ユーザーのコンテキストに基づいてアイテムを推奨し、動的にフィルタリングするAmazon Personalize
Amazon Personalizeは、ユーザーのコンテキストに基づいてアイテムを推奨し、動的にフィルタリングする
組織は、ユーザーにカスタマイズされた関連コンテンツを提供するために、知的な推薦ソリューションの開発に時間と労力を投資し続けています。その目標は多岐にわたることがあります。ユーザーエクスペリエンスの変革、意味のある相互作用の生成、コンテンツの消費促進などです。これらのソリューションの一部は、過去の相互作用パターン、ユーザーの人口統計属性、製品の類似性、グループの行動などに基づいて構築された一般的な機械学習(ML)モデルを使用しています。これらの属性の他にも、相互作用時のコンテキスト(天気、場所など)は、ユーザーがコンテンツをナビゲートする際の意思決定に影響を与えることがあります。
この記事では、ユーザーの現在のデバイスタイプをコンテキストとして使用し、Amazon Personalizeをベースにした推奨の効果を高める方法を紹介します。さらに、そのようなコンテキストを使用して、推奨を動的にフィルタリングする方法も示します。この記事はビデオ・オン・デマンド(VOD)の使用例にAmazon Personalizeを使用する方法を示していますが、Amazon Personalizeは複数の業界で使用できることに注意してください。
Amazon Personalizeとは何ですか?
Amazon Personalizeは、開発者がリアルタイムの個別化された推奨に使用されるAmazon.comと同じタイプのML技術によって動作するアプリケーションを構築できるようにするものです。Amazon Personalizeは、特定の製品の推奨、パーソナライズされた製品の再順位付け、カスタマイズされた直接マーケティングなど、さまざまな個別化体験を提供することができます。さらに、完全に管理されたAIサービスとして、Amazon PersonalizeはMLによる顧客のデジタルトランスフォーメーションを加速し、個別化された推奨を既存のウェブサイト、アプリケーション、メールマーケティングシステムなどに簡単に統合できるようにします。
なぜコンテキストが重要なのですか?
場所、時刻、デバイスの種類、天候などのユーザーのコンテキストメタデータを使用することで、既存のユーザーに個別化された体験を提供し、新しいまたは識別されていないユーザーのコールドスタートフェーズを改善することができます。コールドスタートフェーズとは、そのユーザーに関する履歴情報が不足しているため、レコメンデーションエンジンが非個別化された推奨を提供する期間のことを指します。ニュースや天気などでアイテムをフィルタリングやプロモーションする他の要件がある場合、ユーザーの現在のコンテキスト(季節や時刻など)を追加することで、推奨の包括と除外によって正確性を向上させることができます。
- 海洋ナビゲーションのためのロボットプラットフォームを構築するために、カイアシ類が泳ぐ方法を模倣する
- 紙のような、バッテリー不要のAI対応センサーによる包括的な傷のモニタリング
- Dropboxが、ゲームチェンジングなAIパワードツールを発表:生産性とコラボレーションの新時代
例として、VODプラットフォームがユーザーに番組、ドキュメンタリー、映画を推奨する場合を考えてみましょう。行動分析に基づくと、VODユーザーはモバイルデバイスでシットコムなどの短いコンテンツを消費し、テレビやデスクトップで映画などの長いコンテンツを消費する傾向があります。
ソリューションの概要
ユーザーのデバイスタイプを考慮する例を展開することで、Amazon Personalizeがユーザーのデバイスが好みのコンテンツに与える影響を自動的に学習できるようにする方法を示します。
次の図に示すアーキテクチャパターンに従って、コンテキストをAmazon Personalizeに自動的に渡す方法を説明します。コンテキストの自動生成は、Amazon CloudFrontヘッダーを使用して達成されます。これらのヘッダーは、Amazon API GatewayのREST APIなどのリクエストに含まれ、AWS Lambda関数を呼び出して推奨を取得します。必要なリソースを作成するための完全なコード例は、弊社のGitHubリポジトリで入手できます。AWS CloudFormationテンプレートも提供しています。
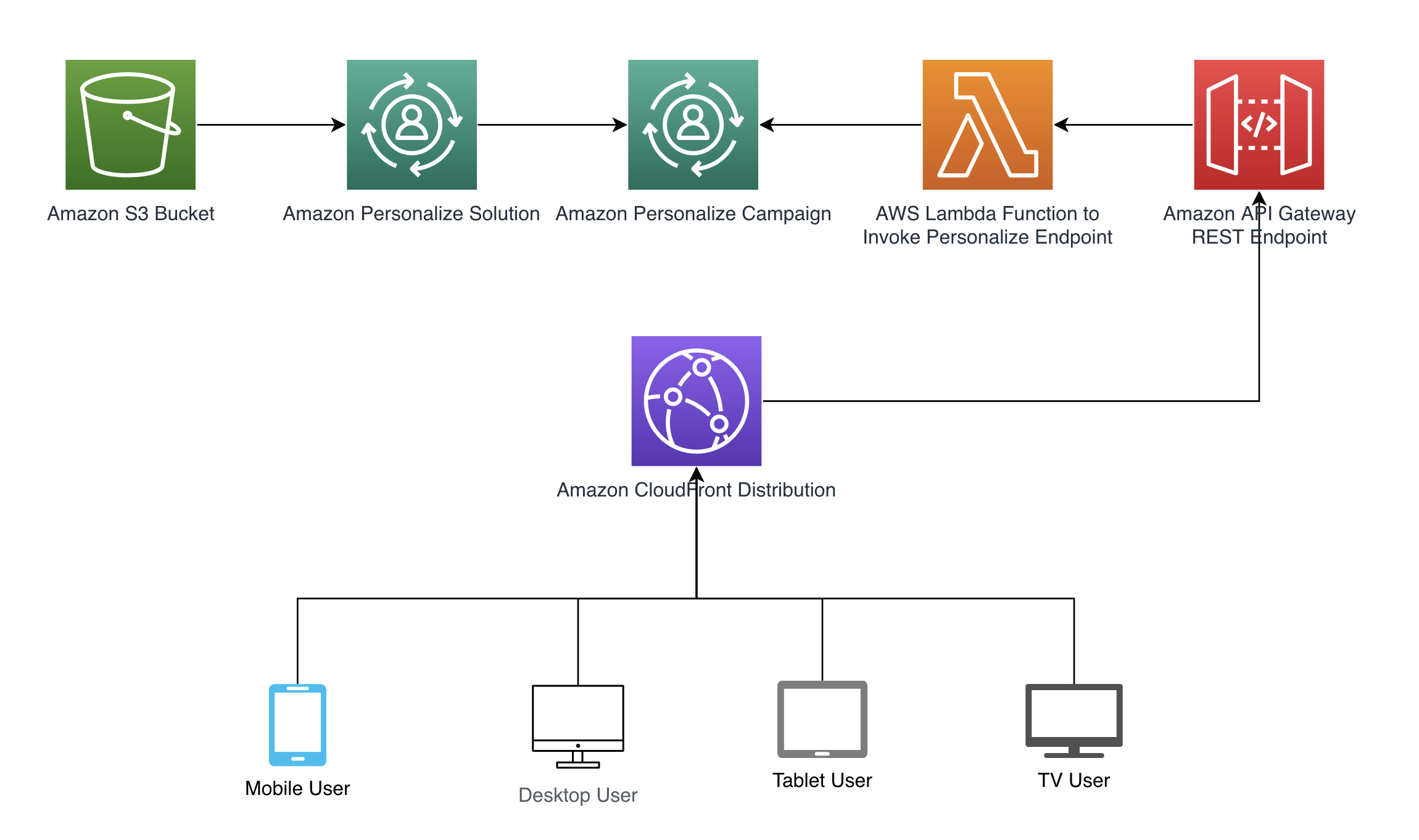
以下のセクションでは、サンプルアーキテクチャパターンの各ステップの設定方法について説明します。
レシピを選択する
レシピは、特定の使用ケースに対して準備されたAmazon Personalizeのアルゴリズムです。Amazon Personalizeは、モデルのトレーニング用に一般的な使用ケースに基づいたレシピを提供します。私たちの使用ケースでは、User-Personalizationレシピを使用してシンプルなAmazon Personalizeカスタムレコメンダーを構築します。このレシピは、相互作用データセットに基づいて、ユーザーがどのアイテムと相互作用するかを予測します。また、このレシピでは、アイテムとユーザーのデータセットも推奨に影響を与える場合に使用されます。このレシピの動作について詳しくは、User-Personalizationレシピを参照してください。
データセットの作成とインポート
コンテキストを活用するには、推奨エンジンがモデルのトレーニング時にコンテキストを特徴として使用できるように、相互作用にコンテキスト値を指定する必要があります。また、推論時にはユーザーの現在のコンテキストを提供する必要があります。相互作用スキーマ(以下のコードを参照)は、履歴およびリアルタイムのユーザー間アイテム相互作用データの構造を定義します。このデータセットには、Amazon Personalizeによって必要とされるUSER_ID、ITEM_ID、TIMESTAMPのフィールドが必要です。DEVICE_TYPEは、この例で追加しているカスタムのカテゴリフィールドです。これにより、モデルのトレーニングにユーザーの現在のコンテキストをキャプチャして含めることができます。Amazon Personalizeは、この相互作用データセットを使用してモデルをトレーニングし、推奨キャンペーンを作成します。
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "DEVICE_TYPE",
"type": "string",
"categorical": true
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}同様に、商品とビデオカタログデータの構造を定義するアイテムスキーマ(以下のコードを参照)もあります。このデータセットでは、Amazon PersonalizeによってITEM_IDが必要です。CREATION_TIMESTAMPは予約済みの列名ですが、必須ではありません。GENREとALLOWED_COUNTRIESは、この例ではビデオのジャンルとビデオ再生が許可されている国をキャプチャするために追加しているカスタムフィールドです。Amazon Personalizeは、このアイテムデータセットを使用してモデルをトレーニングし、レコメンデーションキャンペーンを作成します。
{
"type": "record",
"name": "Items",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "GENRE",
"type": "string",
"categorical": true
},
{
"name": "ALLOWED_COUNTRIES",
"type": "string",
"categorical": true
},
{
"name": "CREATION_TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}私たちの文脈では、履歴データとは、VODプラットフォーム上のビデオとアイテムへのエンドユーザーのインタラクション履歴を指します。このデータは通常、アプリケーションのデータベースに収集され、保存されます。
デモの目的で、PythonのFakerライブラリを使用して、異なるアイテム、ユーザー、およびデバイスタイプによる3か月間の期間にわたるインタラクションデータセットを模倣するテストデータを生成します。スキーマと入力のインタラクションファイルの場所が定義された後、次のステップはデータセットグループを作成し、データセットグループにインタラクションデータセットを含め、最後にトレーニングデータをデータセットにインポートすることです。以下のコードスニペットで示します:
create_dataset_group_response = personalize.create_dataset_group(
name = "personalize-auto-context-demo-dataset-group"
)
create_interactions_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-interactions-dataset",
datasetType = 'INTERACTIONS',
datasetGroupArn = interactions_dataset_group_arn,
schemaArn = interactions_schema_arn
)
create_interactions_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-dataset-import",
datasetArn = interactions_dataset_arn,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, interactions_filename)
},
roleArn = role_arn
)
create_items_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-items-dataset",
datasetType = 'ITEMS',
datasetGroupArn = items_dataset_group_arn,
schemaArn = items_schema_arn
)
create_items_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-items-dataset-import",
datasetArn = items_dataset_arn,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, items_filename)
},
roleArn = role_arn
)履歴データを収集してモデルをトレーニングする
このステップでは、選択したレシピを定義し、以前に定義したデータセットグループを参照してソリューションとソリューションバージョンを作成します。カスタムソリューションを作成する場合、レシピを指定し、トレーニングパラメータを設定します。ソリューションのソリューションバージョンを作成すると、Amazon Personalizeは、レシピとトレーニング構成に基づいてソリューションバージョンをバックアップするモデルをトレーニングします。以下のコードを参照してください:
recipe_arn = "arn:aws:personalize:::recipe/aws-user-personalization"
create_solution_response = personalize.create_solution(
name = "personalize-auto-context-demo-solution",
datasetGroupArn = dataset_group_arn,
recipeArn = recipe_arn
)
create_solution_version_response = personalize.create_solution_version(
solutionArn = solution_arn
)キャンペーンエンドポイントの作成
モデルのトレーニングが完了した後、キャンペーンに展開します。キャンペーンは、トレーニング済みモデルのための自動スケーリングエンドポイントを作成・管理し、GetRecommendations APIを使用してパーソナライズされた推薦を取得するために使用します。後のステップでは、このキャンペーンエンドポイントを使用してデバイスタイプをコンテキストとしてパラメーターとして自動的に渡し、パーソナライズされた推薦を受け取ります。以下のコードを参照してください:
create_campaign_response = personalize.create_campaign(
name = "personalize-auto-context-demo-campaign",
solutionVersionArn = solution_version_arn
)動的フィルターの作成
作成したキャンペーンからの推薦を取得する際、カスタムの基準に基づいて結果をフィルタリングすることができます。この例では、ユーザーの現在の国で再生が許可されている動画のみを推薦するためのフィルターを作成します。国の情報は、CloudFrontのHTTPヘッダーから動的に渡されます。
create_filter_response = personalize.create_filter(
name = 'personalize-auto-context-demo-country-filter',
datasetGroupArn = dataset_group_arn,
filterExpression = 'INCLUDE ItemID WHERE Items.ALLOWED_COUNTRIES IN ($CONTEXT_COUNTRY)'
)Lambda関数の作成
アーキテクチャの次のステップは、CloudFrontディストリビューションからのAPIリクエストを処理し、Amazon Personalizeキャンペーンエンドポイントを呼び出して応答するためのLambda関数を作成することです。このLambda関数では、以下のCloudFrontリクエストのHTTPヘッダーとクエリストリングパラメーターを分析して、それぞれユーザーのデバイスタイプとユーザーIDを判定するロジックを定義します:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
この関数のコードは、CloudFormationテンプレートを介してデプロイされます。
REST APIの作成
Lambda関数とAmazon PersonalizeキャンペーンエンドポイントをCloudFrontディストリビューションからアクセス可能にするために、Lambdaプロキシとして設定されたREST APIエンドポイントを作成します。API Gatewayは、HTTPリクエストをLambda関数にルーティングするためのツールを提供しています。Lambdaプロキシ統合機能により、CloudFrontは単一のLambda関数を呼び出してAmazon Personalizeキャンペーンエンドポイントへのリクエストを抽象化することができます。この関数のコードは、CloudFormationテンプレートを介してデプロイされます。
CloudFrontディストリビューションの作成
CloudFrontディストリビューションを作成する際、これはデモセットアップですので、カスタムキャッシュポリシーを使用してキャッシュを無効にし、リクエストが常にオリジンに送信されるようにします。さらに、オリジンリクエストで必要なHTTPヘッダーとクエリストリングパラメーターを指定するオリジンリクエストポリシーを使用します。この関数のコードは、CloudFormationテンプレートを介してデプロイされます。
推薦のテスト
CloudFrontディストリビューションのURLに異なるデバイス(デスクトップ、タブレット、携帯電話など)からアクセスすると、デバイスに最も関連性のあるパーソナライズされたビデオ推薦が表示されます。また、新規ユーザーが表示された場合、ユーザーのデバイスに合わせた推薦が表示されます。次のサンプル出力では、ビデオの名前はジャンルと再生時間を表現するために使用されています。
次のコードでは、過去の相互作用に基づいてコメディが好きな既知のユーザーが、電話デバイスからアクセスした場合に短いシットコムが表示されます:
ユーザーのための推薦: 460
ITEM_ID ジャンル 許可された国
380 コメディ RU|GR|LT|NO|SZ|VN
540 シットコム US|PK|NI|JM|IN|DK
860 コメディ RU|GR|LT|NO|SZ|VN
600 コメディ US|PK|NI|JM|IN|DK
580 コメディ US|FI|CN|ES|HK|AE
900 サティア US|PK|NI|JM|IN|DK
720 シットコム US|PK|NI|JM|IN|DK次の既知のユーザーは、過去の相互作用に基づいてスマートTVデバイスからアクセスした場合に映画が表示されます:
ユーザーのための推薦: 460
ITEM_ID ジャンル 許可された国
780 ロマンス US|PK|NI|JM|IN|DK
100 ホラー US|FI|CN|ES|HK|AE
400 アクション US|FI|CN|ES|HK|AE
660 ホラー US|PK|NI|JM|IN|DK
720 ホラー US|PK|NI|JM|IN|DK
820 ミステリー US|FI|CN|ES|HK|AE
520 ミステリー US|FI|CN|ES|HK|AEスマートフォンからアクセスしている未知のユーザーには、短くて人気のある番組が表示されます:
ユーザーへのおすすめ: 666
ITEM_ID GENRE ALLOWED_COUNTRIES
940 サティア US|FI|CN|ES|HK|AE
760 サティア US|FI|CN|ES|HK|AE
160 シットコム US|FI|CN|ES|HK|AE
880 コメディ US|FI|CN|ES|HK|AE
360 サティア US|PK|NI|JM|IN|DK
840 サティア US|PK|NI|JM|IN|DK
420 サティア US|PK|NI|JM|IN|DK デスクトップからアクセスしている未知のユーザーには、トップのSF映画やドキュメンタリーが表示されます:
ユーザーへのおすすめ: 666
ITEM_ID GENRE ALLOWED_COUNTRIES
120 SF映画 US|PK|NI|JM|IN|DK
160 SF映画 US|FI|CN|ES|HK|AE
680 SF映画 RU|GR|LT|NO|SZ|VN
640 SF映画 US|FI|CN|ES|HK|AE
700 ドキュメンタリー US|FI|CN|ES|HK|AE
760 SF映画 US|FI|CN|ES|HK|AE
360 ドキュメンタリー US|PK|NI|JM|IN|DK スマートフォンからアクセスしている既知のユーザーは、場所(米国)に基づいてフィルタリングされたおすすめを返します:
ユーザーへのおすすめ: 460
ITEM_ID GENRE ALLOWED_COUNTRIES
300 シットコム US|PK|NI|JM|IN|DK
480 サティア US|PK|NI|JM|IN|DK
240 コメディ US|PK|NI|JM|IN|DK
900 シットコム US|PK|NI|JM|IN|DK
880 コメディ US|FI|CN|ES|HK|AE
220 シットコム US|FI|CN|ES|HK|AE
940 シットコム US|FI|CN|ES|HK|AE 結論
この投稿では、ユーザーのデバイスタイプをコンテキストデータとして使用して推奨事項をより関連性のあるものにする方法について説明しました。Amazon Personalizeモデルを訓練するためにコンテキストメタデータを使用することで、プロファイルデータだけでなく、ブラウジングデバイスプラットフォームからも、新しいユーザーや既存のユーザーに関連性のある製品をおすすめすることができます。さらに、場所(国、都市、地域、郵便番号)や時間(曜日、週末、平日、季節)などのコンテキストは、ユーザーに関連性のあるおすすめをする機会を提供します。GitHubリポジトリで提供されるCloudFormationテンプレートを使用して、Amazon SageMaker Studio にノートブックをクローンすることで、完全なコード例を実行することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





