AudioLDM 2, でも速くなりました ⚡️
AudioLDM 2, でも速くなりました ⚡️
![]()
AudioLDM 2は、Haohe Liuらによる「AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining」で提案されました。AudioLDM 2は、テキストプロンプトを入力として受け取り、対応するオーディオを予測します。リアルな音効、人の声、音楽を生成することができます。
生成されるオーディオは高品質ですが、元の実装での推論の実行は非常に遅いです。10秒のオーディオサンプルを生成するのに30秒以上かかります。これは、深いマルチステージのモデリングアプローチ、大きなチェックポイントサイズ、最適化されていないコードなど、複数の要素の組み合わせによるものです。
このブログ記事では、Hugging Faceの🧨 Diffusersライブラリを使用してAudioLDM 2を使用する方法を紹介し、半精度、フラッシュアテンション、コンパイルなどのコードの最適化、スケジューラの選択、ネガティブプロンプティングなどのモデルの最適化を探求します。その結果、推論時間を10倍以上短縮でき、出力オーディオの品質の低下は最小限です。ブログ記事には、コードはすべて含まれていますが、説明は少なめです。
最後まで読んでください。わずか1秒で10秒のオーディオサンプルを生成する方法がわかります!
モデルの概要
Stable Diffusionに触発され、AudioLDM 2はテキストからオーディオへの潜在的な拡散モデル(LDM)であり、テキストの埋め込みから連続的なオーディオ表現を学習します。
全体の生成プロセスは以下のように要約されます:
- テキスト入力x\boldsymbol{x}xを与えると、2つのテキストエンコーダーモデルが使用され、テキストの埋め込みが計算されます:CLAPのテキストブランチとFlan-T5のテキストエンコーダー
E1=CLAP(x);E2=T5(x) \boldsymbol{E}_{1} = \text{CLAP}\left(\boldsymbol{x} \right); \quad \boldsymbol{E}_{2} = \text{T5}\left(\boldsymbol{x}\right) E1=CLAP(x);E2=T5(x)
CLAPのテキスト埋め込みは、対応するオーディオサンプルの埋め込みと一致するようにトレーニングされますが、Flan-T5の埋め込みはテキストの意味の表現により適しています。
- これらのテキストの埋め込みは、個別の線形射影を介して共有の埋め込み空間に射影されます:
P1=WCLAPE1;P2=WT5E2 \boldsymbol{P}_{1} = \boldsymbol{W}_{\text{CLAP}} \boldsymbol{E}_{1}; \quad \boldsymbol{P}_{2} = \boldsymbol{W}_{\text{T5}}\boldsymbol{E}_{2} P1=WCLAPE1;P2=WT5E2
このdiffusersの実装では、これらの射影はAudioLDM2ProjectionModelによって定義されます。
- GPT2言語モデル(LM)は、射影されたCLAPおよびFlan-T5の埋め込みに基づいて、N個の新しい埋め込みベクトルのシーケンスを自己回帰的に生成します:
Ei=GPT2(P1,P2,E1:i−1)for i=1,…,N \boldsymbol{E}_{i} = \text{GPT2}\left(\boldsymbol{P}_{1}, \boldsymbol{P}_{2}, \boldsymbol{E}_{1:i-1}\right) \qquad \text{for } i=1,\dots,N Ei=GPT2(P1,P2,E1:i−1)for i=1,…,N
- 生成された埋め込みベクトルE1:N\boldsymbol{E}_{1:N}E1:NおよびFlan-T5のテキスト埋め込みE2\boldsymbol{E}_{2}E2は、LDM内の逆拡散プロセスを介してランダムな潜在変数をノイズ除去するためのクロスアテンション条件付けとして使用されます。LDMは、合計T回の逆拡散プロセスで実行されます:
zt=LDM(zt−1∣E1:N,E2)for t=1,…,T \boldsymbol{z}_{t} = \text{LDM}\left(\boldsymbol{z}_{t-1} | \boldsymbol{E}_{1:N}, \boldsymbol{E}_{2}\right) \qquad \text{for } t = 1, \dots, T zt=LDM(zt−1∣E1:N,E2)for t=1,…,T
初期の潜在変数z0は、正規分布N(0,I)から引かれます。LDMのUNetは、他のほとんどのLDMとは異なり、2つのクロスアテンション埋め込み、GPT2の言語モデルからのE1:Nと、Flan-T5からのE2を取ります。
- 最終的なノイズ除去された潜在変数zTは、VAEデコーダに渡され、Melスペクトログラムsを復元します。
s=VAEdec(zT)
- Melスペクトログラムは、ボコーダに渡され、出力オーディオ波形yを取得します。
y=Vocoder(s)
以下の図は、テキスト入力がテキストコンディショニングモデルを通過する様子を示しています。LDMでは、2つのプロンプト埋め込みがクロスコンディショニングとして使用されます。
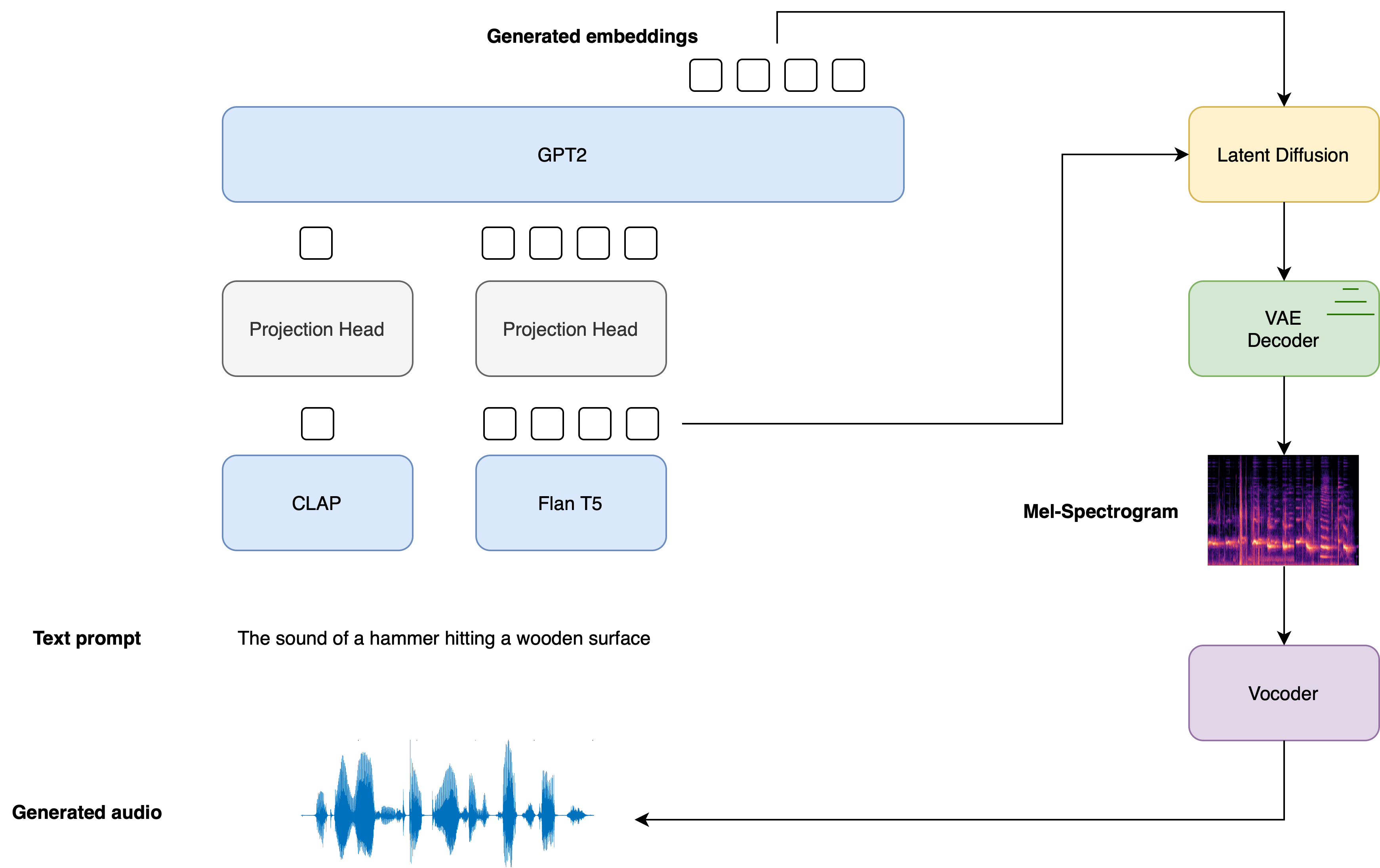
AudioLDM 2モデルのトレーニングの詳細については、AudioLDM 2の論文を参照してください。
Hugging Face 🧨 Diffusersは、この多段階の生成プロセスを1つの呼び出し可能オブジェクトにラップするエンドツーエンドの推論パイプラインクラスAudioLDM2Pipelineを提供し、わずか数行のコードでテキストからオーディオサンプルを生成できるようにします。
AudioLDM 2には3つのバリアントがあります。これらのチェックポイントの2つは、テキストからオーディオの生成の一般的なタスクに適用できます。3番目のチェックポイントは、テキストから音楽の生成に特化してトレーニングされています。3つの公式チェックポイントの詳細については、Hugging Face Hubで確認してください。
AudioLDM 2の生成プロセスの概要を説明しましたので、これを実践に移しましょう!
パイプラインの読み込み
このチュートリアルの目的で、事前学習済みの重みを使用してパイプラインを初期化します。事前学習済みの重みをロードするには、.from_pretrainedメソッドを使用します。これにより、パイプラインがインスタンス化され、事前学習済みの重みがロードされます。
from diffusers import AudioLDM2Pipeline
model_id = "cvssp/audioldm2"
pipe = AudioLDM2Pipeline.from_pretrained(model_id)Output:
Loading pipeline components...: 100%|███████████████████████████████████████████| 11/11 [00:01<00:00, 7.62it/s]パイプラインは、通常のPyTorch nnモジュールと同様に、GPUに移動することができます。
pipe.to("cuda");素晴らしいです!ジェネレータを定義し、再現性のためにシードを設定します。これにより、LDMモデルの開始潜在変数を固定して、プロンプトを調整し、生成に与える影響を観察することができます。
import torch
generator = torch.Generator("cuda").manual_seed(0)それでは、最初の生成を行いましょう!このノートブック全体で同じ実行例を使用し、オーディオ生成を固定テキストプロンプトにコンディション付け、同じシードを使用します。生成されるオーディオの長さは、audio_length_in_s引数で制御されます。デフォルトでは、LDMのトレーニングに使用されたオーディオの長さ(10.24秒)です。
prompt = "The sound of Brazilian samba drums with waves gently crashing in the background"
audio = pipe(prompt, audio_length_in_s=10.24, generator=generator).audios[0]出力:
100%|███████████████████████████████████████████| 200/200 [00:13<00:00, 15.27it/s]すごい!この実行には約13秒かかりました。出力オーディオを聞いてみましょう:
from IPython.display import Audio
Audio(audio, rate=16000)お使いのブラウザはオーディオ要素をサポートしていません。
テキストプロンプトに似ていますね!音質は良いですが、背景ノイズが残っています。パイプラインには、パイプラインが特定の特徴を生成しないようにするためにネガティブプロンプトを提供することができます。この場合、低品質のオーディオを生成することをモデルに避けさせるネガティブプロンプトを渡します。 audio_length_in_s 引数を省略し、デフォルト値を使用します:
negative_prompt = "低品質、平均品質."
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]出力:
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.50it/s]ネガティブプロンプトを使用する場合、推論時間は変わりません。単純に、LDMへの入力をネガティブ入力に置き換えるだけです。つまり、オーディオの品質が向上する場合、推論時間も無料で向上します。
生成されたオーディオを聞いてみましょう:
Audio(audio, rate=16000)お使いのブラウザはオーディオ要素をサポートしていません。
全体的なオーディオの品質が改善されています。ノイズのアーティファクトが少なく、オーディオは一般的により鮮明に聞こえます。 1{}^11 実際には、通常、最初の世代から2番目の世代への推論時間の短縮が見られます。これは、計算を最初に実行する際に発生するCUDAの「ウォームアップ」によるものです。2番目の世代は、実際の推論時間のより良いベンチマークです。
最適化1:フラッシュアテンション
PyTorch 2.0以降では、torch.nn.functional.scaled_dot_product_attention(SDPA)関数を介した注意操作の最適化およびメモリ効率の高い実装が提供されています。この関数は、入力に応じていくつかの組み込みの最適化を自動的に適用し、バニラのアテンション実装よりも高速かつメモリ効率が良くなります。全体的に、SDPA関数は、Dao et. al.によって提案されたFlash Attentionと似た動作を提供します。
これらの最適化は、PyTorch 2.0がインストールされていて、torch.nn.functional.scaled_dot_product_attentionが利用可能な場合に、Diffusersでデフォルトで有効になります。公式の手順に従ってtorch 2.0以上をインストールし、その後、パイプラインをそのまま使用します 🚀
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]出力:
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.60it/s]diffusersでSDPAを使用する詳細については、対応するドキュメントを参照してください。
最適化2:ハーフプレシジョン
デフォルトでは、AudioLDM2Pipelineはモデルの重みをfloat32(完全)精度でロードします。すべてのモデル計算もfloat32精度で実行されます。推論では、モデルの重みと計算を安全にfloat16(ハーフ)精度に変換することができます。これにより、推論時間とGPUメモリが改善され、生成品質にはほとんど変化がありません。
torch_dtype引数を.from_pretrainedに渡すことで、float16精度で重みをロードできます:
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda");float16精度での生成を実行し、オーディオ出力を聞いてみましょう:
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
Audio(audio, rate=16000)出力:
100%|███████████████████████████████████████████| 200/200 [00:09<00:00, 20.94it/s]お使いのブラウザはオーディオ要素をサポートしていません。
オーディオ品質は完全な精度の生成とほぼ変わりませんが、推論速度は約2秒高速化されます。私たちの経験では、float16精度を使用したdiffusersパイプラインでは、重要なオーディオの劣化は見られませんが、一貫して大幅な推論の高速化が得られます。したがって、デフォルトではfloat16精度を使用することをおすすめします。
最適化3:Torchコンパイル
さらなる高速化を得るために、新しいtorch.compile機能を使用することができます。パイプラインのUNetは通常、最も計算量の多い部分ですので、UNetをtorch.compileでラップし、他のサブモデル(テキストエンコーダとVAE)はそのままにします:
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)torch.compileでUNetをラップすると、通常最初の推論ステップは遅くなる傾向があります。これは、UNetの順伝搬をコンパイルするオーバーヘッドによるものです。長い実行を終わらせるために、コンパイルステップを含んだパイプラインを前方に実行してみましょう。最初の推論ステップでは、2分までかかることがありますので、お待ちください。
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]出力:
100%|███████████████████████████████████████████| 200/200 [01:23<00:00, 2.39it/s]素晴らしいですね!UNetがコンパイルされたので、完全な拡散プロセスを実行し、高速推論の恩恵を受けることができます。
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]出力:
100%|███████████████████████████████████████████| 200/200 [00:04<00:00, 48.98it/s]わずか4秒で生成されました!実際には、UNetを1度だけコンパイルする必要があり、その後のすべての生成で高速な推論が得られます。つまり、モデルのコンパイルにかかる時間は、後続の推論時間の利益によって償却されます。 torch.compileに関する詳細な情報やオプションについては、torch compileドキュメントを参照してください。
最適化4:スケジューラ
もう1つのオプションは、推論ステップの数を減らすことです。より効率的なスケジューラを選択することで、出力オーディオの品質を損なうことなく、ステップの数を減らすことができます。 AudioLDM2Pipelineと互換性のあるスケジューラを見つけるには、schedulers.compatibles属性を呼び出します:
pipe.scheduler.compatibles出力:
[diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler]よし!長いスケジューラのリストから選択できるよ 📝。デフォルトでは、AudioLDM 2はDDIMSchedulerを使用し、良質な音声生成には200回の推論ステップが必要です。しかし、DPMSolverMultistepSchedulerなどのパフォーマンスの高いスケジューラは、類似の結果を得るために20-25回の推論ステップしか必要ありません。
では、AudioLDM 2のスケジューラをDDIMからDPM Multistepに切り替えてみましょう。元のDDIMSchedulerの設定からDPMSolverMultistepSchedulerを読み込むために、ConfigMixin.from_config()メソッドを使用します:
from diffusers import DPMSolverMultistepScheduler
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)推論ステップの数を20に設定し、新しいスケジューラで再度音声生成を実行しましょう。LDMの潜在変数の形状が変わらないため、コンパイルの手順を繰り返す必要はありません:
audio = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]出力:
100%|███████████████████████████████████████████| 20/20 [00:00<00:00, 49.14it/s]音声生成には1秒未満かかりました!生成された音声を聴いてみましょう:
Audio(audio, rate=16000)お使いのブラウザはオーディオ要素をサポートしていません。
元の音声サンプルとほぼ同じですが、生成時間はずっと短くなりました! 🧨 Diffusersパイプラインは、スケジューラや他のコンポーネントを簡単に交換できるように設計されています。
メモリについてはどうですか?
生成したいオーディオサンプルの長さは、LDMでデノイズする潜在変数の幅を決定します。UNetのクロスアテンション層のメモリは、シーケンスの長さ(幅)の二乗に比例して増加しますので、非常に長いオーディオサンプルを生成するとメモリ不足のエラーが発生する可能性があります。バッチサイズもメモリ使用量を制御し、生成するサンプルの数を制御します。
既に、モデルをfloat16のハーフ精度で読み込むことでメモリの節約ができることを述べました。PyTorch 2.0 SDPAを使用することもメモリの改善になりますが、非常に大きなシーケンス長には十分ではないかもしれません。
では、150秒の音声サンプルを生成してみましょう。また、num_waveforms_per_prompt``=4を設定することで、4つの候補オーディオを生成します。 num_waveforms_per_prompt``>1となると、生成されたオーディオとテキストプロンプトの間で自動スコアリングが行われます。オーディオとテキストプロンプトはCLAPオーディオテキスト埋め込み空間に埋め込まれ、その後余弦類似度スコアに基づいてランク付けされます。’best’の波形は位置0のものとしてアクセスできます。
UNetの潜在変数の幅が変わったため、新しい潜在変数の形状で別のtorchコンパイルステップを実行する必要があります。時間の節約のために、長いコンパイルの手順で最初に遭遇しないように、torchコンパイルなしでパイプラインを再読み込みします:
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda")
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]出力:
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
<ipython-input-33-c4cae6410ff5> in <cell line: 5>()
3 pipe.to("cuda")
4
----> 5 audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
23 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
OutOfMemoryError: CUDAのメモリが不足しています。1.95 GiBの割り当てを試みました。GPU 0の総容量は14.75 GiBで、そのうち1.66 GiBが空きです。プロセス414660は13.09 GiBのメモリを使用しています。割り当てられたメモリのうち、10.09 GiBはPyTorchによって割り当てられ、1.92 GiBはPyTorchによって予約されていますが未割り当てです。予約されているが未割り当てのメモリが大きい場合は、断片化を避けるためにmax_split_size_mbを設定してみてください。メモリ管理とPYTORCH_CUDA_ALLOC_CONFのドキュメントを参照してください高RAMを備えたGPUを持っていない場合、上記のコードはおそらくOOMエラーを返します。AudioLDM 2パイプラインにはいくつかのコンポーネントが関与していますが、使用されているモデルのみがいつでもGPU上にある必要があります。他のモジュールはCPUにオフロードできます。このテクニックはCPUオフロードと呼ばれ、メモリ使用量を削減することができ、推論時間へのペナルティは非常に低いです。
次の関数enable_model_cpu_offload()を使用して、パイプラインでCPUオフロードを有効にできます。
pipe.enable_model_cpu_offload()CPUオフロードを使用しての生成は、以前と同じです。
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]出力:
100%|███████████████████████████████████████████| 20/20 [00:36<00:00, 1.82s/it]これにより、パイプラインへの1回の呼び出しで、150秒の長さの4つのサンプルを生成することができます!大きなAudioLDM 2チェックポイントを使用すると、基本的なチェックポイントよりもメモリ使用量が高くなります(UNetのサイズが2倍以上(750Mパラメーター対350M)なので、メモリの節約トリックは特に効果的です。
結論
このブログ投稿では、🧨 Diffusersが提供する4つの最適化方法を紹介し、AudioLDM 2の生成時間を14秒から1秒未満に短縮しました。また、長いオーディオサンプルや大きなチェックポイントサイズのピークメモリ使用量を削減するために、半精度やCPUオフロードなどのメモリの節約トリックの使用方法も強調しました。
このブログ投稿はSanchit Gandhiによるものです。建設的なコメントをくださったVaibhav SrivastavさんとSayak Paulさんに感謝いたします。スペクトログラム画像のソース:メルスペクトログラムの理解。ウェーブフォーム画像のソース:Aalto音声処理。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






