「Azure OpenAIを使用した企業文書とのチャット」
Azure OpenAIを使用した企業文書とのチャット
ChatGPTのような大規模言語モデル(LLM)は、インターネットからの大量のテキストデータで訓練されたため、数十億のパラメータ内に膨大な知識を保持しています。しかし、彼らの知識は訓練に使用されたテキストデータに基づくものであり、それ以上の情報や、例えば企業のファイアウォールの背後に保存された個人データなどは持ちません。
これまで、この知識の制約を補完する最も一般的でアクセスしやすい方法は、リトリーバル・オーグメンテッド・ジェネレーション(RAG)と呼ばれる手法です(もう一つの手法はファインチューニングです)。これは、LLMが知識を持たないテキストベースのドキュメントを外部のデータベースに保存しておき、ユーザーがLLMに質問をすると、システムがこのデータベースから関連するドキュメントを取得し、ユーザーの質問に回答するための参照としてLLMに提供することで機能します。これはコンテキスト学習と呼ばれることもあり、より直訳すると「プロンプト stuffing(プロンプト詰め)」とも言えます。ほとんどのユースケースでは、RAGの手法がLLMのファインチューニングよりも好ましいです。ファインチューニングは通常よりも複雑で、特殊なハードウェア(GPU)とスキルセット(例:機械学習)が必要であり、一般的には実装コストが高くなります。
Microsoft Azureは、企業のドキュメントの知識をLLMに付加するためにRAGの手法を活用するためのクイックスタートソリューションをリリースしました。この会話エージェントは、Azureのインフラストラクチャ(OpenAIではなく)上でホストされているOpenAI LLM(gpt-3.5/ChatGPTまたはgpt-4)をアプリケーションが補完APIエンドポイント経由で呼び出します。このアプリケーションの使用は厳格なAzureのデータ保護ポリシーによってカバーされており、したがって使用中に行われるユーザーの対話や共有されるデータは安全かつプライベートに保たれます。価格はトークンの使用量に基づいています。
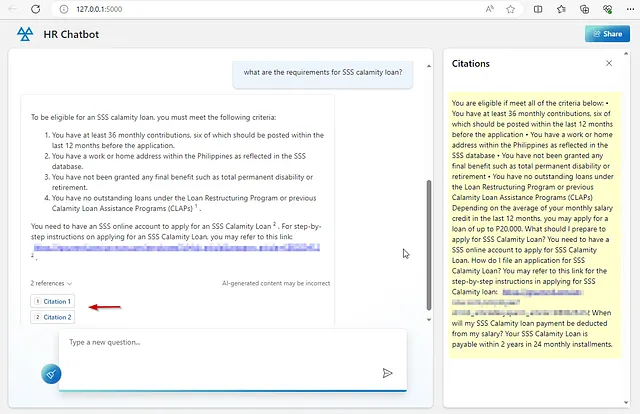
以下のサンプルのチャット対話は、参照としてのサンプルドキュメント(社会保障災害融資プログラムに関するもの)を使用して、このアプリケーションを示しています。LLMは「幻想を生み出す」傾向があり、真実でないまたはでっち上げの回答を返すことが知られています。そのため、各回答は元になったソースドキュメントを参照する引用とともに返されます。これにより、ユーザーは特定の回答の信憑性を検証することができます。
- マサチューセッツ大学アマースト校のコンピューターサイエンティストたちは、Pythonプログラミングを劇的に高速化するためのオープンソースのAIツール、Scaleneを開発しました
- 「最先端のAI翻訳ソフトウェア/ツール(2023年9月)」
- Amazon SageMaker、HashiCorp Terraform、およびGitLab CI/CDを使用したモデルモニタリングと再トレーニングによるバッチ推論のためのMLOps
デプロイメントオプション
このソリューションは、ウェブアプリとして、またはAzure OpenAI Chatプレイグラウンドから直接パワーバーチャルエージェント(PVA)ボットとしてデプロイすることができます。データソースを設定して、利用可能な2つのデプロイメントオプションに基づいてデプロイする必要があります。

ウェブアプリ
ウェブアプリは、ラップトップやモバイルデバイスのブラウザからアクセスできる基本的なチャットインターフェースです。このウェブアプリは、MicrosoftからMITライセンスでオープンソースとしてリリースされており、商用利用が許可されています。GitHubのリポジトリはこちらから見つけることができます。お客様は必要に応じてアプリケーションをカスタマイズすることができます。ウェブアプリは、Azureでホストされるアプリサービスとして「そのまま」デプロイすることができます。これにより、Azureのロゴとデフォルトのカラースキームが使用されます。
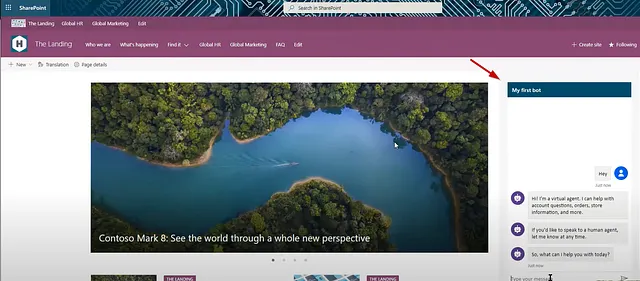
パワーバーチャルエージェント
PVAボットは企業のウェブサイトにデプロイすることができます。また、ネイティブの統合機能を備えており、SharePointサイトやMS Teamsなどの他のMS製品に簡単に埋め込むことができます。
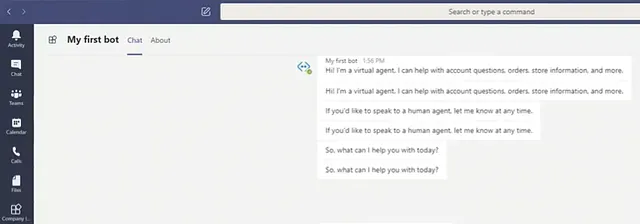
チャットボットのナレッジデータベースに会社の文書を読み込む
以下のドキュメントタイプをボットのデータベースに読み込むことができます:txt、PDF、Wordファイル、PowerPointファイル、HTML。このチャットボットには、企業のポリシーや契約書、操作手順など、テキスト豊かなドキュメントを使用することを推奨します。Excel/CSVや関係データベースに格納されているような表形式のデータは推奨されません。アップロードされたドキュメントは、お客様のAzure環境内のストレージブロブに保存され、同様にプライベートに保持されます。
チャットボットは、Azure Cognitive Searchサービスのインデックスからデータをクエリします。シングルロケーション(ローカルフォルダまたはAzure Blobなど)からすべてのサポートされているドキュメントタイプをインデックスに読み込む直感的なインデクサを持っています。
検索サービス(ユーザーのクエリ/入力とインデックスからの関連ドキュメントの比較に基づいてチャットボットの応答の基礎となる)は、BM25検索アルゴリズムに基づくレキシカルまたはキーワードの比較、およびコサイン類似度や内積を用いた埋め込み/ベクトルベースの検索アルゴリズムをサポートしています。また、これら2つのハイブリッドもサポートしています – フルテキスト検索とベクトル検索の組み合わせ。
参考文献:
Azure OpenAI on your data (preview)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「フレームワークによりロボットは連続した順序で対話的なタスクを実行できる」
- 「効率的な変数選択のための新しいアルゴリズムが提案されました」
- これらの便利なドローンは、空中で結合してより大きく、より強力なロボットを形成することができます
- 「OpenAIがGPT-4の力を持つChatGPT Enterpriseを発表」
- 「3つの医療機関が生成型AIを使用している方法」
- 「VoAGI 30 for 30 Giveaway with O’Reilly」という文を日本語に訳すと、「VoAGI 30周年記念キャンペーン、O’Reillyとの共同企画」となります
- ChatGPTを超えて;AIエージェント:労働者の新たな世界






