「Amazon SageMaker Data WranglerでAWS Lake Formationを使用して細粒度のデータアクセス制御を適用する」
Applying Fine-Grained Data Access Control Using AWS Lake Formation with Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wranglerは、機械学習(ML)のためのデータ収集と準備にかかる時間を数週間から数分に短縮します。SageMaker Data Wranglerを使用することで、特徴量エンジニアリングとデータの準備プロセスを効率化し、データの選択、精製、探索、可視化、スケールでの処理など、データの準備ワークフローの各段階を単一のビジュアルインターフェースで完了することができます。データは、AWS Lake Formationで管理されるデータレイクに頻繁に保持され、直感的な許可または許可解除手順を使用して細かいアクセス制御を実装することができます。SageMaker Data Wranglerは、Lake FormationとAmazon Athenaの接続を使用した細かいデータアクセス制御をサポートしています。
お知らせいたしますが、SageMaker Data Wranglerは現在、Amazon EMRとの組み合わせでLake Formationの使用をサポートし、この細かいデータアクセス制限を提供しています。
データサイエンティストなどのデータ専門家は、高速なデータの準備のためにAmazon EMR上で実行されるApache Spark、Hive、Prestoのパワーを利用したいと考えていますが、学習曲線は急です。お客様は、Amazon EMRに接続してHiveやPrestoでアドホックなSQLクエリを実行し、内部メタストアまたは外部メタストア(AWS Glueデータカタログなど)のデータをクエリし、わずかなクリックでデータを準備する能力を求めていました。
この記事では、Lake Formationを中央データガバナンス機能として、Amazon EMRをビッグデータクエリエンジンとして使用して、SageMaker Data Wranglerへのアクセスを可能にする方法を紹介します。Lake Formationの機能により、分散データレイクを複数のアカウントでシンプルなアプローチでセキュリティ保護および管理することができ、細かいアクセス制御が提供されます。
ソリューションの概要
このソリューションは、サンプルデータセットであるTPCデータモデルを使用したエンドツーエンドのユースケースで示します。このデータは製品のトランザクションデータを表し、顧客の人口統計、在庫、ウェブ販売、プロモーションなどの情報を含んでいます。細かいデータアクセス許可を示すために、以下の2人のユーザを考慮します:
- マーケティングチームのデータサイエンティストであるDavid。彼は顧客セグメンテーションのモデル構築を担当しており、機密情報ではない顧客データにのみアクセスを許可されています。
- セールスチームのデータサイエンティストであるTina。彼女は特定の地域のセールスデータにアクセスする必要があり、セールス予測モデルの構築を担当しています。また、彼女は製品チームにイノベーションの支援をしているため、製品データにもアクセスする必要があります。
このアーキテクチャは以下のように実装されています:
- Lake Formationはデータレイクを管理し、生データはAmazon Simple Storage Service(Amazon S3)バケットで利用できます
- Amazon EMRを使用してデータレイクからデータをクエリし、Sparkを使用してデータの準備を行います
- AWS Identity and Access Management(IAM)ロールを使用して、Lake Formationを介してデータアクセスを管理します
- SageMaker Data Wranglerは、インタラクティブにクエリを実行し、データを準備するための単一のビジュアルインターフェースとして使用されます
次の図は、このアーキテクチャを示しています。アカウントAはデータレイクアカウントであり、抽出、変換、ロード(ETL)プロセスを介して取得したすべてのML対応データが格納されています。アカウントBはデータサイエンスアカウントであり、一連のデータサイエンティストがSageMaker Data Wranglerを使用してデータ変換をコンパイルおよび実行します。アカウントBのSageMaker Data WranglerがLake Formationの権限を介してアカウントAのデータレイク内のデータテーブルにアクセスするためには、必要な権限をアクティブ化する必要があります。
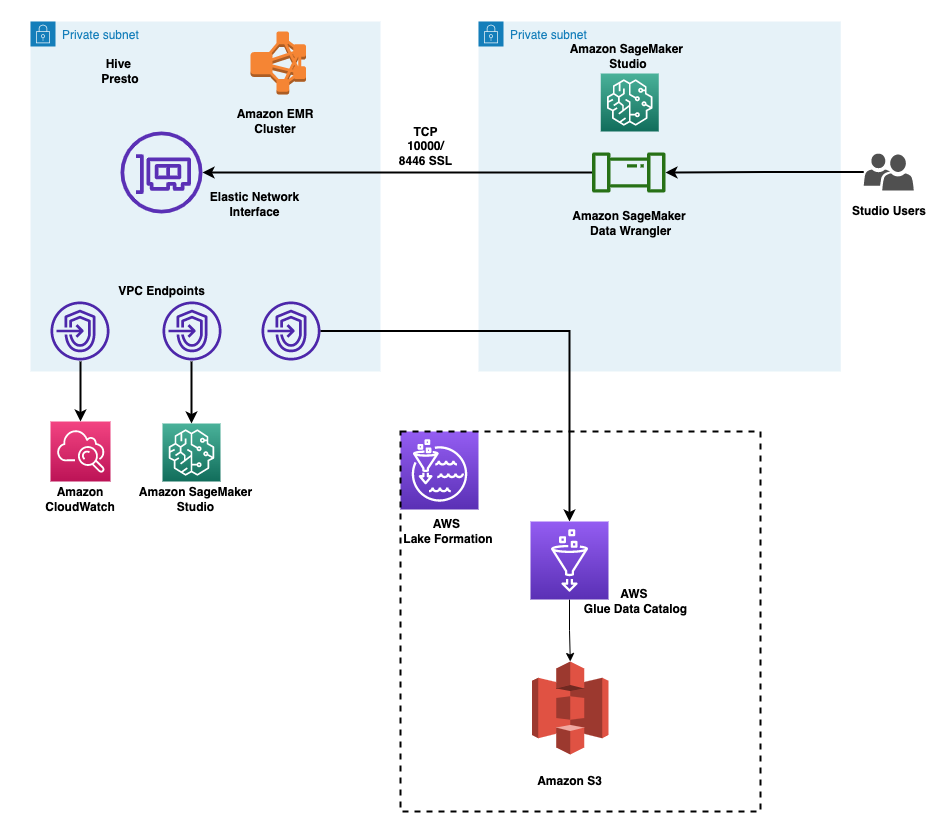
このソリューションのアーキテクチャコンポーネントを設定するために、提供されるAWS CloudFormationスタックを使用することができます。
前提条件
開始する前に、以下の前提条件を確認してください:
- AWSアカウント
- 管理者アクセス権限を持つIAMユーザ
- S3バケット
AWS CloudFormationを使用してリソースをプロビジョニングする
このソリューションのアーキテクチャをエンドツーエンドのテストおよび繰り返しデプロイを容易にするために、CloudFormationテンプレートを提供します。このテンプレートの出力は以下の通りです:
- データレイク用のS3バケット。
- EMRクラスタ(EMRランタイムロールが有効化されている)。Amazon EMRでランタイムロールを使用する詳細については、Amazon EMRでランタイムロールを構成する手順を参照してください。ランタイムロールをEMRクラスタに関連付けることは、Amazon EMR 6.9でサポートされています。次の構成が完了していることを確認してください:
- Amazon EMRでセキュリティ設定を作成します。
- EMRランタイムロールの信頼ポリシーには、EMR EC2インスタンスプロファイルがそのロールを引き受けることができるようにする必要があります。
- EMR EC2インスタンスプロファイルロールはEMRランタイムロールを引き受けることができるようにする必要があります。
- EMRクラスタは転送中の暗号化で作成される必要があります。
- データレイク内のデータにアクセスするための、細かい権限を持つIAMロール:
- マーケティングデータアクセスロール
- セールスデータアクセスロール
- 2つのユーザプロファイルとAmazon SageMaker Studioドメイン。ユーザのSageMaker Studio実行ロールには、ユーザが対応するEMRランタイムロールを引き受けることを許可する権限があります。
- EMR接続に使用するロールの選択を有効にするライフサイクル設定。
- TPCデータでポピュレートされたLake Formationデータベース。
- セットアップに必要なネットワーキングリソース、VPC、サブネット、セキュリティグループなど。
Amazon EMR のデータ転送のための暗号化証明書を作成する
Amazon EMR リリースバージョン 4.8.0 以降では、セキュリティ構成を使用してデータ転送の暗号化に必要なアーティファクトを指定するオプションがあります。私たちは PEM 証明書を手動で作成し、それらを .zip ファイルに含め、S3 バケットにアップロードし、そして Amazon S3 で .zip ファイルを参照します。おそらく、クラスタインスタンスが存在する VPC ドメインへのアクセスを可能にするワイルドカード証明書であるプライベートキー PEM ファイルを構成する必要があります。例えば、クラスタが us-east-1 リージョンに存在する場合、証明書構成でクラスタへのアクセスを許可するために、証明書の subject 定義に CN=*.ec2.internal を指定することができます。クラスタが us-west-2 に存在する場合は、CN=*.us-west-2.compute.internal を指定することができます。
次のコマンドをシステムのターミナルで実行します。これにより PEM 証明書が生成され、それらが .zip ファイルに結合されます:
openssl req -x509 -newkey rsa:1024 -keyout privateKey.pem -out certificateChain.pem -days 365 -nodes -subj '/C=US/ST=Washington/L=Seattle/O=MyOrg/OU=MyDept/CN=*.us-east-2.compute.internal'
cp certificateChain.pem trustedCertificates.pem
zip -r -X my-certs.zip certificateChain.pem privateKey.pem trustedCertificates.pem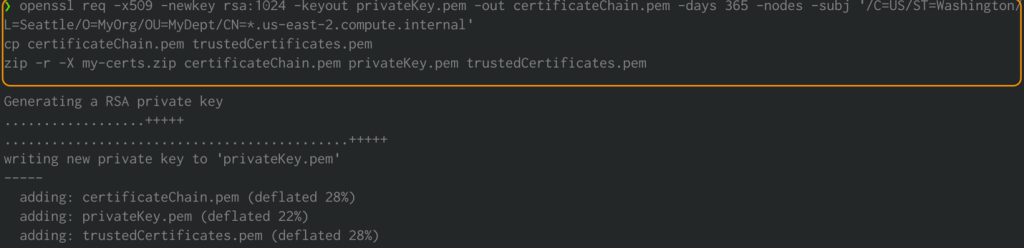
my-certs.zip を、この演習を実行するための同じリージョンの S3 バケットにアップロードします。アップロードしたファイルの S3 URI をコピーしておいてください。これは CloudFormation テンプレートを起動する際に必要です。
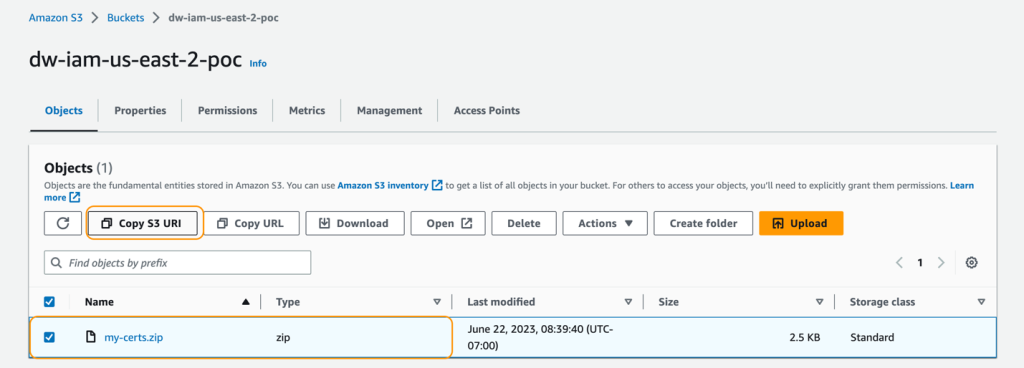
この例はコンセプト実証のデモンストレーションです。自己署名証明書の使用は推奨されず、潜在的なセキュリティリスクを引き起こす可能性があります。本番システムでは、信頼できる認証局(CA)から証明書を発行することをお勧めします。
CloudFormation テンプレートのデプロイ
ソリューションをデプロイするには、次の手順を完了します:
- IAM ユーザーとして AWS Management Console にサインインし、できれば管理者ユーザーとしてサインインします。
- CloudFormation テンプレートを起動するために、スタックを起動 を選択します:

- 次へ を選択します。
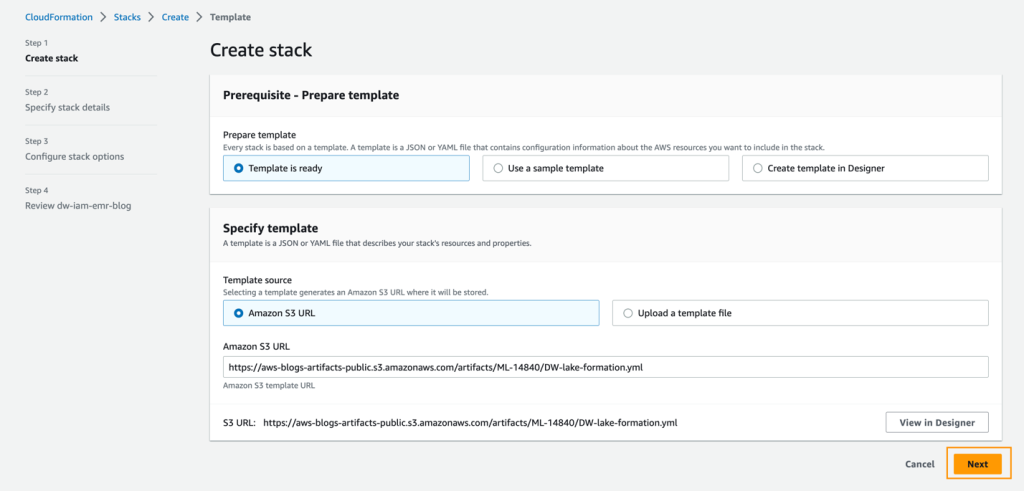
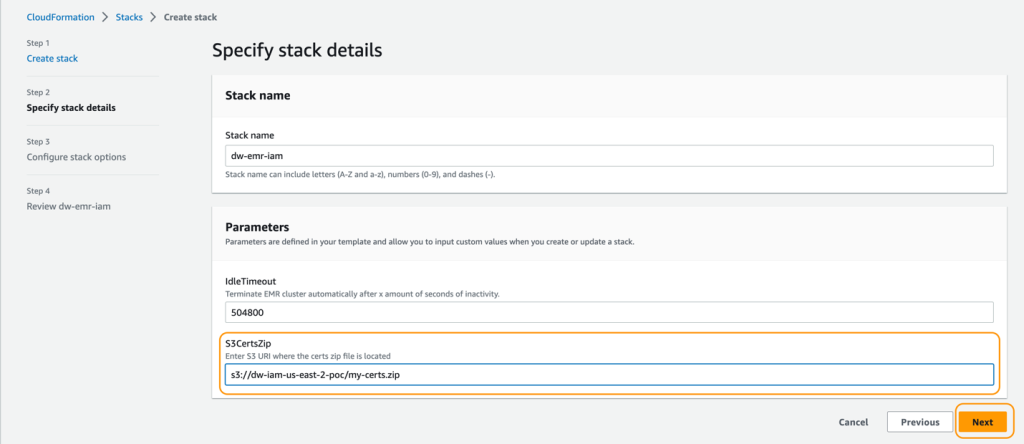
- スタック名 にスタックの名前を入力します。
- IdleTimeout に EMR クラスタのアイドルタイムアウトの値を入力します(クラスタが使用されていない場合に課金を回避するため)。
- S3CertsZip に EMR 暗号化キーを持つ S3 URI を入力します。
Amazon EMR 暗号化に必要なキーと .zip ファイルを生成する手順については、「Providing certificates for encrypting data in transit with Amazon EMR encryption」を参照してください。US East (N. Virginia) で展開する場合は、CN=*.ec2.internal を使用することを忘れないでください。データ暗号化のためのキーと証明書の作成についての詳細は、「Create keys and certificates for data encryption」を参照してください。.zip ファイルを CloudFormation スタックの展開と同じリージョンの S3 バケットにアップロードすることを忘れないでください。
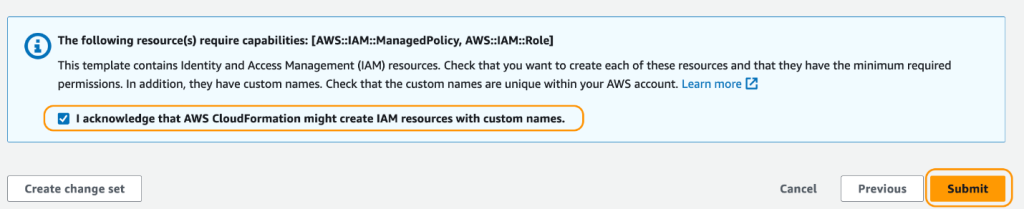
- レビューページで、AWS CloudFormationがリソースを作成できることを確認するために、チェックボックスを選択します。
- スタックの作成を選択します。
スタックの状態がCREATE_IN_PROGRESSからCREATE_COMPLETEに変わるまで待ちます。このプロセスは通常、10〜15分かかります。
スタックが作成されたら、Lake FormationでAmazon EMRがクエリを実行できるようにするために、Lake Formationの外部データフィルタリング設定を更新します。手順については、Lake Formationの入門を参照してください。セッションタグ値にはAmazon EMRを指定し、AWSアカウントIDの下にAWSアカウントIDを入力します。
データアクセス許可のテスト
必要なインフラストラクチャが整ったので、SageMaker Studioの2つのユーザーが細かいデータにアクセスできることを確認できます。確認すると、Davidは顧客に関する個人情報にアクセスできないはずです。Tinaは売上に関する情報にアクセスできます。それぞれのユーザータイプをテストしましょう。
Davidのユーザープロファイルのテスト
Davidのユーザープロファイルでデータアクセスをテストするには、次の手順を完了します。
- SageMakerコンソールで、ナビゲーションペインでドメインを選択します。
- SageMaker Studioドメインから、ユーザープロファイルdavid-non-sensitive-customerからSageMaker Studioを起動します。
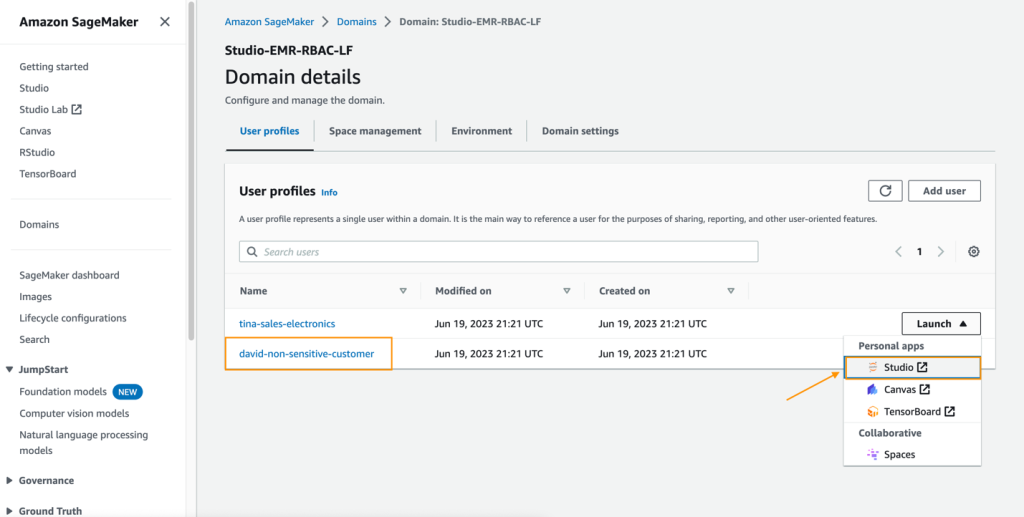
- SageMaker Studio環境で、Amazon SageMaker Data Wranglerフローを作成し、データの視覚的なインポートと準備を選択します。
または、ファイルメニューで新規を選択し、Data Wranglerフローを選択します。
この投稿の後半で、データフローを作成するためのこれらの手順について詳しく説明します。
Tinaのユーザープロファイルのテスト
TinaのSageMaker Studio実行ロールにより、2つのEMR実行ロールを使用してLake Formationデータベースにアクセスすることができます。これは、Tinaのファイルディレクトリ内の設定ファイルにロールARNをリストアップすることで実現されます。これらのロールは、SageMaker Studioライフサイクル設定を使用してアプリの再起動時に永続化することができます。Tinaのアクセスをテストするには、次の手順を完了します。
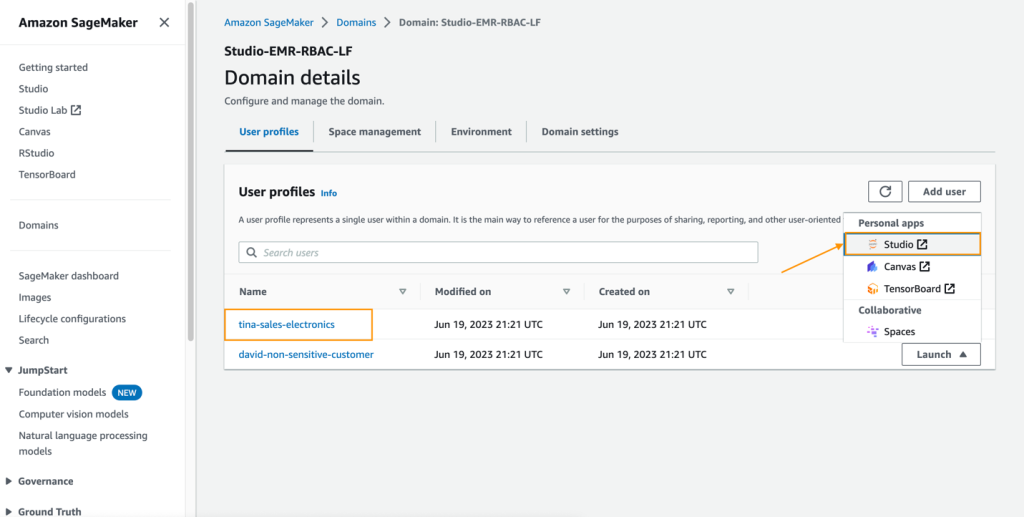
- SageMakerコンソールで、SageMaker Studioドメインに移動します。
- ユーザープロファイル
tina-sales-electronicsからSageMaker Studioを起動します。
ユーザープロファイルを切り替える際に、ブラウザ上の以前のSageMaker Studioセッションを閉じるのは良い習慣です。一度にアクティブなSageMaker Studioユーザーセッションは1つだけです。
- Data Wranglerデータフローを作成します。
次のセクションでは、SageMaker Data Wrangler内でCloudFormationテンプレートを介して作成した既存のEMRクラスタにデータソースとして接続する方法について説明します。デモの目的で、Davidのユーザープロファイルを使用します。
データフローを作成するには、次の手順を完了します。
- SageMakerコンソールで、ナビゲーションペインでドメインを選択します。
- CloudFormationテンプレートを実行して作成されたStudioDomainを選択します。
- ユーザープロファイルを選択し(この例ではDavidのプロファイル)、SageMaker Studioを起動します。
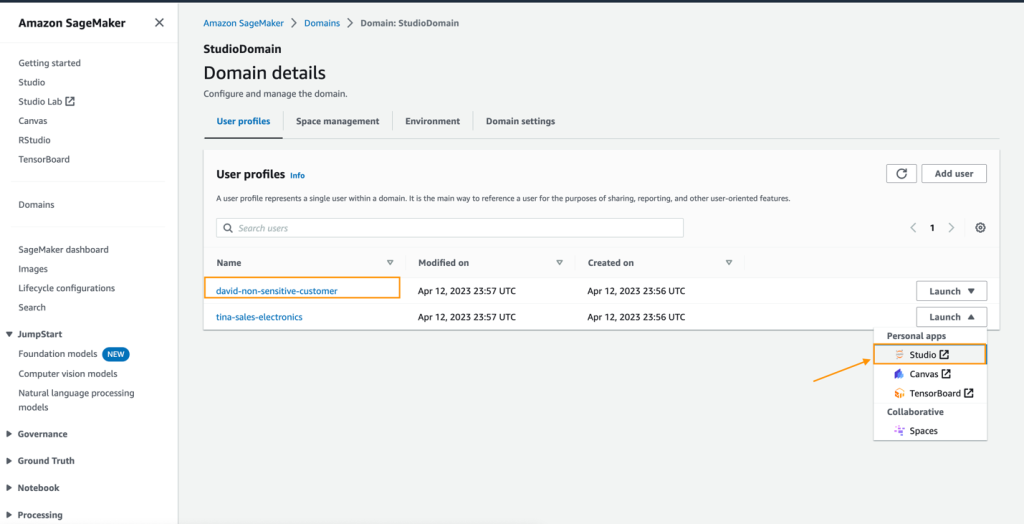
- 「Open Studio」を選択します。
- SageMaker Studioで新しいデータフローを作成し、「Import & prepare data visually」を選択します。
または、「ファイル」メニューから「新規」を選択し、「Data Wrangler flow」を選択します。
新しいフローを作成するには数分かかる場合があります。フローが作成されると、「Import data」ページが表示されます。
- SageMaker Data WranglerでAmazon EMRをデータソースとして追加するには、「データソースの追加」メニューで「Amazon EMR」を選択します。

SageMaker Studioの実行ロールにパーミッションがあるすべてのEMRクラスタを参照することができます。クラスタに接続するためには2つのオプションがあります。1つはインタラクティブなUIを介して接続する方法であり、もう1つは最初にAWS Secrets Managerを使用してEMRクラスタ情報を含むJDBC URLを使用してシークレットを作成し、UIで保存されたAWSシークレットARNを提供してPrestoまたはHiveに接続する方法です。この投稿では、最初の方法を使用します。
- 使用したいクラスタのいずれかを選択し、「次へ」を選択します。
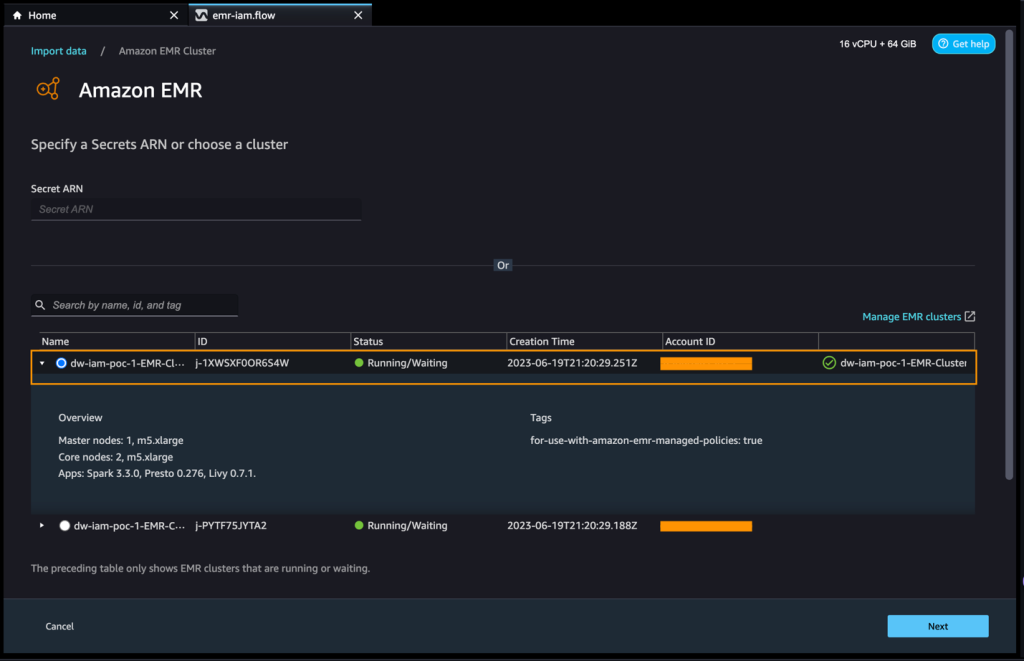
- 使用するエンドポイントを選択します。
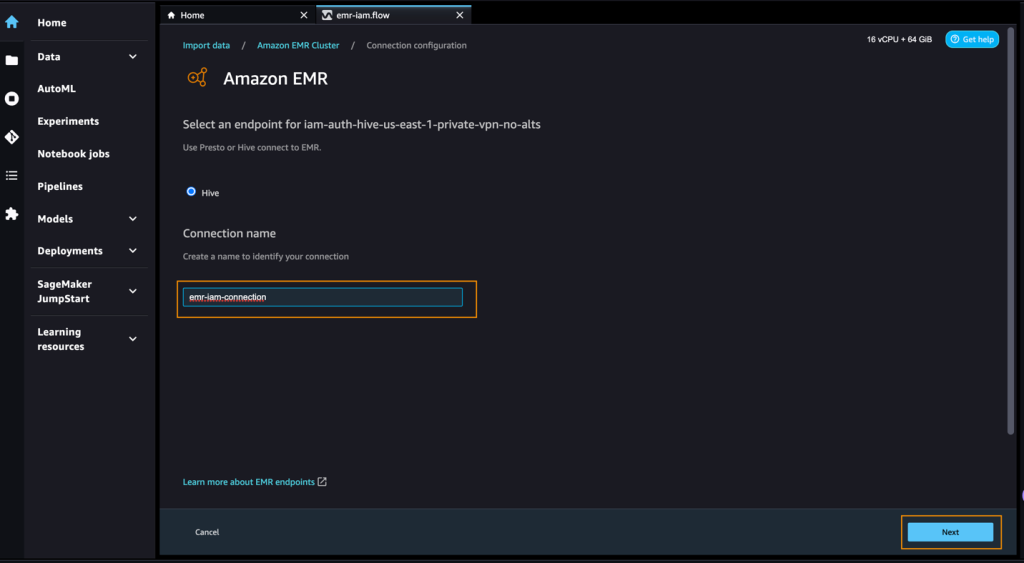
- 接続を識別するための名前を入力します(例:emr-iam-connection)、「次へ」を選択します。
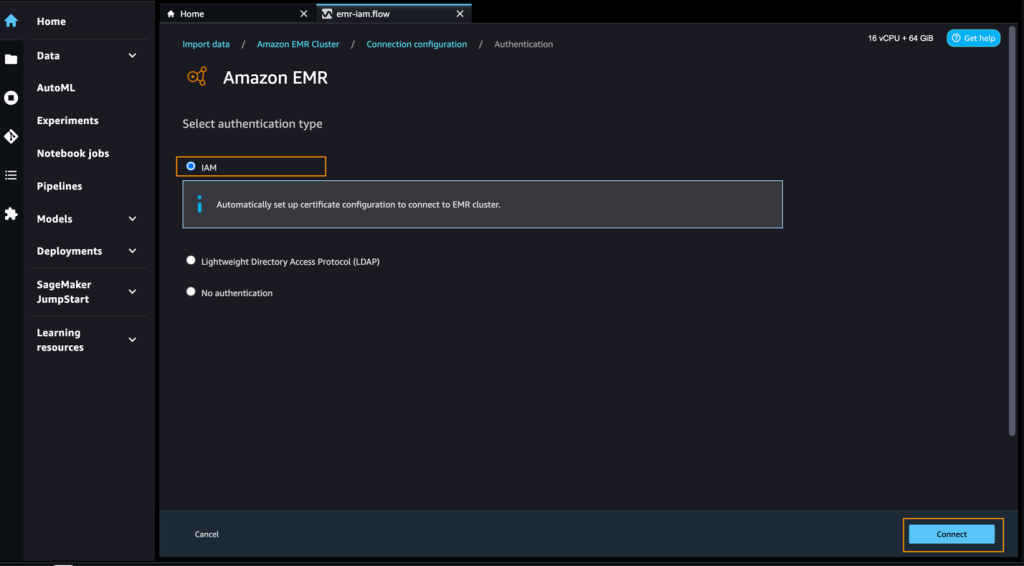
- 認証タイプとして「IAM」を選択し、「接続」を選択します。
接続が確立されると、データベースツリーやテーブルのプレビューまたはスキーマをインタラクティブに表示することができます。Amazon EMRからデータをクエリ、探索、可視化することもできます。プレビューでは、デフォルトで最大100レコードまで表示されます。クエリエディタにSQLステートメントを入力し、「実行」を選択すると、クエリがAmazon EMR Hiveエンジンで実行され、データのプレビューが表示されます。「実行中のクエリをキャンセル」を選択して、異常に長い時間がかかる場合に実行中のクエリをキャンセルすることもできます。
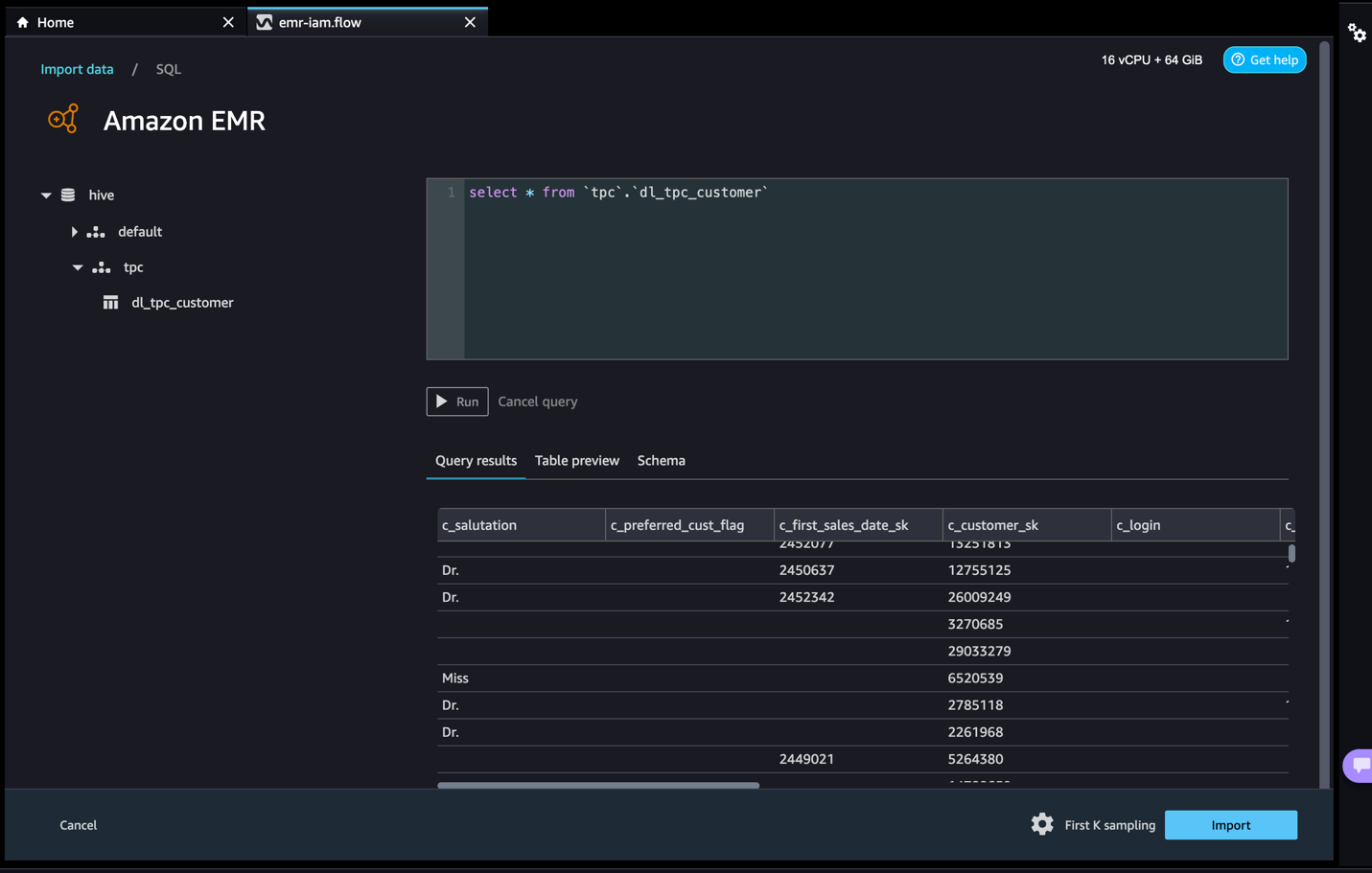
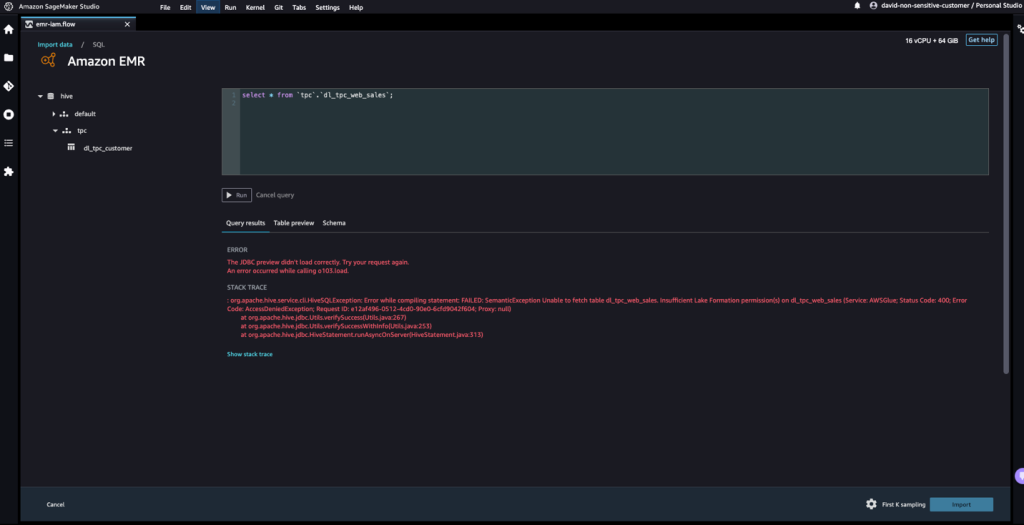
- Davidには権限がないテーブルからデータにアクセスしましょう。
クエリはエラーメッセージ「“Unable to fetch table dl_tpc_web_sales. Insufficient Lake Formation permission(s) on dl_tpc_web_sales.”」となります。
最後のステップはデータのインポートです。クエリされたデータが準備できたら、データの選択に対してサンプリングタイプ(FirstK、Random、またはStratified)とデータをData Wranglerにインポートするためのサンプリングサイズに応じてサンプリング設定を更新するオプションがあります。
- データをインポートするためにインポートを選択します。
次のページでは、データセットにさまざまな変換と重要な分析を追加することができます。
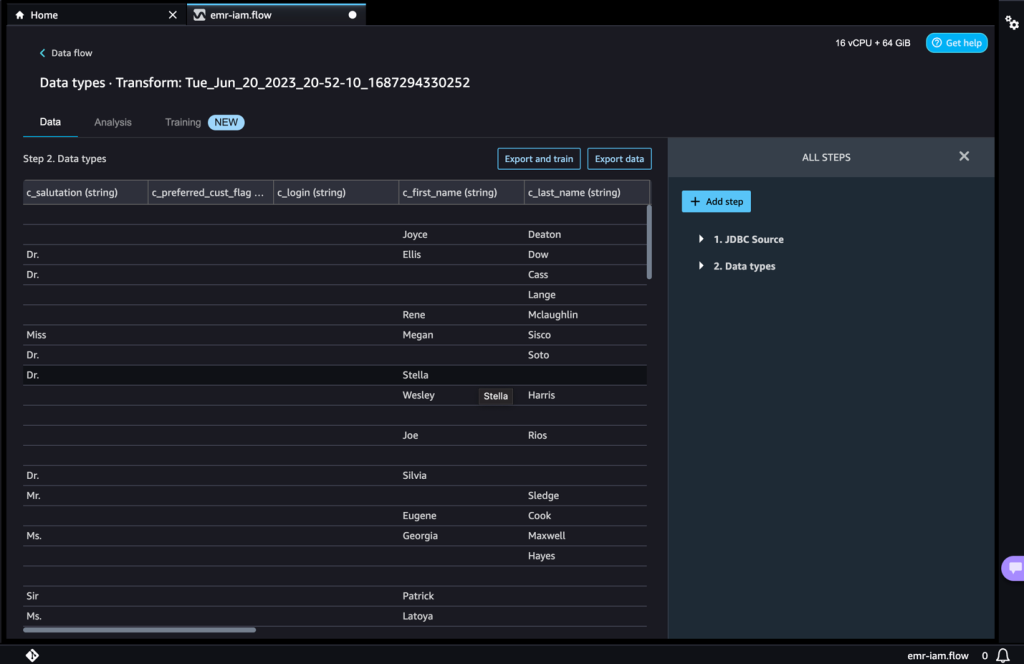
- データフローに移動し、必要に応じて変換と分析のための追加のステップをフローに追加します。
データ品質の問題を特定し、それらの問題を修正するための推奨事項を得るためにデータインサイトレポートを実行することができます。いくつかの例の変換を見てみましょう。
- データフロービューで、Hiveコネクタを使用してAmazon EMRをデータソースとして使用していることがわかります。
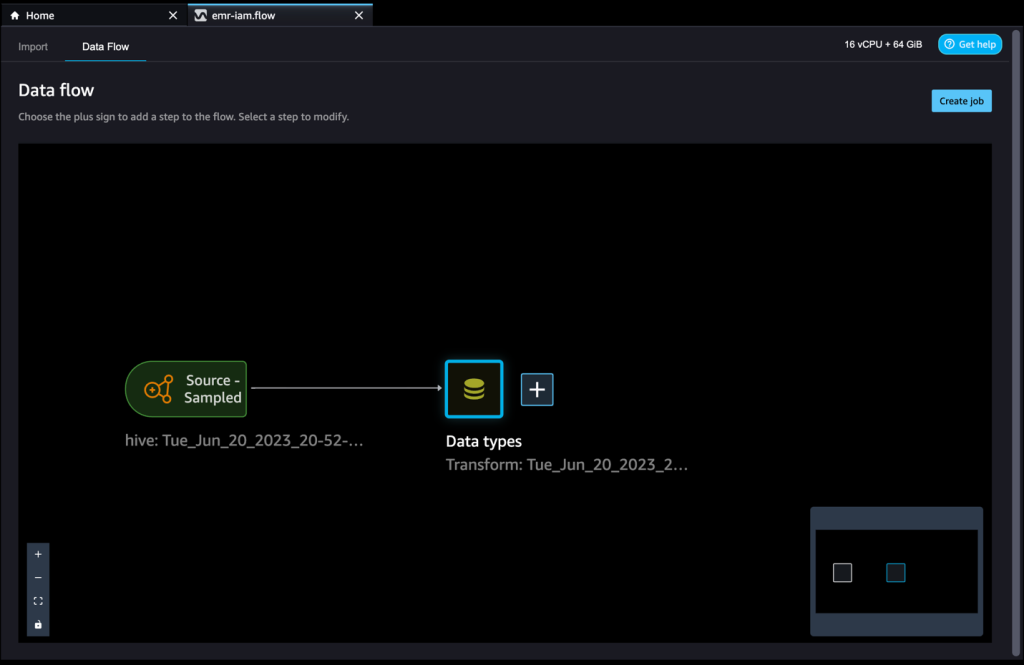
- データタイプの隣にあるプラス記号を選択し、変換を追加します。
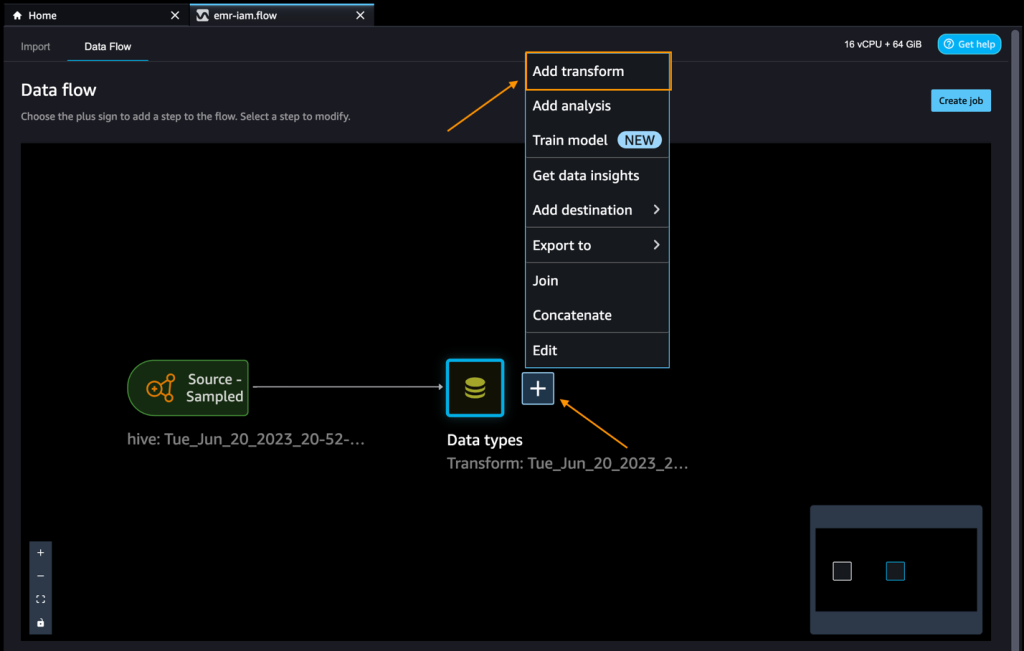
データを探索し、変換を適用しましょう。例えば、c_login列は空であり、特徴として付加価値を持たないため、この列を削除しましょう。
- すべてのステップパネルで、ステップを追加を選択します。
- 列の管理を選択します。
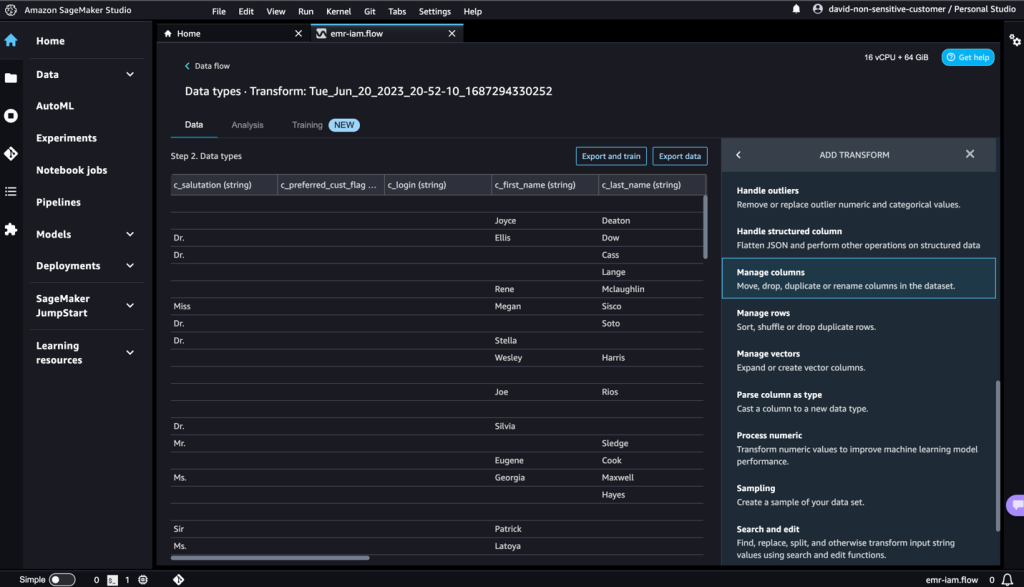
- 変換には列の削除を選択します。
- 削除する列には
c_login列を選択します。 - プレビューを選択し、追加を選択します。
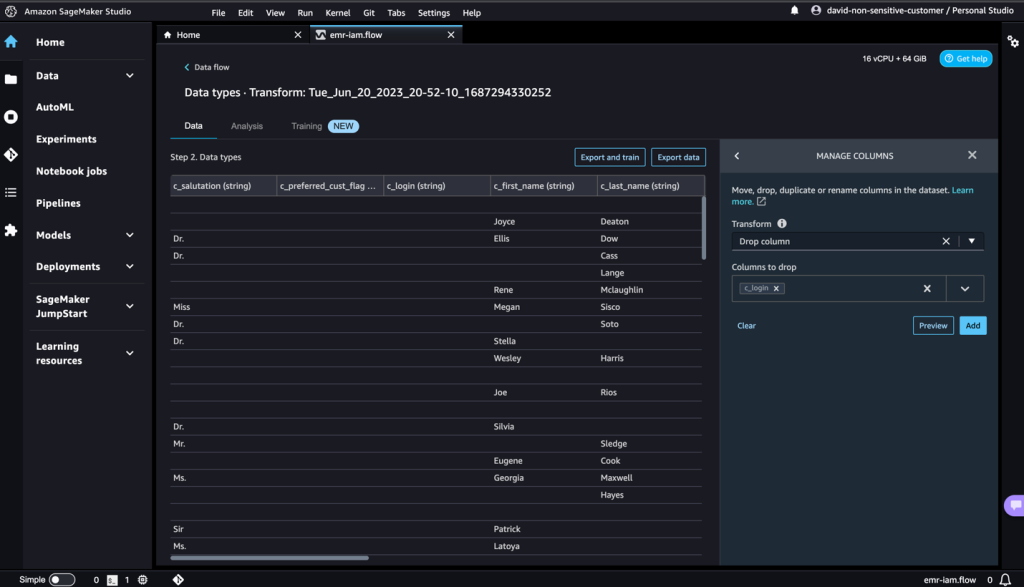
- 列の削除セクションを展開してステップを確認します。
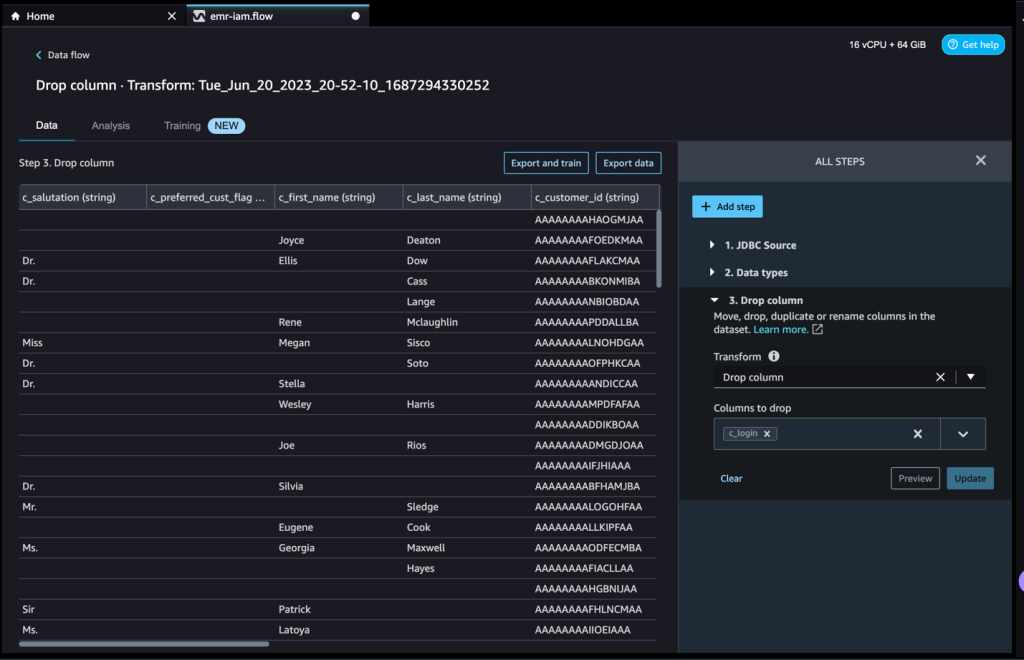
データセットに必要なさまざまな変換に基づいてステップを追加し続けることができます。データフローに戻りましょう。行った変換を示す列の削除ブロックが表示されていることが確認できます。
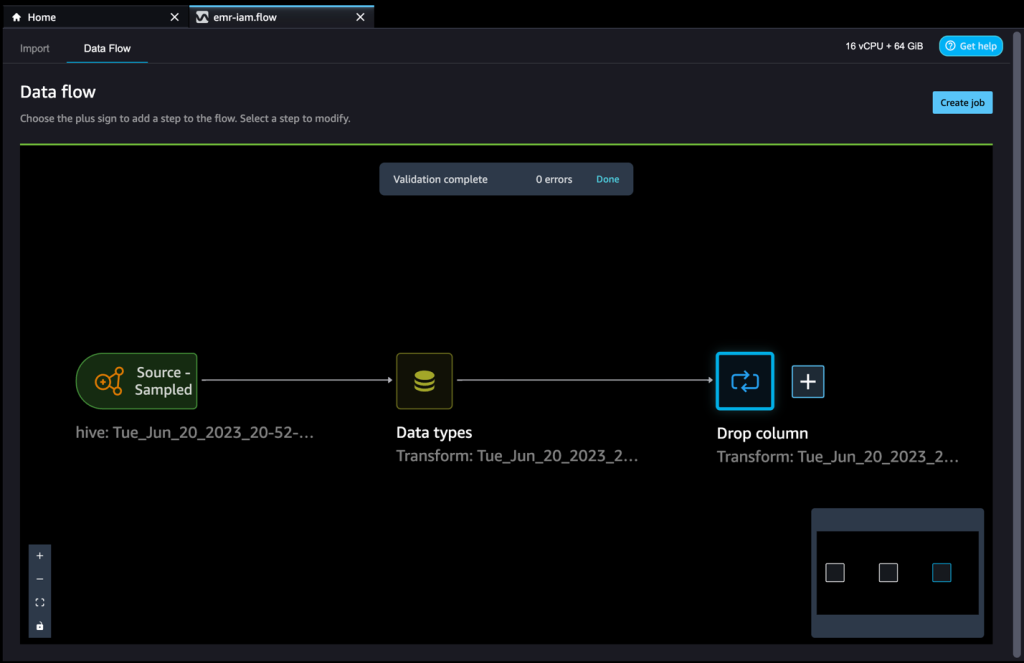
機械学習のプラクティショナーは、特徴エンジニアリングのコードを作成し、初期データセットに適用し、エンジニアリングされたデータセットでモデルをトレーニングし、モデルの精度を評価するために多くの時間を費やします。この作業の実験的な性質を考慮すると、最小のプロジェクトでも複数のイテレーションが行われます。同じ特徴エンジニアリングのコードが何度も実行されることがあり、同じ操作を繰り返すことによって時間と計算リソースが無駄になります。大規模な組織では、異なるチームが同じジョブを実行したり、前の作業の知識がないために重複した特徴エンジニアリングのコードを書いたりすることがあるため、生産性の大きな損失を引き起こす可能性があります。特徴の再処理を避けるために、変換した特徴をAmazon SageMakerの特徴ストアにエクスポートすることができます。詳細については、「Amazon SageMaker特徴ストアを使用して機械学習の特徴を保存、検出、共有する」を参照してください。
- ドロップカラムの隣にあるプラス記号を選択します。
- エクスポート先とJupyter notebookを介したSageMaker Feature Storeを選択します。
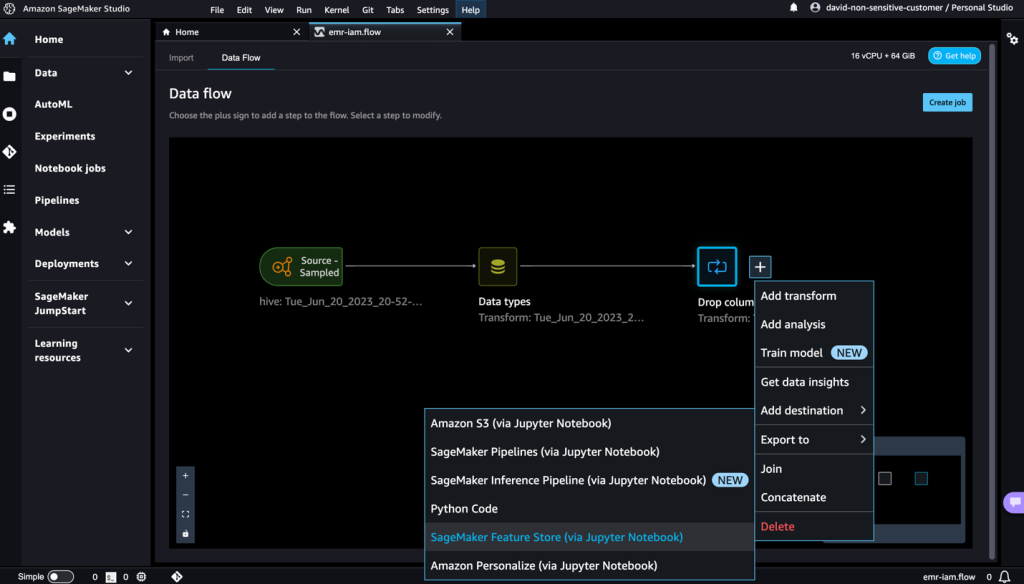
生成された特徴量を簡単にSageMaker Feature Storeにエクスポートすることができます。宛先として指定することで、特徴量を既存の特徴量グループに保存するか、新しい特徴量グループを作成することができます。詳細については、「コードなしでAmazon SageMakerで特徴量を簡単に作成および保存する」を参照してください。
SageMaker Data Wranglerで特徴量を作成し、それらの特徴量をSageMaker Feature Storeに保存しました。SageMaker Data Wrangler UIでの特徴量エンジニアリングの例のワークフローを示しました。
後片付け
SageMaker Data Wranglerでの作業が完了した場合は、追加料金が発生しないように作成したリソースを削除してください。
- SageMaker Studioで、すべてのタブを閉じ、ファイルメニューからシャットダウンを選択します。
- プロンプトが表示されたら、すべてシャットダウンを選択します。
シャットダウンには、インスタンスタイプに基づいて数分かかる場合があります。各ユーザープロファイルに関連付けられたすべてのアプリが削除されたことを確認してください。削除されていない場合は、CloudFormationテンプレートを使用して作成された各ユーザープロファイルの下に関連付けられたアプリを手動で削除してください。
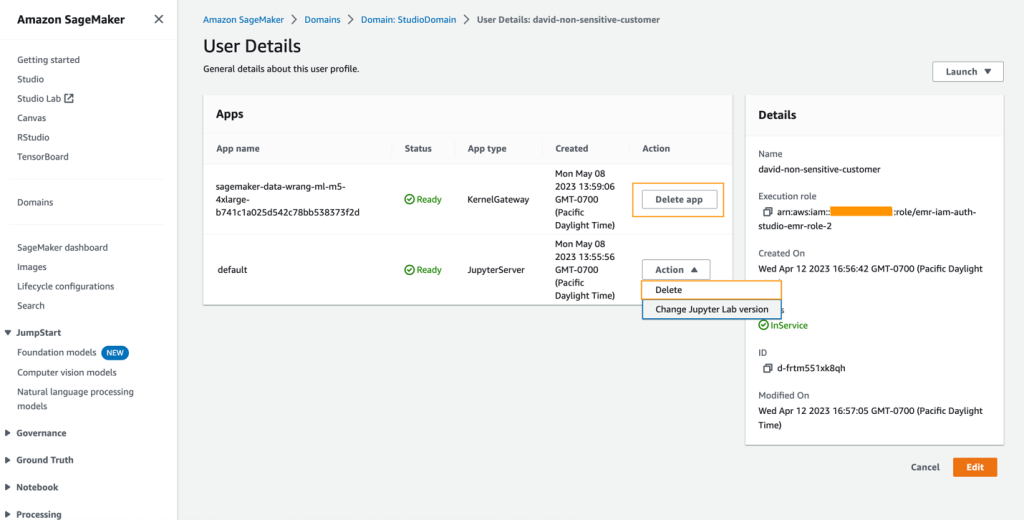
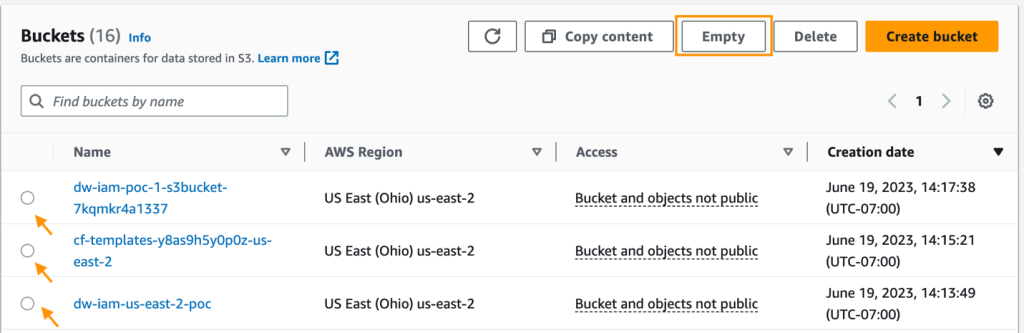
- Amazon S3コンソールで、クラスタのプロビジョニング時に作成されたすべてのS3バケットを空にします。
バケットは、CloudFormationの起動スタック名とcf-templates-と同じプレフィックスを持つ必要があります。
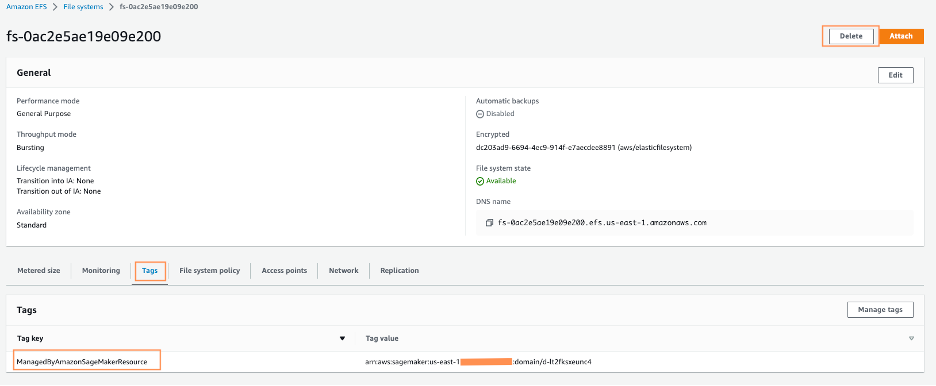
- Amazon EFSコンソールで、SageMaker Studioのファイルシステムを削除します。
正しいファイルシステムを確認するには、ファイルシステムIDを選択し、タグタブでManagedByAmazonSageMakerResourceのタグを確認します。
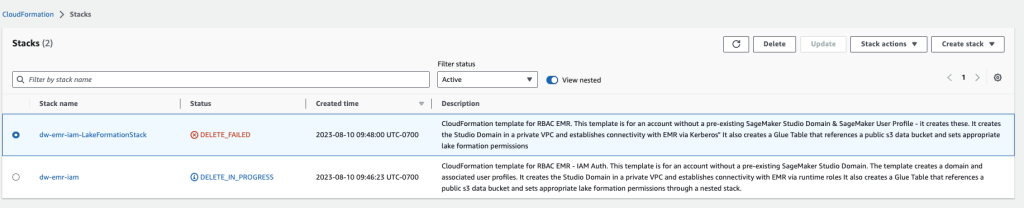
- AWS CloudFormationコンソールで、作成したスタックを選択し、削除を選択します。

予期されたエラーメッセージが表示されます。後の手順でこれをクリーンアップします。
- CloudFormationスタックで作成されたVPCを特定し、dw-emr-という名前のVPCを削除するために指示に従います。
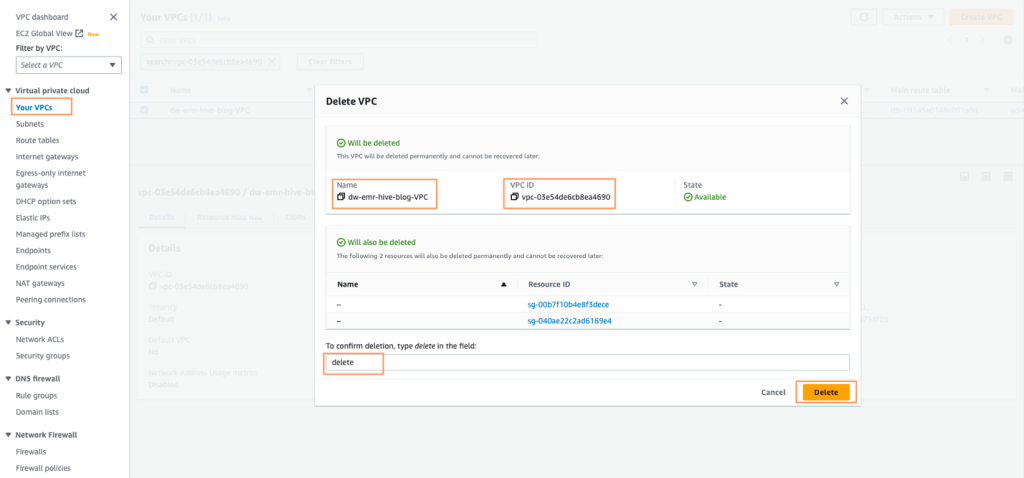
- AWS CloudFormationコンソールに戻り、dw-emr-のスタック削除を再試行します。
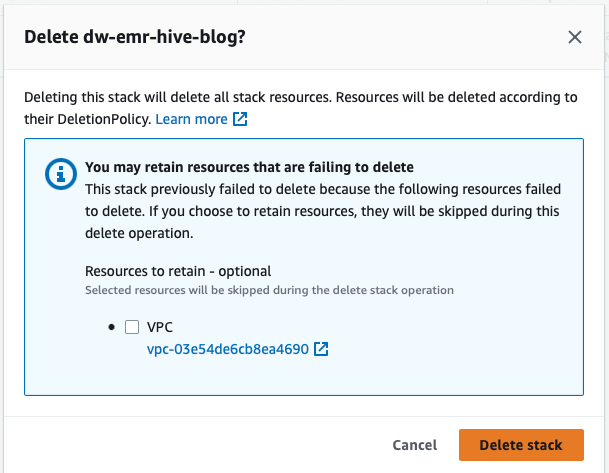
この記事で説明されているCloudFormationテンプレートによってプロビジョニングされたすべてのリソースがアカウントから削除されました。
まとめ
この記事では、Lake Formationを使用して細粒度のアクセス制御を適用し、SageMaker Data WranglerでAmazon EMRをデータソースとしてデータにアクセスし、データセットを変換・分析し、結果をJupyterノートブックで使用するためのデータフローにエクスポートする方法を説明しました。SageMaker Data Wranglerの組み込みの分析機能を使用してデータセットを可視化した後、データフローをさらに強化しました。コードを1行も書かずにデータの準備パイプラインを作成したという事実は重要です。
SageMaker Data Wranglerの使用を開始するには、「Amazon SageMaker Data WranglerでMLデータを準備する」を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
