「AWS 上の生成型 AI を使用して、放射線学のレポートの所見から自動的に印象を生成します」
Automatically generate impressions from radiology report findings using AI generated on AWS.
放射線科のレポートは、放射線画像検査の結果を説明し解釈する包括的で詳細な文書です。通常のワークフローでは、放射線科医が画像を監督し、読み取り、解釈し、その後、主な所見を簡潔にまとめます。要約(もしくは感想)はレポートの最も重要な部分であり、臨床医や患者が臨床的な意思決定に必要な情報を含むレポートの重要な内容に焦点を当てるのに役立ちます。明確かつ影響力のある感想を作成するには、単に所見を再述する以上の努力が必要です。そのため、このプロセス全体は労力が多く、時間がかかり、エラーが起こりやすいものです。医師が簡潔で情報量のある放射線科レポートの要約を書くための十分な専門知識を蓄積するには、数年の訓練が必要とされることがしばしばあります。このプロセスを自動化することの重要性をさらに強調しています。また、レポートの所見の要約を自動的に生成することは、放射線科の報告にとって重要です。これにより、レポートを人間が読みやすい言語に翻訳することができ、患者が長くわかりにくいレポートを読む負担を軽減することができます。
この問題を解決するために、私たちは生成AIの使用を提案します。生成AIは、会話、物語、画像、ビデオ、音楽など、新しいコンテンツやアイデアを作成できるAIの一種です。生成AIは、機械学習(ML)モデルによって駆動されており、非常に大規模なモデルであり、膨大なデータに事前学習されたものであり、ファウンデーションモデル(FM)とも呼ばれています。機械学習(特にトランスフォーマベースのニューラルネットワークアーキテクチャの発明)の最近の進歩により、数十億のパラメータまたは変数を含むモデルが登場しました。この記事で提案されている解決策では、放射線科レポートの所見に基づいて要約を生成するために、事前学習された大規模言語モデル(LLM)のファインチューニングを使用します。
この記事では、AWSのサービスを使用して、公開されているLLMをファインチューニングして放射線科レポートの要約のタスクを行う方法を示しています。LLMは、自然言語の理解と生成において驚異的な能力を示しており、さまざまなドメインやタスクに適応できるファウンデーションモデルとして機能します。事前学習モデルを使用することには、計算コストの削減、炭素フットプリントの削減、またゼロからモデルをトレーニングする必要がないため、最新のモデルを使用できるという利点があります。
私たちの解決策では、Amazon SageMaker JumpStartを使用してFLAN-T5 XL FMを使用しています。これは、アルゴリズム、モデル、およびMLソリューションを提供するMLハブです。Amazon SageMaker Studioのノートブックを使用して、これを実現する方法を示しています。事前学習モデルのファインチューニングは、特定のデータでさらなるトレーニングを行い、異なるが関連するタスクのパフォーマンスを向上させることを意味します。この解決策では、FLAN-T5 XLモデルのファインチューニングを行い、これはT5(テキストからテキストへの変換トランスフォーマ)の汎用LLMの強化バージョンです。T5は自然言語処理(NLP)のタスクを統一されたテキストからテキストへの形式に再構築し、入力のクラスラベルまたはスパンのいずれかの出力しか行えないBERTスタイルのモデルとは対照的です。このモデルは、MIMIC-CXRデータセットから取得した91,544件のフリーテキストの放射線科レポートに対する要約タスクのためにファインチューニングされています。
解決策の概要
このセクションでは、解決策の主要なコンポーネントについて説明します。タスクの戦略の選択、LLMのファインチューニング、結果の評価についても説明します。また、解決策のアーキテクチャと実装手順も示します。
タスクの戦略の特定
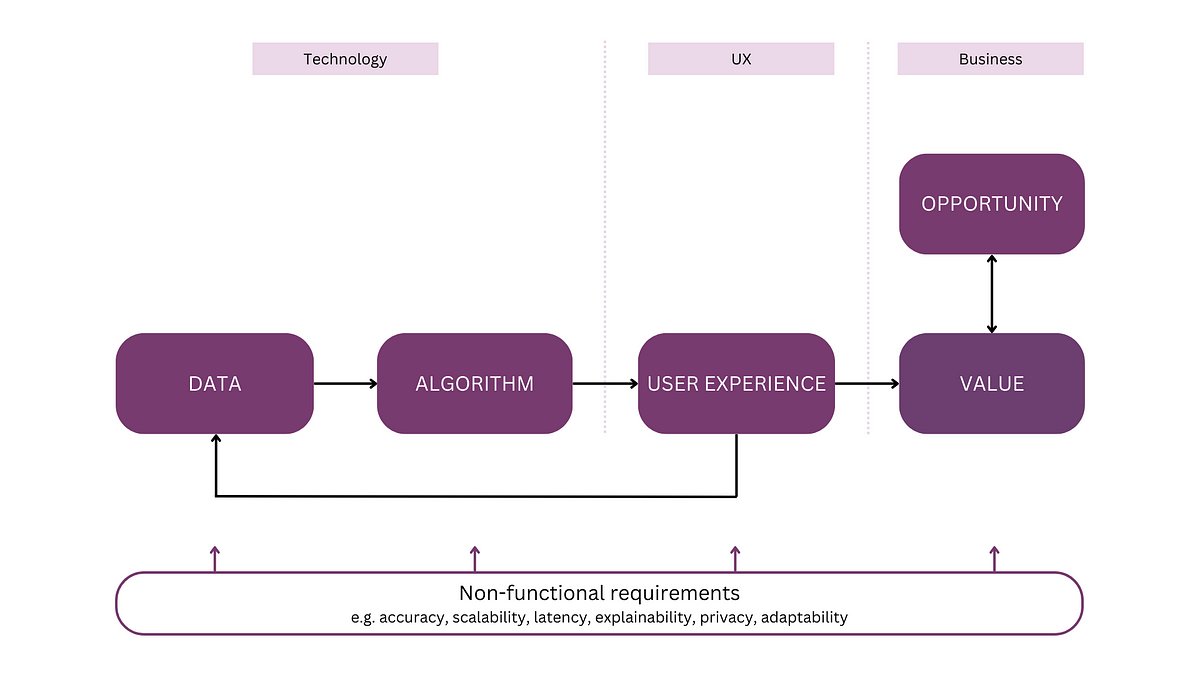
臨床報告書の要約を自動化するためのさまざまな戦略があります。例えば、臨床報告書の専門的な言語モデルをゼロから事前学習することができます。または、一般的な目的の言語モデルを直接ファインチューニングして臨床のタスクを実行することもできます。言語モデルをゼロからトレーニングすることが費用がかかりすぎる場合には、ファインチューニングされたドメイン非依存のモデルを使用することが必要になる場合もあります。この解決策では、放射線科レポートの要約の臨床タスクのためにFLAN-T5 XLモデルを使用し、ファインチューニングを行う後者のアプローチを示しています。以下の図は、モデルのワークフローを示しています。

典型的な放射線科レポートは、整理されて簡潔です。このようなレポートには通常、次の3つの主要なセクションがあります:
- 背景 – 患者の人口統計に関する一般的な情報を提供し、患者の臨床的な経歴や関連する病歴、検査手順の詳細などの情報を提供します
- 所見 – 詳細な検査診断と結果を提示します
- 感想 – 最も重要な所見の要約、所見の解釈、観察された異常に基づいた重要性と潜在的な診断の評価を簡潔にまとめます
放射線学レポートの所見セクションを使用して、解決策は医師の要約に対応する印象セクションを生成します。以下の図は、放射線学レポートの例です。

臨床タスクのための汎用LLMの微調整
このソリューションでは、FLAN-T5 XLモデルを微調整します(モデルのすべてのパラメータを微調整し、タスクに最適化します)。このモデルを微調整するために、公開されている胸部レントゲン写真のデータセットであるMIMIC-CXRを使用します。SageMaker Jumpstartを介してこのモデルを微調整するためには、{プロンプト、補完}のペア形式でラベル付きの例を提供する必要があります。この場合、MIMIC-CXRデータセットの元のレポートから{所見、印象}のペアを使用します。推論には、以下の例に示すようなプロンプトを使用します。

モデルは、64個の仮想CPUと488 GiBのメモリを持つ高速計算ml.p3.16xlargeインスタンスで微調整されます。バリデーションには、データセットの5%がランダムに選択されます。微調整とSageMakerトレーニングジョブの経過時間は、約38,468秒(約11時間)でした。
結果の評価
トレーニングが完了したら、結果を評価することが重要です。生成された印象の定量的分析には、ROUGE(Recall-Oriented Understudy for Gisting Evaluation)が使用されます。これは、要約の評価に最も一般的に使用される指標です。この指標は、自動的に生成された要約と参照または参照要約(人間が作成した)との間の重複を比較します。ROUGE1は、候補(モデルの出力)と参照要約の間のユニグラム(各単語)の重複を指します。ROUGE2は、候補と参照要約の間のバイグラム(2つの単語)の重複を指します。ROUGELは文レベルの指標であり、2つのテキストの最長共通部分列(LCS)を指します。テキスト内の改行は無視されます。ROUGELsumは要約レベルの指標です。この指標では、テキスト内の改行は無視されず、文の境界と解釈されます。次に、各ペアの参照と候補の文の間でLCSが計算され、union-LCSが計算されます。与えられたセットの参照と候補の文に対するこれらのスコアの集計には、平均値が計算されます。
手順とアーキテクチャ
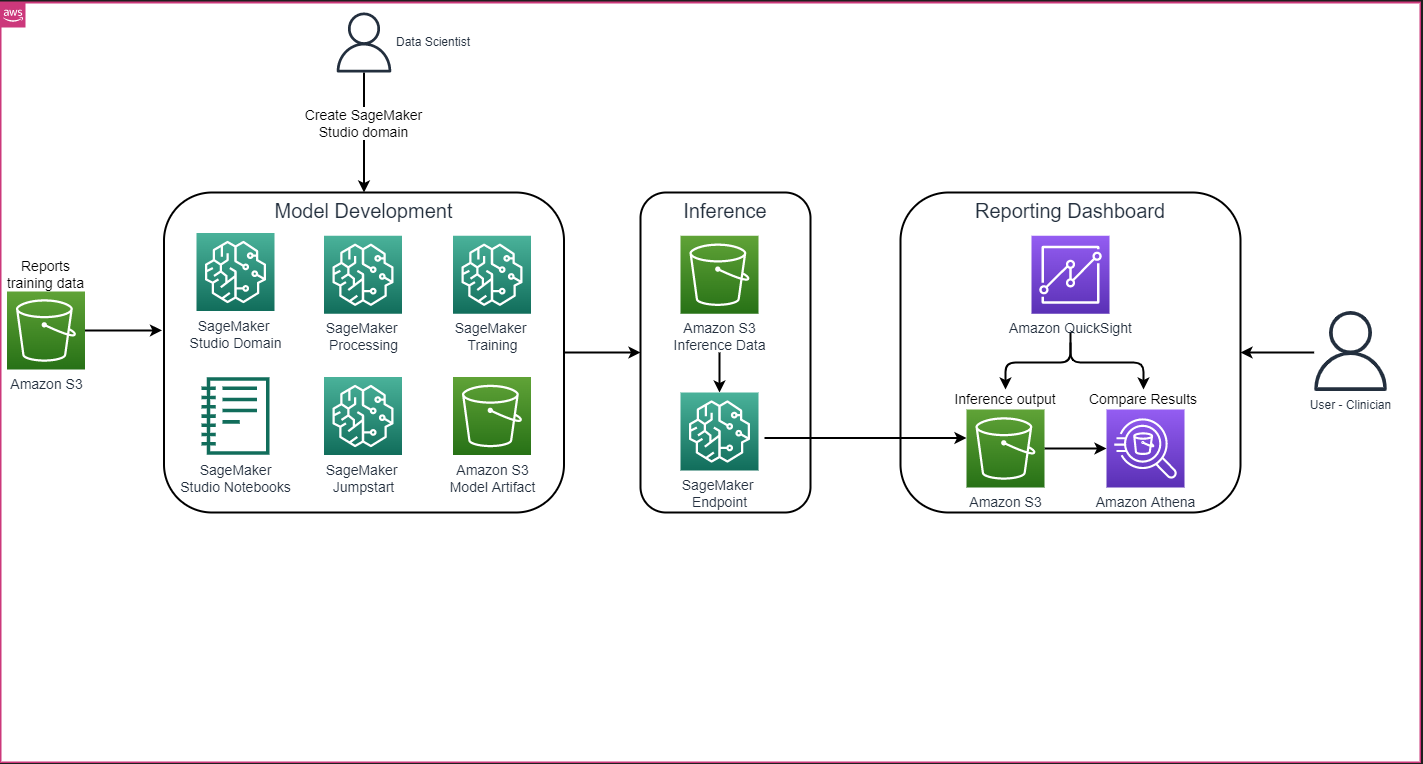
以下の図に示すような全体的なソリューションアーキテクチャは、主にSageMaker Studioを使用したモデル開発環境、SageMakerエンドポイントを使用したモデル展開、およびAmazon QuickSightを使用したレポートダッシュボードから構成されています。
次のセクションでは、SageMaker JumpStartで利用可能なLLMの微調整によるドメイン固有タスクの要約を、SageMaker Python SDKを使用して実演します。具体的には、以下のトピックについて説明します:
- 開発環境の設定手順
- モデルの微調整と評価に使用される放射線学レポートデータセットの概要
- SageMaker JumpStartを使用したFLAN-T5 XLモデルのプログラムによる微調整のデモンストレーション
- 事前学習済みモデルと微調整モデルの推論と評価
- 事前学習済みモデルと微調整モデルの結果の比較
このソリューションは、AWSのGitHubリポジトリで「Generating Radiology Report Impression using generative AI with Large Language Model on AWS」として利用可能です。
前提条件
開始するには、SageMaker Studioを使用できるAWSアカウントが必要です。すでにアカウントを持っていない場合は、SageMaker Studioのためにユーザープロファイルを作成する必要があります。
この記事で使用されるトレーニングインスタンスタイプはml.p3.16xlargeです。p3インスタンスタイプはサービスクォータリミットの増加が必要です。
MIMIC CXRデータセットは、データ使用契約によってアクセスできます。これにはユーザー登録と資格証明プロセスの完了が必要です。
開発環境のセットアップ
開発環境をセットアップするには、S3バケットを作成し、ノートブックを構成し、モデルをデプロイしてエンドポイントを作成し、QuickSightダッシュボードを作成します。
S3バケットの作成
トレーニングおよび評価データセットをホストするために、llm-radiology-bucketという名前のS3バケットを作成します。また、モデルの開発中にモデルアーティファクトを保存するためにも使用されます。
ノートブックの構成
以下の手順を完了します:
- SageMakerコンソールまたはAWSコマンドラインインターフェース(AWS CLI)からSageMaker Studioを起動します。
ドメインへのオンボーディングについての詳細は、「Amazon SageMakerドメインへのオンボーディング」を参照してください。
- レポートデータのクリーニングとモデルの微調整のための新しいSageMaker Studioノートブックを作成します。Python 3カーネルを使用したml.t3.medium 2vCPU+4GiBノートブックインスタンスを使用します。
- ノートブック内で、
nest-asyncio、IPyWidgets(Jupyterノートブック用の対話型ウィジェット)、およびSageMaker Python SDKなどの関連パッケージをインストールします:
!pip install nest-asyncio==1.5.5 --quiet
!pip install ipywidgets==8.0.4 --quiet
!pip install sagemaker==2.148.0 --quiet推論用のエンドポイントの作成とモデルのデプロイ
事前トレーニングおよび微調整済みモデルの推論には、以下のようにノートブックでエンドポイントを作成し、各モデルをデプロイします:
- HTTPSエンドポイントに展開できるModelクラスからモデルオブジェクトを作成します。
- モデルオブジェクトの事前構築された
deploy()メソッドを使用して、HTTPSエンドポイントを作成します:
from sagemaker import model_uris, script_uris
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
# 事前トレーニング済みモデルのURIを取得します
pre_trained_model_uri =model_uris.retrieve(model_id=model_id, model_version=model_version, model_scope="inference")
large_model_env = {"SAGEMAKER_MODEL_SERVER_WORKERS": "1", "TS_DEFAULT_WORKERS_PER_MODEL": "1"}
pre_trained_name = name_from_base(f"jumpstart-demo-pre-trained-{model_id}")
# 事前トレーニング済みモデルのSageMakerモデルインスタンスを作成します
if ("small" in model_id) or ("base" in model_id):
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
entry_point="inference.py",
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
)
else:
# 大きなモデルについては、推論スクリプトとモデルアーティファクトはすでに再パッケージ化されているため、Modelの`source_dir`引数は必要ありません。
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# 事前トレーニング済みモデルをデプロイします。Modelクラスを介してモデルをデプロイする場合、SageMaker APIを介して推論を実行できるように、Predictorクラスを渡す必要があります。
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)QuickSightダッシュボードの作成
Amazon Simple Storage Service(Amazon S3)に推論結果が含まれるAthenaデータソースを使用してQuickSightダッシュボードを作成し、推論結果をグラウンドトゥルースと比較します。以下のスクリーンショットは、例としてのダッシュボードを示しています。 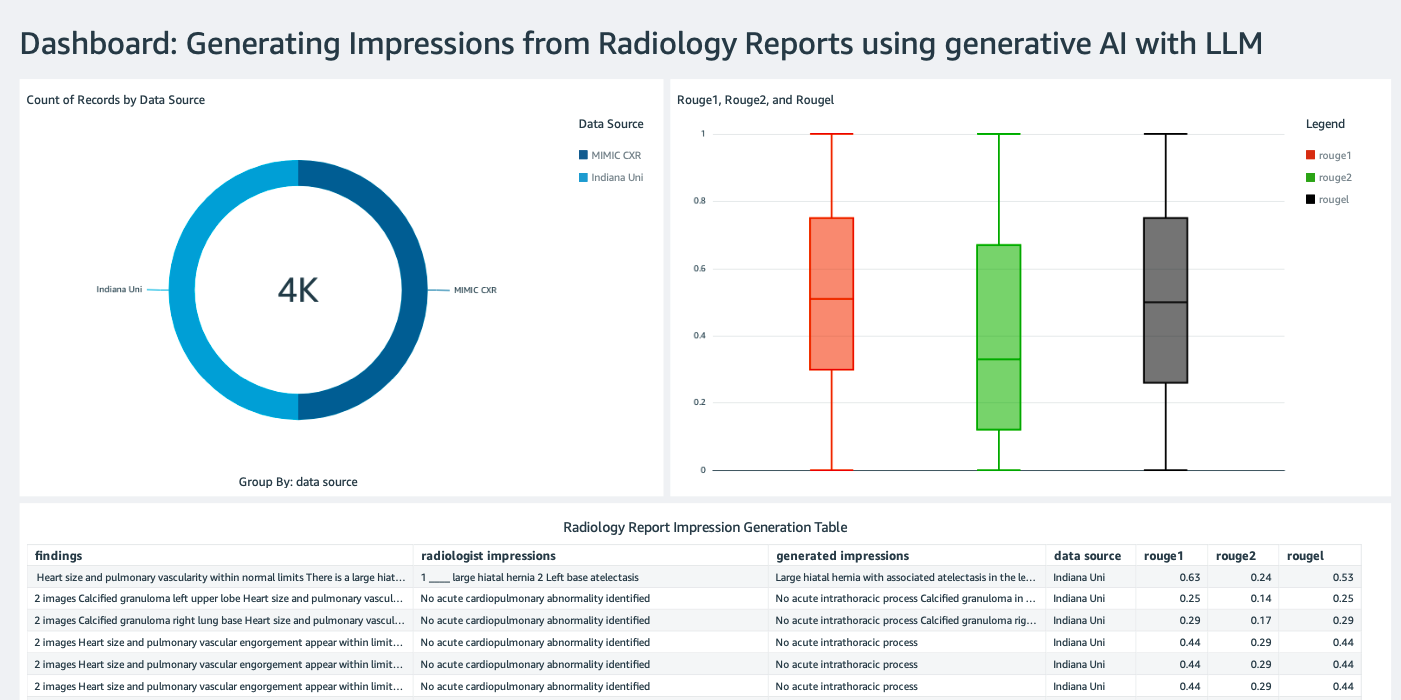
放射線報告データセット
モデルは現在ファインチューニングされており、すべてのモデルパラメータはMIMIC-CXR v2.0データセットからダウンロードされた91,544件のレポートで調整されています。放射線報告テキストデータのみを使用したため、MIMIC-CXRウェブサイトから1つの圧縮されたレポートファイル(mimic-cxr-reports.zip)のみをダウンロードしました。現在、ファインチューニングされたモデルをこのデータセットの別のサブセットである2,000件のレポート(dev1データセットと呼ばれる)で評価します。また、Indiana大学病院ネットワークの胸部X線コレクションから2,000件の放射線報告(dev2と呼ばれる)を使用して、ファインチューニングされたモデルを評価します。すべてのデータセットはJSONファイルとして読み込まれ、新しく作成されたS3バケットllm-radiology-bucketにアップロードされます。デフォルトでは、すべてのデータセットには保護された健康情報(PHI)は含まれていません。すべての機密情報はプロバイダーによって連続するアンダースコア(___)で置換されます。
SageMaker Python SDKを使用したファインチューニング
ファインチューニングには、SageMaker JumpStartモデルのリストからmodel_idとしてhuggingface-text2text-flan-t5-xlが指定されます。training_instance_typeはml.p3.16xlargeに設定され、inference_instance_typeはml.g5.2xlargeに設定されます。JSON形式のトレーニングデータはS3バケットから読み込まれます。次のステップでは、選択したmodel_idを使用してSageMaker JumpStartリソースのURI(Amazon Elastic Container Registry(Amazon ECR)のDockerイメージのimage_uri、事前学習済みモデルのアーティファクトのAmazon S3 URIのmodel_uri、トレーニングスクリプトのscript_uri)を抽出します:
from sagemaker import image_uris, model_uris, script_uris
# トレーニングインスタンスはこのイメージを使用します
train_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # model_idから自動的に推測されます
model_id=model_id,
model_version=model_version,
image_scope="training",
instance_type=training_instance_type,
)
# 事前学習済みモデル
train_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="training"
)
# トレーニングインスタンスで実行するスクリプト
train_script_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="training"
)
output_location = f"s3://{output_bucket}/demo-llm-rad-fine-tune-flan-t5/"また、出力先の場所はS3バケット内のフォルダとして設定されます。
エポック以外のハイパーパラメータはデフォルト値のままで、エポックのみを3に変更します:
from sagemaker import hyperparameters
# モデルのファインチューニングのためのデフォルトのハイパーパラメータを取得します
hyperparameters = hyperparameters.retrieve_default(model_id=model_id, model_version=model_version)
# 一部のデフォルトのハイパーパラメータをカスタム値で上書きします
hyperparameters["epochs"] = "3"
print(hyperparameters)トレーニングメトリクス(バリデーション損失のeval_loss、トレーニング損失のloss、およびトラッキングするepoch)を定義し、リストアップします:
from sagemaker.estimator import Estimator
from sagemaker.utils import name_from_base
model_name = "-".join(model_id.split("-")[2:]) # IDの最も情報量の多い部分を取得します
training_job_name = name_from_base(f"js-demo-{model_name}-{hyperparameters['epochs']}")
print(f"{bold}ジョブ名:{unbold} {training_job_name}")
training_metric_definitions = [
{"Name": "val_loss", "Regex": "'eval_loss': ([0-9\\.]+)"},
{"Name": "train_loss", "Regex": "'loss': ([0-9\\.]+)"},
{"Name": "epoch", "Regex": "'epoch': ([0-9\\.]+)"},
]前述のSageMaker JumpStartリソースURI(image_uri、model_uri、script_uri)を使用して、エスティメータを作成し、トレーニングデータセットのS3パスを指定してファインチューニングします。エスティメータクラスでは、entry_pointパラメータが必要です。この場合、JumpStartではtransfer_learning.pyを使用します。この値が設定されていない場合、トレーニングジョブは実行に失敗します。
# SageMaker Estimatorのインスタンスを作成する
sm_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
model_uri=train_model_uri,
source_dir=train_script_uri,
entry_point="transfer_learning.py",
instance_count=1,
instance_type=training_instance_type,
volume_size=300,
max_run=360000,
hyperparameters=hyperparameters,
output_path=output_location,
metric_definitions=training_metric_definitions,
)
# 指定されたS3パス内のデータを使用してSageMakerのトレーニングジョブを開始する
# トレーニングジョブには数時間かかることがありますので、wait=Falseを設定し、
# トレーニングジョブの状態はSageMakerコンソールで監視することをおすすめします
sm_estimator.fit({"training": train_data_location}, job_name=training_job_name, wait=True)このトレーニングジョブは数時間かかる場合がありますので、waitパラメータをFalseに設定し、SageMakerコンソールでトレーニングジョブの状態を監視することをおすすめします。次のようにTrainingJobAnalytics関数を使用して、さまざまなタイムスタンプでのトレーニングメトリクスを追跡します:
from sagemaker import TrainingJobAnalytics
# このセルを実行する前に、ジョブが開始するまで数分間待ちます
# ジョブがまだ実行中の場合でも呼び出すことができます
df = TrainingJobAnalytics(training_job_name=training_job_name).dataframe()推論エンドポイントの展開
比較を行うために、事前学習済みモデルとファインチューニング済みモデルの両方に対して推論エンドポイントを展開します。
まず、model_idを使用して推論用のDockerイメージURIを取得し、このURIを使用して事前学習済みモデルのSageMakerモデルインスタンスを作成します。モデルオブジェクトの事前構築されたdeploy()メソッドを使用して、事前学習済みモデルを展開します。SageMaker APIを介して推論を実行するためには、Predictorクラスを渡すことを忘れないでください。
from sagemaker import image_uris
# 推論用のDockerイメージURIを取得します。これはHuggingFaceのベースコンテナイメージです
deploy_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # model_idから自動的に推測されます
model_id=model_id,
model_version=model_version,
image_scope="inference",
instance_type=inference_instance_type,
)
# 事前学習済みモデルのURIを取得します
pre_trained_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# 事前学習済みモデルを展開します。モデルを展開する際には、Modelクラスを介してPredictorクラスを渡す必要があります
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)前の手順を繰り返して、ファインチューニング済みモデルのSageMakerモデルインスタンスを作成し、モデルを展開するエンドポイントを作成します。
モデルの評価
まず、要約テキストの長さ、モデルの出力数(複数の要約を生成する場合は1より大きい必要があります)、およびビームサーチのビーム数を設定します。
JSONペイロードとして推論リクエストを構築し、それを使用して事前学習済みモデルとファインチューニング済みモデルのエンドポイントにクエリを送信します。
以前に説明したように、集約されたROUGEスコア(ROUGE1、ROUGE2、ROUGEL、ROUGELsum)を計算します。
結果の比較
次の表は、dev1およびdev2データセットの評価結果を示しています。MIMIC CXR Radiology Reportからの2,000件の所見を含むdev1の評価結果では、事前学習済みモデルと比較して集計平均ROUGE1およびROUGE2スコアが約38パーセントポイント向上しています。dev2では、ROUGE1スコアとROUGE2スコアがそれぞれ31パーセントポイントと25パーセントポイント向上しています。全体的に、ファインチューニングによりdev1およびdev2データセットのROUGELsumスコアがそれぞれ38.2パーセントポイントと31.3パーセントポイント向上しました。
|
評価 データセット |
事前学習モデル | ファインチューニングモデル | ||||||
| ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | |
dev1 |
0.2239 | 0.1134 | 0.1891 | 0.1891 | 0.6040 | 0.4800 | 0.5705 | 0.5708 |
dev2 |
0.1583 | 0.0599 | 0.1391 | 0.1393 | 0.4660 | 0.3125 | 0.4525 | 0.4525 |
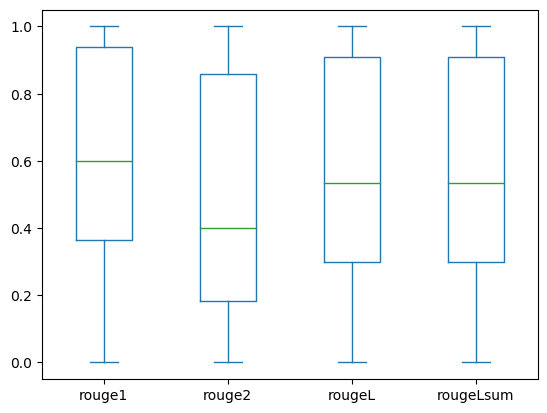
以下のボックスプロットは、ファインチューニングモデルを使用して評価されたdev1およびdev2のデータセットのROUGEスコアの分布を示しています。
 |
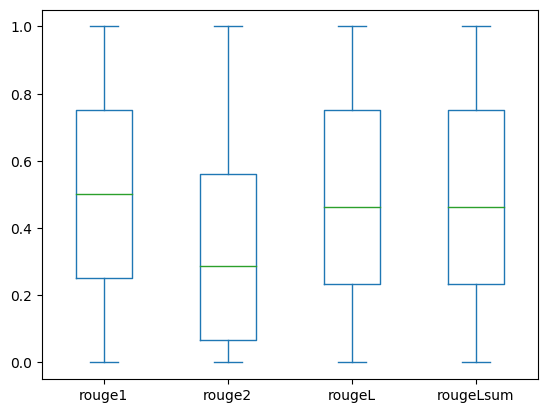 |
(a): dev1 |
(b): dev2 |
以下の表は、評価データセットのROUGEスコアがほぼ同じ中央値と平均値を持ち、したがって対称的に分布していることを示しています。
| データセット | スコア | カウント | 平均値 | 標準偏差 | 最小値 | 第25パーセンタイル | 第50パーセンタイル | 第75パーセンタイル | 最大値 |
dev1 |
ROUGE1 | 2000.00 | 0.6038 | 0.3065 | 0.0000 | 0.3653 | 0.6000 | 0.9384 | 1.0000 |
| ROUGE2 | 2000.00 | 0.4798 | 0.3578 | 0.0000 | 0.1818 | 0.4000 | 0.8571 | 1.0000 | |
| ROUGEL | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
| ROUGELsum | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
dev2 |
ROUGE1 | 2000.00 | 0.4659 | 0.2525 | 0.0000 | 0.2500</
クリーンアップ将来の料金を発生させないために、以下のコードを使用して作成したリソースを削除してください: 結論本記事では、SageMaker Studioを使用して、臨床領域特有の要約タスクのためにFLAN-T5 XLモデルを微調整する方法を示しました。信頼性を高めるために、予測結果を正解データと比較し、ROUGEメトリクスを使用して結果を評価しました。特定のタスクに微調整されたモデルは、一般的なNLPタスクで事前学習されたモデルよりも優れた結果を返すことを示しました。また、汎用的なLLMの微調整により、事前学習のコストを完全に排除することができることを指摘したいと思います。 ここで紹介した作業は、胸部X線レポートに焦点を当てていますが、他の解剖学的部位やモダリティ(MRIやCTなど)を持つより複雑な放射線学レポートの大規模なデータセットに拡張する可能性があります。このような場合、放射線科医は重要度の順に所見を生成し、追加の推奨事項を含めることができます。さらに、このアプリケーションのフィードバックループを設定することで、放射線科医はモデルのパフォーマンスを時間とともに向上させることができます。 本記事で示したように、微調整されたモデルは、高いROUGEスコアを持つ放射線学レポートの所見を生成します。異なる部門からの他の特定ドメインの医療レポートに対してもLLMの微調整を試してみることができます。 We will continue to update VoAGI; if you have any questions or suggestions, please contact us! Was this article helpful?93 out of 132 found this helpful Related articles 
AIニュース人工知能の世界からの最新ニュースと更新情報を入手してください Discover more
機械学習
このAI論文では、リーマン幾何学を通じて拡散モデルの潜在空間の理解に深入りします人工知能や機械学習の人気が高まる中で、自然言語処理や自然言語生成などの主要なサブフィールドも高速に進化しています。最...
AIニュース
このAIニュースレターはあなたが必要なすべてです #72今週、AIニュースはOpenAIのDevdayと多くの新しいモデルや機能の発売で主導権を握り、それによってエロン・マスクがLLMレース...
AI研究
アリゾナ州立大学のこのAI研究は、テキストから画像への非拡散先行法を改善するための画期的な対照的学習戦略「ECLIPSE」を明らかにした拡散モデルは、テキストの提案を受け取ると、高品質な写真を生成するのに非常に成功しています。このテキストから画像へのパ...
AI研究
テンセントAIラボの研究者たちは、テキスト対応の画像プロンプトアダプタ「IP-Adapter」を開発しました:テキストから画像への拡散モデルのためのアダプタです「リンゴ」と言えば、あなたの頭にすぐにリンゴのイメージが浮かびます。私たちの脳の働き方が魅力的であるように、生成AIも...
AI研究
Covid-19への闘いを加速する:研究者がAIによって生成された抗ウイルス薬を検証し、将来の危機における迅速な薬剤開発の道を開拓IBMとオックスフォード大学の研究者による最近の研究により、抗ウイルス薬の開発における画期的な成果が明らかになりました。...
Want to read more? Go here
|