Amazon Textract による強化されたテーブル抽出の発表
Announcement of Enhanced Table Extraction with Amazon Textract
Amazon Textractは、任意のドキュメントまたは画像からテキスト、手書き、およびデータを自動的に抽出する機械学習(ML)サービスです。Amazon Textractには、AnalyzeDocument API内のTables機能があり、任意のドキュメントから表形式の構造を自動的に抽出する機能があります。この記事では、Tables機能への改善点について説明し、さまざまなドキュメントから表形式の情報を抽出することが容易になった方法について説明します。
財務報告書、給与明細書、分析証明ファイルなどのドキュメントに含まれる表形式の構造は、情報の簡単な解釈を可能にするようにフォーマットされています。これらは、しばしば表のタイトル、表のフッター、セクションのタイトル、およびサマリー行などの情報も含まれており、より読みやすく整理されています。この改善前の同様のドキュメントでは、AnalyzeDocument内のTables機能はこれらの要素をセルとして認識し、表の境界外に存在するタイトルやフッターを抽出しなかったため、これらの情報を識別するためのカスタム後処理ロジックが必要でした。このTables機能の改善発表により、表形式のデータのさまざまな側面を抽出することがより簡単になりました。
2023年4月、Amazon Textractは、Tables機能を介して、ドキュメントに存在するタイトル、フッター、セクションタイトル、およびサマリー行を自動的に検出する機能を導入しました。この記事では、これらの改善点について説明し、APIを使用して応答を処理するコード例を使ってこれらの改善点を理解して使用するための例を提供します。
解決策の概要
以下の画像は、更新されたモデルがドキュメント内の表だけでなく、すべての対応する表ヘッダーとフッターを識別することを示しています。このサンプル財務報告書ドキュメントには、表のタイトル、フッター、セクションのタイトル、およびサマリー行が含まれています。
- DeepSpeedを使用してPyTorchを加速し、Intel Habana GaudiベースのDL1 EC2インスタンスを使用して大規模言語モデルをトレーニングします
- Amazon PersonalizeにおけるSimilar-Itemsの人気チューニングを紹介します
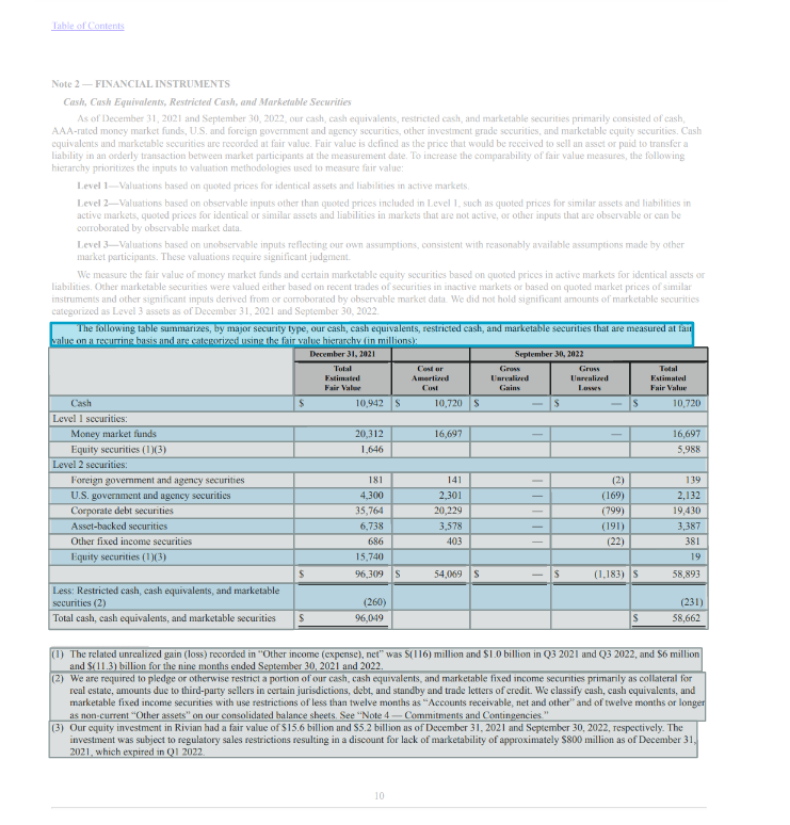
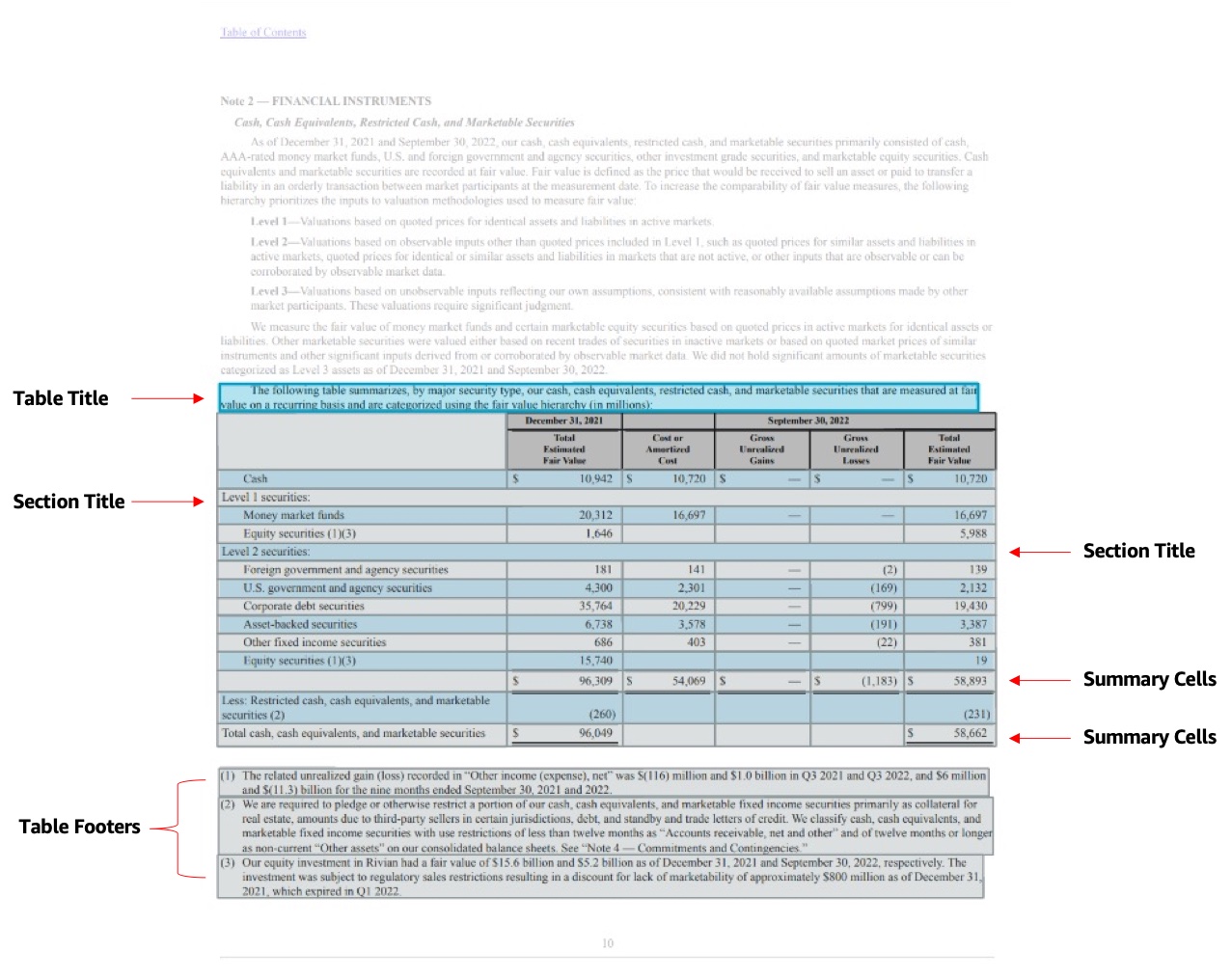
Tables機能の改善により、これらの表要素を容易に抽出できるようになり、表の種類を区別できるようにするためにAPI応答に4つの新しい要素が追加されます。
テーブル要素
Amazon Textractは、テーブルセルやマージセルなど、テーブルのいくつかのコンポーネントを識別できます。これらのコンポーネントは、Blockオブジェクトとして知られ、バウンディングジオメトリ、関係、および信頼度スコアなどのコンポーネントに関連する詳細をカプセル化します。 Blockは、お互いに近いピクセルのグループ内で文書内で認識されたアイテムを表します。 以下は、この改善で導入された新しいテーブルブロックです。
- テーブルタイトル –
TABLE_TITLEという新しいBlockタイプで、特定のテーブルのタイトルを識別できるようになりました。タイトルは、通常、テーブルの上にある1つ以上の行またはテーブル内のセルに埋め込まれています。 - テーブルフッター –
TABLE_FOOTERという新しいBlockタイプで、特定のテーブルに関連するフッターを識別できるようになりました。フッターは、通常、テーブルの下またはテーブル内に埋め込まれた1つ以上の行です。 - セクションタイトル – 新しい
BlockタイプであるTABLE_SECTION_TITLEを使用すると、検出されたセルがセクションタイトルであるかどうかを識別できます。 - サマリーセル –
TABLE_SUMMARYという新しいBlockタイプを使用すると、給与明細書の合計などのサマリーセルであるかどうかを識別できます。
テーブルの種類
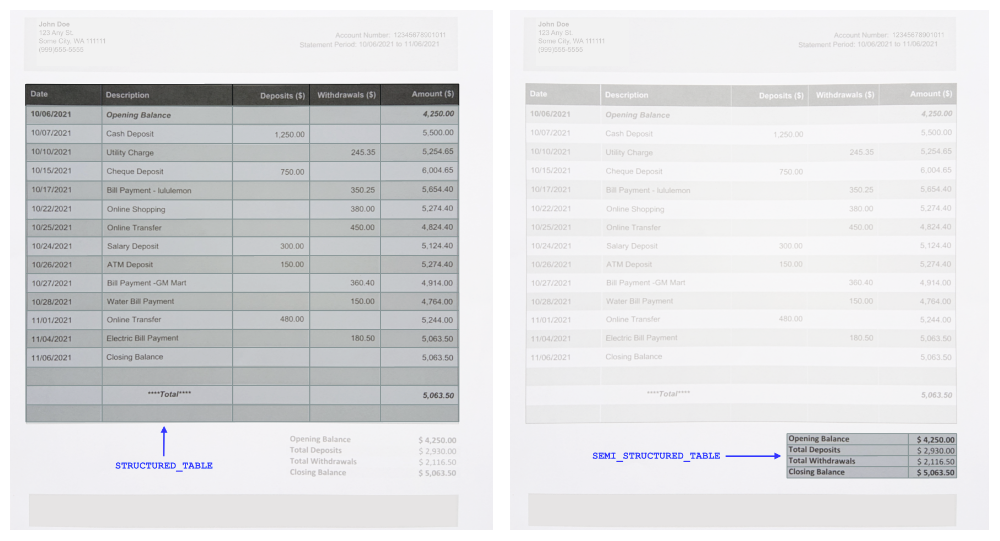
Amazon Textractがドキュメント内のテーブルを識別すると、テーブルのすべての詳細をトップレベルのTABLEブロックタイプに抽出します。テーブルは様々な形状とサイズがあります。たとえば、ドキュメントには、識別可能なテーブルヘッダーがある場合とない場合があるテーブルが含まれています。これらの種類のテーブルを区別するのに役立つために、TABLE Blockの2つの新しいエンティティタイプ、SEMI_STRUCTURED_TABLEおよびSTRUCTURED_TABLEが追加されました。
構造化された表は、明確に定義された列見出しを持つ表です。しかし、半構造化された表では、データが厳密な構造に従わない場合があります。たとえば、定義された見出しを持たない表形式でデータが表示される場合があります。新しいエンティティタイプを使用すると、ポスト処理中にどのテーブルを保持するか、または削除するかを選択できます。以下の画像は、STRUCTURED_TABLEおよびSEMI_STRUCTURED_TABLEの例を示しています。
API出力の分析
このセクションでは、Amazon Textract Textractorライブラリを使用して、AnalyzeDocumentのAPI出力をポスト処理して、テーブル機能の強化版を使用して関連情報を抽出する方法を探索します。
Textractorは、Amazon Textract APIとシームレスに動作するように作成されたライブラリで、APIによって返されるJSONレスポンスをプログラム可能なオブジェクトに変換するためのユーティリティも提供します。ドキュメント上のエンティティを視覚化したり、カンマ区切り値(CSV)ファイルなどの形式でデータをエクスポートするためにも使用できます。これは、Amazon Textractの顧客がポスト処理パイプラインを設定するのに役立つことを意図しています。
私たちの例では、10-K SECファイリングドキュメントからの以下のサンプルページを使用しています。
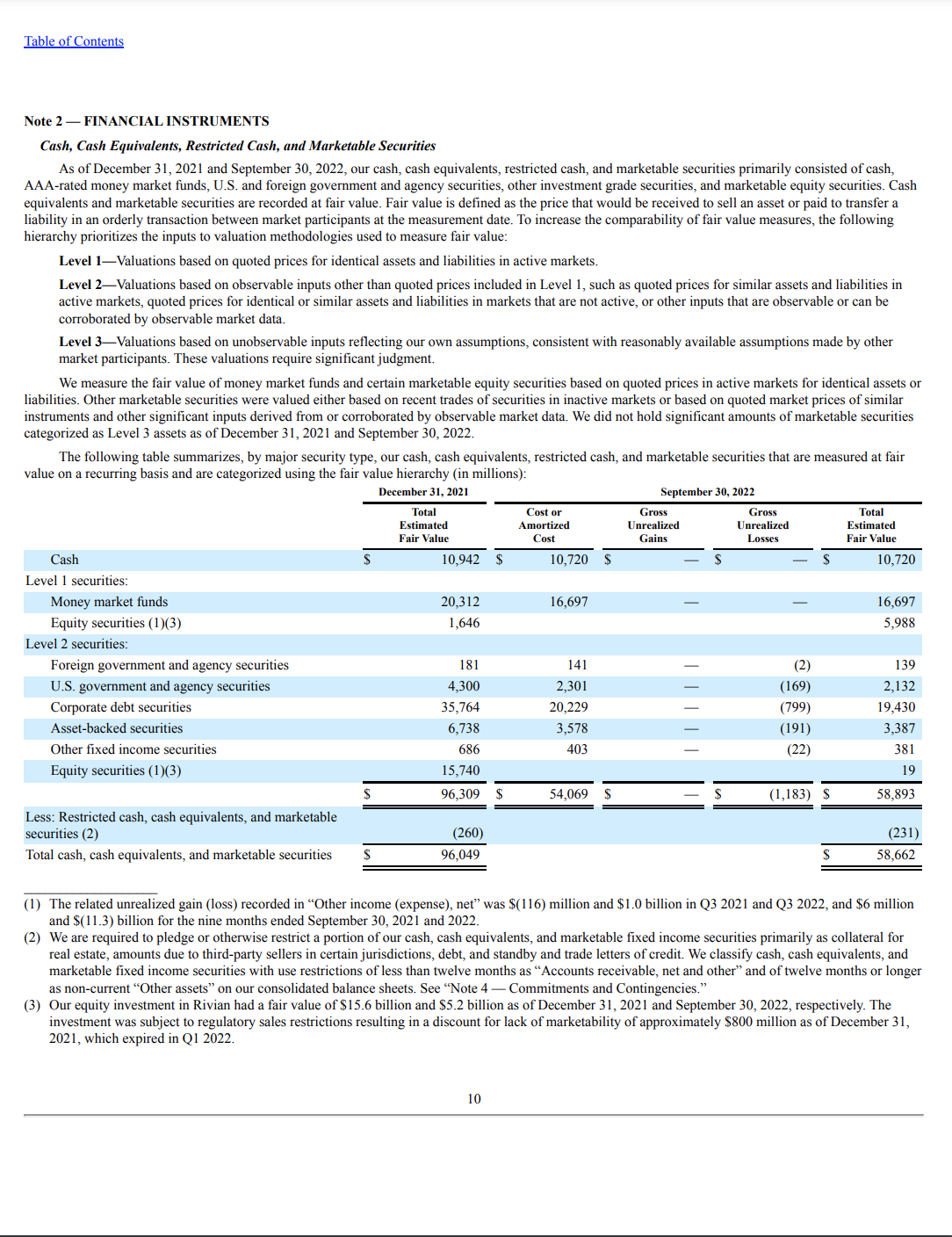
次のコードは、私たちのGitHubリポジトリ内で見つけることができます。このドキュメントを処理するために、Textractorライブラリを使用し、API出力をポスト処理してデータを視覚化する必要があります。
pip install amazon-textract-textractor最初のステップは、features=[TextractFeatures.TABLES]パラメータで示されるテーブル機能を備えたAmazon Textract AnalyzeDocumentを呼び出して、テーブル情報を抽出することです。このメソッドは、シングルページドキュメントをサポートするリアルタイム(または同期)AnalyzeDocument APIを呼び出します。ただし、最大3,000ページのマルチページドキュメントを処理するために、非同期のStartDocumentAnalysis APIを使用することもできます。
from PIL import Image
from textractor import Textractor
from textractor.visualizers.entitylist import EntityList
from textractor.data.constants import TextractFeatures, Direction, DirectionalFinderType
image = Image.open("sec_filing.png") # Pillowを使用してドキュメントイメージを読み込みます。
extractor = Textractor(region_name="us-east-1") # リージョンを変更する場合は、textractorクライアントを初期化します。
document = extractor.analyze_document(
file_source=image,
features=[TextractFeatures.TABLES],
save_image=True
)documentオブジェクトには、ドキュメントに関するメタデータが含まれています。それは、ドキュメント内の他のエンティティとともに、ドキュメント内の1つのテーブルを認識していることに注意してください。
このドキュメントには、次のデータが含まれています。
ページ - 1
単語数 - 658
行数 - 122
キー - 値 - 0
チェックボックス - 0
テーブル - 1
クエリ - 0
署名 - 0
ID書類 - 0
経費書類 - 0API出力にテーブル情報が含まれているため、以前に説明した応答構造を使用して、テーブルの異なる要素を視覚化します。
table = EntityList(document.tables[0])
document.tables[0].visualize()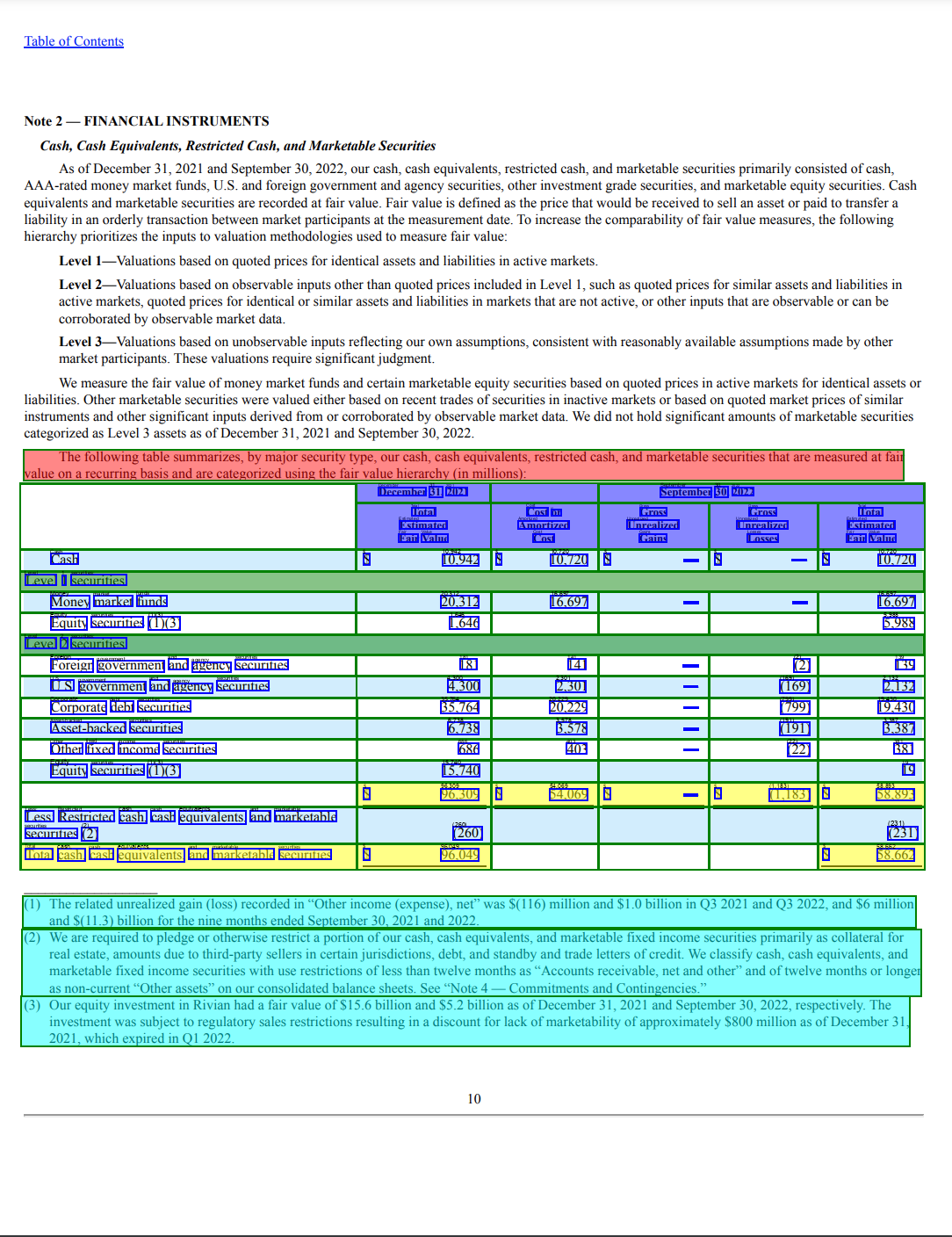
Textractorライブラリは、検出されたテーブル内のさまざまなエンティティを、各テーブル要素に対して異なる色コードで強調表示します。各要素を抽出する方法についてさらに掘り下げてみましょう。次のコードスニペットは、テーブルのタイトルを抽出する方法を示しています。
table_title = table[0].title.text
table_title
'The following table summarizes, by major security type, our cash, cash equivalents, restricted cash, and marketable securities that are measured at fair value on a recurring basis and are categorized using the fair value hierarchy (in millions):'同様に、以下のコードを使用してテーブルのフッターを抽出することができます。table_footersはリストであることに注意してください。これは、テーブルに関連するフッターが1つ以上ある可能性があることを意味します。このリストを反復処理して、存在するすべてのフッターを表示できます。次のコードスニペットに示すように、出力には3つのフッターが表示されます:
table_footers = table[0].footers
for footers in table_footers:
print (footers.text)
(1) "その他の収益(費用)、純額"に記録された関連する未実現利益(損失)は、2021年第3四半期と2022年第3四半期において、それぞれ1億1600万ドルと10億ドル、2021年9月30日および2022年の9月30日までの9か月間で6百万ドルおよび113億ドルの損失がありました。
(2) 不動産、特定の管轄区域における第三者売り手に対する金額、債務、スタンバイおよびトレード信用状などの担保として、現金、現金同等物、および市場で取引可能な固定収益証券の一部を質入れまたはその他に制限することが求められています。使用期間が12か月未満の使用制限がある現金、現金同等物、および市場で取引可能な固定収益証券は、「債権、純額およびその他」として、12か月以上の使用制限があるものは、当社の連結貸借対照表において非流動の「その他の資産」として分類されます。「注4-義務および不確定事項」を参照してください。
(3) 当社が保有するRivianへの出資は、2021年12月31日および2022年9月30日現在、それぞれ156億ドルと52億ドルの公正価値を有していました。投資は規制上の売却制限により流動性不足の割引額約8億ドルを有しており、2021年12月31日現在、第1四半期2022年に期限が切れました。ダウンストリーム処理のデータ生成
Textractorライブラリは、テーブルデータをダウンストリームシステムまたは他のワークフローに簡単に取り込むことができるようになっています。たとえば、抽出されたテーブルデータを人間が読めるMicrosoft Excelファイルにエクスポートできます。この執筆時点では、結合されたテーブルをサポートする唯一のフォーマットです。
table[0].to_excel(filepath="sec_filing.xlsx")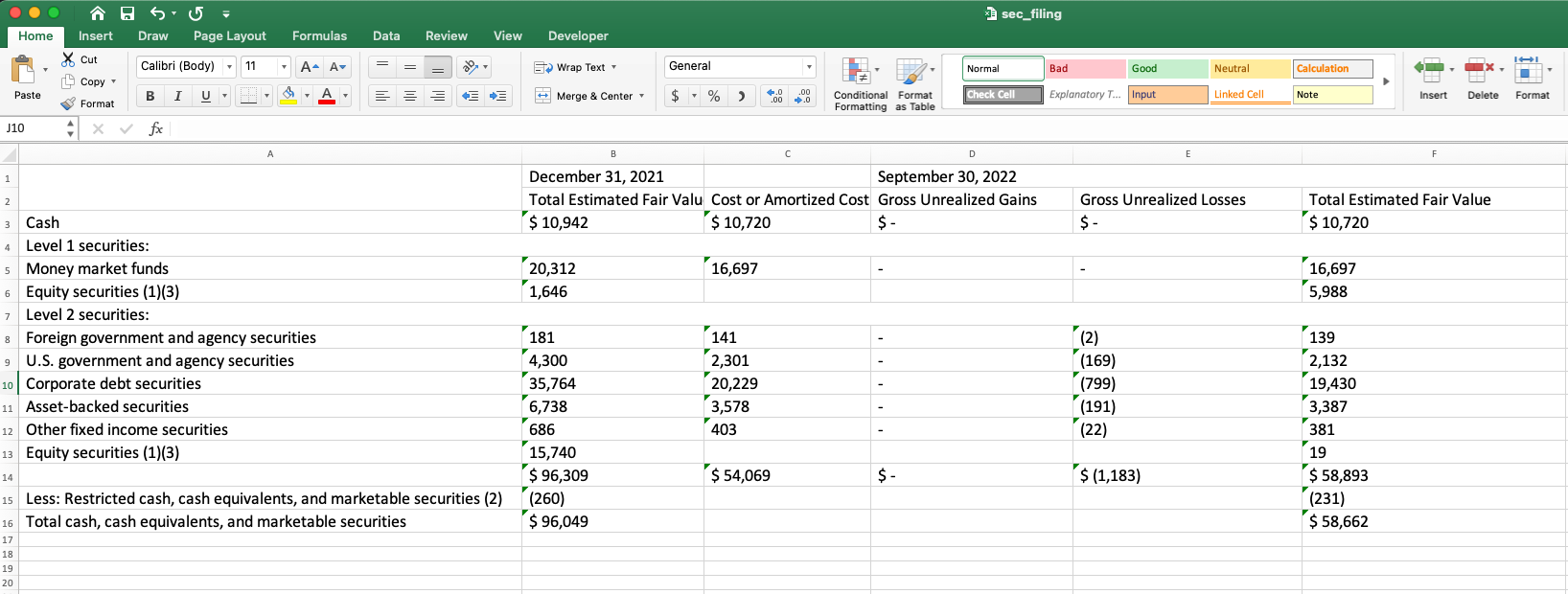
また、Pandas DataFrameに変換することもできます。DataFrameは、PythonやRなどのプログラミング言語でのデータ操作、分析、および可視化において人気のある選択肢です。
Pythonでは、DataFrameはPandasライブラリの主要なデータ構造です。柔軟で強力であり、さまざまなデータ分析およびMLタスクに対してデータ分析プロフェッショナルの最初の選択肢となることがよくあります。次のコードスニペットは、抽出されたテーブル情報を1行のコードでDataFrameに変換する方法を示しています。
df=table[0].to_pandas()
df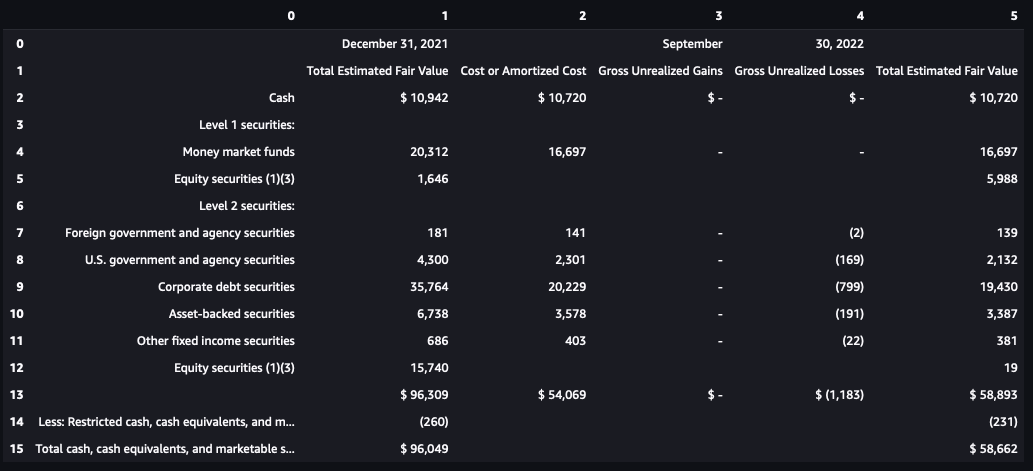
最後に、テーブルデータをCSVファイルに変換することができます。CSVファイルは、関係データベースやデータウェアハウスにデータを取り込むためによく使用されます。以下のコードを参照してください。
table[0].to_csv()
',0,1,2,3,4,5\n0,,"2021年12月31日",, "2022年9月30日",\n1,,総評価公正価値,原価または償却原価,総実現利益,総損失,総評価公正価値\n2,現金,"$ 10,942","$ 10,720",$ -,$ -,"$ 10,720"\n3,レベル1の証券:,,,,,\n4,マネーマーケットファンド,"20,312","16,697",-,-,"16,697"\n5,株式証券(1)(3),"1,646",,,,"5,988"\n6,レベル2の証券:,,,,,\n7,外国政府および機関証券,181,141,-,(2),139\n8,米国政府および機関証券,"4,300","2,301",-,(169),"2,132"\n9,企業債券,"35,764","20,229",-,(799),"19,430"\n10,資産担保証券,"6,738","3,578",-,(191),"3,387"\n11,その他の固定収益証券,686,403,-,(22),381\n12,株式証券(1)(3),"15,740",,,,19\n13,,"$ 96,309","$ 54,069",$ -,"$ (1,183)","$ 58,893"\n14,"制限付き現金、現金同等物、および市場で取引可能な証券(2)から差し引いたもの",(260),,,(231)\n15,"総現金、現金同等物、および市場で取引可能な証券","$ 96,049",,,,"$ 58,662"\n'</p><h2> </h2>結論
これらの新しいブロックとエンティティタイプ (TABLE_TITLE、TABLE_FOOTER、STRUCTURED_TABLE、SEMI_STRUCTURED_TABLE、TABLE_SECTION_TITLE、TABLE_FOOTER、および TABLE_SUMMARY) の導入により、Amazon Textract による文書からの表形式の抽出は大幅に進歩しました。
これらのツールはより微妙で柔軟なアプローチを提供し、構造化された表と半構造化された表の両方に対応し、文書内の場所に関係なく重要なデータを見落とすことがないようにします。
これにより、多様なデータタイプと表構造を、向上した効率性と精度で処理できるようになりました。文書処理ワークフローにおける自動化の力を引き続き取り入れながら、これらの改善によって、より効率的で生産性の高い、より洞察力のあるデータ分析が可能になるでしょう。AnalyzeDocument および Tables 機能の詳細については、AnalyzeDocument を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles