AWS Inferentiaでのディープラーニングトレーニング
AWS InferentiaでのDLトレーニング
もう一つの費用節約AIモデルトレーニングのハック
この記事のテーマは、AWSの自社開発AIチップであるAWS Inferentiaについてです。具体的には、第二世代のAWS Inferentia2についてです。これは、昨年のAWS Trainiumに関する記事の続きであり、専用のAIアクセラレータに関するシリーズの一部です。シリーズの前の記事で探索したチップとは異なり、AWS InferentiaはAIモデルの推論のために設計され、特にディープラーニング推論アプリケーションを対象としています。ただし、AWS Inferentia2とAWS Trainiumは、同じ基盤となるNeuronCore-v2アーキテクチャと同じソフトウェアスタック(AWS Neuron SDK)を共有しているため、疑問が生じます:AWS InferentiaはAIトレーニングワークロードにも使用できるのでしょうか?
確かに、Amazon EC2 Inf2インスタンスファミリーの仕様(AWS Inferentiaアクセラレータで動作する)には、Amazon EC2 Trn1インスタンスファミリーと比較して、一部のトレーニングワークロードには適していない要素があります。たとえば、Inf2ともNeuronLink-v2デバイス間の高帯域幅と低レイテンシをサポートしていますが、Trainiumデバイスはリングトポロジーではなく2D Torusトポロジーで接続されており、これはCollective Communication演算子のパフォーマンスに影響を与える可能性があります(詳細についてはこちらを参照)。ただし、一部のトレーニングワークロードは、Trn1アーキテクチャのユニークな機能を必要とせず、Inf1およびInf2アーキテクチャで同様のパフォーマンスを発揮する場合があります。
実際、TrainiumおよびInferentiaアクセラレータの両方でトレーニングできる能力は、利用可能なトレーニングインスタンスの種類を大幅に増やし、各DLプロジェクトの特定のニーズに合わせてトレーニングインスタンスの選択を調整する能力を大幅に向上させます。最近の記事「Deep Learningのためのインスタンス選択」で、さまざまな種類の異なるインスタンスがDLトレーニングにおいてどれだけ価値があるかについて詳しく説明しました。Trn1ファミリーには2つのインスタンスタイプしか含まれていませんが、Inf2でのトレーニングを可能にすることで、4つの追加のインスタンスタイプを追加できます。また、Inf1を組み合わせることで、さらに4つのインスタンスタイプを追加できます。
この記事では、AWS Inferentiaでのトレーニングの可能性を示すことを目的としています。おもちゃのビジョンモデルを定義し、Amazon EC2 Trn1およびAmazon EC2 Inf2インスタンスファミリーでトレーニングしたパフォーマンスを比較します。この記事への貢献について、Ohad KleinさんとYitzhak Leviさんに感謝いたします。
免責事項
- この記事執筆時点では、Neuron SDKでサポートされていないDLモデルアーキテクチャがいくつかあります。たとえば、CNNモデルのモデル推論はサポートされていますが、CNNモデルのトレーニングはまだサポートされていません。SDKのドキュメントには、モデルアーキテクチャ、トレーニングフレームワーク(例:TensorFlowおよびPyTorch)、およびNeuronアーキテクチャバージョンごとのサポートされる機能が詳細に記載されています。
- 私たちが説明する実験は、「Deep Learning AMI Neuron PyTorch 1.13 (Ubuntu 20.04) 20230720」という執筆時点で最新バージョンのDeep Learning AMI for Neuronを使用してAmazon EC2で実行されました。Neuron SDKはまだアクティブに開発中であるため、私たちが達成した比較結果は時間の経過とともに変化する可能性があります。この記事の結果を最新のバージョンの基盤ライブラリで再評価することを強くお勧めします。
- この記事では、AWS Inferentiaパワードインスタンスでのトレーニングの可能性を示すことを目的としています。この記事または言及されている他の製品の使用を推奨するものではありません。トレーニング環境を選択する際には、プロジェクトの詳細によって大幅に異なる多くの変数が考慮される可能性があります。特に、異なるモデルは、2つの異なるインスタンスタイプで実行した場合に、全く異なる相対価格パフォーマンスの結果を示す場合があります。
おもちゃのモデル
前の記事で説明した実験と同様に、シンプルなVision Transformer(ViT)をベースとした分類モデル(timm Pythonパッケージバージョン0.9.5を使用)とランダムに生成されたデータセットを定義します。
from torch.utils.data import Datasetimport time, osimport torchimport torch_xla.core.xla_model as xmimport torch_xla.distributed.parallel_loader as plfrom timm.models.vision_transformer import VisionTransformer
# ランダムデータの使用class FakeDataset(Dataset): def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3, 224, 224], dtype=torch.float32) label = torch.tensor(data=[index % 1000], dtype=torch.int64) return rand_image, labeldef train(batch_size=16, num_workers=4): # XLAプロセスグループを初期化 import torch_xla.distributed.xla_backend torch.distributed.init_process_group('xla') # マルチプロセッシング:各ワーカーが同じ初期ウェイトを持つようにする torch.manual_seed(0) dataset = FakeDataset() model = VisionTransformer() # モデルをXLAデバイスにロード device = xm.xla_device() model = model.to(device) optimizer = torch.optim.Adam(model.parameters()) data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, num_workers=num_workers) data_loader = pl.MpDeviceLoader(data_loader, device) loss_function = torch.nn.CrossEntropyLoss() summ, tsumm = 0, 0 count = 0 for step, (inputs, target) in enumerate(data_loader, start=1): t0 = time.perf_counter() inputs = inputs.to(device) targets = torch.squeeze(target.to(device), -1) optimizer.zero_grad() outputs = model(inputs) loss = loss_function(outputs, targets) loss.backward() xm.optimizer_step(optimizer) batch_time = time.perf_counter() - t0 if idx > 10: # 最初のステップをスキップ summ += batch_time count += 1 t0 = time.perf_counter() if idx > 500: break print(f'平均ステップ時間: {summ/count}')if __name__ == '__main__': os.environ['XLA_USE_BF16'] = '1' # データローダーワーカーの数をvCPUの数に応じて設定します # たとえば、trn1の場合は4、inf2.xlargeの場合は2、inf2.12xlargeおよびinf2.48xlargeの場合は8です train(num_workers=4)# 初期化コマンド:# torchrun --nproc_per_node
結果
以下の表では、さまざまなAmazon EC2 Trn1およびAmazon EC2 Inf2インスタンスタイプの速度と価格のパフォーマンスを比較しています。
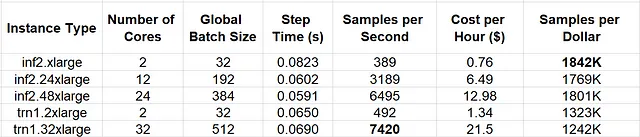
明らかに、Trainiumを搭載したインスタンスタイプはより優れた絶対パフォーマンス(つまり、高速なトレーニング)をサポートしていますが、Inferentiaを搭載したインスタンスでのトレーニングでは、2コアのインスタンスタイプでは約39%優れた価格パフォーマンスが得られ、大きなインスタンスタイプではさらに高いパフォーマンスが得られました。
再度、これらの結果に基づいて単独で設計上の決定をすることは避けるよう注意してください。一部のモデルアーキテクチャはTrn1インスタンスで正常に実行されるかもしれませんが、Inf2ではエラーが発生する可能性があります。また、一部のモデルは両方で成功するかもしれませんが、ここに示されている比較的なパフォーマンス結果とは非常に異なる結果を示す場合があります。
DLモデルのコンパイルに必要な時間は省略しています。これはモデルが実行される最初の時点でのみ必要ですが、コンパイル時間はかなり長くなる場合があります(おもちゃのモデルの場合、10分以上かかることもあります)。モデルのコンパイルのオーバーヘッドを削減する方法は、並列コンパイルとオフラインコンパイルの2つです。重要なのは、スクリプトに頻繁な再コンパイルを引き起こす操作(またはグラフの変更)が含まれていないことを確認することです。詳細については、Neuron SDKのドキュメントを参照してください。
サマリー
AWS InferentiaはAIの推論チップとして販売されていますが、深層学習モデルのトレーニングのための別のオプションとしても提供されているようです。以前のAWS Trainiumに関する記事では、新しいAI ASICでモデルをトレーニングする際に直面する可能性のあるいくつかの課題について説明しました。AWS Inferentiaを搭載したインスタンスタイプでも同じモデルをトレーニングする可能性があるため、取り組む価値が増すかもしれません。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





