Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
今日、生成型AIモデルは、テキストの要約、Q&A、画像およびビデオの生成など、さまざまなタスクをカバーしています。出力の品質を向上させるために、nショット学習、プロンプトエンジニアリング、検索増強生成(RAG)、およびファインチューニングなどの手法が使用されています。ファインチューニングにより、これらの生成型AIモデルを調整して、ドメイン固有のタスクでのパフォーマンスを向上させることができます。
Amazon SageMakerを使用すると、Pythonコードに@remoteデコレータを付けるだけで、SageMakerトレーニングジョブを簡単に実行できます。SageMaker Python SDKは、既存のワークスペース環境、および関連するデータ処理コードとデータセットを、トレーニングプラットフォームで実行されるSageMakerトレーニングジョブに自動的に変換します。これにより、より自然でオブジェクト指向の方法でコードを記述し、最小限の変更でリモートクラスタでトレーニングジョブを実行するためにSageMakerの機能を使用できる利点があります。
この投稿では、SageMaker Python SDKの@remoteデコレータを使用して、Falcon-7B Foundationモデル(FM)をファインチューニングする方法を紹介します。また、Hugging Faceのパラメータ効率の高いファインチューニング(PEFT)ライブラリと、bitsandbytesを介した量子化技術を使用して、ファインチューニングをサポートします。このブログで紹介されたコードは、Llama-2 13bなどの他のFMのファインチューニングにも使用することができます。
このモデルの完全精度表現は、単一または複数のグラフィックプロセッシングユニット(GPU)上のメモリに収まるのに課題がある場合があります。または、より大きなインスタンスが必要な場合もあります。したがって、コストを増やさずにこのモデルをファインチューニングするために、Quantized LLMs with Low-Rank Adapters(QLoRA)という手法を使用します。QLoRAは、メモリ使用量を削減しながら非常に良いパフォーマンスを維持する効率的なファインチューニング手法です。
@remoteデコレータを使用する利点
さらに進む前に、SageMakerと一緒に開発者生産性を向上させる@remoteデコレータの使用方法を理解しましょう:
- @remoteデコレータは、SageMaker EstimatorsとSageMaker入力チャネルを明示的に呼び出さずに、ネイティブなPythonコードを使用してトレーニングジョブを直接トリガします
- SageMakerでモデルをトレーニングする開発者にとっての低い障壁です。
- 統合開発環境(IDE)を切り替える必要はありません。お好きなIDEでコードの記述を続け、SageMakerトレーニングジョブを呼び出します。
- コンテナについて学ぶ必要はありません。要件.txtに依存関係を指定し、それをリモートデコレータに提供し続けます。
前提条件
このソリューションの一部として作成されるリソースを管理する権限を持つAWS Identity and Access Management(AWS IAM)ロールを持つAWSアカウントが必要です。詳細については、「AWSアカウントの作成」を参照してください。
この投稿では、Amazon SageMaker Studioを使用して、Data Science 3.0イメージとml.t3.mediumファストローンチインスタンスを使用します。ただし、お好みの統合開発環境(IDE)を使用することもできます。AWS Command Line Interface(AWS CLI)の認証情報を正しく設定する必要があります。詳細については、「AWS CLIの設定」を参照してください。
ファインチューニングには、この投稿ではFalcon-7Bにml.g5.12xlargeインスタンスを使用します。AWSアカウントでこのインスタンスの十分な容量があることを確認してください。
この投稿で示されているソリューションを再現するために、このGithubリポジトリをクローンする必要があります。
ソリューションの概要
- Falcon-7Bモデルのファインチューニングのための事前準備
- リモートデコレータの設定を行う
- AWSサービスFAQを含むデータセットの前処理
- AWSサービスFAQでFalcon-7Bをファインチューニングする
- AWSサービスに関連するサンプルの質問でファインチューニングモデルをテストする
1. Falcon-7Bモデルのファインチューニングのための事前準備をインストールする
SageMaker Studioで、ImageをData Science、KernelをPython 3として選択し、ノートブックfalcon-7b-qlora-remote-decorator_qa.ipynbを起動します。 requirements.txtに記載されているすべての必要なライブラリをインストールします。いくつかのライブラリはノートブックインスタンス自体にインストールする必要があります。データセットの処理およびSageMakerトレーニングジョブのトリガリングに必要なその他の操作を実行します。
%pip install -r requirements.txt
%pip install -q -U transformers==4.31.0
%pip install -q -U datasets==2.13.1
%pip install -q -U peft==0.4.0
%pip install -q -U accelerate==0.21.0
%pip install -q -U bitsandbytes==0.40.2
%pip install -q -U boto3
%pip install -q -U sagemaker==2.154.0
%pip install -q -U scikit-learn2. リモートデコレータの設定をセットアップする
Amazon SageMakerのトレーニングジョブに関連するすべての設定を指定する設定ファイルを作成します。このファイルは、トレーニングジョブの実行中に@remoteデコレータによって読み込まれます。このファイルには、依存関係、トレーニングイメージ、インスタンス、およびトレーニングジョブに使用される実行ロールなどの設定が含まれています。設定ファイルがサポートするすべての設定の詳細については、SageMaker Python SDKの「設定とデフォルトを使用した設定」を参照してください。
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: ./requirements.txt
ImageUri: '{aws_account_id}.dkr.ecr.{region}.amazonaws.com/huggingface-pytorch-training:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04'
InstanceType: ml.g5.12xlarge
RoleArn: arn:aws:iam::111122223333:role/ExampleSageMakerRole@remoteデコレータを使用するためにconfig.yamlファイルを使用する必要はありませんが、これはすべての設定を@remoteデコレータに供給するためのより整理された方法です。これにより、SageMakerおよびAWS関連のパラメータをコードの外部に保持し、チームメンバー全員が使用する設定ファイルのセットアップに一度だけの努力が必要になります。すべての設定はデコレータ引数に直接指定することもできますが、それでは可読性や変更の保守性が低下します。また、管理者が設定ファイルを作成し、環境内のすべてのユーザーと共有することもできます。
AWSサービスのFAQを含むデータセットの前処理
次のステップは、データセットを読み込んで前処理し、トレーニングジョブの準備を整えることです。まず、データセットを確認しましょう。
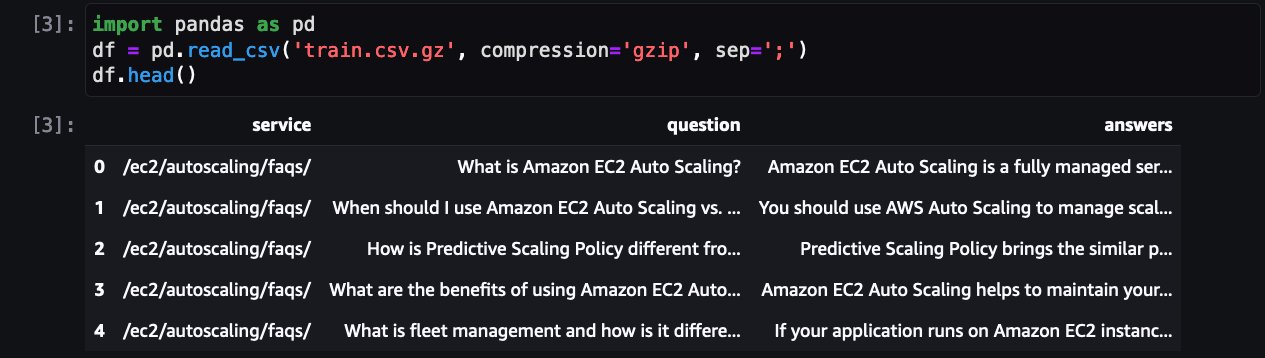
これはAWSサービスのFAQを示しています。QLoRAに加えて、bitsanbytesは、凍結されたLLMを4ビットに量子化し、それにLoRAアダプタを取り付けるために使用されます。
各FAQサンプルをプロンプト形式に変換するためのプロンプトテンプレートを作成します。
from random import randint
# custom instruct prompt start
prompt_template = f"{{question}}\n---\nAnswer:\n{{answer}}{{eos_token}}"
# template dataset to add prompt to each sample
def template_dataset(sample):
sample["text"] = prompt_template.format(question=sample["question"],
answer=sample["answers"],
eos_token=tokenizer.eos_token)
return sample次のステップは、入力(テキスト)をトークンIDに変換することです。これはHugging Face Transformers Tokenizerによって行われます。
from transformers import AutoTokenizer
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Set the Falcon tokenizer
tokenizer.pad_token = tokenizer.eos_tokenこれで、prompt_template関数を使用してすべてのFAQをプロンプト形式に変換し、トレーニングデータセットとテストデータセットをセットアップするだけです。

4. AWSサービスのFAQでFalcon-7Bを微調整する
今度はトレーニングスクリプトを準備し、トレーニング関数train_fnを定義し、関数に@remoteデコレータを付けます。
トレーニング関数は以下のことを行います:
- データセットをトークン化してチャンク化する
BitsAndBytesConfigをセットアップし、モデルが4ビットで読み込まれること、しかし計算時にはbfloat16に変換されることを指定する- モデルをロードする
- ユーティリティメソッド
find_all_linear_namesを使用して、ターゲットモジュールを見つけ、必要な行列を更新する - LoRAの設定を作成し、更新行列のランキング(
s)、スケーリングファクター(lora_alpha)、LoRA更新行列を適用するモジュール(target_modules)、Loraレイヤーのドロップアウト確率(lora_dropout)、task_typeなどを指定する - トレーニングと評価を開始する
import bitsandbytes as bnb
def find_all_linear_names(hf_model):
lora_module_names = set()
for name, module in hf_model.named_modules():
if isinstance(module, bnb.nn.Linear4bit):
names = name.split(".")
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if "lm_head" in lora_module_names:
lora_module_names.remove("lm_head")
return list(lora_module_names)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from sagemaker.remote_function import remote
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
import transformers
# 訓練を開始する
@remote(volume_size=50)
def train_fn(
model_name,
train_ds,
test_ds,
lora_r=8,
lora_alpha=32,
lora_dropout=0.05,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
learning_rate=2e-4,
num_train_epochs=1
):
# データセットをトークン化してチャンクに分割する
lm_train_dataset = train_ds.map(
lambda sample: tokenizer(sample["text"]), batched=True, batch_size=24, remove_columns=list(train_dataset.features)
)
lm_test_dataset = test_ds.map(
lambda sample: tokenizer(sample["text"]), batched=True, remove_columns=list(test_dataset.features)
)
# トータルサンプル数を表示する
print(f"トレーニングサンプルの総数: {len(lm_train_dataset)}")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# Falconでは、リモートコードの実行を許可する必要があります。
# これは、モデルがまだtransformersの一部ではない新しいアーキテクチャを使用しているためです。
# コードはモデルの著者によってリポジトリで提供されています。
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto")
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
# Loraの対象モジュールを取得する
modules = find_all_linear_names(model)
print(f"クオンタイズするモジュールの数: {len(modules)} 個: {modules}")
config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=modules,
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
trainer = transformers.Trainer(
model=model,
train_dataset=lm_train_dataset,
eval_dataset=lm_test_dataset,
args=transformers.TrainingArguments(
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
logging_steps=2,
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
bf16=True,
save_strategy="no",
output_dir="outputs"
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
trainer.evaluate()
model.save_pretrained("/opt/ml/model")そして、train_fn()を呼び出します
train_fn(model_id, train_dataset, test_dataset)チューニングジョブはAmazon SageMakerのトレーニングクラスタで実行されます。チューニングジョブの完了を待ちます。
5. AWSサービスに関連するサンプルの質問でファインチューニングモデルをテストする
さて、モデルにいくつかのテストを実行する時間です。最初に、モデルをロードしましょう:
from peft import PeftModel, PeftConfig
import torch
from transformers import AutoModelForCausalLM
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
config = PeftConfig.from_pretrained("./model")
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, trust_remote_code=True)
model = PeftModel.from_pretrained(model, "./model")
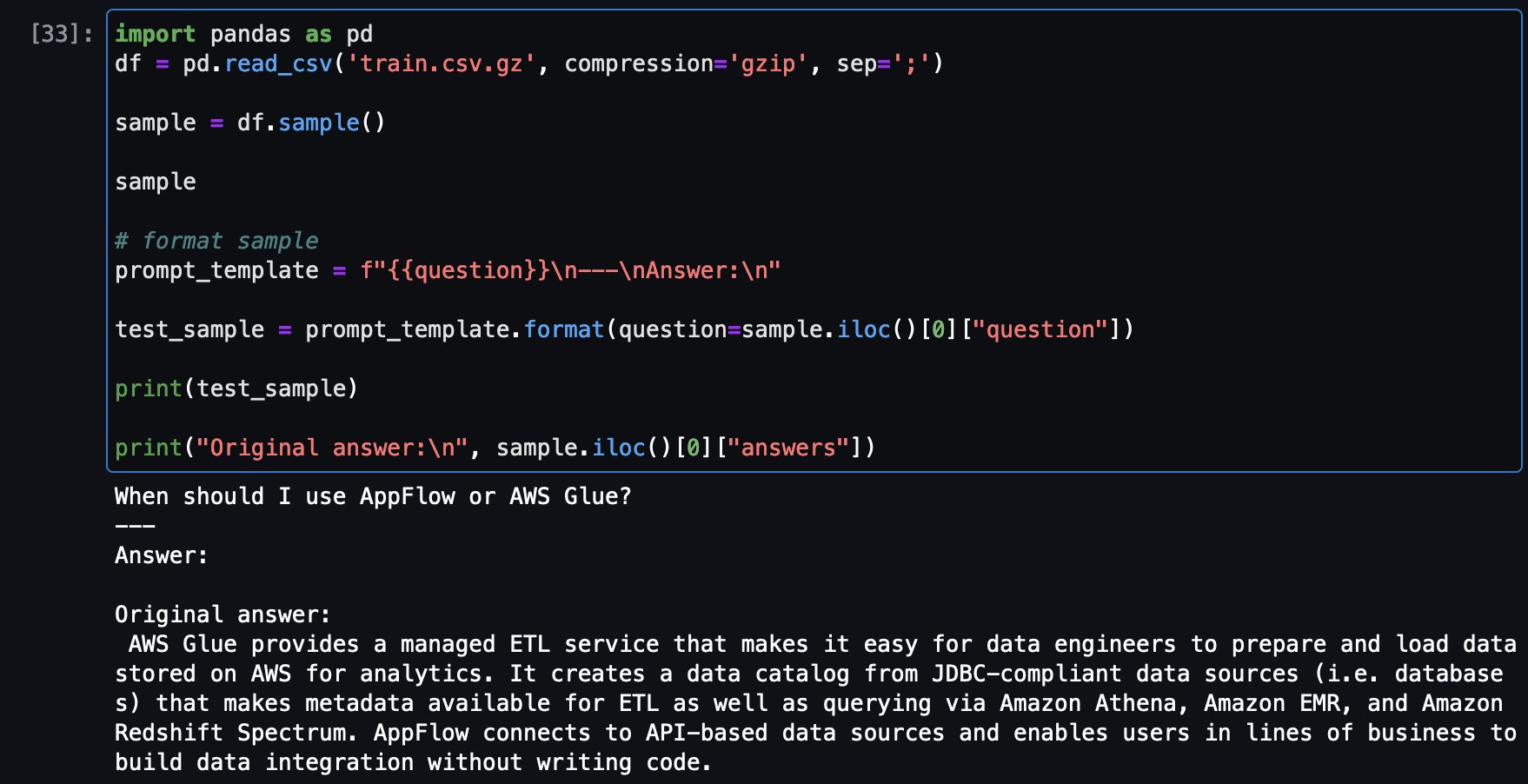
model.to(device)次に、トレーニングデータセットからサンプルの質問をロードして、元の回答を表示し、同じ質問をチューニングモデルに投げて回答を比較します。
トレーニングセットからのサンプル質問とオリジナルの回答です:
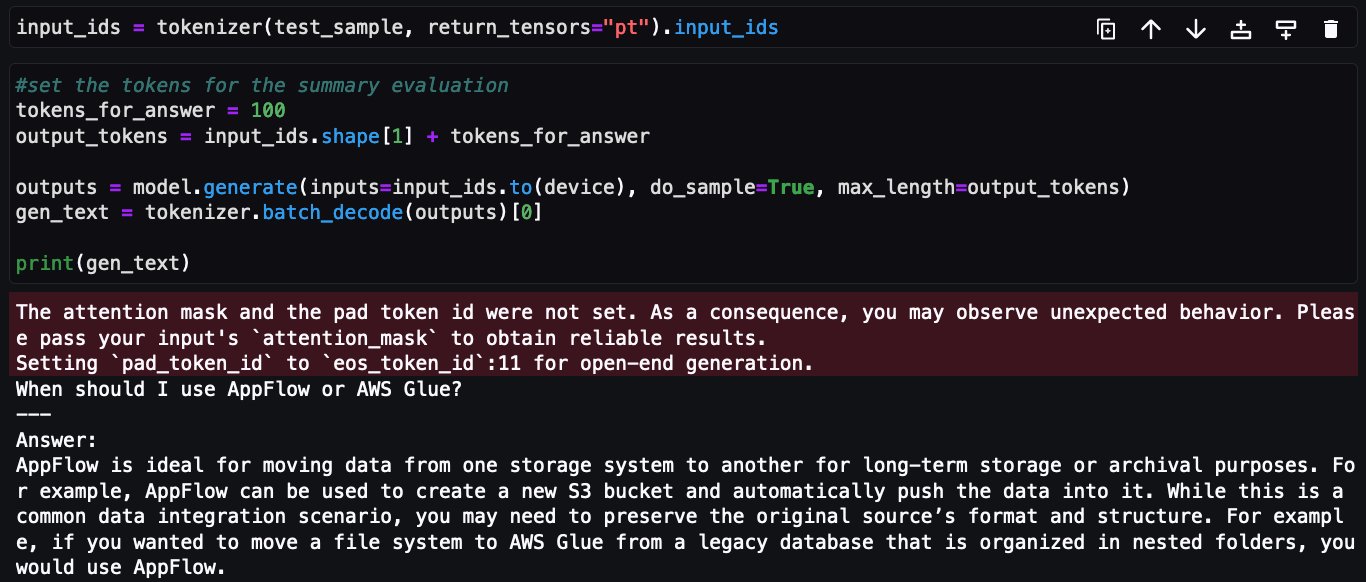
次に、チューニングされたFalcon-7Bモデルに対して同じ質問がされました:
これで、Amazon SageMaker Python SDKの@remoteデコレータを使用してAWSサービスのFAQデータセット上でFalcon-7Bの微調整実装が完了しました。
クリーンアップ
リソースをクリーンアップするには、以下の手順を完了してください:
-
追加の費用が発生しないように、Amazon SageMaker Studioインスタンスをシャットダウンします。
-
Hugging Faceのキャッシュディレクトリをクリアするために、Amazon Elastic File System(Amazon EFS)ディレクトリをクリーンアップしてください:
rm -R ~/.cache/huggingface/hub
結論
この記事では、@remoteデコレータの機能を使用してQLoRA、Hugging Face PEFT、bitsandbtyesを使用してFalcon-7Bモデルの微調整を効果的に行う方法を示しました。トレーニングノートブックに大きな変更を加えずに、Amazon SageMakerの機能を使用してリモートクラスタでトレーニングジョブを実行しました。
Falcon-7Bの微調整のためにこの記事の一部として表示されるすべてのコードは、GitHubリポジトリで入手できます。リポジトリには、Llama-13Bの微調整方法を示すノートブックも含まれています。
次のステップとして、@remoteデコレータの機能とPython SDK APIを確認し、選択した環境とIDEで使用してみることをお勧めします。迅速に始めるために、amazon-sagemaker-examplesリポジトリには追加の例もあります。以下の記事も参考にしてみてください:
- 最小のコード変更でAmazon SageMakerトレーニングジョブとしてローカルの機械学習コードを実行する
- Amazon SageMakerトレーニングワークロードの@remoteデコレータを使用してプライベートリポジトリにアクセスする
- QLoRAを使用してAmazon SageMaker Studioノートブック上でFalcon-40Bおよび他のLLMを対話的に微調整する
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Amazon QuickSightでワードクラウドとしてAmazon Comprehendの分析結果を可視化する」
- 「Hugging Faceを使用してAmazon SageMakerでのメール分類により、クライアントの成功管理を加速する」
- 「Amazon SageMakerは、個々のユーザーのためにAmazon SageMaker Studioのセットアップを簡素化します」
- 「ロボットに対するより柔らかいアプローチ」
- 「3Dプリントされた『生物性材料』が汚染された水を浄化することができる」
- 「AIプロジェクトが、アルゼンチンの軍事独裁政権下で行方不明になった子供たちの成人した顔を想像します」
- 「マイクロソフトに韻を踏む事件」






