「Apache Sparkにおけるメモリ管理:ディスクスピル」
Apache Sparkのメモリ管理:ディスクスピル
それは何か、そしてどのように扱うか
ビッグデータの世界では、Apache Sparkは非常に高速に大量のデータを処理する能力を持つことで愛されています。世界で最も優れたビッグデータ処理エンジンであるため、このツールの使用方法を学ぶことは、ビッグデータのプロフェッショナルにとっての基礎的なスキルです。そして、その道の重要なステップとして、Sparkのメモリ管理システムと「ディスクスピル」の課題を理解することがあります。
ディスクスピルとは、Sparkがデータをメモリに収めることができなくなり、ディスクに保存する必要がある場合に起こるものです。Sparkの主な利点の1つは、ディスクドライブを使用するよりもはるかに高速なインメモリ処理能力です。したがって、ディスクにスピルするアプリケーションを構築することは、Sparkの目的をある程度損なうことになります。
ディスクスピルにはいくつかの望ましくない結果がありますので、Spark開発者にとってはそれに対処する方法を学ぶことが重要なスキルです。そして、この記事ではそのお手伝いをすることを目指しています。Sparkの組み込みUIを使用して、ディスクスピルの兆候を特定し、そのメトリックスを理解する方法を学びます。最後に、効果的なデータパーティショニング、適切なキャッシュ、および動的なクラスタのリサイズなど、ディスクスピルを軽減するための行動可能な戦略について探求します。
Sparkにおけるメモリ管理
ディスクスピルに潜り込む前に、ディスクスピルが発生し、どのように管理されるかを理解するために、Sparkにおけるメモリ管理の仕組みを理解すると役立ちます。
- 「2023年に試してみる必要のある素晴らしい無料LLMプレイグラウンド5選」
- GraphReduce グラフを使用した特徴エンジニアリングの抽象化
- 「無脳」ソフトロボットがロボット工学の大発展により複雑な環境を航行する
Sparkはインメモリデータ処理エンジンとして設計されており、データの格納と操作において主にRAMを使用するため、ディスクストレージに頼ることはありません。このインメモリコンピューティングの能力は、Sparkを高速かつ効率的にする主要な特徴の1つです。
Sparkには、操作に割り当てられた限られた量のメモリがあり、このメモリは異なるセクションに分割されており、統合メモリとして知られています:
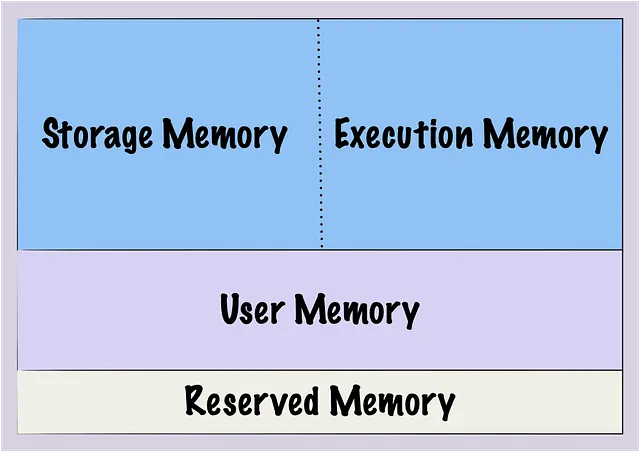
ストレージメモリ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






