「Auto-GPT&GPT-Engineer:今日の主要なAIエージェントについての詳細ガイド」
Auto-GPT & GPT-Engineer Detailed Guide on Today's Major AI Agents
ChatGPTとAuto-GPT、GPT-Engineerなどの自律型AIエージェントを比較すると、意思決定プロセスには大きな違いが現れます。ChatGPTは会話を進めるために積極的な人間の関与が必要であり、ユーザーのプロンプトに基づいてガイダンスを提供しますが、計画プロセスは主に人間の介入に依存しています。
変形器などの生成型AIモデルは、これらの自律型AIエージェントを駆動する最先端のコア技術です。これらの変形器は大規模なデータセットで訓練されており、複雑な推論と意思決定能力をシミュレートすることができます。
オープンソースのルーツ:Auto-GPTとGPT-Engineerの自律エージェント
これらの自律型AIエージェントの多くは、従来のワークフローを変革する革新的な個人によるオープンソースの取り組みから生まれています。Auto-GPTなどのエージェントは、単なる提案だけでなく、オンラインショッピングから基本的なアプリの構築まで、独自にタスクを処理することができます。OpenAIのCode Interpreterは、ChatGPTが単にアイデアを提案するだけでなく、それらのアイデアを活用して問題を積極的に解決することを目指しています。
Auto-GPTとGPT-Engineerの両方には、GPT 3.5とGPT-4のパワーが搭載されています。それはコードの論理を把握し、複数のファイルを組み合わせ、開発プロセスを加速します。
- 「企業がGoogle Cloud AIを利用する7つの方法」
- Googleが「Gemini」というAIツールと、その他多数のAIツールをリリースしました
- オープンAIによって、大規模な企業向けにChatGPT Enterpriseがリリースされます
Auto-GPTの機能の要点は、そのAIエージェントにあります。これらのエージェントは、スケジューリングなどの日常的なタスクから戦略的な意思決定が必要なより複雑なタスクまでを実行するようにプログラムされています。ただし、これらのAIエージェントはユーザーが設定した境界内で動作します。APIを介してアクセスを制御することにより、ユーザーはAIが実行できるアクションの深さと範囲を決定することができます。
例えば、ChatGPTと統合されたチャットWebアプリを作成するというタスクが与えられた場合、Auto-GPTは自律的にその目標をHTMLフロントエンドの作成やPythonバックエンドのスクリプト作成などの具体的なステップに分解します。アプリケーションはこれらのプロンプトを自律的に生成しますが、ユーザーはそれらを監視して変更することができます。AutoGPTの作成者である@SigGravitasによって示されるように、それはPythonに基づいたテストプログラムを構築して実行することができます。
Auto-GPTの大規模なアップデート:コードの実行! 🤖💻
Auto-GPTは#gpt4を使用して独自のコードを書き、Pythonスクリプトを実行できるようになりました!
これにより、再帰的なデバッグ、開発、および自己改善が可能になります… 🤯 👇 pic.twitter.com/GEkMb1LyxV
— Significant Gravitas (@SigGravitas) April 1, 2023
下の図は自律型AIエージェントのより一般的なアーキテクチャを説明しており、裏側のプロセスについて貴重な見識を提供しています。

自律型AIエージェントのアーキテクチャ
プロセスはOpenAI APIキーを検証し、短期記憶やデータベースの内容などのさまざまなパラメータを初期化することから始まります。キーのデータがエージェントに渡されると、モデルはGPT3.5/GPT4と対話して応答を取得します。この応答はJSON形式に変換され、エージェントはそれを解釈してオンライン検索、ファイルの読み書き、コードの実行などさまざまな機能を実行します。Auto-GPTは事前訓練されたモデルを使用して、これらの応答をデータベースに保存し、将来の対話ではこの保存された情報を参照します。このループはタスクが完了するまで続きます。
Auto-GPTとGPT-Engineerのセットアップガイド
GPT-EngineerとAuto-GPTなどの最先端のツールのセットアップは、開発プロセスを効率化することができます。以下は、両方のツールをインストールおよび設定するための構造化されたガイドです。
Auto-GPT
Auto-GPTのセットアップは複雑に見えるかもしれませんが、適切な手順を踏めば簡単になります。このガイドでは、Auto-GPTのセットアップ手順とその多様なシナリオについて説明しています。
1. 前提条件:
- Python環境:Python 3.8以降がインストールされていることを確認してください。Pythonは公式ウェブサイトから入手できます。
- リポジトリをクローンする予定がある場合は、Gitをインストールしてください。
- OpenAI APIキー:OpenAIとのやり取りにはAPIキーが必要です。OpenAIアカウントからキーを取得してください。

Open AI APIキーの生成
メモリバックエンドオプション: メモリバックエンドは、AutoGPTが操作に必要なデータにアクセスするためのストレージメカニズムとして機能します。AutoGPTは、短期および長期のストレージ機能を使用します。Pinecone、Milvus、Redisなどが利用可能なオプションです。
2. ワークスペースの設定:
- 仮想環境の作成:
python3 -m venv myenv - 環境をアクティベートする:
- MacOSまたはLinux:
source myenv/bin/activate
- MacOSまたはLinux:
3. インストール:
- Auto-GPTリポジトリをクローンする(Gitがインストールされていることを確認してください):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - Auto-GPTのバージョン0.2.2で作業していることを確認するために、その特定のバージョンにcheckoutします:
git checkout stable-0.2.2 - ダウンロードしたリポジトリに移動する:
cd Auto-GPT - 必要な依存関係をインストールする:
pip install -r requirements.txt
4. 設定:
- メインの
/Auto-GPTディレクトリにある.env.templateを探します。それを複製して.envに名前を変更します .envを開き、OpenAI APIキーをOPENAI_API_KEY=の隣に設定します- 同様に、Pineconeや他のメモリバックエンドを使用する場合は、
.envファイルをPinecone APIキーとリージョンで更新します。
5. コマンドラインの指示:
Auto-GPTは、動作をカスタマイズするための豊富なコマンドライン引数を提供しています:
- 一般的な使用法:
- ヘルプを表示する:
python -m autogpt --help - AIの設定を調整する:
python -m autogpt --ai-settings <filename> - メモリバックエンドを指定する:
python -m autogpt --use-memory <memory-backend>
- ヘルプを表示する:

CLIでのAuto-GPT
6. Auto-GPTの起動:
設定が完了したら、次のコマンドを使用してAuto-GPTを開始します:
- LinuxまたはMac:
./run.sh start - Windows:
.\run.bat
Dockerの統合(推奨されるセットアップアプローチ)
Auto-GPTをコンテナ化したい場合、Dockerは効率的なアプローチを提供します。ただし、Dockerの初期設定はやや複雑な場合があります。サポートのためにDockerのインストールガイドを参照してください。
次の手順に従ってOpenAI APIキーを変更します。Dockerがバックグラウンドで実行されていることを確認してください。AutoGPTのメインディレクトリに移動し、以下の手順をターミナルで実行します
- Dockerイメージをビルドする:
docker build -t autogpt . - 次に実行します:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
docker-composeを使用する場合:
- 実行:
docker-compose run --build --rm auto-gpt - 追加の引数を統合することで、補足的なカスタマイズが可能です。例えば、–gpt3onlyと–continuousの両方で実行する場合:
docker-compose run --rm auto-gpt --gpt3only--continuous - Auto-GPTは、大規模なデータセットからコンテンツを生成する際に、意図せず悪意のあるWebソースにアクセスする可能性があるため、注意が必要です。
リスクを軽減するために、Dockerのような仮想コンテナ内でAuto-GPTを実行してください。これにより、潜在的に有害なコンテンツが仮想空間内に閉じ込められ、外部ファイルやシステムが影響を受けないようになります。また、Windows Sandboxもオプションですが、セッションごとにリセットされ、状態を保持できません。
セキュリティのためには、常にAuto-GPTを仮想環境で実行し、システムが予期しない出力から隔離されるようにしてください。
これらすべてを考慮しても、望んだ結果を得られない可能性がまだあります。Auto-GPTのユーザーは、ファイルへの書き込みを試みる際に再発する問題に遭遇し、問題のあるファイル名により試行が失敗することがよくあります。以下はそのようなエラーの例です:Auto-GPT(リリース0.2.2)はエラー「write_to_file returned: Error: File has already been updated」の後にテキストを追加しません
この問題に対するさまざまな解決策が関連するGitHubのスレッドで議論されています。
GPT-エンジニア
GPT-エンジニアのワークフロー:
- プロンプトの定義:自然言語を使用してプロジェクトの詳細な説明を作成します。
- コード生成:プロンプトに基づいて、GPT-エンジニアはコードの断片、関数、または完全なアプリケーションを生成します。
- 改善と最適化:生成後、常に改善の余地があります。開発者は生成されたコードを修正して特定の要件を満たし、品質を向上させることができます。
GPT-エンジニアのセットアッププロセスは、わかりやすいガイドにまとめられています。以下にステップバイステップの手順を示します:
1. 環境の準備:ダイブする前に、プロジェクトディレクトリが準備されていることを確認してください。ターミナルを開き、次のコマンドを実行します
- 新しいディレクトリ ‘website’ を作成する:
mkdir website- ディレクトリに移動する:
cd website
2. リポジトリのクローン: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. ナビゲーションと依存関係のインストール: クローンしたら、ディレクトリに切り替えて、必要なすべての依存関係をインストールします。make install
4. 仮想環境の有効化:お使いのオペレーティングシステムに応じて、作成した仮想環境を有効化してください。
- macOS/Linux の場合:
source venv/bin/activate
- Windows の場合:APIキーのセットアップが異なるため、少し異なります:
set OPENAI_API_KEY=[あなたのAPIキー]
5. 設定 – APIキーの設定: OpenAIとのやり取りにはAPIキーが必要です。まだ持っていない場合は、OpenAIプラットフォームにサインアップし、次のようにします:
- macOS/Linux の場合:
export OPENAI_API_KEY=[あなたのAPIキー]
- Windows の場合(前述したとおり):
set OPENAI_API_KEY=[あなたのAPIキー]
6. プロジェクトの初期化とコード生成: GPT-エンジニアの魔法は、projectsフォルダ内にあるmain_promptファイルから始まります。
- 新しいプロジェクトを開始する場合:
cp -r projects/example/ projects/website
ここで、’website’ を選んだプロジェクト名に置き換えてください。
- テキストエディタを使用して
main_promptファイルを編集し、プロジェクトの要件を記述します。

- プロンプトに満足したら、次を実行します:
gpt-engineer projects/website
生成されたコードは、プロジェクトフォルダ内のworkspaceディレクトリに保存されます。
7. ポスト生成: GPT-エンジニアは強力ですが、常に完璧ではありません。生成されたコードを検査し、必要に応じて手動で変更を加え、すべてがスムーズに動作することを確認してください。
実行例
プロンプト:
「Pythonで基本的なStreamlitアプリを開発し、対話的なチャートを介してユーザーデータを視覚化します。ユーザーはCSVファイルをアップロードし、チャートのタイプ(バー、パイ、ラインなど)を選択し、データを動的に視覚化できるようにする必要があります。データ操作にはPandasなどのライブラリを使用し、視覚化にはPlotlyを使用できます。」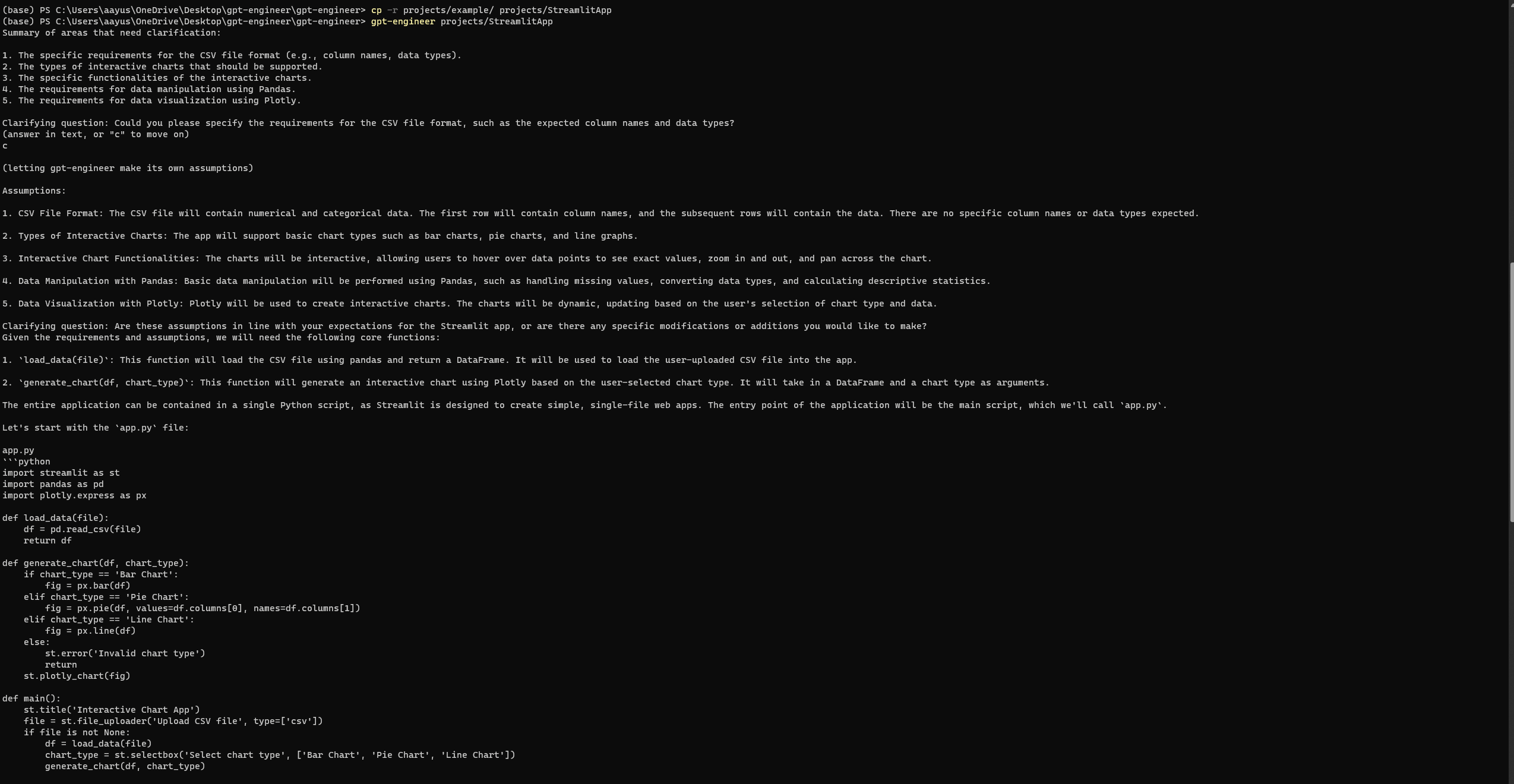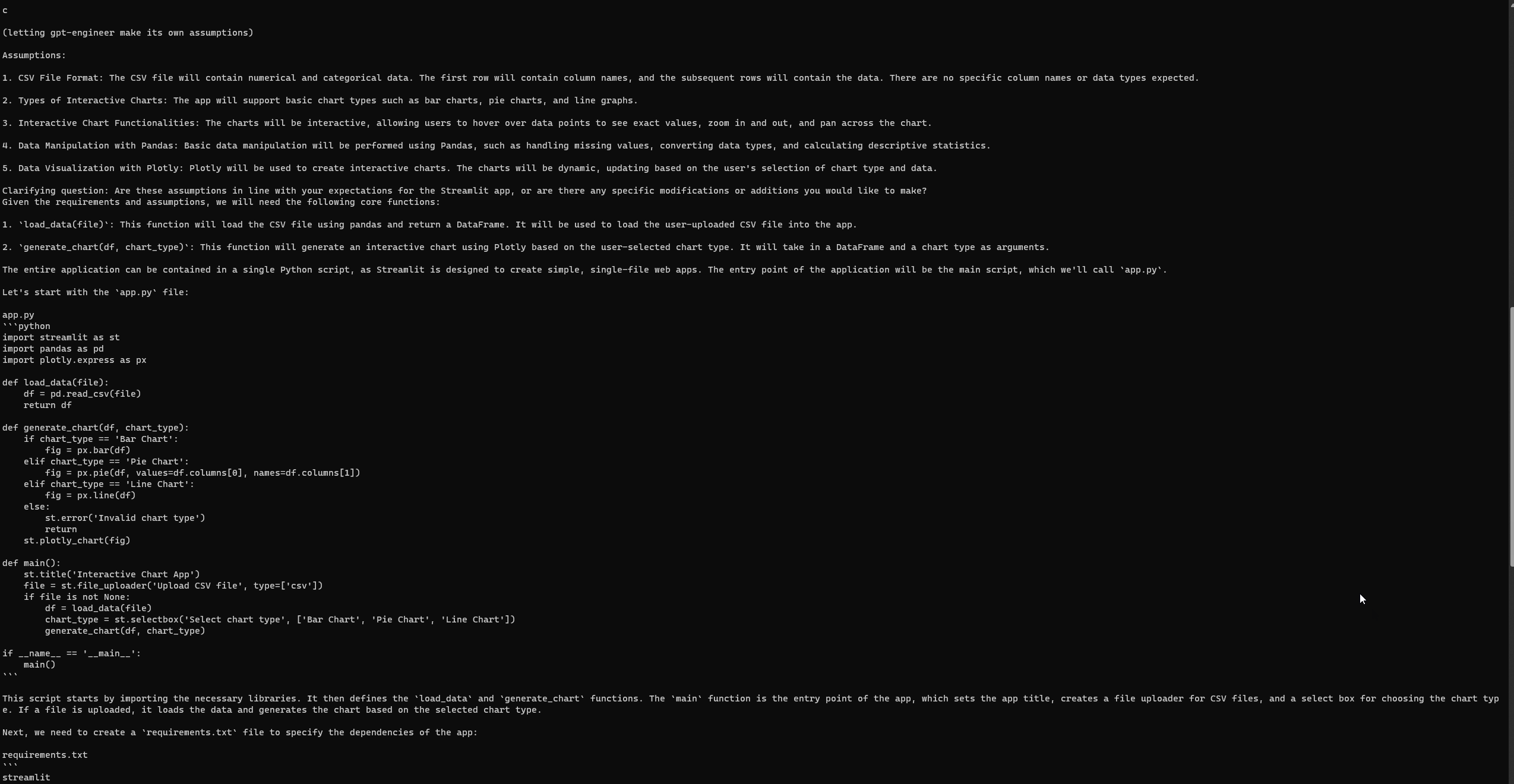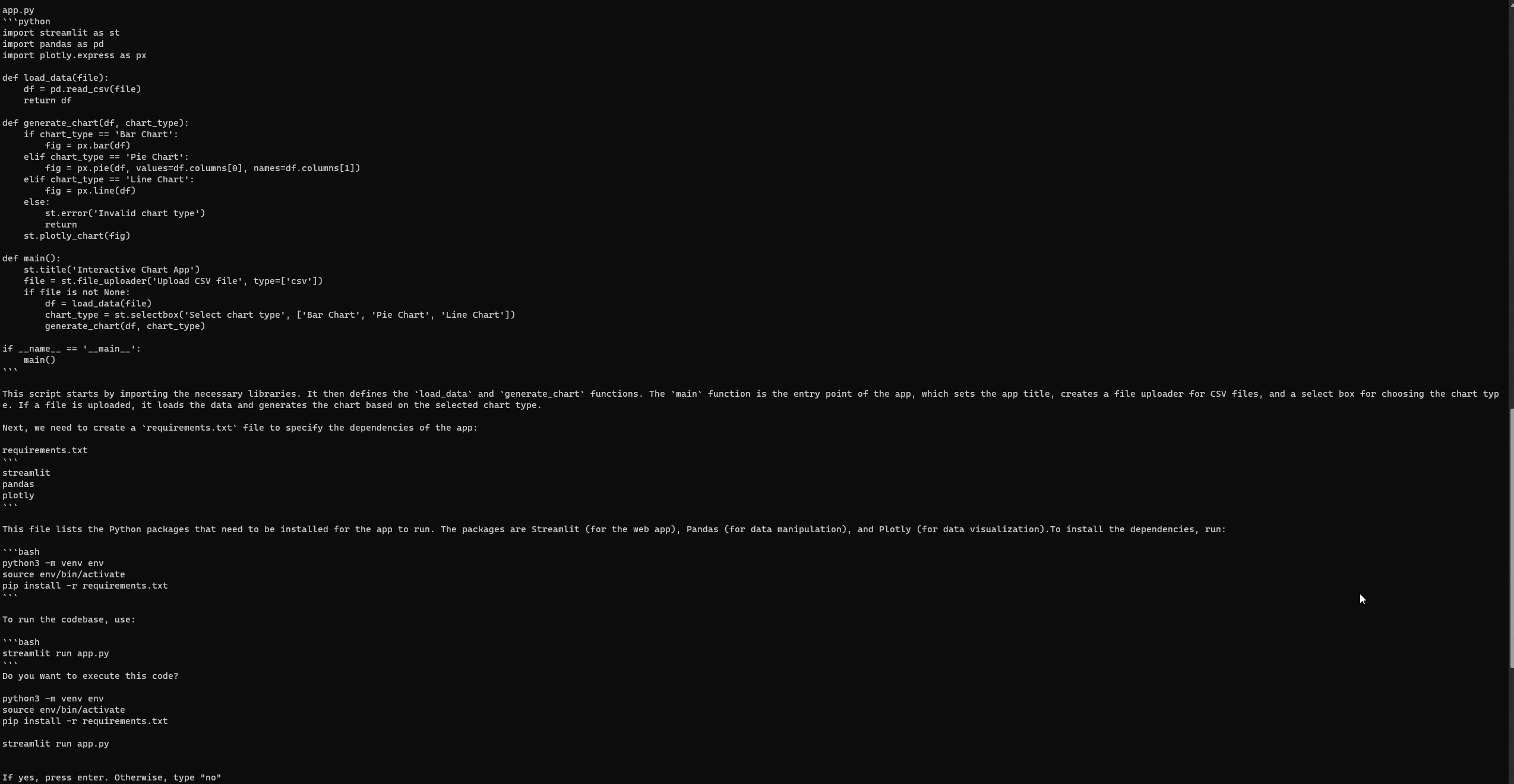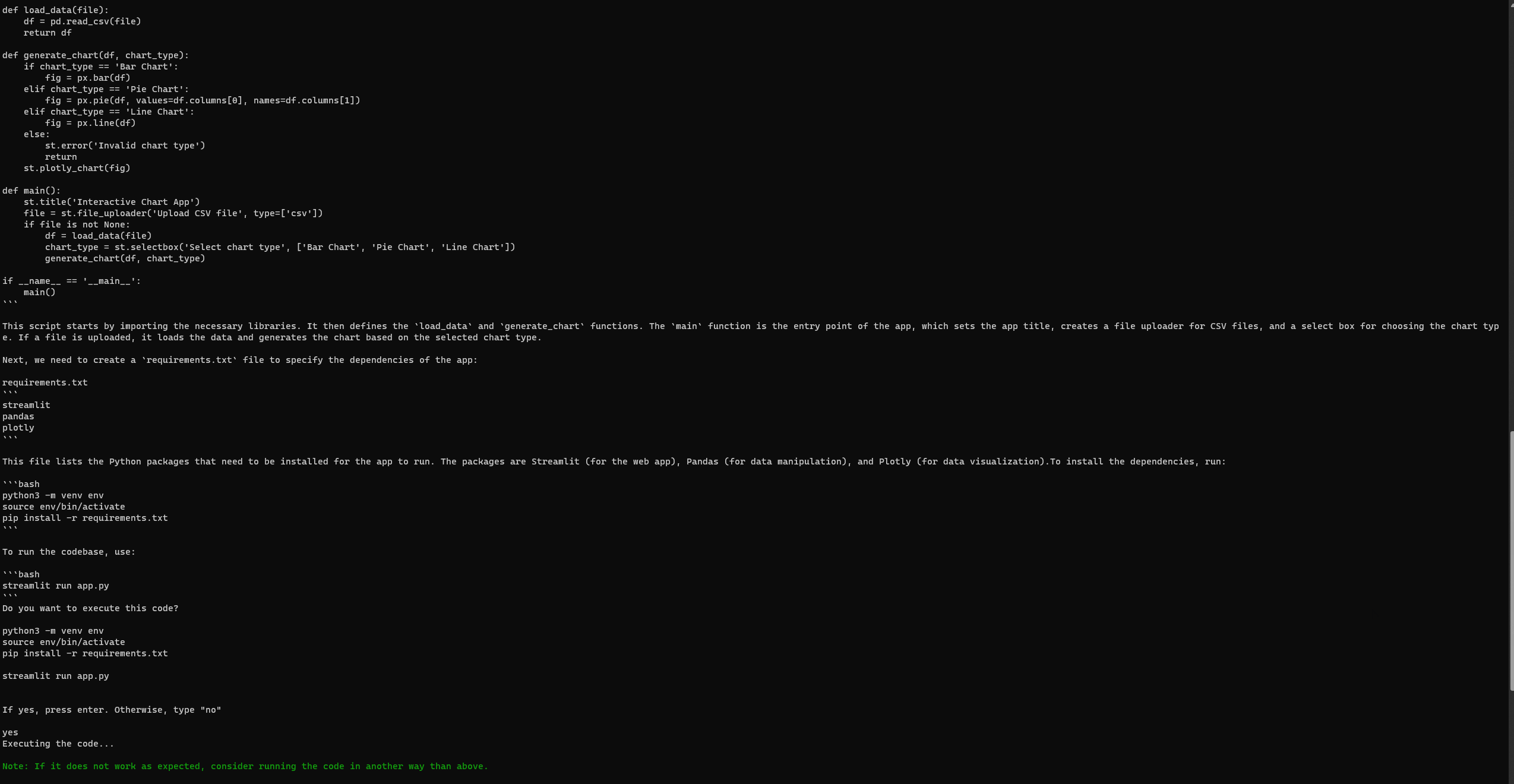
GPT-エンジニアのセットアップと実行
Auto-GPTと同様に、GPT-エンジニアも完全なセットアップ後にエラーが発生することがあります。しかし、3回目の試みで、次のStreamlitのウェブページに正常にアクセスできました。公式のGPT-エンジニアリポジトリの問題ページでエラーを確認してください。

GPT-エンジニアを使用して生成されたStreamlitアプリ
AIエージェントの現在のボトルネック
運用費用
Auto-GPTが実行する単一のタスクには多くのステップが含まれる場合があります。重要なことは、これらのステップのそれぞれが個別に請求される可能性があり、コストが増えるということです。Auto-GPTは反復的なループに陥り、約束された結果を提供できなくなることがあります。このような事象は、信頼性を損ない、投資を損ねます。
Auto-GPTを使用して短いエッセイを作成したいと考えてみてください。エッセイの理想的な長さは8Kトークンですが、作成プロセスではモデルがコンテンツを最終的に仕上げるために複数の中間ステップに入ります。8kコンテキスト長でGPT-4を使用している場合、入力には$0.03が請求されます。そして、出力には$0.06の費用がかかります。さて、モデルが予期せぬループにハマり、何度も一部をやり直すとします。プロセスがより長くなるだけでなく、各繰り返しはコストに追加されます。
これを防ぐためには:
OpenAIの請求と制限で使用制限を設定します:
- ハードリミット:設定した閾値を超えた使用を制限します。
- ソフトリミット:閾値に達したときにメールアラートを送信します。
機能の制限
Auto-GPTの機能は、そのソースコードに示されているように、特定の制約があります。その問題解決戦略は、固有の関数とGPT-4のAPIによって制御されます。詳細な議論や可能な回避策については、Auto-GPT Discussionを参照してください。
AIが労働市場に与える影響
AIと労働市場の関係は常に変化し、この研究論文で詳しく文書化されています。重要なポイントは、技術の進歩がしばしば熟練労働者に利益をもたらす一方で、ルーティン業務に従事している人々にリスクをもたらすということです。実際、技術の進歩は一部のタスクを置き換えるかもしれませんが、同時に多様で労働集約的なタスクの道を開く可能性もあります。

米国の労働者の推定80%が、LLM(言語学習モデル)が彼らの日常業務の約10%に影響を与える可能性があるという統計があります。この統計は、AIと人間の役割が統合されていることを示しています。
労働市場におけるAIの二面性の役割:
- ポジティブな側面:AIは顧客サービスから金融アドバイスまで多くのタスクを自動化でき、専任チームのための資金が不足している小企業に休息を与えることができます。
- 懸念点:自動化の利点は、特に人間の関与が不可欠な顧客サポートなどのセクターでの潜在的な雇用の喪失について疑問を投げかけます。これに加えて、AIが機密データにアクセスするという倫理的な問題があります。これには、透明性、説明責任、AIの倫理的な使用を保証する強力なインフラストラクチャが必要です。
結論
明らかに、ChatGPT、Auto-GPT、およびGPT-Engineerなどのツールは、技術とユーザーの相互作用を再構築する最前線に立っています。これらのAIエージェントは、オープンソース運動にルーツを持ち、スケジューリングからソフトウェア開発までのタスクを効率化する可能性を具現化しています。
AIが私たちの日常生活に深く統合される未来に進むにつれて、AIの能力を受け入れることと人間の役割を守ることのバランスが重要になります。より広範なスペクトルでは、AI労働市場のダイナミックは成長の機会と課題の二重のイメージを描き、技術の倫理と透明性の意識的な統合を要求しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






