AWS SageMaker JumpStart Foundation Modelsを使用して、ツールを使用するLLMエージェントを構築し、展開する方法を学びましょう
AWS SageMaker JumpStart Foundation Modelsを使用して、LLMエージェントを構築・展開する方法を学びましょう
大規模言語モデル(LLM)エージェントは、単独のLLMの機能を拡張するプログラムであり、1)外部ツール(API、関数、Webフック、プラグインなど)へのアクセス、および2)自己指導型でタスクを計画および実行する能力を持っています。しばしば、LLMは複雑なタスクを達成するために他のソフトウェア、データベース、またはAPIと対話する必要があります。例えば、ミーティングをスケジュールする管理用チャットボットは、従業員のカレンダーやメールにアクセスする必要があります。ツールへのアクセスにより、LLMエージェントはより強力になりますが、複雑さが増します。
この記事では、LLMエージェントを紹介し、Amazon SageMaker JumpStartとAWS Lambdaを使用してeコマースLLMエージェントを構築および展開する方法を示します。このエージェントはツールを使用して、返品に関する質問(「私の返品rtn001は処理されましたか?」)や注文に関する更新情報(「注文123456は出荷されましたか?」)などの新しい機能を提供します。これらの新機能には、LLMが複数のデータソース(注文、返品)からデータを取得し、検索増強生成(RAG)を実行する必要があります。
LLMエージェントのパワーを引き出すために、SageMakerエンドポイントとして展開されたFlan-UL2モデルを使用し、AWS Lambdaで構築されたデータ取得ツールを使用します。エージェントは後でAmazon Lexと統合して、ウェブサイトやAWS Connect内でチャットボットとして使用することができます。記事の最後に、LLMエージェントを本番環境に展開する前に考慮すべき事項について説明します。完全に管理されたLLMエージェントのビルド体験については、AWSはAmazon Bedrockのエージェントも提供しています(プレビュー版)。
LLMエージェントアーキテクチャの簡単な概要
LLMエージェントは、複雑なタスクを完了するために必要な場合にのみツールを使用するためのLLMを使用するプログラムです。ツールとタスク計画の能力により、LLMエージェントは外部システムと対話し、LLMの従来の制限(知識の切れ端、幻覚、不正確な計算など)を克服することができます。ツールはAPI呼び出し、Python関数、またはWebフックベースのプラグインなど、さまざまな形式で提供されることがあります。たとえば、LLMは「検索プラグイン」を使用して関連するコンテキストを取得し、RAGを実行することができます。
- 「AIはオーディオブック制作をどのように革新しているのか? ニューラルテキストtoスピーチ技術により、電子書籍から数千冊の高品質なオーディオブックを作成する」
- Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
- 「アメリカがGoogleの検索支配に挑戦する」
では、LLMがツールを選択し、タスクを計画するとはどういう意味でしょうか?(ReAct、MRKL、Toolformer、HuggingGPT、Transformer Agentsなどの)LLMをツールと組み合わせて使用するための多くのアプローチがあり、進展が急速に行われています。ただし、1つの簡単な方法は、LLMにツールのリストをプロンプトとして提示し、以下の例のように、1)ユーザーのクエリを満たすためにツールが必要かどうかを判断し、必要な場合は2)適切なツールを選択するように求めることです。このようなプロンプトは、適切なツールを選択するためのLLMの信頼性を向上させるためにフューショットの例を含む場合があります。
‘’’
ユーザーの質問に答えるためのツールを選択するタスクが与えられます。以下のツールにアクセスできます。
search:よくある質問で答えを検索する
order:商品を注文する
noop:ツールは必要ありません
{フューショットの例}
質問:{入力}
ツール:
‘’’より複雑なアプローチでは、GorillaLLMのように「API呼び出し」や「ツールの使用」といったものを直接デコードできる専門のLLMを使用することがあります。このようなファインチューニングされたLLMは、API仕様データセットでトレーニングされ、命令に基づいてAPI呼び出しを認識および予測するためのメタデータ(説明、yaml、またはJSONスキーマ)が必要です。これはAmazon BedrockおよびOpenAIの関数呼び出しのエージェントによって採用されるアプローチです。なお、ツールの選択能力を示すには、LLMは一般に十分に大きく複雑である必要があります。
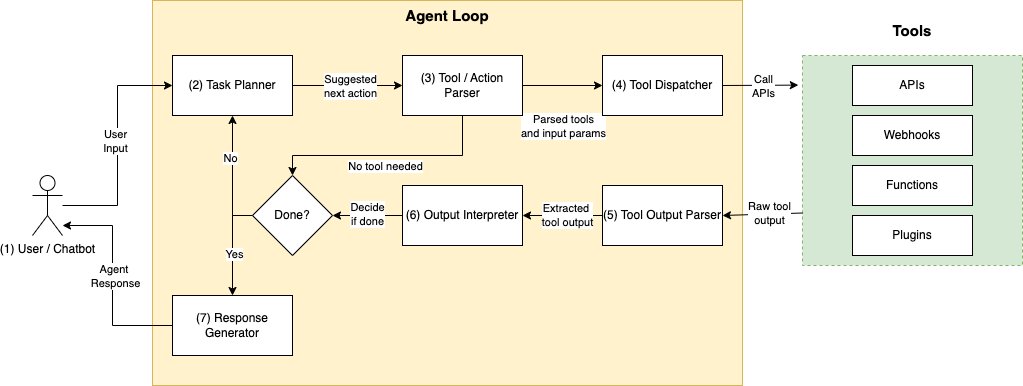
タスク計画とツール選択メカニズムが選択されたと仮定した場合、典型的なLLMエージェントプログラムは次のシーケンスで動作します:
- ユーザーリクエスト – プログラムはクライアントアプリケーションから「私の注文123456はどこですか?」などのユーザー入力を取得します。
- 次のアクションを計画し、使用するツールを選択する – 次に、プログラムはLLMに対してプロンプトを使用して次のアクションを生成させます。たとえば、「
OrdersAPIを使用して注文テーブルを検索する」というアクションを生成させます。LLMは、利用可能なツールとその説明のリストから、OrdersAPIなどのツール名を提案するように求められます。または、LLMに対してOrdersAPI(12345)などの入力パラメータを含むAPI呼び出しを直接生成させることもできます。- 次のアクションがツールやAPIの使用を必要とする場合とそうでない場合があります。必要でない場合、LLMはツールからの追加のコンテキストを組み込まずにユーザー入力に応答するか、「この質問には答えられません」といった既定の応答を返します。
- ツールの要求の解析 – 次に、LLMが提案したツール/アクションの予測を解析して検証する必要があります。検証は、ツール名、API、およびリクエストパラメータが幻覚でなく、仕様に従って適切に呼び出されることを確認するために必要です。この解析には別のLLM呼び出しが必要になる場合があります。
- ツールの呼び出し – 有効なツール名とパラメータが確認されたら、ツールを呼び出します。これはHTTPリクエスト、関数呼び出しなどが該当します。
- 出力の解析 – ツールからの応答には、追加の処理が必要な場合があります。たとえば、API呼び出しの結果は長いJSON応答であり、LLMにとって関心のあるフィールドのサブセットのみが対象です。クリーンで標準化された形式で情報を抽出することで、LLMが結果をより信頼性の高い形で解釈できるようになります。
- 出力の解釈 – ツールからの出力を考慮し、LLMに対して再度プロンプトを
異なるエージェントフレームワークは、前のプログラムのフローを異なる方法で実行します。たとえば、ReActはツールの選択と最終回答の生成を単一のプロンプトに組み合わせます。ツールの選択と回答の生成に別々のプロンプトを使用するのではありません。また、このロジックは単一のパスで実行されるか、または「エージェントループ」と呼ばれるwhile文で実行されます。エージェントループは、最終回答が生成されるか、例外が発生するか、タイムアウトが発生するまで終了します。一貫しているのは、エージェントがタスクが終了するまで計画とツールの呼び出しをオーケストレートするためにLLMを使用することです。次に、AWSサービスを使用して簡単なエージェントループを実装する方法を示します。
ソリューションの概要
このブログ投稿では、ツールによって提供される2つの機能を備えたeコマースサポートLLMエージェントを実装します。
- 返品状況の取得ツール – 「返品
rtn001の状況はどうなっていますか?」など、返品の状況に関する質問に答えます。 - 注文状況の取得ツール – 「注文
123456の状況はどうですか?」など、注文の状況を追跡します。
エージェントはLLMをクエリルーターとして効果的に使用します。クエリ(「注文
123456の状況はどうですか?」など)が与えられた場合、適切な取得ツールを選択して複数のデータソース(返品と注文)にクエリを行います。これを実現するために、LLMは複数の取得ツールの中から選択し、データソースとの対話およびコンテキストの取得を担当します。これにより、単一のデータソースを想定する単純なRAGパターンを拡張します。両方の取得ツールは、入力としてid(
orderIdまたはreturnId)を受け取り、データソースからJSONオブジェクトを取得し、JSONを人間が読みやすい表現文字列に変換します。実世界のシナリオでは、データソースはDynamoDBなどの高いスケーラビリティを持つNoSQLデータベースである場合がありますが、このソリューションではデモ目的で単純なPythonのDictとサンプルデータを使用しています。追加の機能は、取得ツールの追加とそれに応じてプロンプトの修正によってエージェントに追加できます。このエージェントは、HTTPを介して任意のUIと統合するスタンドアロンサービスとしてテストできます。これはAmazon Lexを使用して簡単に行うことができます。
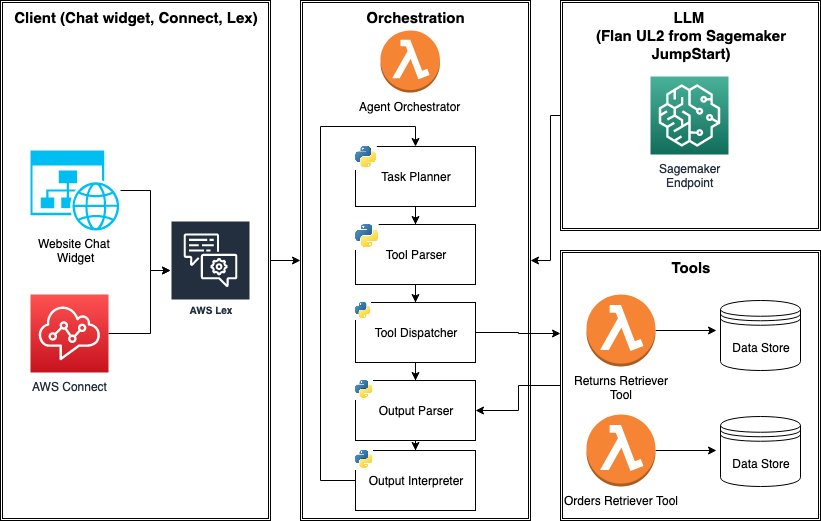
以下に、主要なコンポーネントに関する追加の詳細情報を示します。
- LLM推論エンドポイント – エージェントプログラムの中核はLLMです。SageMaker JumpStartファウンデーションモデルハブを使用して
Flan-UL2モデルを簡単にデプロイします。SageMaker JumpStartを使用すると、専用のSageMakerインスタンスにLLM推論エンドポイントを簡単にデプロイできます。 - エージェントオーケストレータ – エージェントオーケストレータは、LLM、ツール、およびクライアントアプリケーション間の相互作用をオーケストレートします。このソリューションでは、このフローを駆動するためにAWS Lambda関数を使用し、以下をヘルパー関数として使用します。
- タスク(ツール)プランナー – タスクプランナーは、LLMを使用して1)返品の問い合わせ、2)注文の問い合わせ、または3)ツールなしのいずれかを提案します。ファインチューニングせずに、プロンプトエンジニアリングのみを使用し、
Flan-UL2モデルをそのまま使用します。 - ツールパーサー – ツールパーサーは、タスクプランナーからのツールの提案が有効であることを確認します。特に、単一の
orderIdまたはreturnIdが解析できることを確認します。それ以外の場合は、デフォルトのメッセージで応答します。 - ツールディスパッチャ – ツールディスパッチャは、有効なパラメータを使用してツール(Lambda関数)を呼び出します。
- 出力パーサー – 出力パーサーは、JSONから人間が読みやすい文字列に関連するアイテムをクリーンアップおよび抽出します。このタスクは、各取得ツールおよびオーケストレータ内で行われます。
- 出力インタプリタ – 出力インタプリタの役割は、1)ツールの呼び出しからの出力を解釈し、2)ユーザリクエストを満たすことができるか、追加の手順が必要かを判断することです。後者の場合、別個に最終応答が生成され、ユーザに返されます。
- タスク(ツール)プランナー – タスクプランナーは、LLMを使用して1)返品の問い合わせ、2)注文の問い合わせ、または3)ツールなしのいずれかを提案します。ファインチューニングせずに、プロンプトエンジニアリングのみを使用し、
さて、エージェントオーケストレータ、タスクプランナー、およびツールディスパッチャについて少し詳しく見てみましょう。
エージェントオーケストレータ
以下は、エージェントオーケストレータのLambda関数内でのエージェントループの要約版です。このループでは、
task_plannerやtool_parserなどのヘルパー関数を使用して、タスクをモジュール化しています。ここでのループは、LLMが不必要に長いループにはまるのを防ぐために、最大2回まで実行されるように設計されています。#.. インポート .. MAX_LOOP_COUNT = 2 # 2回の反復後にエージェントループを停止する # ... ヘルパー関数の定義 ... def agent_handler(event): user_input = event["query"] print(f"user input: {user_input}") final_generation = "" is_task_complete = False loop_count = 0 # エージェントループの開始 while not is_task_complete and loop_count < MAX_LOOP_COUNT: tool_prediction = task_planner(user_input) print(f"tool_prediction: {tool_prediction}") tool_name, tool_input, tool_output, error_msg = None, None, "", "" try: tool_name, tool_input = tool_parser(tool_prediction, user_input) print(f"tool name: {tool_name}") print(f"tool input: {tool_input}") except Exception as e: error_msg = str(e) print(f"tool parse error: {error_msg}") if tool_name is not None: # 有効なツールが選択され、パースされた場合 raw_tool_output = tool_dispatch(tool_name, tool_input) tool_status, tool_output = output_parser(raw_tool_output) print(f"tool status: {tool_status}") if tool_status == 200: is_task_complete, final_generation = output_interpreter(user_input, tool_output) else: final_generation = tool_output else: # 有効なツールが選択されずにパースされなかった場合は、デフォルトのメッセージまたはエラーメッセージを返す final_generation = DEFAULT_RESPONSES.NO_TOOL_FEEDBACK if error_msg == "" else error_msg loop_count += 1 return { 'statusCode': 200, 'body': final_generation }タスクプランナー(ツール予測)
エージェントオーケストレータは、ユーザーの入力に基づいて取得ツールを予測するために
task plannerを使用します。当社のLLMエージェントでは、このタスクをコンテキストでLLMに教えるために、プロンプトエンジニアリングとフューショットプロンプティングを単純に使用します。より洗練されたエージェントでは、ツール予測にファインチューニングされたLLMを使用することができますが、これはこの記事の範囲外です。プロンプトは次のようになります:tool_selection_prompt_template = """ ユーザーの入力に対応する適切なツールを選択するためのタスクです。ツールが必要ない場合は、"no_tool"を選んでください。 利用可能なツールは次のとおりです: returns_inquiry: 特定の返品のステータス(保留中、処理済みなど)に関する情報のデータベース。 order_inquiry: 特定の注文のステータス(配送状況、商品、金額など)に関する情報。 no_tool: ユーザーの入力に答えるためにツールは必要ありません。 カンマで区切って複数のツールを提案することができます。 例: ユーザー: "営業時間は何時からですか?" ツール: no_tool ユーザー: "注文12345は出荷されましたか?" ツール: order_inquiry ユーザー: "返品ret812は処理済みですか?" ツール: returns_inquiry ユーザー: "注文を返品するまでの期間は何日ですか?" ツール: returns_inquiry ユーザー: "注文38745の合計金額はいくらでしたか?" ツール: order_inquiry ユーザー: "店舗ポリシーに基づいて注文38756を返品できますか?" ツール: order_inquiry ユーザー: "こんにちは" ツール: no_tool ユーザー: "あなたはAIですか?" ツール: no_tool ユーザー: "天気はどうですか?" ツール: no_tool ユーザー: "注文12347の払い戻しの状況はどうですか?" ツール: order_inquiry ユーザー: "返品ret172の払い戻しの状況はどうですか?" ツール: returns_inquiry ユーザーの入力: {} ツール: """ツールディスパッチャ
ツールディスパッチメカニズムは、ツールの名前に基づいて適切なLambda関数を呼び出すための
if/elseロジックで機能します。以下はtool_dispatchヘルパー関数の実装です。これはagentループ内で使用され、ツールLambda関数からの生の応答を返し、それがoutput_parser関数によってクリーンアップされます。def tool_dispatch(tool_name, tool_input): #... tool_response = None if tool_name == "returns_inquiry": tool_response = lambda_client.invoke( FunctionName=RETURNS_DB_TOOL_LAMBDA, InvocationType="RequestResponse", Payload=json.dumps({ "returnId": tool_input }) ) elif tool_name == "order_inquiry": tool_response = lambda_client.invoke( FunctionName=ORDERS_DB_TOOL_LAMBDA, InvocationType="RequestResponse", Payload=json.dumps({ "orderId": tool_input }) ) else: raise ValueError("無効なツールの呼び出し") return tool_responseソリューションのデプロイ
重要な前提条件 – デプロイを開始するには、以下の前提条件を満たす必要があります:
- AWS CloudFormationスタックを起動できるユーザーを介してAWS Management Consoleにアクセスできること
- AWS LambdaおよびAmazon Lexコンソールの操作に慣れていること
Flan-UL2はデプロイに単一のml.g5.12xlargeを必要とし、リソース制限を増やすためにサポートチケットを介して増加する必要がある場合があります。この例では、リージョンとしてus-east-1を使用しているため、us-east-1でサービスクオータを増やす必要がある場合は増やしてください。
CloudFormationを使用してデプロイする – 以下のボタンをクリックしてソリューションを
us-east-1にデプロイできます:
ソリューションのデプロイには約20分かかり、
LLMAgentStackスタックが作成されます。このスタックは以下をデプロイします:- SageMaker JumpStartから
Flan-UL2モデルを使用してSageMakerエンドポイントをデプロイします。 LLMAgentOrchestrator、LLMAgentReturnsTool、LLMAgentOrdersToolの3つのLambda関数をデプロイします。- AWS Lexボットをデプロイします。このボットはエージェントをテストするために使用できます:
Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot。
ソリューションのテスト
スタックは
Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Botという名前のAmazon Lexボットをデプロイします。このボットはエージェントをテストするために使用できます。以下はAWS Amazon LexボットをLambdaとの統合でテストするための詳細なガイドと、統合の高レベルでの動作方法についての追加情報です。簡単に言えば、Amazon Lexボットは、私たちが作成したLambda関数(LLMAgentOrchestrator)内で実行されるLLMエージェントとチャットするためのクイックなUIを提供するリソースです。考慮すべきサンプルテストケースは以下の通りです:
- 有効な注文の問い合わせ(例:「
123456のために注文されたアイテムは何ですか?」)- 注文「123456」は有効な注文なので、合理的な回答(例:「ハーバルハンドソープ」)を期待する必要があります。
- 返品の有効な問い合わせ(例:「私の返品
rtn003はいつ処理されますか?」)- 返品のステータスについて合理的な回答が期待されます。
- 返品または注文のいずれにも関連しない問い合わせ(例:「今スコットランドの天気はどうですか?」)
- 返品または注文に関連しない質問なので、デフォルトの回答(「申し訳ありませんが、その質問にはお答えできません。」)が返されるはずです。
- 無効な注文の問い合わせ(例:「
383833のために注文されたアイテムは何ですか?」)- id 383832は注文データセットに存在しないため、適切に失敗する必要があります(例:「注文が見つかりません。注文IDを確認してください。」)。
- 無効な返品の問い合わせ(例:「私の返品
rtn123はいつ処理されますか?」)- 同様に、id
rtn123は返品データセットに存在しないため、適切に失敗する必要があります。
- 同様に、id
- 返品に関連しない問い合わせ(例:「返品
rtn001の影響は世界平和にどのような影響を与えるのですか?」)- この質問は、有効な注文に関連するように見えるが、関連性がないため、LLMは関連性のないコンテキストの質問をフィルタリングするために使用されます。
これらのテストを自分で実行するには、以下の手順に従ってください。
- Amazon Lexコンソール(AWSコンソール > Amazon Lex)に移動し、
Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Botという名前のボットに移動します。このボットは、FallbackIntentがトリガーされた場合にLLMAgentOrchestratorLambda関数を呼び出すように事前に設定されています。 - ナビゲーションパネルでIntentsを選択します。
- 右上隅にあるBuildを選択します。
- ビルドプロセスの完了を待ちます。完了したら、以下のスクリーンショットに示すように成功メッセージが表示されます。

- テストケースを入力してボットをテストします。
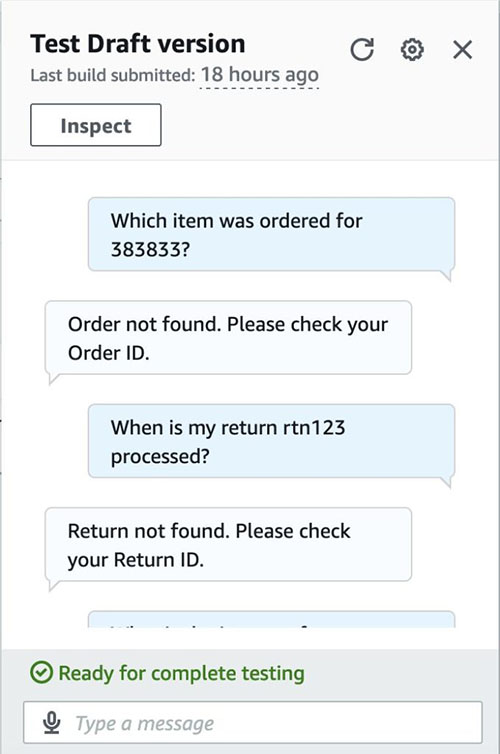
クリーンアップ
追加料金を避けるために、以下の手順に従ってソリューションで作成されたリソースを削除します:
- AWS CloudFormationコンソールで、
LLMAgentStackという名前のスタック(または選択したカスタム名)を選択します。 - 削除を選択します
- CloudFormationコンソールからスタックが削除されたことを確認します。
重要:
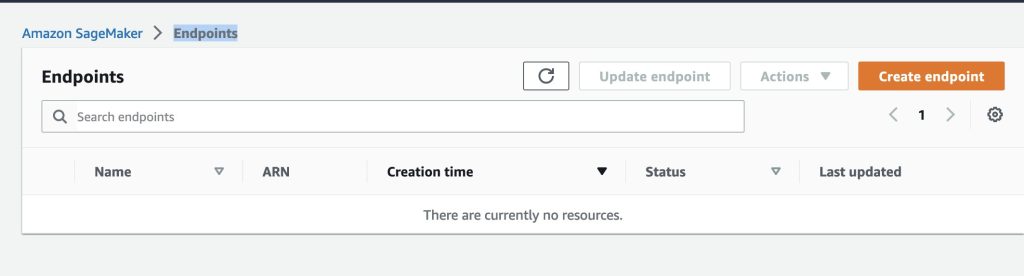
Flan-UL2推論エンドポイントが削除されていることを確認するために、スタックが正常に削除されていることを再確認してください。- 確認するには、AWSコンソール > Sagemaker > エンドポイント > 推論ページに移動します。
- ページにはすべてのアクティブなエンドポイントが表示されます。
- 以下のスクリーンショットのように、
sm-jumpstart-flan-bot-endpointが存在しないことを確認してください。
本番環境の考慮事項
LLMエージェントを本番環境に展開するには、信頼性、パフォーマンス、保守性を確保するために追加の手順が必要です。以下は、本番環境にエージェントを展開する前に考慮すべき事項のいくつかです:
- エージェントループをパワーするLLMモデルの選択: この投稿で説明したソリューションでは、タスクプランニングやツール選択を実行するために、ファインチューニングされていない
Flan-UL2モデルを使用しました。実際には、ツールやAPIリクエストを直接出力するようにファインチューニングされたLLMを使用することで、信頼性とパフォーマンスが向上し、開発が容易になる場合があります。ツール選択タスクに対してLLMをファインチューニングしたり、Toolformerのようにツールトークンを直接デコードするモデルを使用することもできます。- ファインチューニングされたモデルを使用すると、エージェントが使用可能なツールを追加、削除、更新する作業が簡素化されます。プロンプトのみを使用するアプローチでは、ツールを更新するためにエージェントオーケストレータ内のすべてのプロンプトを変更する必要があります(タスクプランニング、ツール解析、ツールディスパッチなどのプロンプト)。これは手間がかかる場合があり、LLMに対してコンテキストで提供されるツールが多すぎるとパフォーマンスが低下する場合があります。
- 信頼性とパフォーマンス: LLMエージェントは、数回のループでは完了できない複雑なタスクに対しては信頼性が低い場合があります。LLMがループに詰まってしまった場合に脱出口を提供するために、出力の検証、リトライ、LLMからの出力をJSONやyamlに構造化し、タイムアウトの強制を行うことで信頼性を向上させることができます。
結論
この投稿では、低レベルのプロンプトエンジニアリング、AWS Lambda関数、およびSageMaker JumpStartをビルディングブロックとして使用して、複数のツールを利用できるLLMエージェントをゼロから構築する方法について説明しました。LLMエージェントのアーキテクチャとエージェントループについて詳しく説明しました。このブログ投稿で紹介された概念とソリューションアーキテクチャは、事前定義されたツールの少数を使用するエージェントに適しているかもしれません。また、プロダクションでエージェントを使用するためのいくつかの戦略についても議論しました。プレビュー中のBedrockのエージェントも、エージェントツールの呼び出しをネイティブにサポートするマネージドエクスペリエンスを提供します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「GPT-4と説明可能なAI(XAI)によるAIの未来の解明」
- コンテンツを人間味を持たせ、AIの盗作を克服する方法
- 「Amazon QuickSightでワードクラウドとしてAmazon Comprehendの分析結果を可視化する」
- 「Hugging Faceを使用してAmazon SageMakerでのメール分類により、クライアントの成功管理を加速する」
- 「Amazon SageMakerは、個々のユーザーのためにAmazon SageMaker Studioのセットアップを簡素化します」
- 「ロボットに対するより柔らかいアプローチ」
- 「3Dプリントされた『生物性材料』が汚染された水を浄化することができる」
- 返品状況の取得ツール – 「返品






