Amazon SageMakerを使用して、オーバーヘッドイメージで自己教師ありビジョン変換モデルをトレーニングする
Amazon SageMakerを使って、自己教師ありビジョン変換モデルをトレーニングする
この記事は、TravelersのBen Veasey、Jeremy Anderson、Jordan Knight、June Liと共同執筆したゲストブログ投稿です。
衛星および航空画像は、精密農業、保険リスク評価、都市開発、災害対応など、さまざまな問題に対する洞察を提供します。ただし、このデータを解釈するための機械学習(ML)モデルのトレーニングは、高コストかつ時間のかかる人手による注釈作業によって制約されています。この課題を克服する方法の1つは、自己教師あり学習(SSL)です。自己教師ありモデルは、ラベルのない大量の画像データでトレーニングすることにより、画像表現を学習し、画像分類やセグメンテーションなどの下流タスクに転送できます。このアプローチにより、未知のデータにも適用できる画像表現が生成され、パフォーマンスの高い下流モデルを構築するために必要なラベル付きデータの量が減少します。
この記事では、Amazon SageMakerを使用してオーバーヘッドイメージで自己教師ありビジョン変換モデルをトレーニングする方法を示します。TravelersはAmazon Machine Learning Solutions Lab(現在はGenerative AI Innovation Centerとして知られています)と協力して、このフレームワークを開発し、航空画像モデルの使用事例をサポートおよび強化しました。当社のソリューションはDINOアルゴリズムに基づいており、SageMaker分散データ並列ライブラリ(SMDDP)を使用してデータを複数のGPUインスタンスに分割します。事前トレーニングが完了すると、DINO画像表現はさまざまな下流タスクに転送できます。このイニシアチブにより、Travelers Data&Analyticsスペース内でのモデルのパフォーマンスが向上しました。
ソリューションの概要
ビジョン変換モデルの事前トレーニングとそれらを監督された下流タスクに転送する2段階のプロセスは、次のダイアグラムに示されています。
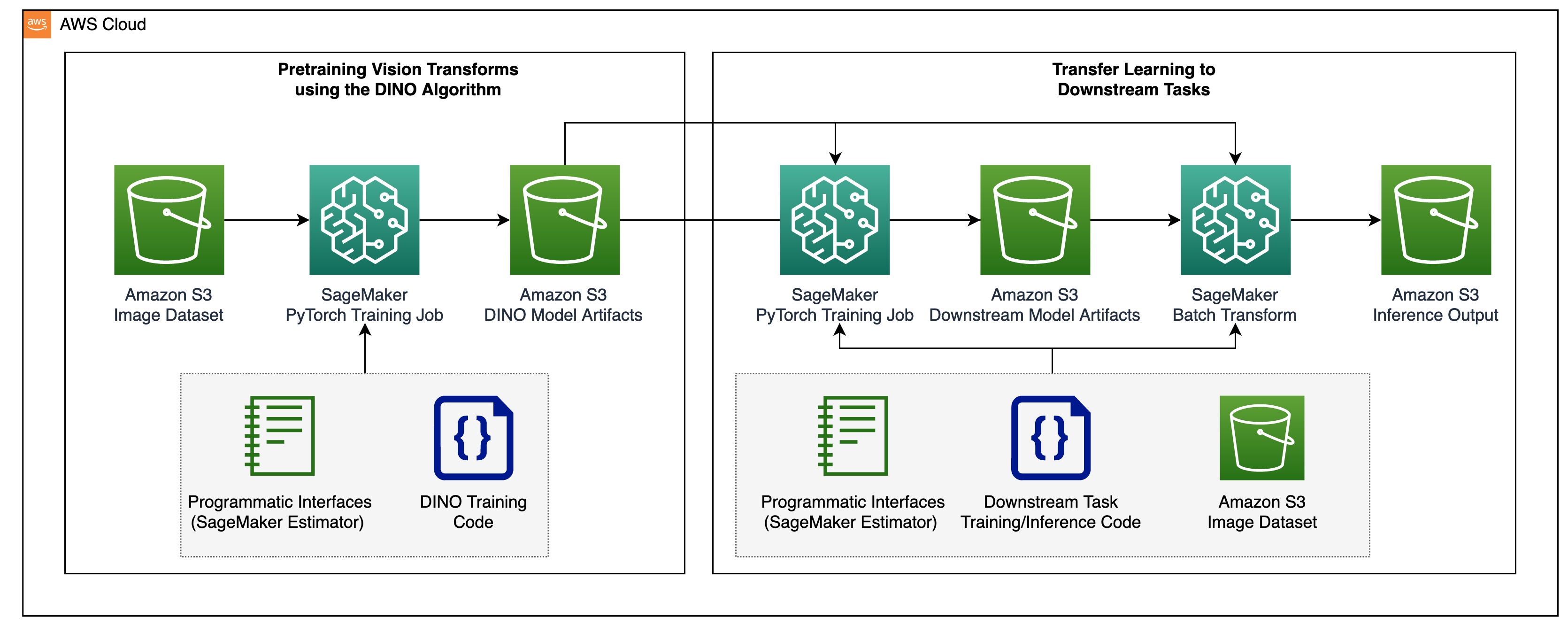
次のセクションでは、BigEarthNet-S2データセットの衛星画像を使用したソリューションの手順を説明します。当社はDINOリポジトリで提供されているコードをベースに構築しています。
前提条件
開始する前に、SageMakerノートブックインスタンスとAmazon Simple Storage Service(Amazon S3)バケットへのアクセス権が必要です。
BigEarthNet-S2データセットの準備
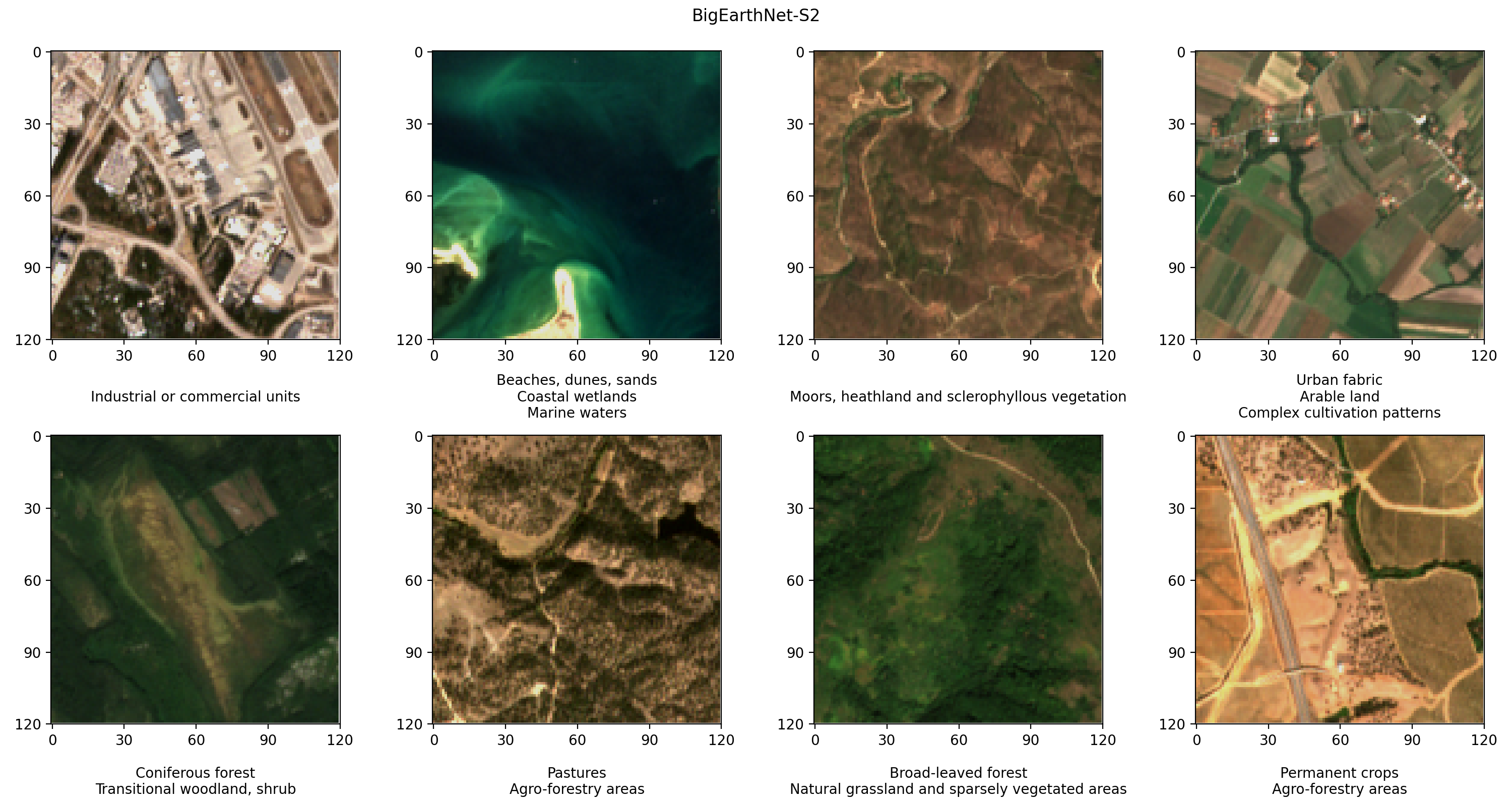
BigEarthNet-S2は、Sentinel-2衛星によって収集された590,325の多光学画像を含むベンチマークアーカイブです。これらの画像は、2017年6月から2018年5月の間に10のヨーロッパの国の土地被覆または物理的な地表特徴を文書化しています。各画像の土地被覆の種類(牧草地や森林など)は、19のラベルに従って注釈されています。以下は、いくつかの例のRGB画像とそのラベルです。
ワークフローの最初のステップは、DINOのトレーニングと評価のためにBigEarthNet-S2データセットを準備することです。SageMakerノートブックインスタンスのターミナルからデータセットをダウンロードして展開します:
wget https://bigearth.net/downloads/BigEarthNet-S2-v1.0.tar.gz
tar -xvf BigEarthNet-S2-v1.0.tar.gzデータセットのサイズは約109GBです。各画像は個別のフォルダに格納され、12のスペクトルチャンネルを含んでいます。60メートルの空間解像度(60メートルのピクセルの高さ/幅)を持つ3つのバンドは、エアロゾル(B01)、水蒸気(B09)、および雲(B10)を識別するために設計されています。20メートルの空間解像度を持つ6つのバンドは、植生(B05、B06、B07、B8A)を識別し、雪、氷、および雲(B11、B12)を区別します。10メートルの空間解像度を持つ3つのバンドは、可視光線と近赤外線光(B02、B03、B04、B8 / B8A)を捉えるのに役立ちます。さらに、各フォルダには画像のメタデータを含むJSONファイルがあります。データの詳細な説明は、BigEarthNetガイドで提供されています。
データの統計分析およびDINOトレーニング中の画像の読み込みを行うために、個々のメタデータファイルを共通のgeopandas Parquetファイルに変換します。これは、BigEarthNet CommonおよびBigEarthNet GDF Builderヘルパーパッケージを使用して行うことができます:
python -m bigearthnet_gdf_builder.builder build-recommended-s2-parquet BigEarthNet-v1.0/生成されたメタデータファイルには、季節の雪、雲、雲の影に完全に覆われた71,042枚の画像を除外した推奨画像セットが含まれています。また、各画像の取得日、場所、土地被覆、およびトレーニング、検証、テストの分割に関する情報も含まれています。
BigEarthNet-S2の画像とメタデータファイルはS3バケットに保存されています。DINOトレーニング中には真のカラー画像を使用するため、赤(B04)、緑(B03)、青(B02)のバンドのみをアップロードします:
aws s3 cp final_ben_s2.parquet s3://bigearthnet-s2-dataset/metadata/
aws s3 cp BigEarthNet-v1.0/ s3://bigearthnet-s2-dataset/data_rgb/ \
--recursive \
--exclude "*" \
--include "_B02.tif" \
--include "_B03.tif" \
--include "_B04.tif"データセットのサイズは約48 GBで、次の構造を持っています:
bigearthnet-s2-dataset/ Amazon S3バケット
├── metadata/
│ └── final_ben_s2.parquet
└── dataset_rgb/
├── S2A_MSIL2A_20170613T101031_0_45/
│ └── S2A_MSIL2A_20170613T101031_0_45_B02.tif 青チャンネル
│ └── S2A_MSIL2A_20170613T101031_0_45_B03.tif 緑チャンネル
│ └── S2A_MSIL2A_20170613T101031_0_45_B04.tif 赤チャンネルSageMakerでDINOモデルをトレーニングする
データセットをAmazon S3にアップロードしたので、BigEarthNet-S2でDINOモデルをトレーニングします。以下の図に示すように、DINOアルゴリズムは入力画像の異なるグローバルおよびローカルなクロップを学生ネットワークと教師ネットワークに渡します。学生ネットワークはクロスエントロピー損失を最小化することで教師ネットワークの出力と一致させるように学習されます。学生と教師の重みは指数移動平均 (EMA) によって接続されます。
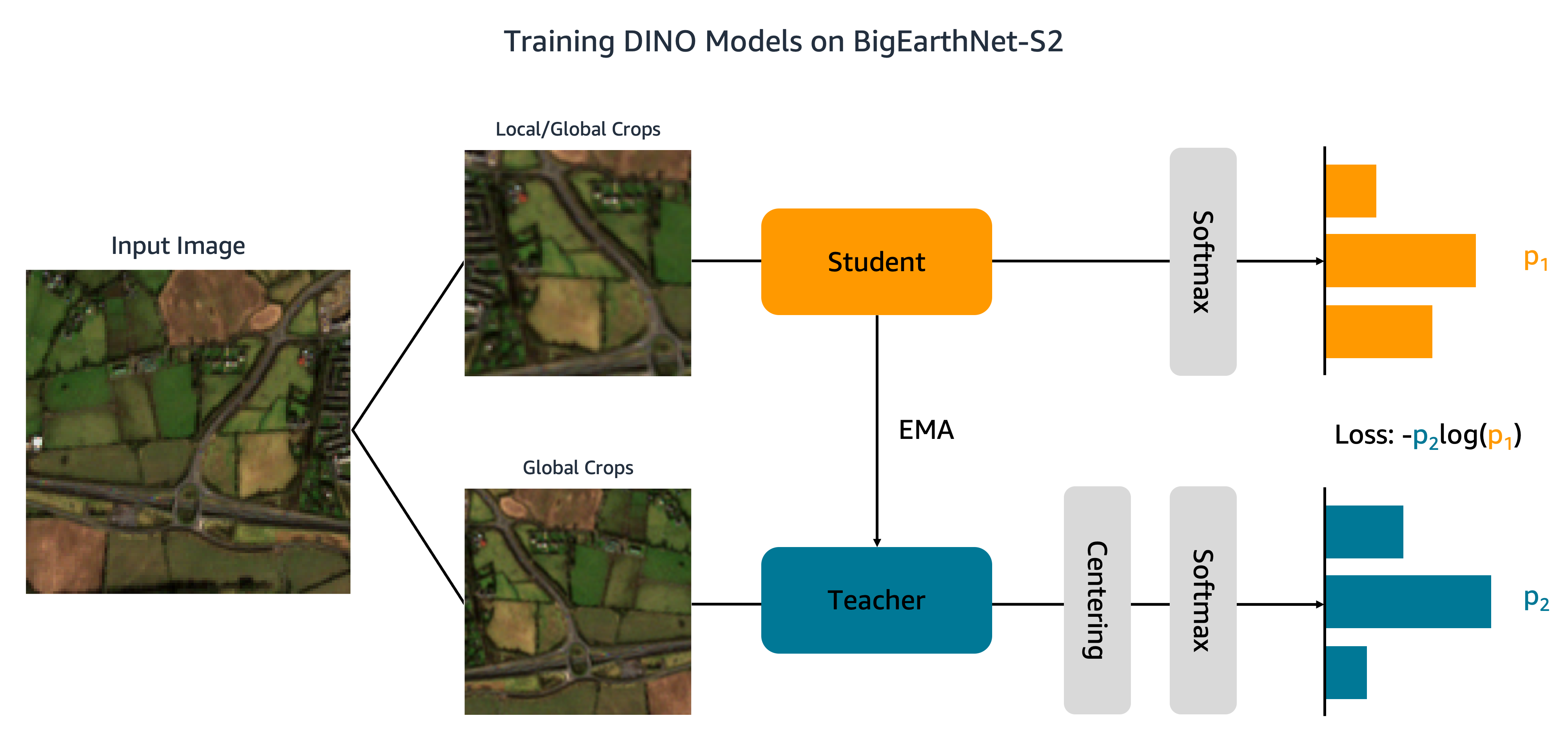
元のDINOコードには2つの変更を加えています。まず、BigEarthNet-S2の画像を読み込むためのカスタムのPyTorchデータセットクラスを作成します。コードは元々ImageNetデータを処理するために書かれており、画像がクラスごとに保存されることを想定しています。しかし、BigEarthNet-S2は各画像が独自のサブフォルダに存在するマルチラベルのデータセットです。私たちのデータセットクラスはメタデータに保存されているファイルパスを使用して各画像をロードします:
import pandas as pd
import rasterio
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
OPTICAL_MAX_VALUE = 2000
LAND_COVER_LABELS = [
"都市地域",
"工業地帯または商業施設",
"耕地",
"恒久的な作物",
"牧草地",
"複雑な耕作パターン",
"主に農業に占められた土地で、自然植生の広範な地域が存在する",
"農林業エリア",
"広葉樹林",
"針葉樹林",
"混合林",
"天然草地およびまばらに植生した地域",
"湿地、ヒース、多肉植物の植生",
"移行林地、低木",
"浜、砂丘、砂",
"内陸湿地",
"沿岸湿地",
"内陸水域",
"海洋水域",
]
class BigEarthNetDataset(Dataset):
"""
メタデータファイルからBigEarthNet-S2の画像を読み込むPyTorchデータセットクラス。
Args:
metadata_file: メタデータファイルへのパス
data_dir: BigEarthNet-S2データがあるディレクトリ
split: train、validation、またはtestのいずれかの分割
transform: 入力画像に適用する変換
"""
def __init__(self, metadata_file, data_dir, split="train", transform=None):
# メタデータから画像ファイルのパスを取得
metadata = pd.read_parquet(metadata_file)
self.metadata_split = metadata[metadata["original_split"] == split]
self.data_dir = data_dir
self.patch_names = self.metadata_split["name"].tolist()
# ランドカバーラベルをone-hotエンコードする
multiclass_labels = self.metadata_split.new_labels.tolist()
self.labels = self.get_multi_onehot_labels(multiclass_labels)
# 変換
self.transform = transform
def __len__(self):
"""データセットの長さを返す。"""
return len(self.metadata_split)
def __getitem__(self, index):
"""指定されたインデックスの画像とラベルを返す。"""
patch_name = self.patch_names[index]
file_path = os.path.join(self.data_dir, patch_name)
# RGB画像を生成
r_channel = rasterio.open(os.path.join(file_path, patch_name + "_B04.tif")).read(1)
g_channel = rasterio.open(os.path.join(file_path, patch_name + "_B03.tif")).read(1)
b_channel = rasterio.open(os.path.join(file_path, patch_name + "_B02.tif")).read(1)
image = np.stack([r_channel, g_channel, b_channel], axis=2)
image = image / OPTICAL_MAX_VALUE * 255
image = np.clip(image, 0, 225).astype(np.uint8)
# 画像変換を適用
image = Image.fromarray(image, mode="RGB")
if self.transform is not None:
image = self.transform(image)
# ラベルをロード
label = self.labels[index]
return image, label
def get_multi_onehot_labels(self, multiclass_labels):
"""BEN-19のラベルをone-hotエンコードされたベクトルに変換する。"""
targets = torch.zeros([len(multiclass_labels), len(LAND_COVER_LABELS)])
for index, img_labels in enumerate(multiclass_labels):
for label in img_labels:
index_hot = LAND_COVER_LABELS.index(label)
targets[index, index_hot] = 1.
return targetsこのデータセットクラスは、トレーニング中にmain_dino.pyで呼び出されます。コードには、土地被覆ラベルをワンホットエンコードする関数が含まれていますが、これらのラベルはDINOアルゴリズムでは使用されません。
DINOコードへの2つ目の変更は、SMDDPのサポートを追加することです。次のコードをutil.pyファイルのinit_distributed_mode関数に追加します:
util.pyファイルのinit_distributed_mode関数:
def init_distributed_mode(args):
if json.loads(
os.environ.get('SM_FRAMEWORK_PARAMS', '{}'))
.get('sagemaker_distributed_dataparallel_enabled', False)
):
# SMDDPでトレーニングを開始
dist.init_process_group(backend='smddp')
args.word_size = dist.get_world_size()
args.gpu = int(os.environ['LOCAL_RANK'])これらの調整を行うことで、SageMakerを使用してBigEarthNet-S2でDINOモデルをトレーニングする準備が整いました。複数のGPUまたはインスタンスでトレーニングするために、DINOのトレーニングスクリプト、画像およびメタデータファイルパス、およびトレーニングのハイパーパラメータを入力するSageMaker PyTorch Estimatorを作成します:
import time
from sagemaker.pytorch import PyTorch
# 最終的なモデルアーティファクトがアップロードされる出力バケット
DINO_OUTPUT_BUCKET = 'dino-models'
# トレーニングインスタンス上のパス
sm_metadata_path = '/opt/ml/input/data/metadata'
sm_data_path = '/opt/ml/input/data/train'
sm_output_path = '/opt/ml/output/data'
sm_checkpoint_path = '/opt/ml/checkpoints'
# トレーニングジョブの名前
dino_base_job_name = f'dino-model-{int(time.time())}'
# SageMaker Estimatorを作成
estimator = PyTorch(
base_job_name=dino_base_job_name,
source_dir='path/to/aerial_featurizer',
entry_point='main_dino.py',
role=role,
framework_version="1.12",
py_version="py38",
instance_count=1,
instance_type="ml.p3.16xlarge",
distribution = {'smdistributed':{'dataparallel':{'enabled': True}}},
volume_size=100,
sagemaker_session=sagemaker_session,
hyperparameters = {
# エントリポイントスクリプトに渡されるハイパーパラメータ
'arch': 'vit_small',
'patch_size': 16,
'metadata_dir': sm_metadata_path,
'data_dir': sm_data_path,
'output_dir': sm_output_path,
'checkpoint_dir': sm_checkpoint_path,
'epochs': 100,
'saveckp_freq': 20,
},
max_run=24*60*60,
checkpoint_local_path = sm_checkpoint_path,
checkpoint_s3_uri =f's3://{DINO_OUTPUT_BUCKET}/checkpoints/{base_job_name}',
debugger_hook_config=False,
)このコードでは、パッチサイズ16の小さなビジョン変換モデル(2100万のパラメータ)を100エポックでトレーニングすることを指定しています。初期データのダウンロード時間を短縮するために、各トレーニングジョブに対して新しいcheckpoint_s3_uriを作成するのがベストプラクティスです。SMDDPを使用しているため、ml.p3.16xlarge、ml.p3dn.24xlarge、またはml.p4d.24xlargeのインスタンスでトレーニングする必要があります。これは、SMDDPは最大のマルチGPUインスタンスでのみ有効になっているためです。SMDDPを使用せずにより小さいインスタンスタイプでトレーニングするには、Estimatorからdistributionおよびdebugger_hook_config引数を削除する必要があります。
SageMaker PyTorch Estimatorを作成した後、fitメソッドを呼び出してトレーニングジョブを開始します。BigEarthNet-S2のメタデータと画像のためにAmazon S3 URIを使用して入力トレーニングデータを指定します:
# トレーニングを開始するためにfitを呼び出す
estimator.fit(
inputs={
'metadata': 's3://bigearthnet-s2-dataset/metadata/',
'train': 's3://bigearthnet-s2-dataset/data_rgb/',
},
wait=False
)SageMakerはインスタンスを起動し、トレーニングスクリプトと依存関係をコピーしてDINOトレーニングを開始します。以下のコマンドを使用して、Jupyterノートブックからトレーニングジョブの進捗状況を監視できます:
# トレーニングを監視する
training_job_name = estimator.latest_training_job.name
attached_estimator = PyTorch.attach(training_job_name)
attached_estimator.logs()私たちはSageMakerコンソールのトレーニングジョブの下でインスタンスのメトリクスをモニタリングし、ログファイルを表示することもできます。以下の図では、ml.p3.16xlargeインスタンスでバッチサイズ128でトレーニングされたDINOモデルのGPU利用率と損失関数をプロットしています。
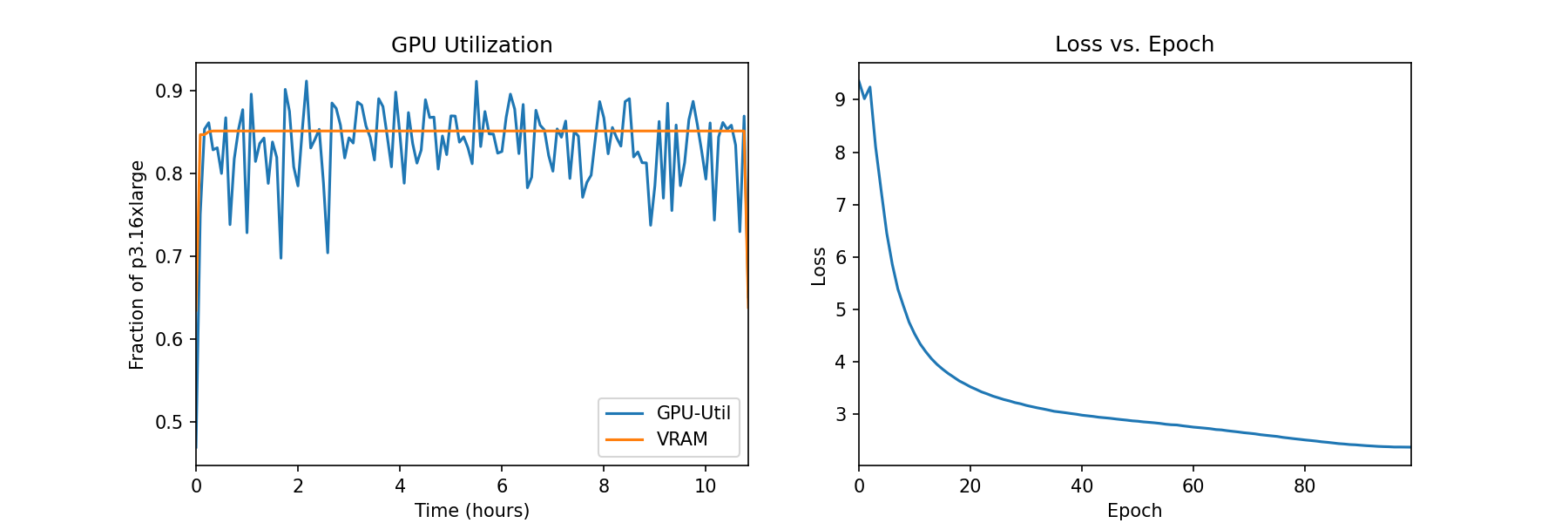
トレーニング中、GPUの利用率はml.p3.16xlargeの容量(8つのNVIDIA Tesla V100 GPU)の83%であり、VRAMの使用率は85%です。損失関数は各エポックごとに着実に減少し、学生ネットワークと教師ネットワークの出力がより類似していることを示しています。トレーニング全体では約11時間かかります。
ダウンストリームタスクへの転移学習
トレーニング済みのDINOモデルは、画像分類やセグメンテーションなどのダウンストリームタスクに転送することができます。このセクションでは、事前トレーニングされたDINOの特徴を使用して、BigEarthNet-S2データセットの画像の土地被覆クラスを予測します。以下の図に示すように、凍結されたDINOの特徴の上にマルチラベルの線形分類器をトレーニングします。この例では、入力画像は耕作地と牧草地の被覆に関連付けられています。
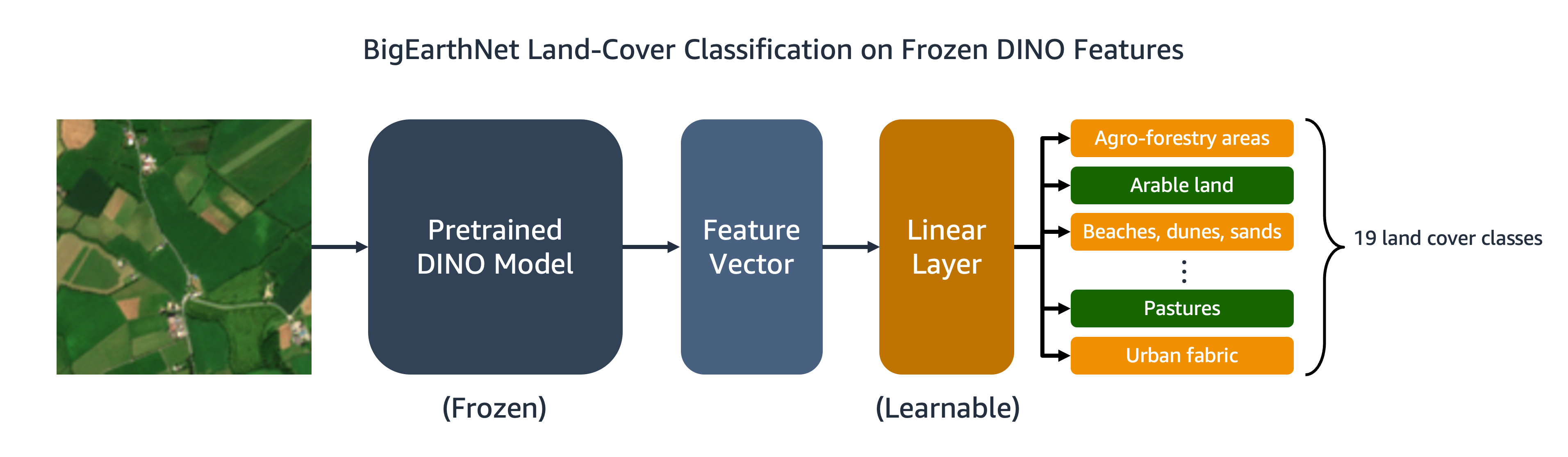
線形分類器のほとんどのコードは元のDINOリポジトリに既に存在しています。特定のタスクに合わせていくつかの調整を行います。前と同様に、カスタムのBigEarthNetデータセットを使用してトレーニングと評価中に画像をロードします。画像のラベルは19次元のバイナリベクトルとしてワンホットエンコードされます。損失関数にはバイナリクロスエントロピーを使用し、モデルのパフォーマンスを評価するために平均適合率を計算します。
分類器をトレーニングするために、eval_linear.pyというトレーニングスクリプトを実行するSageMaker PyTorch Estimatorを作成します。
# モデルアーティファクトをアップロードする出力バケット
CLASSIFIER_OUTPUT_BUCKET = 'land-cover-classification'
# DINOのチェックポイント名
checkpoint = 'checkpoint.pth'
# トレーニングインスタンス上のパス
sm_dino_path = f'/opt/ml/input/data/dino_checkpoint'
sm_dino_checkpoint = f'{sm_dino_path}/{checkpoint}'
# トレーニングジョブ名
classifier_base_job_name = f'linear-classifier-{int(time.time())}'
# Estimatorを作成
estimator = PyTorch(
base_job_name=classifier_base_job_name,
source_dir='path/to/aerial_featurizer',
entry_point = 'eval_linear.py',
role=role,
framework_version='1.12',
py_version='py38',
instance_count=1,
instance_type='ml.p3.2xlarge',
sagemaker_session=sagemaker_session,
hyperparameters = {
# entry pointスクリプトに渡されるハイパーパラメータ
'arch': 'vit_small',
'pretrained_weights': sm_dino_checkpoint,
'epochs': 50,
'data_dir': sm_data_path,
'metadata_dir': sm_metadata_path,
'output_dir': sm_checkpoint_path,
'num_labels': 19,
},
max_run=1*60*60,
checkpoint_local_path = sm_checkpoint_path,
checkpoint_s3_uri =f's3://{CLASSIFIER_OUTPUT_BUCKET}/checkpoints/{base_job_name}',
)Amazon S3上のBigEarthNet-S2のメタデータとトレーニング画像、およびDINOモデルのチェックポイントの場所を指定して、fitメソッドを使用してトレーニングジョブを開始します。
# トレーニングを開始するためにfitを呼び出す
estimator.fit(
inputs={
'metadata': 's3://bigearthnet-s2-dataset/metadata/',
'dataset': 's3://bigearthnet-s2-dataset/data_rgb/',
'dino_checkpoint': f's3://bigearthnet-s2-dataset/dino-models/checkpoints/{dino_base_job_name}',
},
wait=False
)トレーニングが完了したら、SageMakerバッチトランスフォームまたはSageMaker Processingを使用してBigEarthNet-S2テストセットで推論を実行することができます。以下の表では、2つの異なるDINO画像表現を使用してテストセットの画像上での線形モデルの平均適合率を比較しています。最初のモデルであるViT-S/16(ImageNet)は、DINOリポジトリに含まれている小さなビジョントランスフォーマーチェックポイントであり、ImageNetデータセットの正面画像を事前トレーニングしています。2番目のモデルであるViT-S/16(BigEarthNet-S2)は、空中画像で事前トレーニングして生成したモデルです。
| モデル | 平均精度 |
| ViT-S/16 (ImageNet) | 0.685 |
| ViT-S/16 (BigEarthNet-S2) | 0.732 |
私たちは、BigEarthNet-S2で事前学習されたDINOモデルが、ImageNetで事前学習されたDINOモデルよりも土地被覆分類タスクにおいて優れた転移性を持つことを見つけました。これにより、平均精度が6.7%向上しました。
クリーンアップ
DINOのトレーニングと転移学習が完了したら、料金が発生しないようにリソースをクリーンアップします。ノートブックインスタンスを停止または削除し、Amazon S3から不要なデータやモデルアーティファクトを削除します。
結論
この記事では、SageMakerを使用してオーバーヘッド画像でDINOモデルをトレーニングする方法を示しました。SageMaker PyTorch EstimatorsとSMDDPを使用して、明示的なラベルなしでBigEarthNet-S2画像の表現を生成しました。次に、DINOの特徴をダウンストリームの画像分類タスクに転送しました。これは、BigEarthNet-S2画像の土地被覆クラスを予測することを含みます。このタスクでは、衛星画像での事前トレーニングは、ImageNetでの事前トレーニングに比べて平均精度が6.7%向上しました。
このソリューションは、大規模な未ラベルの航空および衛星画像データセットでDINOモデルをトレーニングするためのテンプレートとして使用できます。DINOとSageMakerでモデルを構築する詳細については、次のリソースをご覧ください:
- Emerging Properties in Self-Supervised Vision Transformers
- Use PyTorch with Amazon SageMaker
- SageMakerのデータ並列処理ライブラリ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Cheetorと会ってください:幅広い種類の交互に織り交ぜられたビジョン言語の指示を効果的に処理し、最先端のゼロショットパフォーマンスを達成する、Transformerベースのマルチモーダルな大規模言語モデル(MLLMs)」
- メタAIのハンプバック!LLMの自己整列と指示逆翻訳による大きな波を起こしています
- 「3D-VisTAに会いましょう:さまざまな下流タスクに簡単に適応できる、3Dビジョンとテキストの整列のための事前学習済みトランスフォーマー」
- 「なぜOpenAIのAPIは英語以外の言語に対してより高価なのか」
- 「大規模言語モデル(LLM)を実世界のビジネスアプリケーションに移す」
- 「AIのプロセス」
- 「ディープフェイクの解明:ヘッドポーズ推定パターンを活用した検出精度の向上」