメイン固有の実装の方が優れている場合もあります(Zhang et al.、2023)。
病理言語と画像の事前訓練(PLIP)
ここでは、病理学に特化した元のCLIPモデルの微調整バージョンであるPLIPの構築方法について説明します。
病理言語および画像事前訓練のためのデータセットの構築
私たちはデータが必要であり、このデータはモデルの訓練に使用するのに十分に良いものでなければなりません。問題は、これらのデータをどのように見つけるかです。必要なのは関連する説明を持つ画像です-上記のGIFで見たようなものです。
ウェブ上にはかなりの量の病理データがありますが、注釈がないことが多く、PDFファイル、スライド、YouTube動画などの非標準的な形式である場合があります。
他の場所を探さなければなりません。その他の場所とはソーシャルメディアのことです。ソーシャルメディアプラットフォームを活用することで、病理に関連するコンテンツの豊富な情報にアクセスできる可能性があります。病理学者は自分の研究結果をオンラインで共有したり、同僚に質問したりするためにソーシャルメディアを使用します(病理学者がソーシャルメディアをどのように使用するかについての議論については、Isom et al.、2017を参照してください)。また、一般的に推奨されるTwitterハッシュタグセットもあります。
Twitterデータに加えて、LAIONデータセット(Schuhmann et al.、2022)から画像のサブセットも収集しています。LAIONはウェブスクレイピングによって収集された50億の画像テキストペアの膨大なコレクションです。LAIONは多くの人気のあるOpenCLIPモデルの訓練に使用されました。
病理のTwitter
病理学のTwitterハッシュタグを使用して100,000以上のツイートを収集しています。プロセスは非常に簡単です。APIを使用して特定のハッシュタグに関連するツイートを収集します。疑問符を含むツイートは除外します。なぜなら、これらのツイートは他の病理学的疑問(例:「これはどのような種類の腫瘍ですか?」)を含んでおり、実際にはモデルの構築に必要な情報ではないからです。

LAIONからのサンプリング
LAIONには50億の画像テキストペアが含まれており、データを収集する計画は次のようになります。Twitterからの自分自身の画像を使用し、この大規模なコーパス内で類似の画像を見つけることができます。この方法で、類似の画像を入手し、これらの類似の画像が病理画像でもあることを期待することができます。
ただし、これを手動で行うことは不可能です。50億の埋め込みを使用して埋め込みと検索を行うことは非常に時間がかかる作業です。幸いにも、LAION用の事前計算済みベクトルインデックスがあり、APIを使用して実際の画像でクエリを行うことができます。したがって、単に画像を埋め込み、K-NN検索を使用してLAION内の類似の画像を見つけるだけです。これらの画像のそれぞれにはキャプションが付いていることを覚えておいてください。これは私たちのユースケースに完璧です。
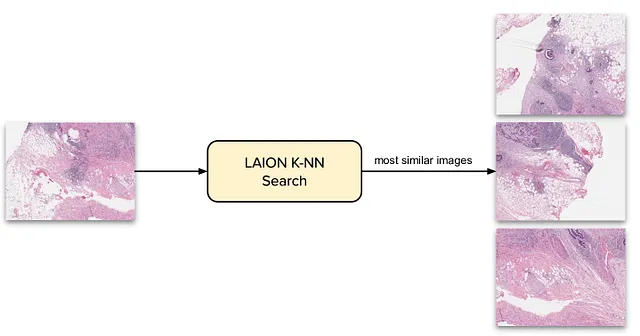
データ品質の確保
収集したすべての画像が良質ではありません。例えば、Twitterからは医学会議のグループ写真が多く収集されました。LAIONからは、時にはいくつかのフラクタルのような画像が得られることもあり、それらはあいまいにいくつかの病理学的パターンに似ているかもしれません。
私たちが行ったことは非常にシンプルでした:病理学データを陽性クラスデータ、ImageNetデータを陰性クラスデータとして使用して分類器をトレーニングしました。この種の分類器は非常に高い精度を持っています(実際には、病理画像とウェブ上のランダムな画像を簡単に区別することができます)。
さらに、LAIONデータには英語の言語分類器を適用して、英語でない例を除去しています。
病理学的言語と画像の事前トレーニング
データの収集は最も困難な部分でした。それが完了し、データを信頼できるようになったら、トレーニングを開始できます。
私たちはPLIPをトレーニングするために元のOpenAIのコードを使用しました – トレーニングループを実装し、損失のためのコサイン退冷を追加し、すべてがスムーズに動作し、検証可能な方法で実行されるようにいくつかの微調整を行いました(例えば、Comet MLトラッキング)。
私たちはさまざまなモデル(数百)をトレーニングし、パラメータと最適化技術を比較しました。最終的に、満足のいくモデルを見つけることができました。詳細は論文にありますが、このような対照的なモデルを構築する際に最も重要な要素の1つは、トレーニング中のバッチサイズができるだけ大きいことを確認することです。これにより、モデルはできるだけ多くの要素を区別することを学習できます。
医療AIのための病理学的言語と画像の事前トレーニング
さて、PLIPを検証の対象にしましょう。この基礎モデルは標準ベンチマークで優れていますか?
私たちはPLIPモデルのパフォーマンスを評価するためにさまざまなテストを実行しました。最も興味深い3つはゼロショット分類、線形プロービング、および検索ですが、ここでは主に最初の2つに焦点を当てます。簡潔さのために実験の設定は無視しますが、すべての詳細は論文で入手できます。
PLIPをゼロショット分類器として
以下のGIFは、PLIPのようなモデルを使用してゼロショット分類を行う方法を示しています。ベクトル空間での類似性の尺度としてドット積を使用します(値が高いほど類似度が高いです)。

以下のプロットでは、ゼロショット分類に使用したデータセットのPLIP対CLIPの比較が簡単に表示されています。CLIPを置き換えるためにPLIPを使用すると、性能が大幅に向上します。
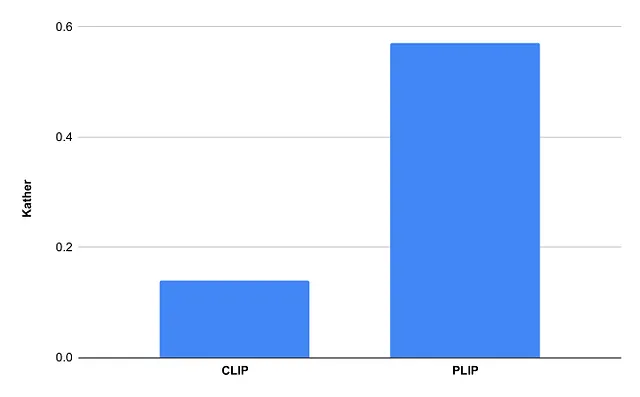
線形プロービングのための特徴抽出器としてのPLIP
PLIPの別の使用方法は、病理画像の特徴抽出器として使用することです。訓練中、PLIPは多くの病理画像を見て、それらのためのベクトル埋め込みを構築する方法を学習します。
注釈付きのデータがあるとして、新しい病理分類器を訓練したい場合、PLIPで画像の埋め込みを抽出し、それらの埋め込みの上にロジスティック回帰(または好きな他の回帰器)を訓練することができます。これは分類タスクを実行するための簡単で効果的な方法です。
なぜこれが機能するのでしょうか?アイデアは、分類器を訓練するために、病理に特化したPLIPの埋め込みは、汎用のCLIPの埋め込みよりも優れているはずだということです。

以下は、CLIPとPLIPのパフォーマンスを比較した例です。CLIPは良いパフォーマンスを発揮しますが、PLIPを使用するとさらに高い結果が得られます。

病理言語と画像の事前トレーニングの使用方法
PLIPの使用方法についてのいくつかの例と、PythonでPLIPを使用するためのStreamlitデモがあります。
コード:PLIPを使用するためのAPI
当社のGitHubリポジトリには、参考にできるいくつかの追加の例があります。モデルと対話するためのAPIを構築しました:
from plip.plip import PLIPimport numpy as npplip = PLIP('vinid/plip')# 画像の埋め込みとテキストの埋め込みを作成します。image_embeddings = plip.encode_images(images, batch_size=32)text_embeddings = plip.encode_text(texts, batch_size=32)# 埋め込みを単位ノルムに正規化します(類似性の比較に余弦類似度の代わりにドット積を使用できるようにするため)image_embeddings = image_embeddings/np.linalg.norm(image_embeddings, ord=2, axis=-1, keepdims=True)text_embeddings = text_embeddings/np.linalg.norm(text_embeddings, ord=2, axis=-1, keepdims=True)また、より標準的なHF APIを使用してモデルを読み込み、使用することもできます:
from PIL import Imagefrom transformers import CLIPProcessor, CLIPModelmodel = CLIPModel.from_pretrained("vinid/plip")processor = CLIPProcessor.from_pretrained("vinid/plip")image = Image.open("images/image1.jpg")inputs = processor(text=["a photo of label 1", "a photo of label 2"], images=image, return_tensors="pt", padding=True)outputs = model(**inputs)logits_per_image = outputs.logits_per_image probs = logits_per_image.softmax(dim=1) デモ:教育ツールとしてのPLIP
PLIPと将来のモデルは、医療AIの教育ツールとして効果的に使用できると考えています。PLIPを使用すると、ゼロショット検索が可能です。ユーザーは特定のキーワードで検索し、PLIPが最も類似/一致する画像を見つけようとします。こちらにStreamlitで作成したシンプルなウェブアプリがあります。
結論
読んでいただき、ありがとうございます!この技術の可能な将来の進化について非常に興奮しています。
このブログ投稿を終える前に、PLIPの非常に重要な制限について議論し、興味のある追加の情報を提案します。
制限事項
私たちの結果は興味深いですが、PLIPにはさまざまな制限があります。データだけでは病理の複雑な側面すべてを学ぶことはできません。データ品質を確保するためにデータフィルターを構築しましたが、モデルが正しい情報と間違った情報をどのように理解しているのかを把握するためには、より良い評価指標が必要です。
さらに重要なことに、PLIPは現在の病理学の課題を解決するものではありません。PLIPは完璧なツールではなく、多くの調査を必要とするエラーを起こすことがあります。私たちが見ている結果は間違いなく有望であり、視覚と言語を組み合わせた将来の病理学モデルの可能性を広げるものです。しかし、これらのツールが日常の医療で使用される前にはまだたくさんの作業が必要です。
雑多な情報
CLIPモデリングとCLIPの制限に関する他のブログ投稿もあります。たとえば:
CLIPにファッションを教える
ファッション向けのドメイン固有のCLIPモデル、FashionCLIPのトレーニング
towardsdatascience.com
あなたのビジョン・ランゲージモデルは単語の袋かもしれません
私たちはICLR 2023でのオーラルペーパーで、ビジョン・ランゲージモデルが言語についてどれだけ理解できるかの限界を探求します
towardsdatascience.com
参考文献
Chia, P.J., Attanasio, G., Bianchi, F., Terragni, S., Magalhães, A.R., Gonçalves, D., Greco, C., & Tagliabue, J. (2022). Contrastive language and vision learning of general fashion concepts. Scientific Reports, 12.
Isom, J.A., Walsh, M., & Gardner, J.M. (2017). Social Media and Pathology: Where Are We Now and Why Does it Matter? Advances in Anatomic Pathology.
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., & Jitsev, J. (2022). LAION-5B: An open large-scale dataset for training next generation image-text models. ArXiv, abs/2210.08402.
Zhang, S., Xu, Y., Usuyama, N., Bagga, J.K., Tinn, R., Preston, S., Rao, R.N., Wei, M., Valluri, N., Wong, C., Lungren, M.P., Naumann, T., & Poon, H. (2023). Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing. ArXiv, abs/2303.00915.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 富士通とLinux Foundationは、富士通の自動機械学習とAIの公平性技術を発表:透明性、倫理、アクセシビリティの先駆者
- 「言語モデルは放射線科を革新することができるのか?Radiology-Llama2に会ってみてください:指示調整というプロセスを通じて特化した大規模な言語モデル」
- 「InstaFlowをご紹介します:オープンソースのStableDiffusion(SD)から派生した革新的なワンステップ生成型AIモデル」
- マルチAIの協力により、大規模な言語モデルの推論と事実の正確さが向上します
- 自己対戦を通じてエージェントをトレーニングして、三目並べをマスターする
- AI/MLを活用してインテリジェントなサプライチェーンを構築するための始め方
- 「検索強化生成システムのパフォーマンスを向上させるための10の方法」






