「AVIS内部:Googleの新しい視覚情報検索LLM」
AVIS内部:Googleの新しい視覚情報検索LLM
新しいモデルは、ウェブ検索、コンピュータビジョン、画像検索と組み合わせてLLMを使用し、驚くべき結果を達成します。

最近、AIに特化した教育ニュースレターを開始しました。現在、16万人以上の購読者がいます。TheSequenceは、5分で読める、ノン・ヒュープ、ノン・ニュースなどのML指向のニュースレターです。目標は、機械学習のプロジェクト、研究論文、概念について最新の情報を提供することです。以下のリンクから購読して試してみてください:
TheSequence | Jesus Rodriguez | Substack
機械学習、人工知能、データの進展について最新情報を入手するための最良の情報源…
thesequence.substack.com
マルチモーダリティは、ファンデーションモデルの研究の中で最も注目されている分野の1つです。GPT-4などのモデルがマルチモーダルなシナリオで驚異的な進展を示しているにもかかわらず、この領域にはまだ多くの課題が残っています。その中でも、特定の質問に答えるために外部の知識が必要な視覚情報検索タスクは、その1つです。Google Researchは、「大規模言語モデル(LLM)を用いた自律型視覚情報検索」という論文で、視覚情報の検索に関連するタスクで興味深い結果を得るための新しい手法を提案しています。この手法は、以下の3つの異なるカテゴリのツールとLLMを統合しています:1)コンピュータビジョンツールは、画像から視覚データを抽出するために使用されます。2)ウェブ検索ツールは、広範なオープンワールドの知識や事実から情報を取得するために利用されます。3)画像検索ツールは、視覚的に類似した画像に関連するメタデータから適切な詳細を抽出するために活用されます。これらの3つの組み合わせにより、LLMによるプランナーが各ステップごとに適切なツールとクエリを決定する技術が実現します。さらに、LLMパワードのリーズナーがツールの出力を検証し、重要な洞察を抽出します。プロセス全体で、機能的なメモリモジュールが情報を保持し保存します。
背景
GoogleのAVISのアイデアは、最近の研究領域に基づいています。Chameleon、ViperGPT、MM-ReActなどの最近の探索では、LLMにマルチモーダルな入力の補完ツールを組み込むことに焦点を当てています。これらのシステムは、計画と実行の2つのステージで動作します。計画では、質問を構造化された指示に分解することが含まれ、実行ではツールを使用して情報を収集します。このアプローチは、初歩的なタスクでは成功を収めていますが、複雑な現実世界のシナリオに直面するとしばしば失敗します。
- 「言語の壁を乗り越える:アフリカの言語のためのAIツールの推進」
- 「機械学習 vs AI vs ディープラーニング vs ニューラルネットワーク:違いは何ですか?」
- Google AIは、スケールで事前に訓練されたニューラルネットワークを剪定するための最適化ベースのアプローチ、CHITAを紹介します

また、WebGPTやReActなどのLLMを自律エージェントとして利用することにも関心が集まっています。これらのエージェントは環境との対話を行い、リアルタイムのフィードバックに基づいて適応し目標を達成します。ただし、これらの手法では、各段階で利用できるツールの種類に制約がないため、検索空間が広範になります。その結果、最も高度なLLMでも無限ループに陥ったり、エラーを伝播したりすることがあります。AVISメソッドは、ユーザースタディから得られた人間の意思決定に影響を受けたガイド付きLLMアプリケーションによって、この問題に対処します。
InfoseekやOK-VQAなどのデータセット内の多数の視覚クエリは、しばしば人間の応答者にとっても課題となり、多様なツールやAPIの支援を必要とします。外部ツールを使用する際の人間の意思決定を理解するために、ユーザースタディが実施されました。
参加者はAVISメソッドで使用されるPALI、PaLM、ウェブ検索などと同じセットのツールを装備しました。入力画像、質問、切り抜かれたオブジェクト画像、および画像検索の結果へのリンクが提供されました。これらのボタンは、切り抜かれたオブジェクト画像に関するさまざまな情報を提供しました。例えば、知識グラフ内のエンティティ、類似画像のキャプション、関連する商品タイトル、および同一の画像の説明などです。
ユーザーのアクションと出力は記録され、AVISシステムの参考として2つの重要な方法で使用されました。まず、ユーザーの連続した意思決定のシーケンスを分析して移行グラフが構築されました。このグラフは、各状態で利用可能なアクションの範囲を明示し、離散的な状態を示しています。たとえば、初期状態では、システムはPALIのキャプション、PALIのVQA、またはオブジェクト検出の3つのアクションに制限されます。次に、人間の意思決定の例をプランナーとリーズナー内で利用して、AVISシステムを導くための関連する文脈のインスタンスを与え、パフォーマンスと効果を高めました。
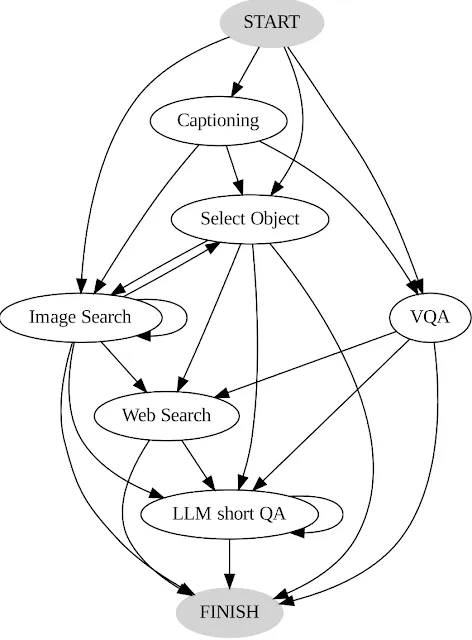
AVISの内部
AVISでは、Google Researchは視覚情報を求めるクエリに特化した動的アプローチを採用しています。この方法論は、システムのアーキテクチャ内の3つの基本的なコンポーネントで構成されています。1) 最初に、プランナーが指揮を取り、適切なAPI呼び出しと処理の対応するクエリを包括する次のアクションを解読します。2) 並行して、作業メモリモジュールがあり、APIの実行から生じる結果に関するデータを忠実に保存しています。3) 最後に、リーズナーがAPI呼び出しから生成された結果を精査するという重要な役割を果たします。この役割には、取得した情報が十分な価値があるかどうかを評価し、確定的な回答を提供できるか、さらなるデータの取得が必要かどうかを判断することが含まれます。
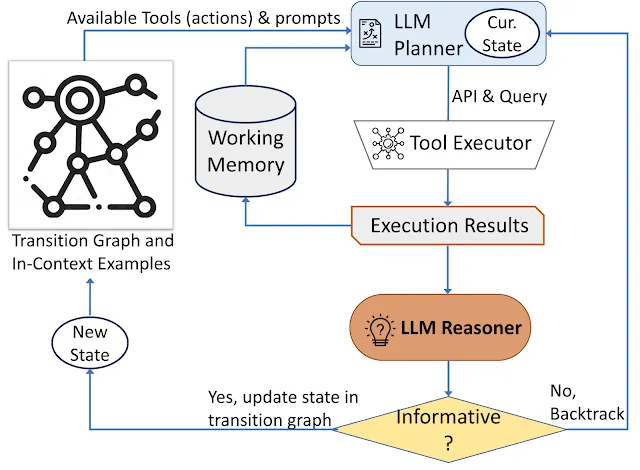
プランナーは、ツールの選択と対応するクエリの判断に関して、判決を下すたびに一連の手順に乗り出します。現在の状態に合わせて、プランナーは可能な次のアクションの配列を展開します。潜在的なアクションの幅は広範であり、検索空間での課題を提起します。このジレンマに対処するために、プランナーは遷移グラフを参照し、関係のないアクションを考慮から除外します。以前に実行され、作業メモリに記憶されたアクションも除外されます。
その後、プランナーは、ユーザースタディ中の人間の参加者によって以前に行われた判断から派生した関連する文脈のインスタンスの配列を組み立てます。これらのインスタンスと作業メモリにカプセル化されたデータの貯蔵庫を備えたプランナーは、プロンプトを作成します。このプロンプトはLLMに送られ、構造化された応答を提供します。この出力に基づいて、次にアクティベートするツールと関連するクエリが決定されます。この設計図により、プランナーはプロセス全体で再帰的にトリガーされることにより、初期のクエリに対処するために徐々に進行する動的な意思決定を実現します。
リーズナーは、ツールの実行結果を分析するために介入します。リーズナーは貴重な洞察を得て、ツールの出力が情報提供、情報不足、または結果的な応答のいずれに属するかを識別します。この手法は、リーズニングタスクのために適切なプロンプトと文脈のインスタンスをLLMと組み合わせることに依存しています。リーズナーが応答を生成する準備ができていると判断した場合、確定的な回答を適切に発行し、タスクを終了します。ツールの出力が無益である場合は、リーズナーは現在の状態に基づいて代替行動の選択のためにプランナーに委ねます。ツールの出力が示唆に富んでいる場合、リーズナーは状態のシフトを組織し、プランナーの権限を復活させ、新しい状態に基づいた新たな決定を促します。
結果
Googleは、InfoseekやOK-VQAなどの視覚情報検索のベンチマークでAIVSを評価しました。その結果は非常に印象的であり、微調整なしでも50%以上の精度を達成しました。

AVISの研究は、視覚情報検索モデルの新しいフレームワークに異なるアイデアを組み合わせています。Googleによってリリースされる新しいマルチモーダル基盤モデルの一環としてAVISが組み込まれることに驚かないでください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 大規模な言語モデルを使用した自律型の視覚情報検索
- 「Lineが『japanese-large-lm』をオープンソース化:36億パラメータを持つ日本語言語モデル」
- この中国のAI論文では、「物理的なシーンの制約を持つ具体的な計画におけるタスクプランニングエージェント(TaPA)」が提案されています
- Google AIによるコンテキストの力を解き放つ:プレフィックスLMと因果LMの対決におけるインコンテキスト学習
- 「FraudGPTと出会ってください:ChatGPTのダークサイドの双子」
- 「ビデオ編集はもはや難問ではありません:INVEはインタラクティブなニューラルビデオ編集を可能にするAI手法です」
- 大規模な言語モデルを効率的に提供するためのフレームワーク






