「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
Amazon Redshiftのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
Amazon Redshiftは、毎日エクサバイトのデータを分析するために数万人の顧客によって使用される最も人気のあるクラウドデータウェアハウスです。多くの実践者は、Amazon SageMakerというフルマネージドの機械学習(ML)サービスを使用して、Redshiftデータセットを拡張し、コードまたはローコード/ノーコードの方法でオフラインでフィーチャを開発し、Amazon Redshiftからフィーチャデータを保存し、これを本番環境でスケールさせる必要があります。
この記事では、SageMakerでスケールを考慮したRedshiftソースデータの準備方法として、Amazon Redshiftからデータをロードし、フィーチャエンジニアリングを実行し、フィーチャをAmazon SageMaker Feature Storeに組み込む3つのオプションを紹介します。
- オプションA – AWS Glueを使用したAmazon SageMaker Studioのインタラクティブセッション(開発環境)とAWS Glueジョブ(本番環境)をSparkで使用する
- オプションB – Amazon SageMaker Processingジョブを使用してRedshiftデータセットの定義を行うか、SageMaker Feature Processingを使用してSageMaker Feature Storeで実行することで、SageMakerトレーニングジョブを実行する
- オプションC – Amazon SageMaker Data Wranglerをローコード/ノーコードの方法で使用する
AWS Glueユーザーであり、インタラクティブにプロセスを実行したい場合は、オプションAを検討してください。SageMakerとSparkコードの記述に精通している場合は、オプションBが適しているかもしれません。ローコード/ノーコードの方法でプロセスを実行したい場合は、オプションCに従ってください。
Amazon Redshiftは、AWSが設計したハードウェアとMLを使用して、データウェアハウス、運用データベース、データレイク上の構造化および半構造化データをSQLで分析し、どのスケールでも最適な価格性能を提供します。
SageMaker Studioは、MLのための最初の完全統合開発環境(IDE)です。データの準備、モデルの構築、トレーニング、展開など、すべてのML開発ステップを実行できる単一のWebベースのビジュアルインターフェースを提供します。
AWS Glueは、データ統合サービスであり、データの発見、準備、結合を分析、ML、アプリケーション開発のために簡単に行うことができます。AWS Glueでは、組み込みの変換を含むさまざまな機能を使用して、データをシームレスに収集、変換、クレンジング、準備し、データレイクやデータパイプラインにストレージすることができます。
ソリューションの概要
以下の図は、各オプションのソリューションアーキテクチャを示しています。

前提条件
この記事の例を続けるために、必要なAWSリソースを作成する必要があります。これを行うために、リソースを含むスタックを作成するためのAWS CloudFormationテンプレートを提供します。スタックを作成すると、AWSはアカウントにいくつかのリソースを作成します。
- SageMakerドメイン(関連するAmazon Elastic File System(Amazon EFS)ボリュームを含む)
- 承認済みユーザーのリストとさまざまなセキュリティ、アプリケーション、ポリシー、Amazon Virtual Private Cloud(Amazon VPC)の設定
- Redshiftクラスタ
- Redshiftシークレット
- Amazon Redshift用のAWS Glue接続
- 必要なリソース、実行ロール、ポリシーを設定するためのAWS Lambda関数
CloudFormationテンプレートを実行しているリージョンに既に2つのSageMaker Studioドメインがないことを確認してください。これは、各サポートされているリージョンで許可される最大のドメイン数です。
CloudFormationテンプレートのデプロイ
以下の手順を実行して、CloudFormationテンプレートをデプロイします。
- CloudFormationテンプレート「sm-redshift-demo-vpc-cfn-v1.yaml」をローカルに保存します。
- AWS CloudFormationコンソールで、「スタックの作成」を選択します。
- 「テンプレートの準備」で、「テンプレートは準備済み」を選択します。
- 「テンプレートのソース」で、「テンプレートファイルのアップロード」を選択します。
- 「ファイルの選択」を選択し、CloudFormationテンプレートがダウンロードされた場所に移動し、ファイルを選択します。
- 「Demo-Redshift」などのスタック名を入力します。
- 「スタックのオプションを構成」ページでは、すべてをデフォルトのままにして「次へ」を選択します。
- 「レビュー」ページで、「AWS CloudFormationがカスタム名のIAMリソースを作成する場合があることを認識します」というオプションを選択し、「スタックの作成」を選択します。
新しいCloudFormationスタックが作成され、名前がDemo-Redshiftになることを確認してください。スタックのステータスがCREATE_COMPLETEになるまで(約7分)待機してから次に進んでください。スタックのリソースタブに移動して、作成されたAWSリソースを確認できます。
SageMaker Studioの起動
SageMaker Studioドメインを起動するには、次の手順を完了してください:
- SageMakerコンソールで、ナビゲーションペインでドメインを選択します。
- CloudFormationスタックの一部として作成したドメイン(
SageMakerDemoDomain)を選択します。 - 起動とStudioを選択します。
このページは、SageMaker Studioに初めてアクセスするときに1〜2分かかる場合があります。その後、ホームタブにリダイレクトされます。
GitHubリポジトリのダウンロード
GitHubリポジトリをダウンロードするには、次の手順を完了してください:
- SageMakerノートブックで、ファイルメニューから新規とターミナルを選択します。
- ターミナルに、次のコマンドを入力します:
git clone https://github.com/aws-samples/amazon-sagemaker-featurestore-redshift-integration.gitSageMaker Studioのナビゲーションペインにamazon-sagemaker-featurestore-redshift-integrationフォルダが表示されます。
Sparkコネクタを使用してバッチインジェスチョンを設定する
バッチインジェスチョンを設定するには、次の手順を完了してください:
- SageMaker Studioで、
amazon-sagemaker-featurestore-redshift-integration内のノートブック1-uploadJar.ipynbを開きます。 - カーネルの選択を求められた場合は、イメージとしてData Science、カーネルとしてPython 3を選択し、選択を選択します。
- AWS Glueインタラクティブセッションノートブック(4a)を除く、以下のノートブックについては、同じイメージとカーネルを選択します。
- 各セルでShift+Enterを押してセルを実行します。
コードが実行されている間、角かっこの間にアスタリスク(*)が表示されます。コードの実行が終了すると、*は数値に置き換えられます。この操作は、他のすべてのノートブックに対しても有効です。
スキーマの設定とAmazon Redshiftへのデータのロード
次のステップは、Amazon Simple Storage Service(Amazon S3)からAmazon Redshiftにデータを設定してロードすることです。そのためには、ノートブック2-loadredshiftdata.ipynbを実行します。
SageMaker Feature Storeで特徴ストアを作成する
特徴ストアを作成するには、ノートブック3-createFeatureStore.ipynbを実行します。
特徴エンジニアリングを実行し、SageMaker Feature Storeに特徴をインジェストする
このセクションでは、特徴エンジニアリングを実行し、処理された特徴をSageMaker Feature Storeにインジェストするための3つのオプションの手順を説明します。
オプションA:SageMaker StudioとサーバーレスのAWS Glueインタラクティブセッションを使用する
オプションAの手順を完了するには、次の手順を実行してください:
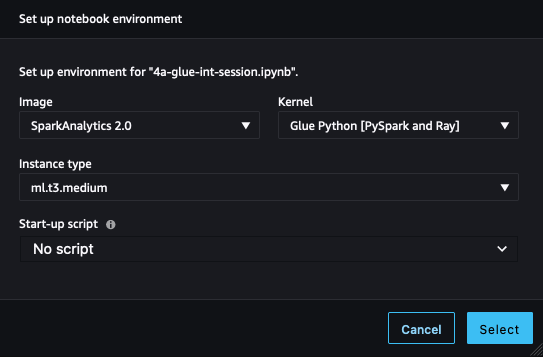
- SageMaker Studioで、ノートブック4a-glue-int-session.ipynbを開きます。
- カーネルの選択を求められた場合は、イメージとしてSparkAnalytics 2.0、カーネルとしてGlue Python [PySpark and Ray]を選択し、選択を選択します。
環境の準備には時間がかかる場合があります。
オプションB:SageMaker Processingジョブを使用してSparkを利用する
このオプションでは、SageMaker ProcessingジョブとSparkスクリプトを使用して、Amazon Redshiftから元のデータセットをロードし、特徴エンジニアリングを行い、データをSageMaker Feature Storeに取り込みます。これを行うには、SageMaker Studio環境でノートブック4b-processing-rs-to-fs.ipynbを開いてください。
ここでは、RedshiftDatasetDefinitionを使用してRedshiftクラスタからデータセットを取得します。RedshiftDatasetDefinitionは、識別子、データベース、テーブル、クエリ文字列など、Redshift接続に関連するパラメータを簡単に設定するための入力の一種です。接続を常時維持することなく、RedshiftDatasetDefinitionを使用して簡単にRedshiftへの接続を確立することができます。また、SageMaker Feature Store Sparkコネクタライブラリも使用して、処理ジョブでSpark DataFrameからSageMaker Feature Storeに接続します。このコネクタには、フィーチャグループのオンラインおよびオフラインストアにデータを簡単に取り込む機能が含まれています。また、このコネクタには、フィーチャグループの作成をサポートするためのフィーチャ定義の自動読み込み機能も含まれています。最も重要なことは、このソリューションがAmazon RedshiftからSageMakerに至るまでのエンドツーエンドのデータパイプラインを実装するためのネイティブなSparkの方法を提供することです。Sparkコンテキストで任意の特徴エンジニアリングを実行し、最終的な特徴をたった1つのSparkプロジェクトでSageMaker Feature Storeに取り込むことができます。
SageMaker Feature Store Sparkコネクタを使用するには、sagemaker-feature-store-pysparkがインストールされた事前に構築されたSageMaker Sparkコンテナを拡張します。Sparkスクリプトでは、システムの実行可能コマンドを使用してpip installを実行し、このライブラリをローカル環境にインストールし、JARファイルの依存関係のローカルパスを取得します。処理ジョブAPIでは、このパスを処理ジョブが作成するSparkクラスタのノードのsubmit_jarsパラメータに指定します。
処理ジョブのSparkスクリプトでは、まずAmazon S3から元のデータセットファイルを読み込みます。このAmazon S3は、Amazon Redshiftからアンロードされたデータセットを一時的に保管するVoAGIとして機能します。次に、Sparkの方法で特徴エンジニアリングを実行し、feature_store_pysparkを使用してオフラインフィーチャストアにデータを取り込みます。
処理ジョブでは、redshift_dataset_definitionを持つProcessingInputを提供します。ここでは、Redshift接続に関連する設定を含む構造を作成します。SQLによってデータセットをフィルタリングし、Amazon S3にアンロードするためにquery_stringを使用することができます。次のコードを参照してください:
rdd_input = ProcessingInput(
input_name="redshift_dataset_definition",
app_managed=True,
dataset_definition=DatasetDefinition(
local_path="/opt/ml/processing/input/rdd",
data_distribution_type="FullyReplicated",
input_mode="File",
redshift_dataset_definition=RedshiftDatasetDefinition(
cluster_id=_cluster_id,
database=_dbname,
db_user=_username,
query_string=_query_string,
cluster_role_arn=_redshift_role_arn,
output_s3_uri=_s3_rdd_output,
output_format="PARQUET"
),
),
)USER、PLACE、およびRATINGの各データセットを含む処理ジョブごとに6〜7分間待つ必要があります。
SageMaker Processingジョブの詳細については、「データの処理」を参照してください。
Amazon Redshiftからのフィーチャ処理のためのSageMakerネイティブソリューションとして、SageMaker Feature Storeのフィーチャ処理を使用することもできます。これは、計算環境の提供やデータのロードと取り込みのためのSageMakerパイプラインの作成と維持など、基礎となるインフラストラクチャに関するものです。Amazon RedshiftのソースとSageMaker Feature Storeのシンクを含むフィーチャプロセッサの定義に集中することができます。スケジューリングやジョブ管理などの本番のワークロードは、SageMakerによって管理されます。フィーチャプロセッサパイプラインはSageMakerパイプラインなので、標準のモニタリングメカニズムと統合が利用できます。
オプションC:SageMaker Data Wranglerを使用する
SageMaker Data Wranglerを使用すると、Amazon Redshiftを含むさまざまなデータソースからデータをインポートし、データを準備、変換、特徴化するための低コード/ノーコードの方法が提供されます。データの準備が完了したら、SageMaker Data Wranglerを使用してフィーチャをSageMaker Feature Storeにエクスポートすることができます。
SageMaker Data WranglerがAmazon Redshiftに接続するためのいくつかのAWS Identity and Access Management(IAM)設定があります。まず、Amazon S3アクセスポリシーを含むIAMロール(例:redshift-s3-dw-connect)を作成してください。このポストでは、IAMロールにAmazonS3FullAccessポリシーをアタッチしました。指定されたS3バケットへのアクセス制限がある場合は、Amazon S3アクセスポリシーで定義することができます。IAMロールを前もって作成したRedshiftクラスタにアタッチしてください。次に、SageMakerがAmazon Redshiftにアクセスするためにクラスタの認証情報を取得するためのポリシーを作成し、SageMakerのIAMロールにポリシーをアタッチしてください。ポリシーは以下のコードのようになります:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "redshift:getclustercredentials",
"Effect": "Allow",
"Resource": [
"*"
]
}
]
}この設定後、SageMaker Data Wranglerを使用してAmazon Redshiftにクエリを実行し、結果をS3バケットに出力することができます。Redshiftクラスタに接続し、Amazon RedshiftからSageMaker Data Wranglerにデータをクエリおよびインポートする手順については、「Amazon Redshiftからデータをインポートする」を参照してください。
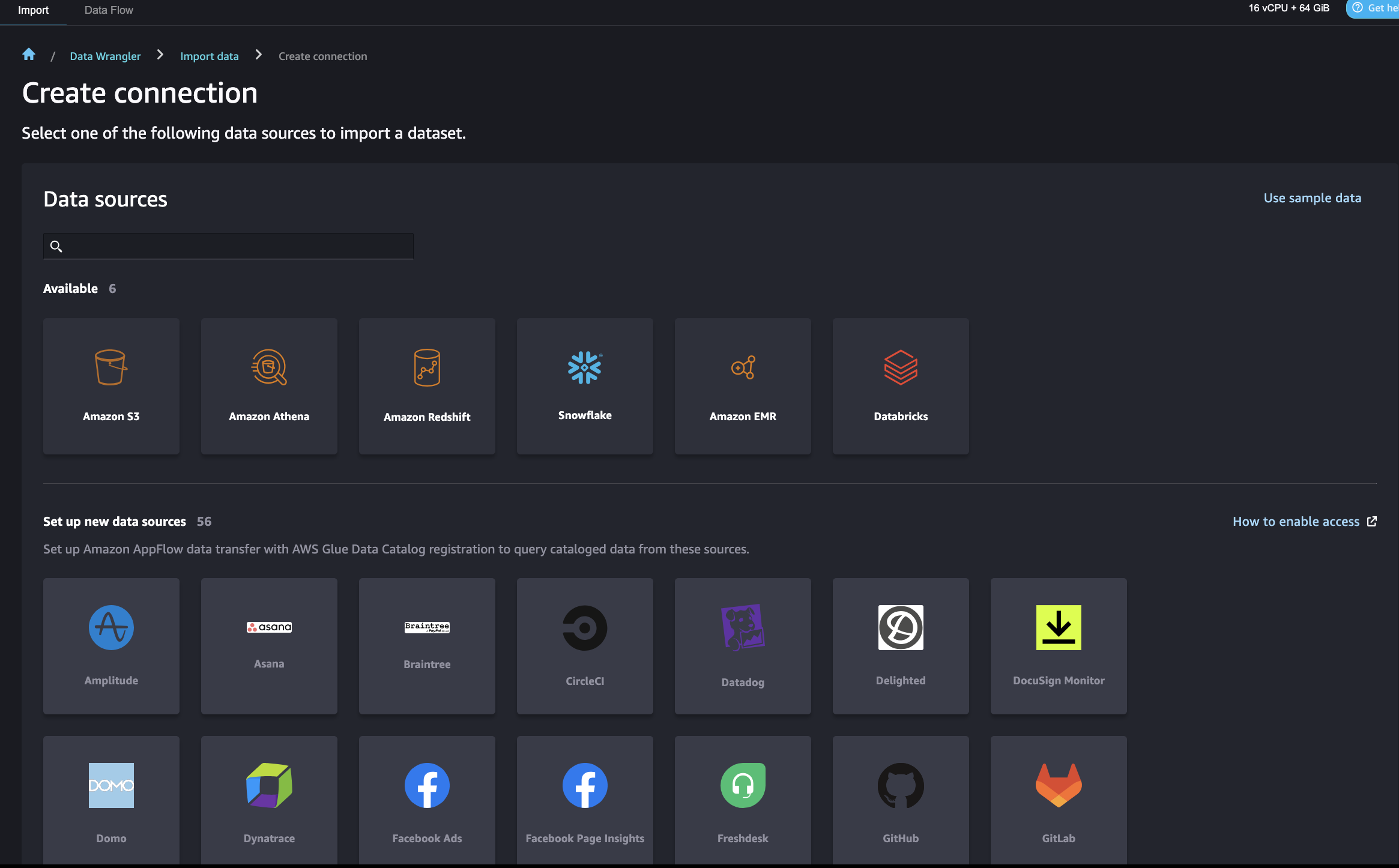
SageMaker Data Wranglerでは、重複行の削除、欠損データの補完、ワンホットエンコーディング、時系列データの処理など、一般的なユースケースに対応した300以上の事前構築データ変換が用意されています。また、pandasやPySparkでカスタム変換を追加することもできます。この例では、データに対してカラムの削除、データ型の強制、序数エンコーディングなどの変換を適用しました。
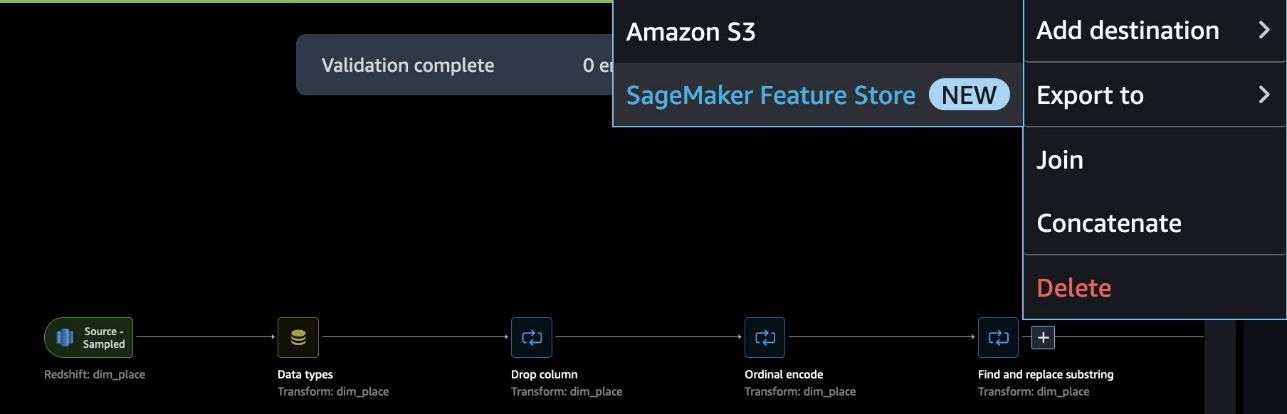
データフローが完了したら、SageMaker Feature Storeにエクスポートすることができます。この時点で、フィーチャーグループを作成する必要があります。フィーチャーグループに名前を付け、オンラインおよびオフラインストレージの両方を選択し、オフラインストアに使用するS3バケットの名前を指定し、SageMaker Feature Storeへのアクセス権限を持つロールを指定します。最後に、SageMaker Data Wranglerフローを実行してRedshiftデータソースからフィーチャーグループにフィーチャーを取り込むSageMaker Processingジョブを作成できます。

以下は、PLACEフィーチャーエンジニアリングシナリオにおけるエンドツーエンドのデータフローの例です。
モデルのトレーニングと予測にSageMaker Feature Storeを使用する
モデルのトレーニングと予測にSageMaker Feature Storeを使用するには、ノートブック5-classification-using-feature-groups.ipynbを開きます。
Redshiftデータがフィーチャーに変換され、SageMaker Feature Storeに取り込まれた後、データサイエンティストチームが独立した多くのMLモデルとユースケースに責任を持つデータサイエンティスト向けに、フィーチャーは検索と発見が可能になります。これらのチームは、フィーチャーを再構築または再実行することなくモデリングに使用することができます。フィーチャーグループは独立して管理およびスケーリングされ、上流データソースに関係なく再利用および結合することができます。
次のステップは、1つまたは複数のフィーチャーグループから選択されたフィーチャーを使用してMLモデルを構築することです。どのフィーチャーグループをモデルに使用するかは、あなたが決定します。フィーチャーグループからMLデータセットを作成するためには、SageMaker Python SDKを利用した2つのオプションがあります:
- SageMaker Feature Store DatasetBuilder APIを使用する – SageMaker Feature Storeの
DatasetBuilderAPIを使用すると、データサイエンティストはオフラインストアの1つまたは複数のフィーチャーグループからMLデータセットを作成することができます。APIを使用して、単一のフィーチャーグループまたは複数のフィーチャーグループからデータセットを作成し、CSVファイルまたはpandas DataFrameとして出力することができます。以下の例コードを参照してください:
from sagemaker.feature_store.dataset_builder import DatasetBuilder
fact_rating_dataset = DatasetBuilder(
sagemaker_session = sagemaker_session,
base = fact_rating_feature_group,
output_path = f"s3://{s3_bucket_name}/{prefix}",
record_identifier_feature_name = 'ratingid',
event_time_identifier_feature_name = 'timestamp',
).to_dataframe()[0]- FeatureGroup APIのathena_query関数を使用してSQLクエリを実行する – もう1つのオプションは、FeatureGroup APIのAWS Glue Data Catalogを自動ビルドすることです。FeatureGroup APIには
Athena_query関数が含まれており、AthenaQueryインスタンスを作成してユーザー定義のSQLクエリ文字列を実行します。その後、Athenaクエリを実行し、クエリ結果をpandas DataFrameに整理します。このオプションでは、フィーチャーグループから情報を抽出するためにより複雑なSQLクエリを指定することができます。以下の例コードを参照してください:
dim_user_query = dim_user_feature_group.athena_query()
dim_user_table = dim_user_query.table_name
dim_user_query_string = (
'SELECT * FROM "'
+ dim_user_table
+ '"'
)
dim_user_query.run(
query_string = dim_user_query_string,
output_location = f"s3://{s3_bucket_name}/{prefix}",
)
dim_user_query.wait()
dim_user_dataset = dim_user_query.as_dataframe()次に、異なるフィーチャーグループからクエリされたデータをモデルのトレーニングとテストのための最終データセットにマージします。このポストでは、モデル推論にはバッチ変換を使用します。バッチ変換は、Amazon S3の大量のデータに対してモデル推論を行い、その推論結果をAmazon S3に保存することができます。モデルのトレーニングと推論の詳細については、ノートブック「5-classification-using-feature-groups.ipynb」を参照してください。
Amazon Redshiftで予測結果を結合クエリする
最後に、予測結果をクエリし、Amazon Redshiftの元のユーザープロファイルと結合します。これには、Amazon Redshift Spectrumを使用して、Amazon S3のバッチ予測結果を元のRedshiftデータと結合します。詳細については、ノートブック「run 6-read-results-in-redshift.ipynb」を参照してください。
クリーンアップ
このセクションでは、このポストの一部として作成されたリソースをクリーンアップする手順を提供します。これにより、継続的な料金が発生するのを防ぐことができます。
SageMakerアプリをシャットダウンする
以下の手順を完了して、リソースをシャットダウンします。
- SageMaker Studioで、ファイルメニューからシャットダウンを選択します。
- シャットダウンの確認ダイアログで、全てシャットダウンを選択して続行します。
- 「サーバーが停止しました」というメッセージが表示されたら、このタブを閉じることができます。
アプリを削除する
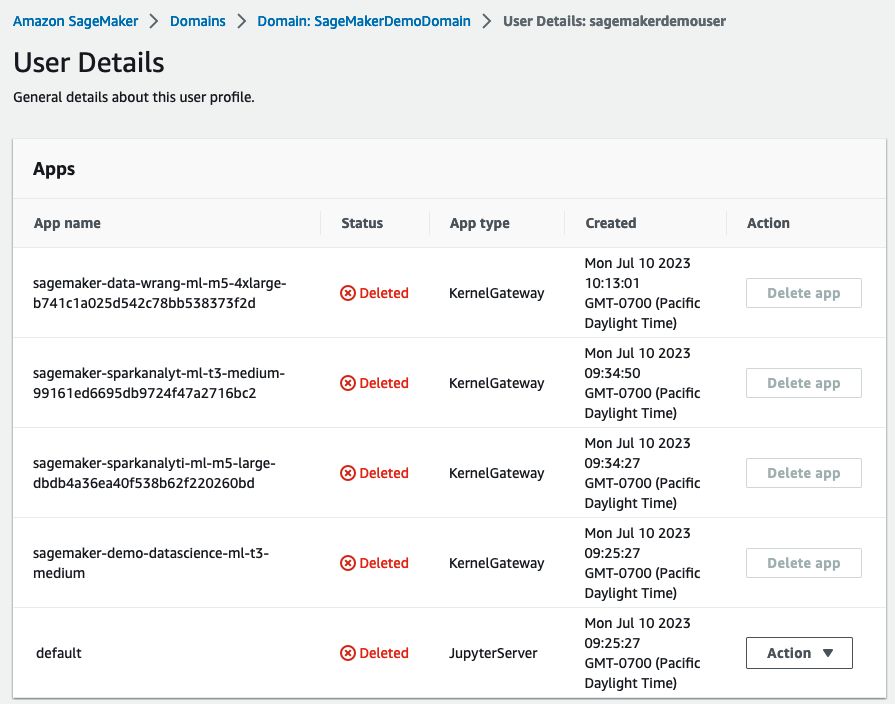
以下の手順を完了して、アプリを削除します。
- SageMakerコンソールで、ナビゲーションペインでドメインを選択します。
- ドメインページで、
SageMakerDemoDomainを選択します。 - ドメインの詳細ページで、ユーザープロファイルの下で、ユーザー
sagemakerdemouserを選択します。 - アプリセクションで、アクティブなアプリに対してアプリを削除を選択します。
- すべてのアプリのステータス列が削除済みであることを確認します。
SageMakerドメインに関連付けられたEFSストレージボリュームを削除する
SageMakerコンソールでEFSボリュームを検索し、削除します。手順については、「SageMaker StudioでAmazon EFSストレージボリュームを管理する」を参照してください。
SageMakerのデフォルトのS3バケットを削除する
SageMakerのデフォルトのS3バケット(sagemaker-<region-code>-<acct-id>)を削除します。そのリージョンでSageMakerを使用していない場合は、削除してください。
CloudFormationスタックを削除する
AWSアカウント内のCloudFormationスタックを削除して、関連するすべてのリソースをクリーンアップします。
結論
このポストでは、RedshiftデータウェアハウスからSageMakerへのデータとMLフローを終端までデモンストレーションしました。AWSのネイティブな統合機能を使用して、データのジャーニーをシームレスに進めることができます。モダンなデータウェアハウスからMLフィーチャーを構築するためのさらなるベストプラクティスについては、AWSブログをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「GPT4のデータなしでコードLLMのインストラクションチューニングを行う方法は? OctoPackに会いましょう:インストラクションチューニングコード大規模言語モデルのためのAIモデルのセット」
- 「データ主導的なアプローチを取るべきか?時にはそうである」
- 「Azure Data Factory(ADF)とは何ですか?特徴とアプリケーション」
- 「pandasのCopy-on-Writeモードの深い探求-パートII」
- 「データサイエンス(2023年)で学ぶべきこと」
- データセンターは、電力管理ソフトウェアの欠陥により危険にさらされています
- AIとコンテンツの創造:デジタルイノベーションの新たな地平
