AWSは、大規模なゲーミング会社のために、Large Language Model (LLM) を使って有害なスピーチを分類するためのファインチューニングを行います
AWSは、Large Language Model (LLM) を使って有害なスピーチの分類を行います
ビデオゲーム業界は、世界で30億人以上のユーザーベースを持っていると推定されています1。それは毎日お互いに仮想的にやりとりする大量のプレイヤーで構成されています。残念ながら、現実世界と同様に、すべてのプレイヤーが適切に、尊重を持ってコミュニケーションを取るわけではありません。社会的責任を持つゲーム環境を作り維持するため、AWSプロフェッショナルサービスはオンラインゲームのプレイヤー間の不適切な言語(有害な発言)を検出するメカニズムを構築するよう依頼されました。全体的なビジネス目標は、既存の手動プロセスを自動化し、プレイヤー間の不適切なやりとりを検出する速度と品質を向上させることにより、組織の運営を改善し、クリーンで健康的なゲーム環境を促進することです。
顧客の要望は、音声とテキストの抜粋をそれぞれ独自に定義された有害言語のカテゴリに分類する英語の言語検出機能を作成することでした。まず、与えられた言語の抜粋が有害であるかどうかを判断し、その抜粋を卑猥な言語や暴力的な言語などの特定の顧客定義の有害言語のカテゴリに分類することを望んでいました。
AWS ProServeは、Generative AI Innovation Center(GAIIC)とProServe ML Delivery Team(MLDT)の共同作業によってこのユースケースを解決しました。AWS GAIICは、顧客と専門家を組み合わせて、概念実証(PoC)ビルドを使用したさまざまなビジネスユースケースに対する生成AIソリューションを開発するAWS ProServe内のグループです。AWS ProServe MLDTは、PoCをスケーリングし、強化し、顧客のためにソリューションを統合することで、実証から本番までを担当します。
この顧客のユースケースは、2つの別々の投稿で紹介されます。この投稿(パート1)は、科学的な方法論について詳しく説明します。解決策の背後にある思考過程や実験、モデルのトレーニングと開発プロセスなどが説明されます。パート2では、製品化されたソリューションについて、設計の決定事項、データフロー、モデルのトレーニングとデプロイメントアーキテクチャの説明が行われます。
- AIの力による教育:パーソナライズされた成功のための学習の変革
- 一貫性のあるAIビデオエディターが登場しました:TokenFlowは、一貫性のあるビデオ編集のために拡散特徴を使用するAIモデルです
- 「メタに立ち向かい、開発者を強力にサポートするために、アリババがAIモデルをオープンソース化」
この投稿では、以下のトピックについて説明します。
- AWS ProServeがこのユースケースで解決するために直面した課題
- 大規模言語モデル(LLM)の歴史的な文脈と、この技術がこのユースケースに最適である理由
- AWS GAIICのPoCとAWS ProServe MLDTのデータサイエンスと機械学習(ML)の視点からの解決策
データの課題
AWS ProServeが有害言語分類器のトレーニングに直面した主な課題は、顧客から正確なモデルをゼロからトレーニングするための十分なラベル付きデータを入手することでした。AWSは顧客から約100のラベル付きデータサンプルを受け取りましたが、これはデータサイエンスコミュニティでLLMを微調整するために推奨される1,000のサンプルよりもはるかに少ないです。
付加的な固有の課題として、自然言語処理(NLP)分類器は、正確な予測を行うためには大量の語彙(コーパスとして知られる)が必要であり、その訓練は非常に高コストになることが歴史的に知られています。十分な量のラベル付きデータが提供された場合、厳格で効果的なNLPソリューションは、顧客のラベル付きデータを使用してカスタム言語モデルをトレーニングすることです。このモデルはプレイヤーのゲーム用語のみでトレーニングされるため、ゲーム内で観察される言語に適応したものになります。ただし、この解決策はコストと時間の制約があり、実現不可能でした。AWS ProServeは、比較的小規模なラベル付きデータセットで正確な言語有害性分類器をトレーニングする解決策を見つける必要がありました。その解決策は、転移学習として知られています。
転移学習のアイデアは、事前にトレーニングされたモデルの知識を利用して、異なるが比較的似た問題に適用することです。たとえば、画像分類器が画像に猫が含まれるかどうかを予測するためにトレーニングされた場合、そのモデルがトレーニング中に獲得した知識を使用して、他の動物(例えばトラ)を認識することができます。この言語ユースケースでは、AWS ProServeは、有害な言語を検出するために事前にトレーニングされた言語分類器を見つけ、顧客のラベル付きデータを使用して微調整する必要がありました。
解決策は、LLMを見つけて微調整することで有害言語を分類することでした。LLMは、ラベル付きデータを使用せずに数十億のパラメータを使用してトレーニングされたニューラルネットワークです。AWSのソリューションに進む前に、次のセクションではLLMの歴史とその歴史的なユースケースについて概説します。
LLMの力を活用する
LLMは、ChatGPTがリリース後わずか2ヶ月で2023年1月に1億人以上のアクティブユーザーに達し、史上最も急成長した消費者向けアプリケーションとして公衆の注目を集めたことから、MLの新しい応用を探しているビジネスの焦点となっています2。ただし、LLMはMLの分野で新しい技術ではありません。これまでに、感情分析、コーパスの要約、キーワードの抽出、音声の翻訳、テキストの分類など、NLPのタスクを実行するために広く使用されてきました。
テキストの連続的な性質により、再帰ニューラルネットワーク(RNN)はNLPモデリングの最先端技術でした。具体的には、エンコーダーデコーダーネットワークアーキテクチャは、任意の長さの入力を受け取り、任意の長さの出力を生成できるRNN構造を作成するために定式化されました。これは、入力と出力の間に単語の数が異なる翻訳などのNLPタスクにとって理想的でした。Transformerアーキテクチャ(Vaswani、2017)はエンコーダーデコーダーの大幅な改良であり、入力および出力のフレーズの異なる単語に注意を集中できる自己注意の概念を導入しました。通常のエンコーダーデコーダーでは、モデルは各単語を同一の方法で解釈します。モデルは入力フレーズの各単語を逐次処理するにつれて、フレーズの終わりまでには始めの時点での意味情報が失われる可能性があります。自己注意メカニズムは、エンコーダーブロックとデコーダーブロックの両方に注意層を追加することで、特定の単語を生成する際に入力フレーズの特定の単語に異なる重みを付けることができるようにしました。このように、Transformerモデルの基盤が生まれました。
Transformerアーキテクチャは、現在使用されている最もよく知られたLLMの2つの基盤となり、Bidirectional Encoder Representations from Transformers(BERT)4(Radford、2018)とGenerative Pretrained Transformer(GPT)5(Devlin、2018)です。 GPTモデルの後のバージョンであるGPT3とGPT4は、ChatGPTアプリケーションのエンジンです。LLMが非常に強力なのは、ULMFiTというプロセスを介して包括的なテキストコーパスからラベリングや前処理をほとんど必要とせずに情報を抽出できる能力です。この方法では、一般的なテキストを収集し、モデルを以前の単語に基づいて次の単語を予測するタスクでトレーニングします。ここでの利点は、トレーニングに使用される任意の入力テキストが、テキストの順序に基づいて事前にラベル付けされているということです。LLMは、インターネットスケールのデータから学習することが本当に可能です。たとえば、元のBERTモデルは、BookCorpusと英語全体のWikipediaテキストデータセットで事前トレーニングされました。
この新しいモデリングパラダイムは、2つの新しいコンセプトを生み出しました。Foundation Models(FMs)とGenerative AIです。従来の教師あり学習では、タスク固有のデータを使用してモデルをゼロからトレーニングするのが通常でしたが、LLMでは、広範なテキストデータセットから一般的な知識を抽出するために事前にトレーニングされ、その後、より小さなデータセット(通常数百のサンプル)で特定のタスクやドメインに適応させるために適応されます。新しいMLワークフローは、事前トレーニングされたモデルであるFoundation Modelから始まります。適切な基盤の上に構築することが重要であり、Amazonの新しいTitan FMsなどの選択肢が増えています。これらの新しいモデルは、出力が人間に解釈可能であり、入力データと同じデータ型であるため、生成モデルとしても考慮されます。過去のMLモデルが説明的であったのに対して、猫と犬の画像を分類するようなLLMは生成的であり、入力単語に基づいて次の単語セットを出力します。これにより、ChatGPTなどのインタラクティブなアプリケーションを駆動することができます。
Hugging Faceは、AWSと提携してFMsを民主化し、アクセスしやすく構築できるようにしました。Hugging FaceはTransformers APIを作成し、MLフレームワークを含むさまざまなトランスフォーマーアーキテクチャを統一し、Model Hubで事前トレーニングされたモデルの重みにアクセスできるようにしました。このポストの執筆時点で、Model Hubは20万以上のモデルに成長しました。次のセクションでは、証明コンセプト、ソリューション、および顧客の有毒なスピーチ分類のユースケースを解決するための基盤としてテストおよび選択されたFMsについて探求します。
AWS GAIICの証明コンセプト
AWS GAIICは、有毒な言語分類器を微調整するためにLLMの基盤モデルとしてBERTアーキテクチャを実験することを選びました。Hugging FaceのModel Hubから合計3つのモデルがテストされました:
- vinai/bertweet-base
- cardiffnlp/bertweet-base-offensive
- cardiffnlp/bertweet-base-hate
これらの3つのモデルアーキテクチャは、BERTweetアーキテクチャに基づいています。BERTweetはRoBERTaの事前トレーニング手順に基づいてトレーニングされています。RoBERTaの事前トレーニング手順は、BERTの事前トレーニングの複製研究の結果です。この研究では、ハイパーパラメータのチューニングとトレーニングセットのサイズの効果を評価し、BERTモデルのトレーニングのレシピを改善するための事前トレーニング方法を評価しました6(Liu、2019)。実験は、基礎アーキテクチャを変更せずにBERTのパフォーマンスを向上させる事前トレーニング方法を見つけることを目的としていました。研究の結論は、次の事前トレーニングの変更がBERTのパフォーマンスを大幅に向上させたというものでした。
- より大きなバッチとより多くのデータでモデルをトレーニングする
- 次の文予測目的を削除する
- より長いシーケンスでトレーニングする
- トレーニングデータに適用されるマスキングパターンを動的に変更する
bertweet-baseモデルは、RoBERTaの研究から前述の事前トレーニング手順を使用して、850百万の英語ツイートを使用して元のBERTアーキテクチャを事前トレーニングします。これは、英語のツイート向けに公開された最初の大規模言語モデルです。
ツイートを使用した事前トレーニングされたFMsは、主に次の2つの理論的な理由から使用ケースに適していると考えられました:
- ツイートの長さは、オンラインゲームチャットで見つかる不適切または有害なフレーズの長さと非常に似ています
- ツイートは、ゲームプラットフォームで見つかる人口と非常に多様なユーザーからなる人口と類似しています
AWSは、まずBERTweetを顧客のラベル付きデータでファインチューニングしてベースラインを得ることを決定しました。次に、bertweet-base-offensiveとbertweet-base-hateの2つの他のFMsを選択しました。これらは、より関連性の高い有害なツイートをさらに事前トレーニングするために使用され、より高い精度を得ることができます。bertweet-base-offensiveモデルは、ベースのBertTweet FMを使用し、さらに14,100件のアノテーション付きツイートで事前トレーニングされ、攻撃的と見なされたツイート7(Zampieri 2019)です。bertweet-base-hateモデルもベースのBertTweet FMを使用していますが、さらに19,600件のヘイトスピーチと見なされたツイート8(Basile 2019)で事前トレーニングされています。
PoCモデルの性能をさらに向上させるために、AWS GAIICは2つの設計上の決定を行いました:
- テキストが有害かどうかをバイナリ分類する最初のモデルと、顧客が定義した有害なタイプに基づいてテキストを分類する細かいモデルの2段階の予測フローを作成しました。最初のモデルがテキストを有害と予測した場合にのみ、2番目のモデルに渡されます。
- トレーニングデータを拡張し、顧客から受け取った元の100サンプルに加えて、パブリックなKaggleの競技(Jigsaw Toxicity)からサードパーティがラベル付けした有害なテキストのサブセットを追加しました。Jigsawのラベルを関連する顧客定義の有害性ラベルにマッピングし、トレーニングデータとして80%、テストデータとして20%に分割してモデルを検証しました。
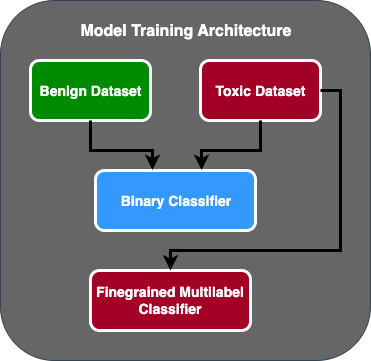
AWS GAIICは、ファインチューニングの実験を実行するためにAmazon SageMakerノートブックを使用し、bertweet-base-offensiveモデルが検証セットで最高のスコアを達成したことを確認しました。次の表は、観測されたメトリックスコアをまとめたものです。
| モデル | 精度 | 再現率 | F1 | AUC |
| バイナリ | .92 | .90 | .91 | .92 |
| 細かい | .81 | .80 | .81 | .89 |
この時点から、GAIICはPoCをAWS ProServe ML Delivery Teamに引き継ぎ、PoCを本番化しました。
AWS ProServe ML Delivery Teamの解決策
モデルアーキテクチャを本番化するために、AWS ProServe ML Delivery Team(MLDT)は、スケーラブルでメンテナンスが容易なソリューションを作成するよう顧客から依頼されました。2段階モデルアプローチのいくつかのメンテナンス上の課題がありました:
- モデルは、モデルの監視量が2倍になるため、再トレーニングのタイミングが一貫しなくなります。あるモデルの再トレーニングが他のモデルよりも頻繁に必要な場合があります。
- 1つのモデルと比較して2つのモデルを実行することによるコストの増加。
- 推論の速度が遅くなり、推論が2つのモデルを通過するためです。
これらの課題に対処するために、AWS ProServe MLDT は、2段階のモデルアーキテクチャを単一のモデルアーキテクチャに変換しながら、2段階アーキテクチャの精度を維持する方法を見つけなければなりませんでした。
解決策は、まず顧客により多くのトレーニングデータを要求し、その後、bertweet-base-offensive モデルをすべてのラベル(非有毒サンプルも含む)でファインチューニングして、1つのモデルに統合することでした。そのアイデアは、より多くのデータで1つのモデルをファインチューニングすることで、2段階のモデルアーキテクチャを少ないデータでファインチューニングする結果と同様の結果が得られるというものです。2段階のモデルアーキテクチャをファインチューニングするために、AWS ProServe MLDT は、事前学習済みモデルのマルチラベル分類ヘッドを更新して非有毒クラスを表す1つの追加ノードを含めました。
以下は、Hugging Face モデルハブの transformers プラットフォームを使用して、事前学習済みモデルをファインチューニングし、モデルのマルチラベル分類ヘッドを予測したいクラスの数に変更するコードのサンプルです。AWS ProServe MLDT は、ファインチューニングの基礎としてこの設計図を使用しました。トレーニングデータと検証データが準備され、正しい入力形式であることを前提としています。
まず、Python モジュールと Hugging Face モデルハブからの事前学習済みモデルをインポートします:
# Imports.
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
DataCollatorWithPadding,
PreTrainedTokenizer,
Trainer,
TrainingArguments,
)
# Load pretrained model from model hub into a tokenizer.
model_checkpoint = “cardiffnlp/bertweet-base-offensive”
tokenizer = AutoTokenizer.from_pretrained(checkpoint)次に、事前学習済みモデルを読み込んでファインチューニングの準備をします。これは、有毒カテゴリの数とすべてのモデルパラメータが定義されるステップです:
# Load pretrained model into a sequence classifier to be fine-tuned and define the number of classes you want to classify in the num_labels parameter.
model = AutoModelForSequenceClassification.from_pretrained(
model_checkpoint,
num_labels=[クラスの数]
)
# Set your training parameter arguments. The below are some key parameters that AWS ProServe MLDT tuned:
training_args = TrainingArguments(
num_train_epochs=[入力を入力してください]
per_device_train_batch_size=[入力を入力してください]
per_device_eval_batch_size=[入力を入力してください]
evaluation_strategy="epoch",
logging_strategy="epoch",
save_strategy="epoch",
learning_rate=[入力を入力してください]
load_best_model_at_end=True,
metric_for_best_model=[入力を入力してください]
optim=[入力を入力してください],
)モデルのファインチューニングは、トレーニングデータセットと検証データセットへのパスを入力することから始まります:
# Finetune the model from the model_checkpoint, tokenizer, and training_args defined assuming train and validation datasets are correctly preprocessed.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=[入力を入力してください],
eval_dataset=[入力を入力してください],
tokenizer=tokenizer,
data_collator=data_collator,
)
# Finetune model command.
trainer.train()AWS ProServe MLDT は、約5,000件の追加のラベル付きデータサンプルを受け取りました。そのうち3,000件は非有毒で、2,000件は有毒です。彼らはこれらのデータを PoC の5,000件のサンプルに追加して、同じ80% のトレーニングセット、20% のテストセットの方法を使用して新しい1段階モデルをファインチューニングしました。以下の表は、パフォーマンススコアが2段階モデルとほぼ同等であることを示しています。
| モデル | 適合率 | 再現率 | F1 | AUC |
| bertweet-base (1-Stage) | .76 | .72 | .74 | .83 |
| bertweet-base-hate (1-Stage) | .85 | .82 | .84 | .87 |
| bertweet-base-offensive (1-Stage) | .88 | .83 | .86 | .89 |
| bertweet-base-offensive (2-Stage) | .91 | .90 | .90 | .92 |
ワンステージモデルアプローチは、精度をわずか3%減らすだけで、コストとメンテナンスの改善を実現しました。トレードオフを考慮した結果、顧客はAWS ProServe MLDTを選択し、ワンステージモデルを本番環境に導入しました。
AWS ProServe MLDTは、より多くのラベル付きデータで1つのモデルを微調整することで、顧客のモデル精度の基準を満たすソリューションを提供し、メンテナンスの容易さを実現し、コストを削減し、堅牢性を向上させることができました。
結論
大規模なゲーム顧客は、コミュニケーションチャネル内で有害な言語を検出し、社会的責任を持つゲーム環境を促進する方法を探していました。AWS GAIICは、有害な言語を検出するためにLLMを微調整することで、有害な言語検出器のPoCを作成しました。そして、AWS ProServe MLDTは、モデルトレーニングのフローを2段階から1段階に変更し、LLMを本番環境でスケールアップして顧客が使用できるようにしました。
この投稿では、AWSがLLMを微調整してこの顧客のユースケースを解決する効果と実用性を示し、ファウンデーションモデルとLLMの歴史についてのコンテキストを共有し、AWS Generative AI Innovation CenterとAWS ProServe ML Delivery Teamの間のワークフローを紹介しています。このシリーズの次の投稿では、AWS ProServe MLDTがSageMakerを使用して生成されたワンステージモデルを本番環境に導入する方法について詳しく説明します。
AWSと共にGenerative AIソリューションを構築したい場合は、GAIICにお問い合わせください。彼らはあなたのユースケースを評価し、Generative-AIベースのPoCを作成し、その結果を本番環境に実装するためにAWSとの協力を延長するためのオプションを提供します。
参考文献
- ゲーマーの人口統計:世界で最も人気のある趣味に関する事実と統計
- ChatGPTは最も急成長するユーザーベースの記録を樹立 – アナリストノート
- Vaswani et al.、「Attention is All You Need」
- Radford et al.、「Improving Language Understanding by Generative Pre-Training」
- Devlin et al.、「BERT:言語理解のための深層双方向トランスフォーマーの事前トレーニング」
- Yinhan Liu et al.、「RoBERTa:ロバストに最適化されたBERT事前トレーニングアプローチ」
- Marcos Zampieri et al.、「SemEval-2019タスク6:ソーシャルメディアでの攻撃的な言語の識別とカテゴリ化(OffensEval)」
- Valerio Basile et al.、「SemEval-2019タスク5:Twitterでの移民と女性へのヘイトスピーチの多言語検出」
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「CT2Hairに会ってください:ダウンストリームグラフィックスアプリケーションで使用するために適した高精細な3Dヘアモデルを完全自動で作成するフレームワーク」
- 「Jupyter AIに会おう:マジックコマンドとチャットインターフェースでジェネラティブ人工知能をJupyterノートブックにもたらす新しいオープンソースプロジェクト」
- 「OpenAIを任意のLLM(Language Model)と交換し、すべてを1行で行うことを想像してください!Genoss GPTに会ってください:OpenAI SDKと互換性のあるAPIで、GPT4ALLなどのオープンソースモデルをベースにして構築されています」
- メタのラマ2:商業利用のためのオープンソース言語モデルの革命化
- 「2023年に機械学習とコンピュータビジョンの進歩について最新情報を入手する方法」
- Mozilla Common Voiceでの音声言語認識-第II部:モデル
- 「プロジェクトRumiにご参加ください:大規模言語モデルのための多言語パラ言語的プロンプティング」






