「Amazon SageMaker プロファイラーのプレビューを発表します:モデルトレーニングのワークロードの詳細なハードウェアパフォーマンスデータを追跡および可視化します」
Amazon SageMaker プロファイラーのプレビューを発表します:モデルトレーニングのワークロードの詳細なハードウェアパフォーマンスデータを追跡および可視化します Announcing the preview of Amazon SageMaker Profiler Tracking and visualizing detailed hardware performance data for model training workloads.
今日は、Amazon SageMaker Profilerのプレビューを発表できて嬉しく思います。これは、SageMakerでディープラーニングモデルのトレーニング中に割り当てられたAWSの計算リソースの詳細なビューを提供するAmazon SageMakerの機能です。SageMaker Profilerでは、CPUとGPU上のすべてのアクティビティをトラッキングすることができます。CPUおよびGPUの使用率、GPU上でのカーネルの実行、CPU上でのカーネルの起動、同期操作、GPU間のメモリ操作、カーネルの起動と対応する実行の間の待ち時間、CPUとGPU間のデータ転送などです。この記事では、SageMaker Profilerの機能について説明します。
SageMaker Profilerは、PyTorchまたはTensorFlowのトレーニングスクリプトに注釈を付けてSageMaker Profilerを有効にするためのPythonモジュールを提供しています。また、プロファイルの視覚化、プロファイルイベントの統計的な要約、およびGPUとCPUのイベントのタイムラインをトラッキングおよび理解するためのユーザーインターフェース(UI)も提供しています。
トレーニングジョブのプロファイリングの必要性
ディープラーニング(DL)の台頭に伴い、機械学習(ML)は計算とデータが集中するようになり、通常はマルチノード、マルチGPUクラスタが必要とされるようになりました。最先端のモデルが兆個のパラメータで成長するにつれて、その計算量とコストも急速に増加しています。大規模な言語モデル(LLM)では、数十億のパラメータを持つことが一般的であり、効率的にトレーニングするために大規模なマルチノードGPUクラスタが必要です。
大規模な計算クラスタでこれらのモデルをトレーニングする際には、I/Oのボトルネック、カーネル起動の待ち時間、メモリ制限、リソースの低い利用など、計算リソースの最適化の課題に直面することがあります。トレーニングジョブの設定が最適化されていない場合、これらの課題は効率的なハードウェアの利用やトレーニング時間の増加、未完了のトレーニング実行などにつながり、プロジェクト全体のコストとスケジュールを増加させる可能性があります。
- 「アナリストとデータサイエンティストにとっての5つの一般的なデータガバナンスの課題」
- 「LLMsが幻覚を見るのを止めることはできますか?」
- 「エンティティ解決とグラフニューラルネットワークを用いた詐欺検知」
前提条件
SageMaker Profilerの使用を開始するための前提条件は以下のとおりです:
- AWSアカウント内のSageMakerドメイン – ドメインのセットアップ方法については、「クイックセットアップを使用したAmazon SageMakerドメインへのオンボード」を参照してください。また、個々のユーザーがSageMaker Profiler UIアプリケーションにアクセスできるようにするために、ドメインユーザープロファイルを追加する必要もあります。詳細については、「SageMakerドメインのユーザープロファイルの追加と削除」を参照してください。
- 権限 – SageMaker Profiler UIアプリケーションの実行ロールに割り当てる必要のある最小限の権限は以下の通りです:
sagemaker:CreateAppsagemaker:DeleteAppsagemaker:DescribeTrainingJobsagemaker:SearchTrainingJobss3:GetObjects3:ListBucket
SageMaker Profilerを使用したトレーニングジョブの準備と実行
トレーニングジョブが実行中の間、GPU上のカーネル実行をキャプチャするために、SageMaker ProfilerのPythonモジュールを使用してトレーニングスクリプトを変更します。ライブラリをインポートし、start_profiling()メソッドおよびstop_profiling()メソッドを追加してプロファイリングの開始と終了を定義します。また、各ステップでハードウェアのアクティビティを視覚化するために、オプションのカスタム注釈も追加することができます。
SageMaker Profilerを使用してトレーニングスクリプトをプロファイリングするためには、2つのアプローチがあります。1つ目のアプローチは、関数全体のプロファイリングであり、2つ目のアプローチは、関数内の特定のコード行のプロファイリングです。
関数ごとにプロファイリングする場合は、コンテキストマネージャsmppy.annotateを使用して関数全体に注釈を付けます。以下の例のスクリプトは、トレーニングループと各イテレーションの関数をラップするためにコンテキストマネージャを実装する方法を示しています:
import smppy
sm_prof = smppy.SMProfiler.instance()
config = smppy.Config()
config.profiler = {
"EnableCuda": "1",
}
sm_prof.configure(config)
sm_prof.start_profiling()
for epoch in range(args.epochs):
if world_size > 1:
sampler.set_epoch(epoch)
tstart = time.perf_counter()
for i, data in enumerate(trainloader, 0):
with smppy.annotate("step_"+str(i)):
inputs, labels = data
inputs = inputs.to("cuda", non_blocking=True)
labels = labels.to("cuda", non_blocking=True)
optimizer.zero_grad()
with smppy.annotate("Forward"):
outputs = net(inputs)
with smppy.annotate("Loss"):
loss = criterion(outputs, labels)
with smppy.annotate("Backward"):
loss.backward()
with smppy.annotate("Optimizer"):
optimizer.step()
sm_prof.stop_profiling()smppy.annotation_begin()やsmppy.annotation_end()を使用して、関数内の特定のコード行に注釈を付けることもできます。詳細はドキュメントを参照してください。
SageMakerトレーニングジョブランチャーの設定
注釈を付けたりプロファイラの初期化モジュールを設定したりした後、トレーニングスクリプトを保存し、SageMaker Python SDKを使用してトレーニング用のSageMakerフレームワークエスティメータを準備します。
-
次のように
ProfilerConfigとProfilerモジュールを使用してprofiler_configオブジェクトを設定します:from sagemaker import ProfilerConfig, Profiler profiler_config = ProfilerConfig( profiler_params = Profiler(cpu_profiling_duration=3600)) -
前のステップで作成した
profiler_configオブジェクトを使用して、SageMakerエスティメータを作成します。次のコードはPyTorchエスティメータの例です:import sagemaker from sagemaker.pytorch import PyTorch estimator = PyTorch( framework_version="2.0.0", image_uri="763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker", role=sagemaker.get_execution_role(), entry_point="train_with_profiler_demo.py", # トレーニングジョブのエントリーポイント source_dir=source_dir, # トレーニングスクリプトのソースディレクトリ output_path=output_path, base_job_name="sagemaker-profiler-demo", hyperparameters=hyperparameters, # 必要な場合は指定 instance_count=1, instance_type=ml.p4d.24xlarge, profiler_config=profiler_config )
TensorFlowエスティメータを作成する場合は、sagemaker.tensorflow.TensorFlowをインポートし、SageMakerプロファイラでサポートされているTensorFlowのバージョンのいずれかを指定します。サポートされているフレームワークとインスタンスタイプの詳細については、「サポートされているフレームワーク」を参照してください。
-
fitメソッドを実行してトレーニングジョブを開始します:
estimator.fit(wait=False)
SageMakerプロファイラUIの起動
トレーニングジョブが完了したら、SageMakerプロファイラUIを起動してトレーニングジョブのプロファイルを視覚化および探索することができます。SageMakerプロファイラUIアプリケーションには、SageMakerコンソールのSageMakerプロファイラランディングページまたはSageMakerドメインを介してアクセスできます。
SageMakerコンソールでSageMakerプロファイラUIアプリケーションを起動するには、次の手順を実行してください:
- ナビゲーションペインでSageMakerコンソールを選択します。
- 始めるの下で、SageMakerプロファイラUIアプリケーションを起動するドメインを選択します。
ユーザープロファイルが1つのドメインにのみ所属している場合、ドメインを選択するオプションは表示されません。
- 起動するSageMakerプロファイラUIアプリケーションの対象となるユーザープロファイルを選択します。
ドメインにユーザープロファイルが存在しない場合は、ユーザープロファイルの作成を選択します。新しいユーザープロファイルの作成方法についての詳細は、「ユーザープロファイルの追加と削除」を参照してください。
- プロファイラを開くを選択します。
ドメインの詳細ページからもSageMakerプロファイラUIを起動することもできます。
SageMakerプロファイラからの洞察
SageMakerプロファイラUIを開くと、次のスクリーンショットに示すように、プロファイルの選択と読み込みページが表示されます。
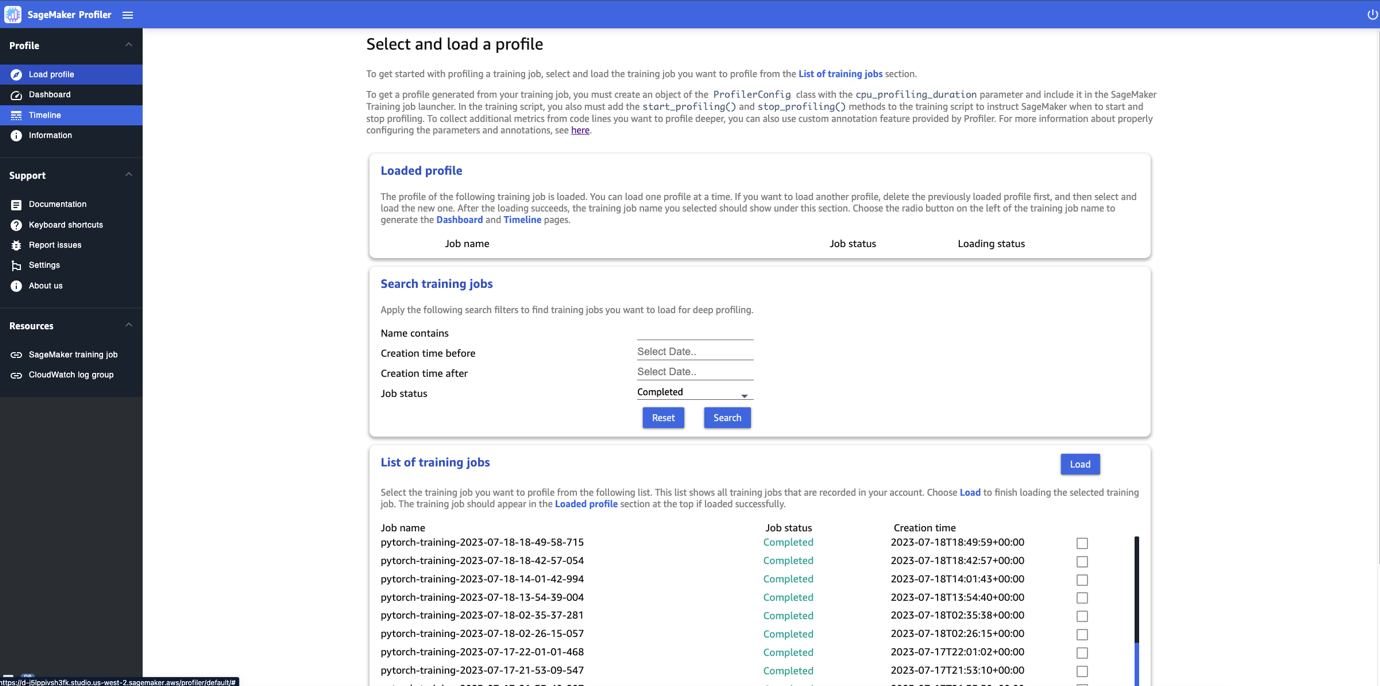
SageMaker Profilerに提出されたトレーニングジョブのリストを表示し、名前、作成時刻、実行ステータス(進行中、完了、失敗、停止、または停止中)で特定のトレーニングジョブを検索することができます。プロファイルをロードするには、表示したいトレーニングジョブを選択し、ロードを選択します。ジョブ名は上部のロードされたプロファイルセクションに表示されます。
ダッシュボードとタイムラインを生成するためにジョブ名を選択してください。ジョブを選択すると、UIは自動的にダッシュボードを開きます。一度に1つのプロファイルをロードして表示することができます。別のプロファイルをロードするには、まず以前にロードされたプロファイルをアンロードする必要があります。プロファイルをアンロードするには、ロードされたプロファイルセクションのゴミ箱アイコンを選択してください。
この記事では、2つのml.p4d.24xlargeインスタンスでのALBEFトレーニングジョブのプロファイルを表示します。
トレーニングジョブのロードと選択が完了した後、UIは以下のスクリーンショットに示すようにダッシュボードページを開きます。
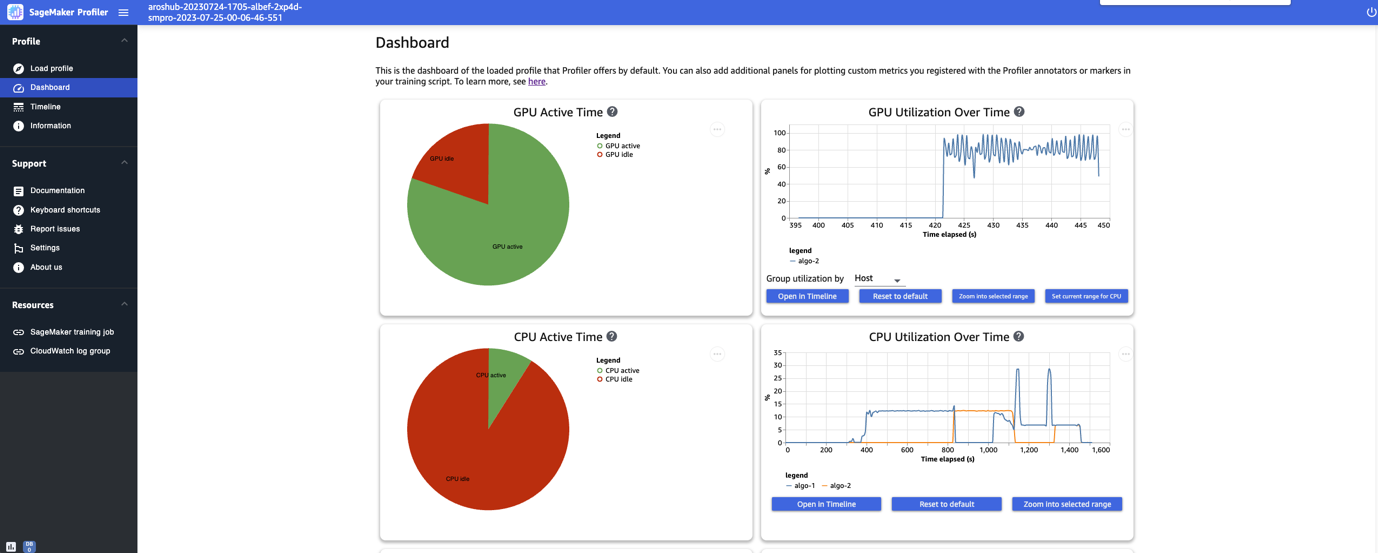
GPUアクティブ時間、時間の経過によるGPU利用率、CPUアクティブ時間、時間の経過によるCPU利用率といった主要なメトリクスのプロットを表示することができます。GPUアクティブ時間の円グラフは、GPUのアクティブ時間とアイドル時間の割合を示しており、トレーニングジョブ全体でGPUがアイドルよりもアクティブであるかどうかを確認することができます。 GPU利用率の時間軸グラフは、ノードごとの平均GPU利用率を時間の経過とともに表示し、すべてのノードを1つのチャートに集約しています。特定の時間間隔でのGPUの負荷バランス、利用率の問題、ボトルネック、アイドルの問題を確認することができます。 これらのメトリクスの詳細については、ドキュメントを参照してください。
ダッシュボードでは、すべてのGPUカーネルの実行時間、上位15のGPUカーネルの実行時間、すべてのGPUカーネルの起動回数、上位15のGPUカーネルの起動回数などの追加のプロットを提供します。以下のスクリーンショットに示すようになります。
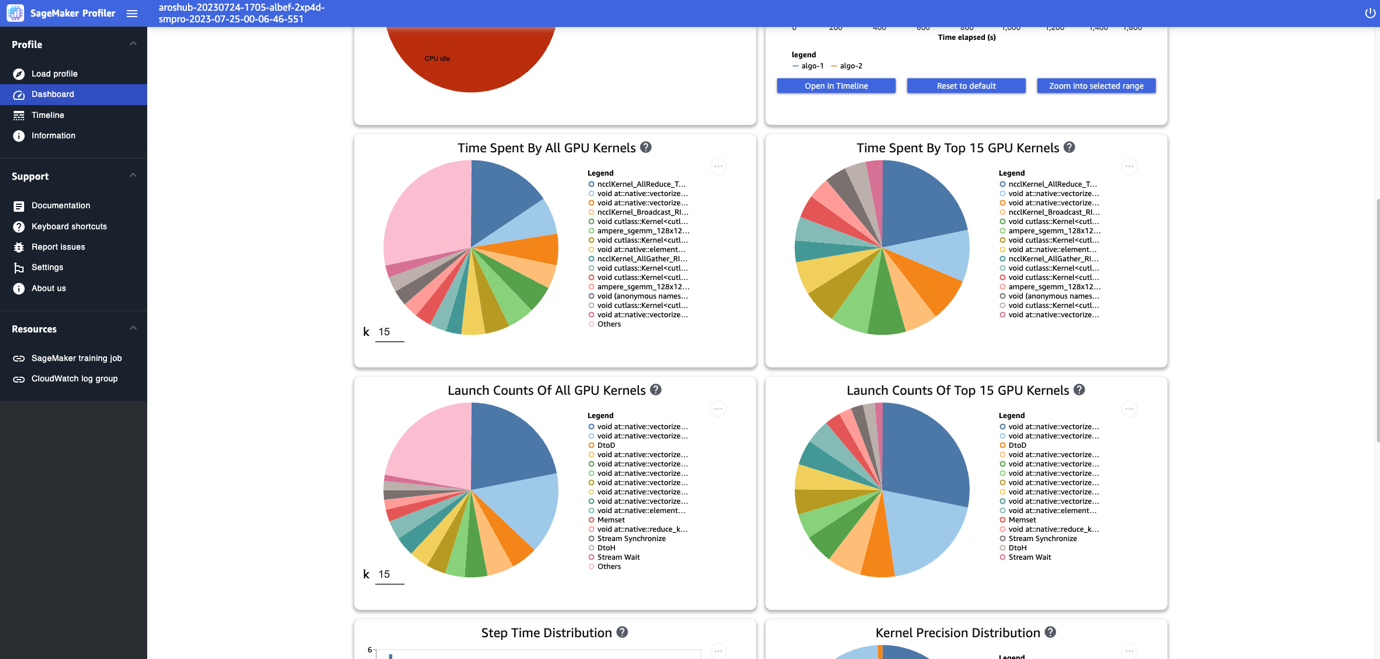
最後に、ダッシュボードでは手動で注釈付けしたカスタムメトリクスに基づいたヒストグラムを作成することもできます。新しいヒストグラムにカスタム注釈を追加する際は、トレーニングスクリプトで追加した注釈の名前を選択または入力してください。
タイムラインインターフェース
SageMaker ProfilerのUIには、操作レベルとGPUでスケジュールされたカーネルを詳細に表示するタイムラインインターフェースも含まれています。タイムラインはツリー構造で組織されており、ホストレベルからデバイスレベルまでの情報を提供します。以下のスクリーンショットに示すようになります。
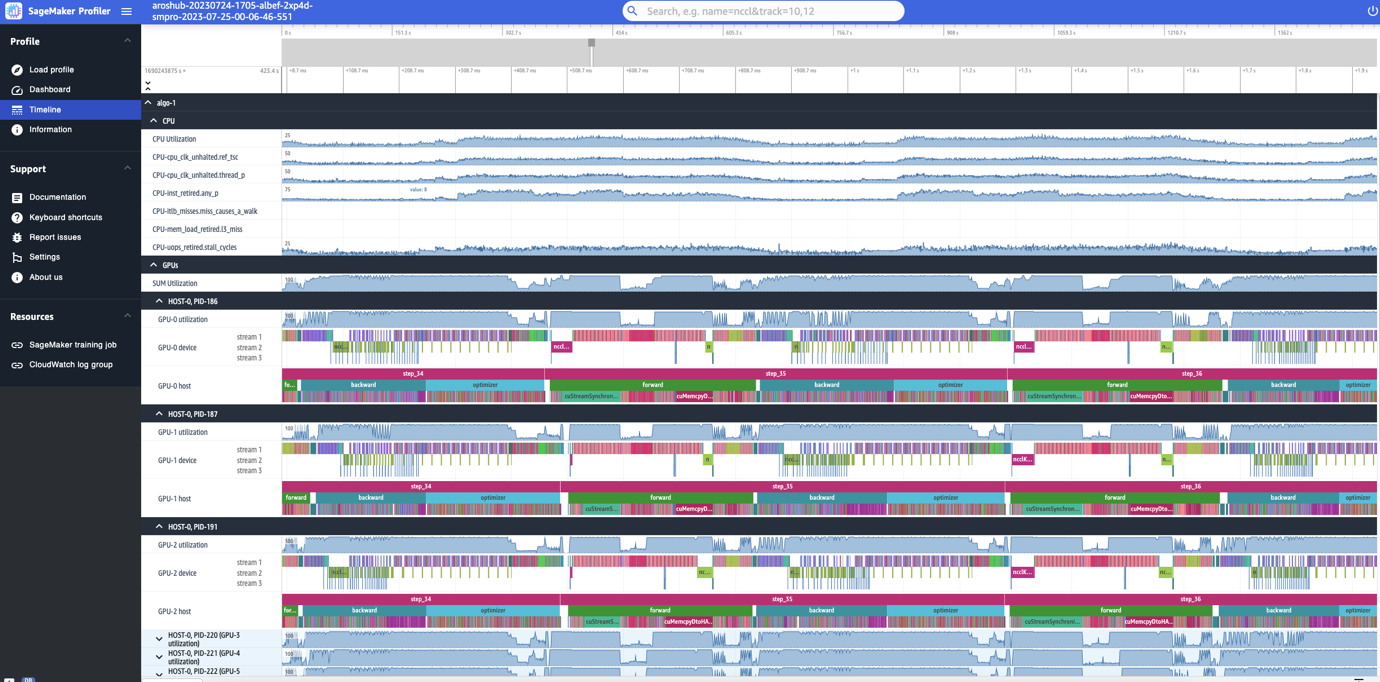
各CPUには、clk_unhalted_ref.tscやitlb_misses.miss_causes_a_walkなどのCPUパフォーマンスカウンタを追跡することができます。2x p4d.24xlargeインスタンスの各GPUには、ホストのタイムラインとデバイスのタイムラインがあります。カーネルの起動はホストのタイムライン上にあり、カーネルの実行はデバイスのタイムライン上にあります。
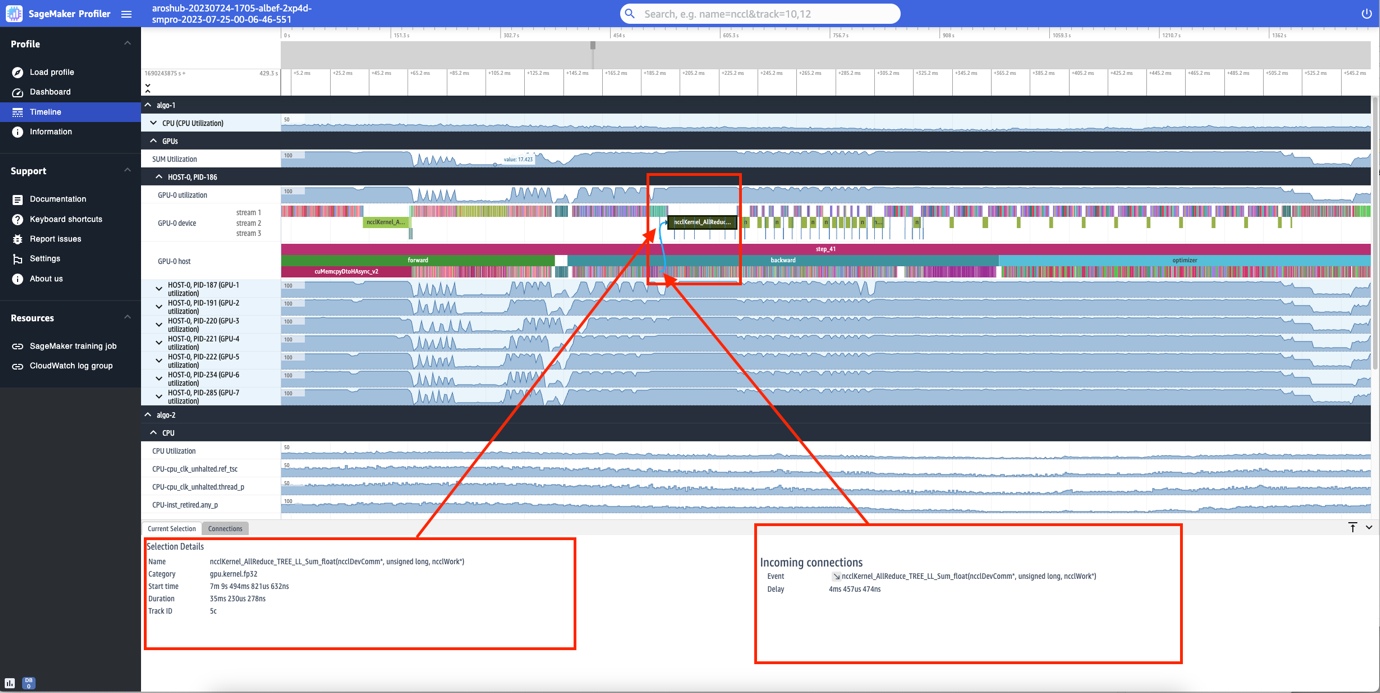
個々のステップにもズームインすることができます。次のスクリーンショットでは、step_41にズームインしています。次のスクリーンショットで選択されているタイムラインストリップは、分散トレーニングでの重要な通信と同期のステップであるAllReduce操作で、GPU-0で実行されています。スクリーンショットでは、GPU-0ホストでのカーネル起動がシアンで示されるGPU-0デバイスストリーム1で実行されるカーネルランに接続されていることに注意してください。
利用可能性と考慮事項
SageMaker Profilerは、PyTorch(バージョン2.0.0および1.13.1)およびTensorFlow(バージョン2.12.0および2.11.1)で利用可能です。以下の表は、SageMakerのサポートされているAWS Deep Learning Containersへのリンクを提供しています。
| フレームワーク | バージョン | AWS DLCイメージURI |
| PyTorch | 2.0.0 | 763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| PyTorch | 1.13.1 | 763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:1.13.1-gpu-py39-cu117-ubuntu20.04-sagemaker |
| TensorFlow | 2.12.0 | 763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:2.12.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| TensorFlow | 2.11.1 | 763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:2.11.1-gpu-py39-cu112-ubuntu20.04-sagemaker |
SageMaker Profilerは現在、次のリージョンで利用可能です:米国東部(オハイオ、北バージニア)、米国西部(オレゴン)、およびヨーロッパ(フランクフルト、アイルランド)。
SageMaker Profilerは、トレーニングインスタンスタイプml.p4d.24xlarge、ml.p3dn.24xlarge、およびml.g4dn.12xlargeで利用可能です。
サポートされているフレームワークとバージョンの完全なリストについては、ドキュメントを参照してください。
SageMaker Profilerは、SageMaker Free Tierまたは機能の無料トライアル期間が終了した後に料金が発生します。詳細については、Amazon SageMakerの価格を参照してください。
SageMaker Profilerのパフォーマンス
SageMaker Profilerのオーバーヘッドをさまざまなオープンソースのプロファイラと比較しました。比較のために使用されたベースラインは、プロファイラなしでトレーニングジョブを実行した結果から得られました。
私たちの主な調査結果は、SageMaker Profilerが一般的に請求可能なトレーニングの期間を短縮する結果となったことです。エンドツーエンドのトレーニング実行において、SageMaker Profilerはオーバーヘッド時間が少なかったため、オープンソースの代替品と比較してプロファイリングデータも少なく生成しました(最大で10倍少ない)。SageMaker Profilerによって生成されるプロファイリングアーティファクトは、ストレージの使用量も少なくなり、コストの節約にもつながります。
結論
SageMaker Profilerを使用すると、ディープラーニングモデルのトレーニング時のコンピュートリソースの利用状況について詳細な洞察を得ることができます。これにより、パフォーマンスのホットスポットやボトルネックを解決し、効率的なリソース利用を確保し、トレーニングコストを削減し、全体のトレーニング時間を短縮することができます。
SageMaker Profilerの使用を開始するには、ドキュメントを参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Maxflow Mincut定理の発見:包括的かつ形式的なアプローチ」
- 「iOSのための10の最高のデータ復旧ツール(2023年8月)」
- 「ビジネスはマルチリンガル製品分類器の精度をどのように改善できるのか?このAI論文では、訓練データが限られた言語における分類精度を高めるためのアクティブラーニング手法であるLAMMを提案しています」
- オブジェクト指向データサイエンス:コードのリファクタリング
- ランダムウォークタスクにおける時差0(Temporal-Difference(0))と定数αモンテカルロ法の比較
- データ、効率化された:より良い製品、ワークフロー、チームの構築方法
- 「データパイプラインにおけるデータ契約の役割」
