「Amazon Transcribe Toxicity Detectionを使用して、会話中の有害な言語をフラグ付けします」
Amazon Transcribe Toxicity Detectionを使用して、有害な言語をフラグ付けします
オンラインのソーシャルアクティビティ、例えばソーシャルネットワーキングやオンラインゲームはしばしば敵対的な行動に満ちており、ヘイトスピーチ、サイバーブリーリング、ハラスメントなどの望まれない表現につながることがあります。例えば、多くのオンラインゲームコミュニティでは、ユーザー間のコミュニケーションを促進するためにボイスチャット機能が提供されています。ボイスチャットは友好的なおしゃべりや罵り合いをサポートすることが多いですが、ヘイトスピーチ、サイバーブリーリング、ハラスメント、詐欺などの問題も引き起こすことがあります。有害な言語をフラッグ付けすることで、組織は会話を文明的に保ち、ユーザーが自由に作成、共有、参加できる安全で包括的なオンライン環境を維持することができます。現在、多くの企業は有害なコンテンツをレビューするために人間のモデレーターに完全に頼っています。しかし、十分な品質と速度でこれらのニーズを満たすために人間のモデレーターを拡大することは高コストです。その結果、多くの組織は高いユーザー離脱率、評判の損害、規制による罰金のリスクに直面しています。さらに、モデレーターはしばしば有害なコンテンツをレビューすることで心理的な影響を受けます。
Amazon Transcribeは、開発者がアプリケーションに音声テキスト変換の機能を簡単に追加できる自動音声認識(ASR)サービスです。今日、私たちはAmazon Transcribe Toxicity Detectionを発表し、音声およびテキストベースの手がかりを使用して声ベースの有害なコンテンツを性的ハラスメント、ヘイトスピーチ、脅迫、虐待、不適切な言葉、侮辱、過激な言葉の7つのカテゴリに分類し、特定する機械学習(ML)を活用した機能を提供します。また、Toxicity Detectionはテキストに加えてトーンやピッチなどの音声の手がかりも使用し、音声の有害な意図を特定します。
これは意図を考慮しない特定の用語に焦点を当てた標準的なコンテンツモデレーションシステムよりも改善されたものです。ほとんどの企業は、モデレーターが会話が有害になったかどうかを評価するために長時間のオーディオファイルを聴取する必要があるため、ユーザーから報告されたコンテンツをレビューするSLA(サービスレベルアグリーメント)が7-15日間あります。Amazon Transcribe Toxicity Detectionを使用すると、モデレーターは有害なコンテンツがフラッグ付けされたオーディオファイルの特定の部分のみをレビューするため(全体のオーディオファイルではなく)、レビューするコンテンツは95%削減されます。これにより、顧客はSLAを数時間にまで短縮することができるだけでなく、ユーザーからフラッグ付けされたコンテンツだけでなく、より多くのコンテンツを積極的にモデレートすることも可能になります。これにより、企業はスケールでコンテンツを自動的に検出およびモデレートし、安全かつ包括的なオンライン環境を提供し、ユーザーの離脱や評判の損害を引き起こす前に対策を講じることができます。有害なコンテンツの検出に使用されるモデルはAmazon Transcribeによって維持され、定期的に更新されて正確性と関連性を保つようになっています。
この記事では、以下の方法を学ぶことができます:
- 「AWSは、人工知能、機械学習、生成AIのガイドを提供しており、AI戦略を計画するための新しい情報を提供しています」
- 「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
- 「AIの力を解き放つ – VoAGIとMachine Learning Masteryによる特別リリース」
- Amazon Transcribe Toxicity Detectionを使用して音声の有害なコンテンツを特定する
- Amazon Transcribeコンソールを使用して有害性の検出を行う
- AWSコマンドラインインターフェース(AWS CLI)およびPython SDKを使用して有害性の検出を含むトランスクリプトジョブを作成する
- Amazon Transcribeの有害性検出APIレスポンスを使用する
Amazon Transcribe Toxicity Detectionを使用して音声チャットで有害性を検出する
Amazon Transcribeは、話し言葉の会話で有害な言語をフラッグ付けするためのシンプルなMLベースのソリューションを提供します。この機能は特にソーシャルメディア、ゲーム、一般的なニーズに適しており、顧客が独自のデータを提供せずにMLモデルをトレーニングする必要がなくなります。Toxicity Detectionは有害なオーディオコンテンツを以下の7つのカテゴリに分類し、それぞれのカテゴリに対して信頼スコア(0-1)を提供します:
- 不適切な言葉 – 不快、下品、または攻撃的な単語、フレーズ、または頭字語を含む音声。
- ヘイトスピーチ – 人種、民族、性別、宗教、性的指向、能力、国籍などの身元を理由に個人またはグループを批判、侮辱、非難、非人間化する音声。
- 性的内容 – 身体の部位、身体的特徴、または性に関する直接的または間接的な言及を使用して、性的な興味、活動、または興奮を示す音声。
- 侮辱 – 軽蔑的、屈辱的、嘲笑的、侮辱的、または軽視的な言語を含む音声。このタイプの言語はいじめとしてもラベル付けされます。
- 暴力または脅迫 – 痛み、怪我、または敵意を向ける脅威を含む音声。
- 過激な表現 – 目に不快なイメージを使用する音声。このタイプの言語は、受信者の不快感を増幅するために意図的に冗長になることが多いです。
- 嫌がらせまたは虐待 – 受信者の心理的な幸福に影響を与えることを意図した音声で、侮辱的で物体化する言葉を含みます。
Amazon TranscribeコンソールまたはAWS CLIまたはAWS SDKを直接呼び出すことで、Toxicity Detectionにアクセスできます。Amazon Transcribeコンソールでは、毒性のテストを行いたいオーディオファイルをアップロードし、わずか数回のクリックで結果を取得することができます。Amazon Transcribeは、ハラスメント、憎悪表現、性的な内容、暴力、侮辱、卑語などの有害なコンテンツを識別し、カテゴリ分けします。また、各カテゴリに対する信頼度スコアも提供されるため、コンテンツの有害性レベルに関する貴重な情報を提供します。Toxicity Detectionは、バッチ処理のための標準のAmazon Transcribe APIで現在利用でき、米国英語に対応しています。
Amazon Transcribeコンソールの操作手順
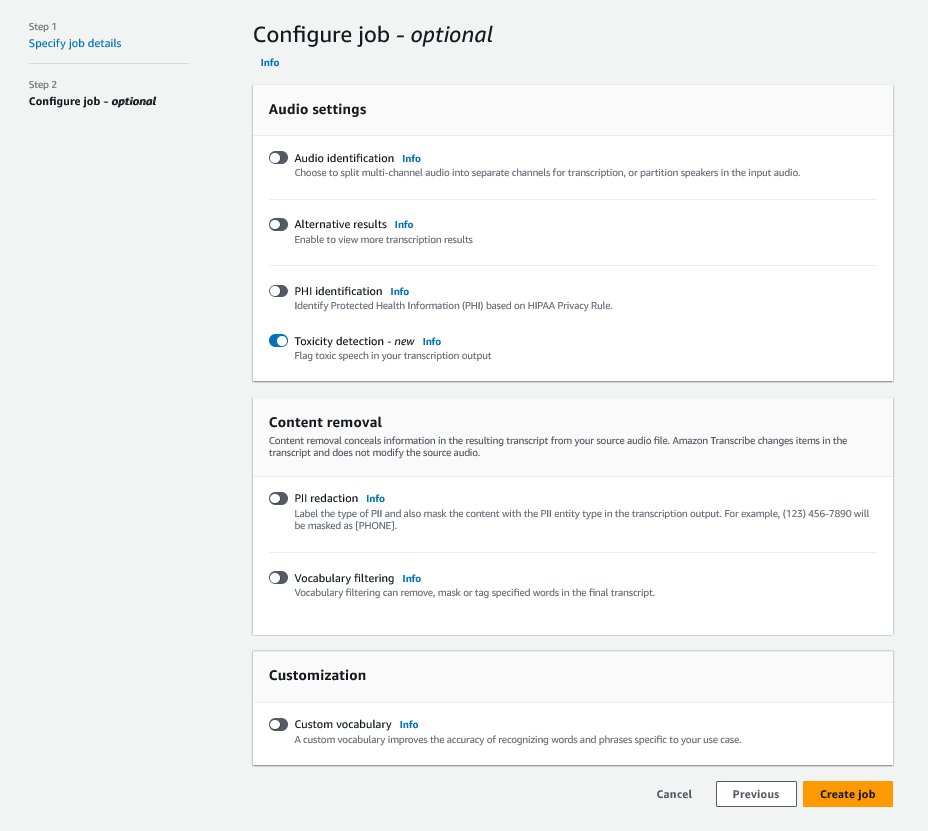
始めるには、AWS Management Consoleにサインインし、Amazon Transcribeに移動します。新しい転記ジョブを作成するには、処理する前に録音したファイルをAmazon Simple Storage Service(Amazon S3)バケットにアップロードする必要があります。次のスクリーンショットに示すように、オーディオ設定ページで有害性検出を有効にし、新しいジョブの作成に進みます。Amazon Transcribeは、転記ジョブをバックグラウンドで処理します。ジョブの進行状況に応じて、プロセスが完了するとステータスがCOMPLETEDに変わることが期待できます。
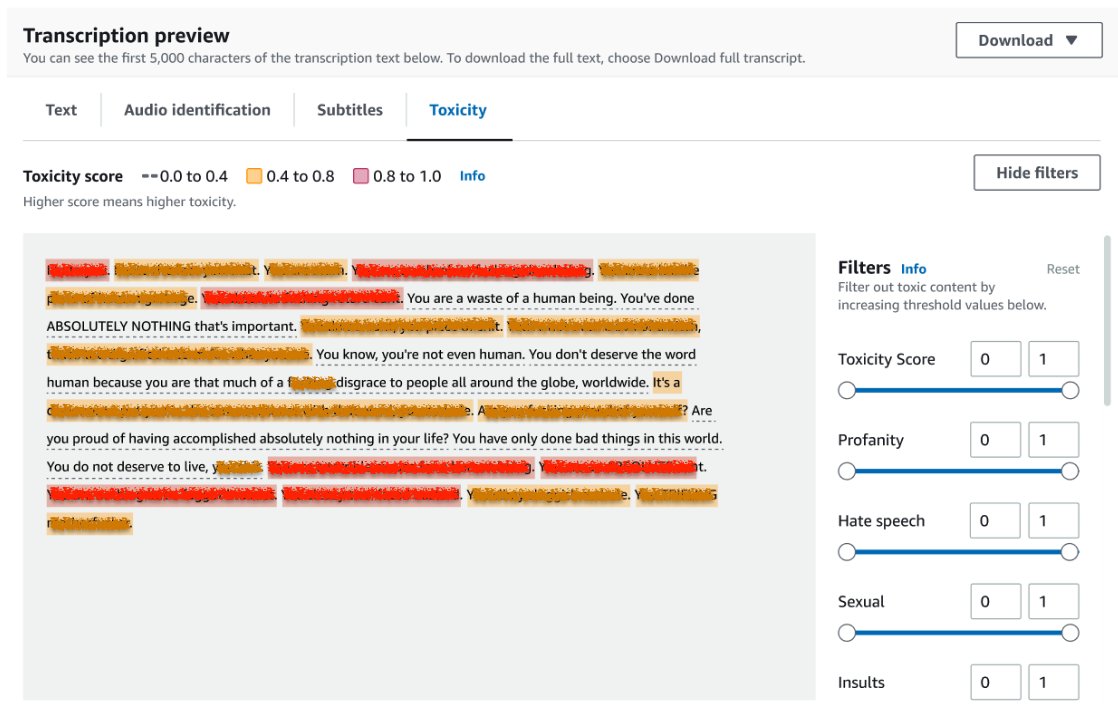
転記ジョブの結果を確認するには、ジョブリストからジョブを選択して開きます。トランスクリプションプレビューセクションにスクロールして有害性タブの結果を確認します。UIでは、信頼度スコアによって決定される有害性レベルを示す色分けされたトランスクリプションセグメントが表示されます。表示をカスタマイズするには、フィルタパネルのトグルバーを使用できます。これらのバーを使用して、しきい値を調整し、有害性カテゴリをフィルタリングすることができます。
次のスクリーンショットは、機密情報や有害な情報の存在により、トランスクリプションテキストの一部が隠されています。
有害性検出リクエストを使用したトランスクリプションAPI
このセクションでは、プログラミングインターフェースを使用して有害性検出を使用したトランスクリプションジョブを作成する方法を案内します。オーディオファイルがすでにS3バケットにない場合は、Amazon Transcribeからアクセスできるようにアップロードしてください。コンソール上でトランスクリプションジョブを作成するのと同様に、ジョブを呼び出すときには、次のパラメータを指定する必要があります:
- TranscriptionJobName – ユニークなジョブ名を指定します。
- MediaFileUri – Amazon S3上のオーディオファイルのURIの場所を入力します。Amazon Transcribeは、次のオーディオ形式をサポートしています:MP3、MP4、WAV、FLAC、AMR、OGG、またはWebM
- LanguageCode –
en-USに設定します。現時点では、有害性検出は米国英語のみをサポートしています。 - ToxicityCategories –
ALLの値を渡して、すべてのサポートされている有害性検出カテゴリを含めます。
以下は、Python3を使用して有害性検出を有効にしたトランスクリプションジョブを開始する例です:
import time
import boto3
transcribe = boto3.client('transcribe', 'us-east-1')
job_name = "toxicity-detection-demo"
job_uri = "s3://my-bucket/my-folder/my-file.wav"
# トランスクリプションジョブを開始
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = { 'MediaFileUri': job_uri },
OutputBucketName = 'doc-example-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
ToxicityDetection = [{'ToxicityCategories': ['ALL']}]
)
# トランスクリプションジョブの完了を待つ
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)以下のAWS CLIコマンドを使用して、同じトランスクリプションジョブを毒性検出とともに呼び出すことができます:
aws transcribe start-transcription-job \
--region us-east-1 \
--transcription-job-name toxicity-detection-demo \
--media MediaFileUri=s3://my-bucket/my-folder/my-file.wav \
--output-bucket-name doc-example-bucket \
--output-key my-output-files/ \
--language-code en-US \
--toxicity-detection ToxicityCategories=ALL毒性検出を含むトランスクリプションAPIの応答
Amazon Transcribeの毒性検出JSON出力には、結果フィールドにトランスクリプション結果が含まれます。毒性検出を有効にすると、結果フィールドの下にtoxicityDetectionという追加のフィールドが追加されます。toxicityDetectionには、次のパラメータを持つトランスクリプションアイテムのリストが含まれます:
- text – 生のトランスクリプションテキスト
- toxicity – 検出の信頼スコア(0から1の値)
- categories – 各種類の有害な発言の信頼スコア
- start_time – オーディオファイル内の検出の開始位置(秒)
- end_time – オーディオファイル内の検出の終了位置(秒)
以下は、コンソールからダウンロードできるサンプルの略語形式の毒性検出応答です:
{
"results":{
"transcripts": [...],
"items":[...],
"toxicityDetection": [
{
"text": "ここに有害なトランスクリプションセグメントが入ります。",
"toxicity": 0.8419,
"categories": {
"PROFANITY": 0.7041,
"HATE_SPEECH": 0.0163,
"SEXUAL": 0.0097,
"INSULT": 0.8532,
"VIOLENCE_OR_THREAT": 0.0031,
"GRAPHIC": 0.0017,
"HARASSMENT_OR_ABUSE": 0.0497
},
"start_time": 16.298,
"end_time": 20.35
},
...
]
},
"status": "COMPLETED"
}概要
この記事では、新しいAmazon Transcribe毒性検出機能の概要を提供しました。また、毒性検出JSON出力の解析方法について説明しました。詳細については、Amazon Transcribeコンソールを確認し、毒性検出を含むトランスクリプションAPIを試してみてください。
Amazon Transcribe毒性検出は、次のAWSリージョンで利用できます:米国東部(オハイオ)、米国東部(バージニア北部)、米国西部(オレゴン)、アジア太平洋(シドニー)、ヨーロッパ(アイルランド)、ヨーロッパ(ロンドン)。詳細については、Amazon Transcribeをご覧ください。
AWS上のコンテンツモデレーションとコンテンツモデレーションMLユースケースについてもっと学びましょう。AWSでコンテンツモデレーション操作を効率化するための第一歩を踏み出しましょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「DreamPose」というAIフレームワークを使用して、ファッション画像を見事な写真のようなビデオに変換します
- 遺伝的アルゴリズムを使用したPythonによるTV番組スケジューリングの最適化
- 「MACTAに会いましょう:キャッシュタイミング攻撃と検出のためのオープンソースのマルチエージェント強化学習手法」
- 「クラスタリング解放:K-Meansクラスタリングの理解」
- 「夢を先に見て、後で学ぶ:DECKARDは強化学習(RL)エージェントのトレーニングにLLMsを使用するAIアプローチです」
- 「トランスフォーマベースのLLMがパラメータから知識を抽出する方法」
- 「TR0Nに会ってください:事前学習済み生成モデルに任意のコンディショニングを追加するためのシンプルで効率的な方法」





