「生成AIとAmazon Kendraを使用して、エンタープライズスケールでキャプションの作成と画像の検索を自動化する」
Automate caption creation and image search at an enterprise scale using generative AI and Amazon Kendra.
Amazon Kendraは、機械学習(ML)によって強化された知的な検索サービスです。Amazon Kendraは、ウェブサイトやアプリケーションにおいて、従業員や顧客が簡単に求めているコンテンツを見つけることができるように、組織内の複数の場所やコンテンツリポジトリに分散している場合でも、検索を再構築します。
Amazon Kendraは、Microsoft Word、PDF、およびさまざまなデータソースからのテキストなど、さまざまな文書形式をサポートしています。この記事では、Amazon Kendraのドキュメントサポートを拡張し、画像を表示されたコンテンツで検索可能にする方法に焦点を当てています。画像はしばしばキーワードなどの補足メタデータを使用して検索されます。ただし、数千もの画像に詳細なメタデータを手動で追加するのには多くの手間がかかります。生成的AI(GenAI)は、メタデータを自動的に生成するのに役立ちます。テキストキャプションを生成することにより、GenAIキャプション予測は画像の説明的なメタデータを提供します。Amazon Kendraインデックスは、ドキュメントの取り込み中に生成されたメタデータで豊かにされ、手動の手間なしで画像を検索できるようになります。
例えば、GenAIモデルは、画像のドキュメント取り込み中に「傘の下に横たわる犬」として次の画像のテキストの説明を生成するために使用できます。

- 「SageMaker Distributionは、Amazon SageMaker Studioで利用可能になりました」
- 「Amazon SageMakerを使用して、生成AIを使ってパーソナライズされたアバターを作成する」
- メタは、AIを活用した「パーソナ」と呼ばれる機能を自社サービスに統合する予定です
オブジェクト認識モデルはまだ「犬」や「傘」といったキーワードを検出することができますが、GenAIモデルは犬が傘の下に横たわることを識別することで、画像に表されているもののより深い理解を提供します。これにより、画像検索プロセスにおいてより洗練された検索を構築することができます。テキストの説明は、自動化されたカスタムドキュメントエンリッチメント(CDE)を介してAmazon Kendraの検索インデックスにメタデータとして追加されます。その後、「犬」や「傘」といった用語を検索するユーザーは、次のスクリーンショットに示されているように、画像を見つけることができます。
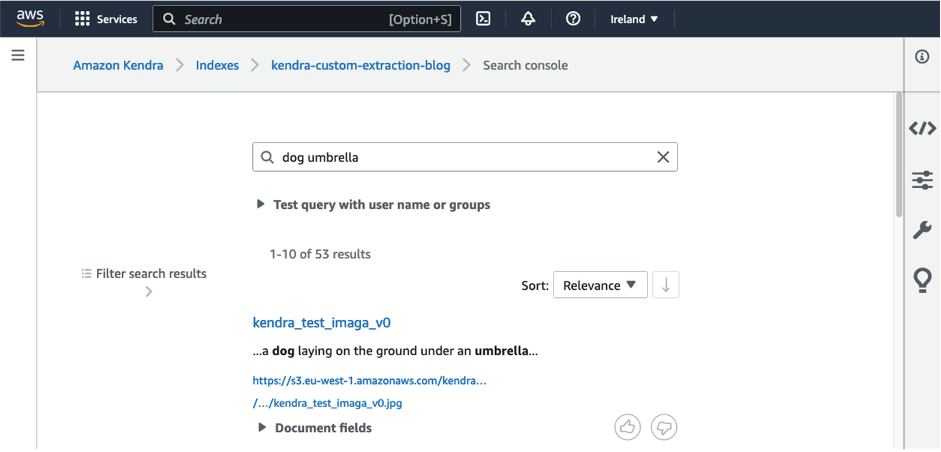
この記事では、Amazon SageMakerで展開されたGenAIモデルを使用してAmazon KendraでCDEを使用する方法を紹介します。シンプルな例を使用してCDEをデモンストレーションし、AWSアカウント内のAmazon KendraインデックスでCDEを体験するためのステップバイステップガイドも提供します。これにより、ユーザーは手動でタグ付けや分類をすることなく、必要な画像を迅速かつ簡単に見つけることができます。このソリューションは、さまざまなアプリケーションや産業のニーズに合わせてカスタマイズしてスケーリングすることも可能です。
GenAIによる画像キャプション
GenAIによる画像説明は、MLアルゴリズムを使用して画像のテキスト説明を生成することを意味します。このプロセスは画像キャプションとも呼ばれ、コンピュータビジョンと自然言語処理(NLP)の交差点で操作されます。データがメタデータの形でテキストや画像を含む、マルチモーダルなデータが存在する場所(例えば、eコマース)や、データが医師のメモや診断と共にMRIやCTスキャンを含む医療分野など、さまざまな用途で使用されます。
GenAIモデルは、画像内のオブジェクトや特徴を認識し、それらのオブジェクトや特徴の自然言語による説明を生成することを学習します。最先端のモデルは、エンコーダー-デコーダーアーキテクチャを使用しており、画像情報はニューラルネットワークの中間層においてエンコードされ、抽出された視覚的特徴に基づいてテキストの説明にデコードされます。これは、特徴抽出(エンコーダー)の段階とキャプション生成(デコーダー)の段階として考えることができます。特徴抽出の段階では(エンコーダー)、GenAIモデルは画像を処理し、オブジェクトの形状、色、テクスチャなどの関連する視覚的特徴を抽出します。キャプション生成の段階では(デコーダー)、モデルは抽出された視覚的特徴に基づいて画像の自然言語の説明を生成します。
GenAIモデルは通常、大量のデータでトレーニングされるため、追加のトレーニングなしでさまざまなタスクに適しています。カスタムデータセットや新しいドメインに適応することも、フューショットラーニングを通じて容易に実現できます。プレトレーニングの手法により、最先端の言語モデルや画像モデルを使用してマルチモーダルなアプリケーションを容易にトレーニングすることができます。これらのプレトレーニングの手法により、データに最適なビジョンモデルと言語モデルを組み合わせることも可能です。
生成された画像の説明の品質は、トレーニングデータの品質とサイズ、GenAIモデルのアーキテクチャ、特徴抽出とキャプション生成アルゴリズムの品質によって異なります。GenAIによる画像の説明は、研究の活発な領域ではありますが、画像検索、ビジュアルストーリーテリング、視覚障害者のアクセシビリティなど、さまざまなアプリケーションで非常に良い結果を示しています。
ユースケース
GenAI画像キャプションは、以下のようなユースケースで有用です:
- Eコマース – 画像とテキストが一緒に出現する一般的な業界ユースケースは、小売業です。特に、Eコマースは製品画像とテキストの説明とともに膨大なデータを保管します。検索クエリに基づいてユーザーに最適な製品を表示するために、テキストの説明やメタデータは重要です。さらに、Eコマースサイトが第三者のベンダーからデータを取得するというトレンドにより、製品の説明はしばしば不完全であり、メタデータの列に正しい情報をタグ付けするために多くの手作業と膨大なオーバーヘッドが発生します。GenAIベースの画像キャプションは、この労働集約的なプロセスを自動化するのに特に役立ちます。ファッション製品の属性を説明するテキストと共にファッション画像などのカスタムファッションデータでモデルを微調整することで、ユーザーの検索体験を向上させるためのメタデータを生成することができます。
- マーケティング – 画像検索の別のユースケースは、デジタルアセット管理です。マーケティング企業は膨大なデジタルデータを保管し、データカタログによって集中化、簡単に検索可能でスケーラブルにする必要があります。情報豊かなデータカタログを備えた集中化されたデータレイクは、重複作業を減らし、クリエイティブコンテンツの広範な共有とチーム間の一貫性を実現します。ソーシャルメディアコンテンツの生成や企業のプレゼンテーションを可能にするために広く使用されるグラフィックデザインプラットフォームでは、より高速な検索により、ユーザーが探している画像の正しい検索結果が表示され、自然言語のクエリを使用して検索できるようになり、ユーザーエクスペリエンスが向上します。
- 製造業 – 製造業は、部品、建物、ハードウェア、機器の設計図などの画像データを多く保管しています。そのようなデータを検索できる能力は、製品チームが既存の開始点から設計を簡単に再作成し、多くの設計オーバーヘッドを排除することを可能にし、設計生成プロセスを高速化します。
- ヘルスケア – 医師や医学研究者はMRIやCTスキャン、標本サンプル、発疹や変形などの疾患の画像、医師のメモ、診断、臨床試験の詳細をカタログ化して検索することができます。
- メタバースまたは拡張現実 – 製品の広告は、ユーザーが想像し、共感することができるストーリーを作ることです。AIパワードツールと分析を使用することで、ユーザーのユニークな好みや感性に合わせたカスタマイズされたストーリーを作成することが今まで以上に容易になりました。これが画像からテキストへのモデルがゲームチェンジャーとなる場所です。ビジュアルストーリーテリングはキャラクターの作成や異なるスタイルへの適応、キャプション付けに役立ちます。また、メタバースや拡張現実、ビデオゲームを含む没入型コンテンツでも刺激的な体験を提供するために使用することもできます。画像検索により、開発者、デザイナー、チームは自然言語のクエリを使用してコンテンツを検索することができ、さまざまなチーム間でコンテンツの一貫性を維持することができます。
- 視覚障害者や視力の低い人のためのデジタルコンテンツのアクセシビリティ – これは主にスクリーンリーダーやタッチリーディング・ライティングを可能にする点字システム、ウェブサイトやアプリケーションをナビゲートするための特殊キーボードなどの支援技術によって実現されます。ただし、画像は音声として伝えることができるテキストコンテンツとして提供する必要があります。GenAIアルゴリズムを使用した画像キャプションは、インターネットの再設計と、オンラインコンテンツにアクセスし、理解し、対話する機会をすべてに提供することで、インターネットをより包括的にするための重要な要素です。
モデルの詳細とカスタムデータセットのモデルの微調整
このソリューションでは、Hugging Faceから提供されているvit-gpt2-image-captioningモデルを利用しています。このモデルはApache 2.0のライセンスで提供されており、さらなる微調整は行っていません。Vitは画像データの基盤モデルであり、GPT-2は言語の基盤モデルです。この2つのモデルのマルチモーダルな組み合わせにより、画像キャプションの機能が提供されます。Hugging Faceは最先端の画像キャプションモデルをホストしており、AWSで簡単に展開し、シンプルな展開推論エンドポイントを提供しています。この事前訓練済みモデルを直接使用することもできますが、ドメイン固有のデータセット、ビデオや空間データなどのより多様なデータタイプ、ユニークなユースケースに合わせてモデルをカスタマイズすることもできます。特定のデータセットに最適なパフォーマンスを発揮するいくつかのGenAIモデルがあり、または既にビジョンと言語モデルを使用している可能性があります。このソリューションは、使用したモデルを簡単に置き換えることで、最適なビジョンと言語モデルを画像キャプションモデルとして選択する柔軟性を提供します。
業界固有のアプリケーションにモデルをカスタマイズするためには、Hugging Faceを介してAWSで利用可能なオープンソースモデルがいくつかあります。事前訓練済みモデルを一意のデータセットでテストしたり、ラベル付きデータのサンプルでトレーニングしたりして微調整することができます。新しい研究手法を使用することで、ビジョンと言語モデルの任意の組み合わせを効率的に組み合わせ、データセットでトレーニングすることもできます。この新しくトレーニングされたモデルは、このソリューションで説明されている画像キャプションのためにSageMakerに展開することができます。
カスタマイズされた画像検索の例は、企業資源計画(ERP)です。 ERPでは、物流やサプライチェーン管理の異なる段階から収集された画像データには、税金の領収書、ベンダーの注文書、給与明細などが含まれる場合があります。これらは組織内の異なるチームの対象となるように自動的に分類する必要があります。また、医療スキャンと医師の診断を使用して新しい医療画像を自動分類するためにも利用できます。ビジョンモデルはMRI、CT、またはX線画像から特徴を抽出し、テキストモデルはそれを医療診断とキャプション付けします。
ソリューションの概要
次の図は、GenAIとAmazon Kendraを使用した画像検索のアーキテクチャを示しています。
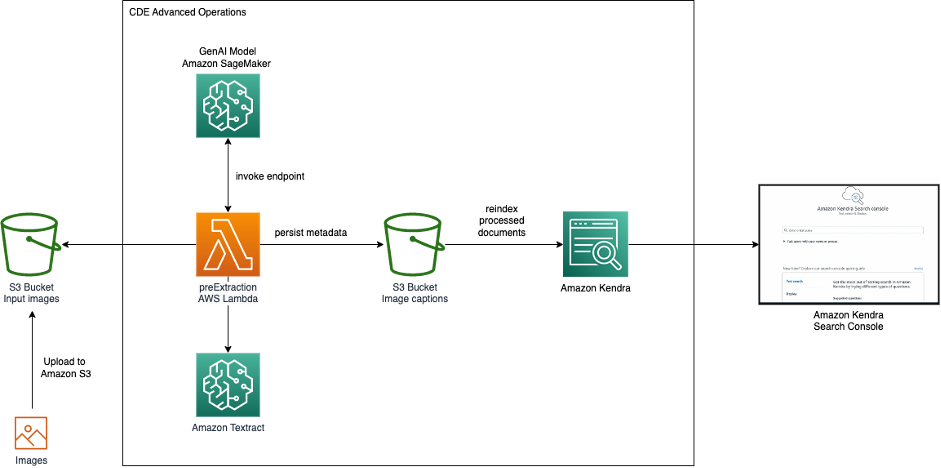
Amazon Simple Storage Service(Amazon S3)から画像をAmazon Kendraに取り込みます。 Amazon Kendraへの取り込み中に、SageMakerにホストされたGenAIモデルが呼び出され、画像の説明が生成されます。さらに、画像内に表示されるテキストはAmazon Textractによって抽出されます。画像の説明と抽出されたテキストはメタデータとして保存され、Amazon Kendraの検索インデックスで利用できるようになります。取り込み後、画像はAmazon Kendraの検索コンソール、API、またはSDKを介して検索できます。
画像の取り込みステップで、GenAIモデルとAmazon Textractを呼び出すために、Amazon KendraのCDEの高度な操作を使用します。ただし、CDEはさまざまなユースケースで使用できます。CDEを使用すると、Amazon Kendraにドキュメントを取り込む際にドキュメント属性とコンテンツを作成、変更、または削除できます。これにより、必要に応じてデータを操作して取り込むことができます。これは、取り込み中にプレおよびポスト抽出AWS Lambda関数を呼び出すことで実現できます。これにより、データの充実や変更が可能になります。たとえば、医療テキストデータを取り込む際にAmazon Medical Comprehendを使用して、検索メタデータにML生成の洞察を追加することができます。
以下の手順に従って、Amazon Kendraを介して画像を検索するためのソリューションを使用できます:
- 画像をS3バケットなどの画像リポジトリにアップロードします。
- 画像リポジトリはAmazon Kendraによってインデックス化されます。 Amazon Kendraは、構造化データや非構造化データを検索するために使用できる検索エンジンです。インデックス作成中に、GenAIモデルとAmazon Textractが呼び出されて画像のメタデータが生成されます。インデックスの作成は、手動でトリガーするか、事前に定義されたスケジュールで行うことができます。
- Amazon Kendraコンソール、SDK、またはAPIを介して、「赤いバラの画像を検索」や「公園で遊ぶ犬の写真を表示」といった自然言語クエリを使用して画像を検索できます。これらのクエリは、Amazon Kendraによって処理され、クエリの意味を理解し、インデックスされたリポジトリから関連する画像を取得するためにMLアルゴリズムを使用します。
- 検索結果が表示され、それに対応するテキストの説明と共に、探している画像を迅速かつ簡単に見つけることができます。
前提条件
以下の前提条件を満たす必要があります:
- AWSアカウント
- AWS CloudFormationを介して以下のサービスをプロビジョニングおよび呼び出すための権限:Amazon S3、Amazon Kendra、Lambda、およびAmazon Textract。
コスト見積もり
このソリューションをコンセプトの証明として展開する場合のコストは、以下の表に示されています。これが、開発者向けエディションのAmazon Kendraを使用している理由です。開発者向けエディションは本番ワークロードには推奨されませんが、開発者向けの低コストオプションを提供します。Amazon Kendraの検索機能を1か月あたり20日間、1日3時間使用することを想定し、60か月間のアクティブ時間に関連するコストを計算しています。
| サービス | 消費時間 | 1か月あたりの見積もりコスト |
| Amazon S3 | データ転送を含む10 GBのストレージ | 2.30 USD |
| Amazon Kendra | 1か月あたり60時間の開発者エディション | 67.90 USD |
| Amazon Textract | 10,000枚の画像で100%のドキュメントテキストを検出 | 15.00 USD |
| Amazon SageMaker | 20日間、1日3時間、1エンドポイントで展開されたモデルに対するリアルタイム推論(ml.g4dn.xlargeを使用) | 44.00 USD |
| . | . | 129.2 USD |
AWS CloudFormationを使用してリソースをデプロイする
CloudFormationスタックは、以下のリソースをデプロイします:
- Hugging Faceハブから画像キャプションモデルをダウンロードし、その後モデルのアセットをビルドするLambda関数
- 推論コードと圧縮されたモデルアーティファクトを宛先のS3バケットに配置するLambda関数
- 圧縮されたモデルアーティファクトと推論コードを格納するためのS3バケット
- アップロードされた画像とAmazon Kendraドキュメントを格納するためのS3バケット
- 生成された画像キャプションを検索するためのAmazon Kendraインデックス
- Hugging Face画像キャプションモデルを展開するためのSageMakerリアルタイム推論エンドポイント
- 需要に応じてAmazon Kendraインデックスをエンリッチする際にトリガーされるLambda関数。Amazon TextractとSageMakerリアルタイム推論エンドポイントを呼び出します。
さらに、AWS CloudFormationは、必要なすべてのAWS Identity and Access Management(IAM)ロールとポリシー、VPCとサブネット、セキュリティグループ、およびカスタムリソースLambda関数が実行されるインターネットゲートウェイをデプロイします。
リソースをプロビジョニングするには、次の手順を完了してください:
- スタックを起動を選択して、CloudFormationテンプレートを
us-east-1リージョンで起動します: - 次へを選択します。
- スタックの詳細を指定ページでは、テンプレートURLとパラメータファイルのS3 URIをデフォルトのままにして、次へを選択します。
- その後のページでも次へを選択し続けます。
- スタックを作成してスタックをデプロイします。
スタックのステータスを監視します。ステータスがCREATE_COMPLETEと表示されると、デプロイが完了です。
画像の取り込みと検索
画像の取り込みと検索を行うには、次の手順を完了してください:
- Amazon S3コンソールで、
kendra-image-search-stack-imagecaptionsS3バケット内にimagesという名前のフォルダを作成します。 - 次の画像を
imagesフォルダにアップロードします。




us-east-1リージョンでAmazon Kendraコンソールに移動します。- ナビゲーションペインでインデックスを選択し、インデックス(
kendra-index)を選択します。 - データソースを選択し、
generated_image_captionsを選択します。 - 今すぐ同期を選択します。
同期が完了するまで待機してから次の手順に進んでください。
- ナビゲーションペインでインデックスを選択し、
kendra-indexを選択します。 - 検索コンソールに移動します。
- 個別または組み合わせて次のクエリを試してみてください:“dog”、“umbrella”、“newsletter”。Amazon Kendraによって高い評価が得られる画像を見つけてください。
アップロードされた画像に適合するクエリを自由にテストしてください。
クリーンアップ
すべてのリソースを解除するには、以下の手順を完了します。
- AWS CloudFormationコンソールで、ナビゲーションペインでスタックを選択します。
- スタック
kendra-genai-image-searchを選択し、削除を選択します。
スタックのステータスがDELETE_COMPLETEに変わるまで待ちます。
結論
この投稿では、Amazon KendraとGenAIを組み合わせて画像の意味のあるメタデータの自動作成を行う方法を紹介しました。最先端のGenAIモデルは、画像の内容を説明するテキストキャプションを生成するのに非常に役立ちます。これには、ヘルスケアとライフサイエンス、小売りとEコマース、デジタルアセットプラットフォーム、メディアなど、さまざまな業界のユースケースがあります。画像キャプションは、視覚障がいのある社会のニーズに対応するために、より包括的なデジタルワールドの構築とインターネット、メタバース、没入型テクノロジーの再設計にも重要です。
キャプションを通じた画像検索により、これらのアプリケーションのために手動の労力なしでデジタルコンテンツを簡単に検索でき、重複した作業を排除できます。提供したCloudFormationテンプレートを使用すると、Amazon Kendraを使用して画像検索を有効にするためのソリューションを簡単にデプロイできます。Amazon S3に格納された画像のシンプルなアーキテクチャとGenAIを使用して画像のテキスト説明を作成し、Amazon KendraでCDEを使用してこのソリューションをパワーアップすることができます。
これはGenAIとAmazon Kendraの1つのアプリケーションに過ぎません。Amazon KendraでGenAIアプリケーションを構築する方法についてさらに詳しく学ぶには、「Amazon Kendra、LangChain、および大規模言語モデルを使用した企業データの高精度な生成型AIアプリケーションを迅速に構築する」を参照してください。GenAIアプリケーションの構築とスケーリングについては、Amazon Bedrockをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「MITのPhotoGuardは、AI画像操作に対抗するためにAIを使用します」
- 「アジア太平洋地域でAIスタートアップを創出する女性のための新たなファンド」
- 「デリー政府、提案された電子都市にAIハブを建設する計画」
- 2023年6月のVoAGIトップ投稿:GPT4Allは、あなたのドキュメント用のローカルチャットGPTであり、無料です!
- 創造力を解き放つ:ジェネレーティブAIとAmazon SageMakerがビジネスを支援し、AWSを活用したマーケティングキャンペーンの広告クリエイティブを生み出します
- 「Amazon SageMakerを使用したヘルスケアの要約オプションの探索」
- 「AIの創造性の測定」 AIの創造性を測定する





