AutoMLのジレンマ
AutoMLのジレンマ
インフラストラクチャエンジニアの視点
AutoMLは過去数年間で注目されてきました。そのハイプは非常に高まり、人間の機械学習の専門家を置き換えるという野心さえもありました。しかし、長い間採用が進まなかったため、AutoMLへの期待は急速に低下しており、これは厳密にはGartnerの曲線に従っています。
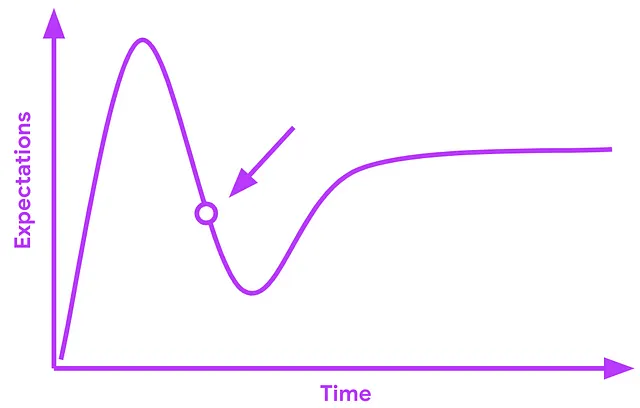
この時点で、私たちはAutoMLの現在の状況を理解し、明日のための方法を見つける必要があります。私はAutoKerasとKerasTunerという2つのAutoMLライブラリを開発したソフトウェアエンジニアです。この記事では、AutoMLとは何か、そしてAutoMLが大規模な採用を妨げていた欠落している要素をお手伝いします。
AutoMLとは何ですか?
限られた機械学習の専門知識を持つ人が現実世界の画像分類の問題に直面していると想像してみてください。彼らは問題を明確に定義し、トレーニングデータを利用できます。この場合、AutoMLは訓練済みの機械学習モデルの構築を支援することができます。
入力と出力の観点から、AutoMLは以下のことを行います。
- 「CodiumAIに会ってください:開発者のための究極のAIベースのテストアシスタント」
- スタビリティAIが安定したオーディオを導入:テキストプロンプトからオーディオクリップを生成できる新しい人工知能モデル
- 「リソース制約のあるアプリケーションにおいて、スパースなモバイルビジョンMoEsが密な対応物よりも効率的なビジョンTransformerの活用を解き放つ方法」
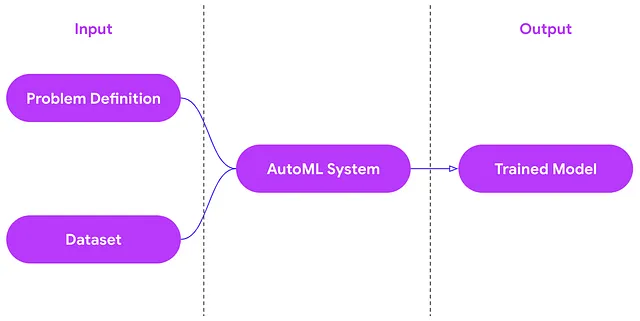
問題の定義とトレーニングデータを受け取り、デプロイ準備ができた訓練済みの機械学習モデルを出力します。例えば、画像分類のタスクが与えられた場合、トレーニング画像データセットを入力として、訓練済みの画像分類モデルを出力します。
AutoMLが自動化しようとする手順には、データの前処理、特徴抽出、モデルの選択、ハイパーパラメータのチューニング、ニューラルアーキテクチャの検索、モデルのトレーニング、テストデータでの推論、データの後処理などが含まれる場合があります。
要約すると、自動化された機械学習(AutoML)は、現在利用可能なさまざまな洗練された機械学習モデルとトレーニング技術と、実世界の問題を解決する可能性があるものとの「ギャップ」を埋めるために、自動化された「エンドツーエンドのソリューション」を提供することを試みます。
AutoMLはどのように機能しますか?
与えられたタスクとデータセットに対して、AutoMLシステムは関連する一連の手法やモデルを効率的に試し、最適なものを選択します。
以下のステップを含むforループとして考えることができます:
- モデルの設定を生成する。
- その設定でモデルを作成し、訓練する。
- 検証データでモデルを評価する。
- 評価結果から学び、設定を改善する。
AutoMLシステム内のスマートエージェントは、設定を生成し、評価結果を学習することで徐々に改善していきます。
スマートエージェントとして多くのアルゴリズムが使用されることがありますが、ベイジアン最適化や強化学習などがあります。しかし、スマートエージェントの核心は、関数近似と関数最大化です。それぞれについて見てみましょう。
- 関数近似。スマートエージェントは、モデルの設定とモデルのパフォーマンスの関係を学習しようとしています。数学的な言葉で言えば、関数 y=f(x) を学習しようとしています。ここで x はモデルの設定であり、y はモデルのパフォーマンスです。
- 関数最大化。スマートエージェントの最終目標は、最もモデルのパフォーマンスが良い設定を見つけることです。つまり、f(x) の値が最大となる x を見つけたいのです。つまり、argmax f(x) を見つけたいのです。
AutoMLの影響
広く採用されれば、AutoMLの影響は非常に大きいです。機械学習の専門家の生産性を劇的に向上させることができます。彼らはもはやモデル構成の細かな調整に多くの時間を費やす必要はありません。タスクを注意深く定義し、検索空間を手動で制約するだけで、より速く結果を得ることができるかもしれません。
今日のAutoMLは何ができるのか?
現在のAutoMLの応用範囲はかなり限定的であり、主に以下の2つの側面に焦点を当てています。
- クイックトライアウト。一部の機械学習エンジニアは、自分のタスクとデータセットで素早く機械学習を試したい場合があります。彼らはAutoMLを出発点として使用することができます。比較的良い結果を得た場合、手動でMLソリューションをさらに開発することができます。
- ML教育。MLを学び始めたばかりの学生は、AutoMLを使用してMLの可能性を理解することができます。彼らはMLソリューションのすべての詳細に触れる必要はありませんが、プロセスの概要を素早く把握することができます。
将来のAutoMLの可能性
AutoMLの将来の可能性に対する期待は、現在の実現可能性よりもはるかに高いです。以下に3つの主要な目標にまとめました。
- ML専門家向け: データサイエンティストや機械学習エンジニアの生産性を向上させる。
- ドメインエキスパート向け: 医師や機械工学者などのドメインエキスパートが、自分の問題にAutoMLを簡単に適用できるようにする。
- プロダクションエンジニア向け: 見つかったソリューションを簡単に本番環境に展開できるようにする。
AutoMLの問題点
現在のAutoMLの状況と将来の展望を学びましたが、問題はどのように解決されるのでしょうか。現在直面している問題を以下の3つのカテゴリにまとめます。これらの問題が解決されると、AutoMLは大規模な普及を達成するでしょう。
問題1: ビジネスインセンティブの不足
モデリングは取るに足らないものであり、データ収集、クリーニング、検証、モデルの展開、モニタリングなどを含む使いやすい機械学習ソリューションを開発することと比較してトリビアルです。これらのステップをすべて担当する人を雇う余裕がある企業にとって、モデリングに対する費用オーバーヘッドは取るに足らないものです。モデリングのための専門家チームをほとんど費用オーバーヘッドなく結成できる場合、彼らはAutoMLのような新しい技術を試すことには関心を持ちません。
そのため、他のすべてのステップのコストが最低限に抑えられるまで、人々はAutoMLの使用を開始することはありません。つまり、モデリングのための人材のコストが重要な要素になった時です。それでは、この目標に向けたロードマップを見ていきましょう。
多くのステップが自動化される可能性があります。クラウドサービスが進化するにつれ、データの検証、モニタリング、サービス提供など、機械学習ソリューションの開発における多くのステップが自動化される可能性があることに楽観的な姿勢を持つべきです。ただし、自動化できない重要なステップが1つあります。それはデータラベリングです。機械自体が自己学習できない限り、人間が機械が学習するためのデータを準備する必要があります。
データラベリングが最終的なコストの主要要素になるかもしれません。データラベリングのコストを削減できれば、彼らはビジネスインセンティブを持って、モデリングのコストを削減するためにAutoMLを使用するでしょう。モデリングのコストが機械学習ソリューションの唯一のコストになるからです。
長期的な解決策: 残念ながら、データラベリングのコストを削減する究極の解決策は現在存在しません。私たちは将来の研究の突破を頼りにする必要があります。「少量のデータでの学習」に関する研究の一つの可能性として、転移学習への投資があります。
ただし、転移学習に取り組むことに関心を持つ人は少ないです。このトピックについては発表するのが難しいためです。詳細については、このビデオ「Why most machine learning research is useless」をご覧いただけます。
短期的な解決策: 短期的には、事前学習された大規模なモデルを少量のデータで微調整することができます。これは転移学習と少量のデータでの学習の簡単な方法です。
まとめると、クラウドサービスによって機械学習ソリューションのほとんどのステップが自動化され、AutoMLは事前学習モデルを使用して小規模なデータから学習し、データラベリングのコストを削減することができれば、ビジネスインセンティブが生まれ、MLモデリングのコストを削減するためにAutoMLを適用する動機が生まれるでしょう。
問題2: メンテナンス性の不足
すべての深層学習モデルは信頼性に欠けるわけではありません。モデルの振る舞いは時に予測不可能です。モデルが特定の出力を生成する理由を理解するのは難しいです。
エンジニアがモデルを維持しています。今日、問題が発生した場合、エンジニアがモデルを診断して修正する必要があります。会社は深層学習モデルに対して変更を行いたい場合、エンジニアとコミュニケーションを取ります。
AutoMLシステムはエンジニアよりも対話が難しいです。今日、AutoMLシステムには事前に数学的に明確に定義された目標のシリーズを与えて深層学習モデルを作成するための一発法としてしか使用できません。実際のモデルの使用中に問題が発生した場合、それを修正するのに役立ちません。
長期的な解決策:HCI(人間コンピュータインタラクション)に関する研究が必要です。AutoMLによって作成されるモデルがより信頼性のあるものになるよう、目標を定義するより直感的な方法が必要です。また、新しい要件に合わせてモデルを更新したり、問題を修正したりするためにAutoMLシステムとの対話をより良くする方法も必要です。異なるモデルをすべて検索するために多くのリソースを使わないようにするためにも。
短期的な解決策:FLOPSやパラメータ数などのより多くの目標タイプのサポート。モデルのサイズや推論時間を制限するための加重混同行列の対処方法。モデルに問題が発生した場合、関連する目標をAutoMLシステムに追加して新しいモデルを生成することができます。
問題3:インフラストラクチャのサポートの不足
AutoMLシステムの開発時に、今日存在しない深層学習フレームワークから必要な機能がいくつか見つかりました。これらの機能がないと、AutoMLシステムの能力が制限されます。以下にまとめます。
まず、柔軟な統一APIを備えた最先端のモデル。効果的なAutoMLシステムを構築するためには、大量の最先端モデルが必要で、これらを組み合わせて最終的な解決策を組み立てる必要があります。モデルプールは定期的に更新され、適切にメンテナンスされる必要があります。さらに、モデルを呼び出すためのAPIは非常に柔軟で統一されている必要があります。これにより、AutoMLシステムからプログラム的に呼び出すことができます。これらはエンドツーエンドのMLソリューションを構築するためのビルディングブロックとして使用されます。
この問題を解決するために、私たちはKerasCVとKerasNLPを開発しました。これは、Kerasを基にしたコンピュータビジョンおよび自然言語処理タスク用のドメイン固有のライブラリです。これらは最先端モデルをシンプルでクリーンで柔軟なAPIにラップし、AutoMLシステムの要件を満たします。
次に、モデルの自動ハードウェア配置。AutoMLシステムは、複数のGPU上の複数のマシンに分散して大規模なモデルを構築およびトレーニングする必要がある場合があります。与えられた計算リソースのどの量でも実行可能である必要があります。これには、モデルの分散(モデル並列処理)またはトレーニングデータの分散(データ並列処理)の方法をハードウェアに合わせて動的に決定する必要があります。
驚くべきことに、今日のどの深層学習フレームワークも複数のGPU上にモデルを自動的に分散することはできません。各テンソルに対して明示的にGPU割り当てを指定する必要があります。ハードウェア環境が変化した場合、例えばGPUの数が減少した場合、モデルコードが機能しなくなる可能性があります。
この問題にはまだ明確な解決策が見えません。深層学習フレームワークが進化するまで、モデル定義コードとテンソルハードウェア配置のコードが独立している必要があります。
第三に、モデルの展開の容易さ。AutoMLシステムによって生成された任意のモデルは、クラウドサービスやエンドデバイスなどに展開する必要がある場合があります。展開の前に特定のハードウェア向けにモデルを再実装するためにエンジニアを雇う必要があると仮定しましょう。これは現在のケースで最もありそうです。なぜ最初から同じエンジニアを使用せずにAutoMLシステムを使用するのでしょうか?
人々は現在この展開の問題に取り組んでいます。例えば、Modularはすべてのモデルのための統一された形式を作成し、主要なハードウェアプロバイダーと深層学習フレームワークをこの表現に統合しました。モデルが深層学習フレームワークで実装された場合、この形式にエクスポートしてそれをサポートするハードウェアに展開することができます。
結論
私たちが議論したすべての問題を考えると、私はAutoMLについては長期的な展望を持っています。自動化と効率性が深層学習開発の未来であるため、これらの問題は最終的に解決されると信じています。現在はまだAutoMLが大規模に採用されていませんが、機械学習の革命が続く限り、それは採用されるでしょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles