「バランスのとれたアクト:推薦システムにおける人気バイアスの解消」
Balanced Act Resolving Popularity Bias in Recommendation Systems
ある朝、目が覚めて自分へのご褒美として新しい靴を買うことにしました。お気に入りのスニーカーのウェブサイトにアクセスし、あなたに勧められた商品を見ました。特にある一つのペアが目に留まりました — スタイルとデザインが気に入りました。迷うことなく購入し、新しい靴を履くのを楽しみにしました。
靴が届いたとき、早速自慢したくなりました。来る予定のコンサートで新しい靴を履くことにしました。しかし、会場に着くと、同じ靴を履いている人が少なくとも10人もいました!それは一体どんな確率だったのでしょうか?
突然、がっかりした気持ちが押し寄せてきました。最初は靴が大好きだったのに、同じペアを履いている人がたくさんいるのを見て、自分の購入がそれほど特別ではなかったと感じるようになりました。目立ちたいと思っていた靴が、自分を溶け込ませる結果になってしまったのです。
その瞬間、あなたは二度とそのスニーカーのウェブサイトで買い物をすることはないと誓いました。彼らの推薦アルゴリズムが好みの商品を提案してくれたとしても、それがあなたが求める満足感やユニークさをもたらすことはありませんでした。初めは推薦された商品を高く評価していましたが、全体的な体験はあなたを不幸にさせました。
これは、推薦システムには限界があることを示しています — 「良い」商品を推薦することが、顧客にとってポジティブで充実した体験を保証するものではありません。では、それは結局良い推薦だったのでしょうか?
推薦システムにおける人気バイアスを測定することの重要性とは?
人気バイアスとは、推薦システムが個人の好みに合わせた選択肢ではなく、世界的に人気のあるアイテムを多く提案する現象のことです。これは、アルゴリズムが多くのユーザーに好まれるコンテンツを推薦することでエンゲージメントを最大化しようと訓練されているために起こります。
人気のあるアイテムは依然として関連性があるかもしれませんが、人気に過度に依存することは個別の興味を考慮していないことを意味します。推薦は一般的であり、個々の興味を考慮していません。多くの推薦アルゴリズムは、全体的な人気を報酬とするメトリクスを使用して最適化されています。既に人気のあるものに対するこのシステム的なバイアスは、ユニークな提案ではなく、トレンドやバイラルなアイテムの過度なプロモーションにつながることがあります。ビジネス側から見ると、人気バイアスは、ユーザーによって発見されにくく、売りにくいニッチな商品の在庫が企業に蓄積されるという状況にもつながることがあります。
特定のユーザーの好みを考慮した個別の推薦は、特に主流とは異なるニッチな興味にとって大きな価値をもたらすことがあります。それらはユーザーが自分に合った新しい予想外のアイテムを発見するのを助けます。
推薦システムでは人気と個別性のバランスを取ることが理想的です。目立たない宝石のようなアイテムを各ユーザーに提供することを目指す一方で、一般的に魅力的なコンテンツも時折提供することが目標です。
人気バイアスを測定する方法は?
平均推薦人気度
平均推薦人気度 (ARP) は、推薦されたアイテムの人気度を評価するための指標です。トレーニングセットで受け取ったレーティングの数に基づいて、アイテムの平均人気度を計算します。数学的には、ARPは以下のように計算されます:

ここで:
- |U_t| はユーザーの数です
- |L_u| はユーザー u の推薦リスト L_u 内のアイテム数です。
- ϕ(i) はトレーニングセットで “アイテム i” が評価された回数です。
単純に言えば、ARPは推薦リスト内のアイテムの人気度(レーティング数)を合計し、テストセットのすべてのユーザーでこの人気度を平均化することで計算されます。
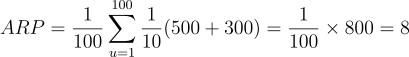
例えば、テストセットに100人のユーザー |U_t| = 100 があるとします。各ユーザーに対して、10個のアイテム |L_u| = 10 の推薦リストを提供します。アイテムAがトレーニングセットで500回(ϕ(A) =. 500)評価され、アイテムBが300回(ϕ(B) =. 300)評価された場合、これらの推薦のARPは以下のように計算されます:
この例では、ARP値は8であり、トレーニングセットでの評価の数に基づいて、すべてのユーザーにおける推奨アイテムの平均人気が8であることを示しています。
ロングテールアイテムの平均割合(APLT)
ロングテールアイテムの平均割合(APLT)メトリックは、推奨リストに存在するロングテールアイテムの平均割合を計算します。以下のように表されます:

ここで:
- |Ut|はユーザーの総数を表します。
- u ∈ Utは各ユーザーを示します。
- Luはユーザーuの推奨リストを表します。
- Γはロングテールアイテムの集合を表します。
簡単に言えば、APLTはユーザーに提供される推奨アイテムの平均的な人気の低いアイテムまたはニッチなアイテムの割合を定量化します。より高いAPLTは、推奨にそのようなロングテールアイテムの大部分が含まれていることを示します。
例えば:100人のユーザー(|Ut| = 100)がいるとします。各ユーザーの推奨リストでは、平均して50アイテム(|Lu| = 50)のうち20アイテムがロングテールセット(Γ)に属しているとします。公式を使用して、APLTは次のようになります:
APLT = Σ (20 / 50) / 100 = 0.4
よって、このシナリオではAPLTは0.4または40%であり、推奨リストの平均40%がロングテールセットからのアイテムであることを意味します。
ロングテールアイテムの平均カバレッジ(ACLT)
ロングテールアイテムの平均カバレッジ(ACLT)メトリックは、全体の推奨に含まれるロングテールアイテムの割合を評価します。APLTとは異なり、ACLTはすべてのユーザーにわたるロングテールアイテムのカバレッジを考慮し、これらのアイテムが推奨に効果的に表されているかどうかを評価します。次のように定義されます:
ACLT = Σ Σ 1(i ∈ Γ) / |Ut| / |Lu|
ここで:
- |Ut|はユーザーの総数を表します。
- u ∈ Utは各ユーザーを示します。
- Luはユーザーuの推奨リストを表します。
- Γはロングテールアイテムの集合を表します。
- 1(i ∈ Γ)は、アイテムiがロングテールセットΓにある場合に1、それ以外の場合に0となる指示関数です。
簡単に言えば、ACLTは各ユーザーの推奨に含まれるロングテールアイテムの平均割合を計算します。
例えば:100人のユーザー(|Ut| = 100)と500個のロングテールアイテム(|Γ| = 500)があるとします。すべてのユーザーの推奨リストには、ロングテールアイテムが150回(Σ Σ 1(i ∈ Γ) = 150)推奨されています。すべての推奨リストに含まれるアイテムの総数は3000です(Σ |Lu| = 3000)。公式を使用して、ACLTは次のようになります:
ACLT = 150 / 100 / 3000 = 0.0005
よって、このシナリオではACLTは0.0005または0.05%であり、全体の推奨においてロングテールアイテムの0.05%がカバーされていることを示しています。このメトリックは、レコメンダーシステムにおけるニッチなアイテムのカバレッジを評価するのに役立ちます。
推薦システムにおける人気バイアスの削減方法
人気度に注意した学習
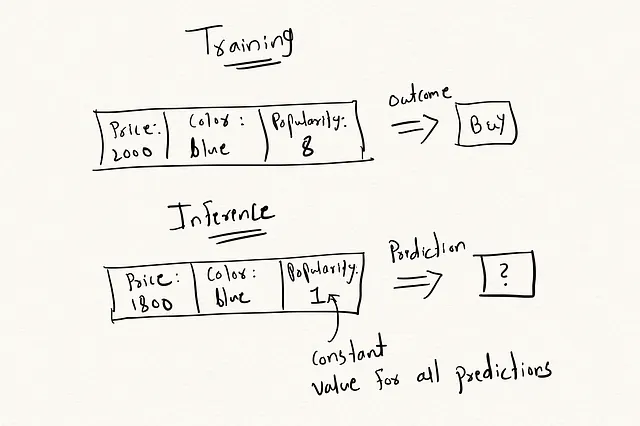
このアイデアは、Position Aware Learning(PAL)からのインスピレーションを受けています。PALでは、ランキングの関連性と位置の影響を同時に最適化するようにMLモデルに依頼するアプローチが採用されています。同じアプローチを人気度スコアにも使用できます。このスコアは、平均推奨人気など、上記で説明したいずれかのスコアを持つことができます。
- トレーニング時に、アイテムの人気度を入力特徴量の1つとして使用します。
- 予測段階では、定数値で置き換えます。
xQUADフレームワーク
人気バイアスを修正する興味深い方法の1つは、xQUADフレームワークと呼ばれるものを使用することです。このフレームワークでは、現在のモデルからの長い推薦リスト(R)と確率/尤度スコアを使用して、より多様な新しいリスト(S)を作成します(|S| < |R|)。この新しいリストの多様性は、ハイパーパラメータλによって制御されます。
フレームワークのロジックを包み込もうとしました:

セットR内のすべてのドキュメントにスコアを計算します。最大スコアのドキュメントをセットSに追加し、同時にセットRから削除します。


「S」に追加する次のアイテムを選択するために、R\S(Sを除いたR)の各アイテムのスコアを計算します。 「S」に追加するために選択された各アイテムにより、P(v/u)が上昇するため、非人気アイテムが再び選択される可能性も上昇します。
参考文献
https://arxiv.org/pdf/1901.07555.pdf
https://www.ra.ethz.ch/cdstore/www2010/www/p881.pdf
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- MEMSセンサーデータの探索的分析
- LangChainとPinecone Vector Databaseを使用したカスタムQ&Aアプリケーションの構築
- 「このAI論文は、すべての科学分野をカバーする学術データを含む26億以上のトリプルを持つ包括的なRDFデータセットを紹介しています」
- 「Plotly プロットでインド数字システムの表記を使用する」
- 情報とエントロピー
- クロマに会ってください:LLMs用のAIネイティブオープンソースベクトルデータベース-メモリを使用したPythonまたはJavaScript LLMアプリをより速く構築する方法
- 「大規模言語モデル:現実世界のCXアプリケーションの包括的な分析」
