Amazon CloudWatchで、ポッドベースのGPUメトリクスを有効にします
Amazon CloudWatchで、ポッドベースのGPUメトリクスを有効化します
2022年2月、Amazon Web ServicesはAmazon CloudWatchでのNVIDIA GPUメトリクスのサポートを追加し、Amazon CloudWatchエージェントからAmazon CloudWatchにメトリクスをプッシュしてコードの最適なGPU利用状況を監視することが可能になりました。それ以来、この機能はDeep Learning AMIやAWS ParallelCluster AMIなど、多くの管理型Amazon Machine Images(AMI)に統合されています。GPU利用状況のインスタンスレベルのメトリクスを取得するには、PackerまたはAmazon ImageBuilderを使用して独自のカスタムAMIをブートストラップし、AWS Batch、Amazon Elastic Container Service(Amazon ECS)、Amazon Elastic Kubernetes Service(Amazon EKS)などのさまざまな管理サービスオファリングで使用することができます。ただし、コンテナベースのサービスオファリングやワークロードの場合、コンテナ、ポッド、またはネームスペースのレベルで利用状況メトリクスを取得することが理想的です。
この記事では、コンテナベースのGPUメトリクスの設定方法と、EKSポッドからこれらのメトリクスを収集する例を提供します。
ソリューションの概要
コンテナベースのGPUメトリクスをデモンストレーションするために、g5.2xlargeのインスタンスを使用したEKSクラスタを作成します。ただし、これはサポートされているNVIDIAアクセラレーションインスタンスファミリであれば使用できます。
GPUリソースの使用を可能にするためにNVIDIA GPUオペレータを展開し、GPUメトリクスの収集を可能にするためにNVIDIA DCGMエクスポータを展開します。その後、2つのアーキテクチャを探索します。最初のアーキテクチャでは、NVIDIA DCGMエクスポータからメトリクスをCloudWatchに接続するためにCloudWatchエージェントを使用します。以下のダイアグラムに示すように。
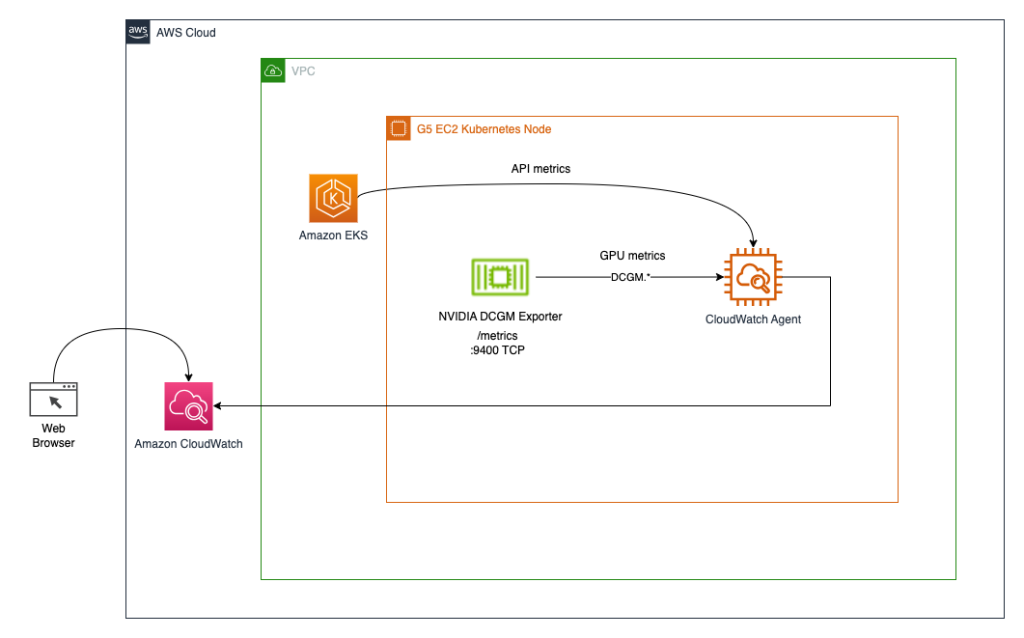
2つ目のアーキテクチャ(以下のダイアグラムを参照)では、DCGMエクスポータからのメトリクスをPrometheusに接続し、それらのメトリクスを可視化するためにGrafanaダッシュボードを使用します。
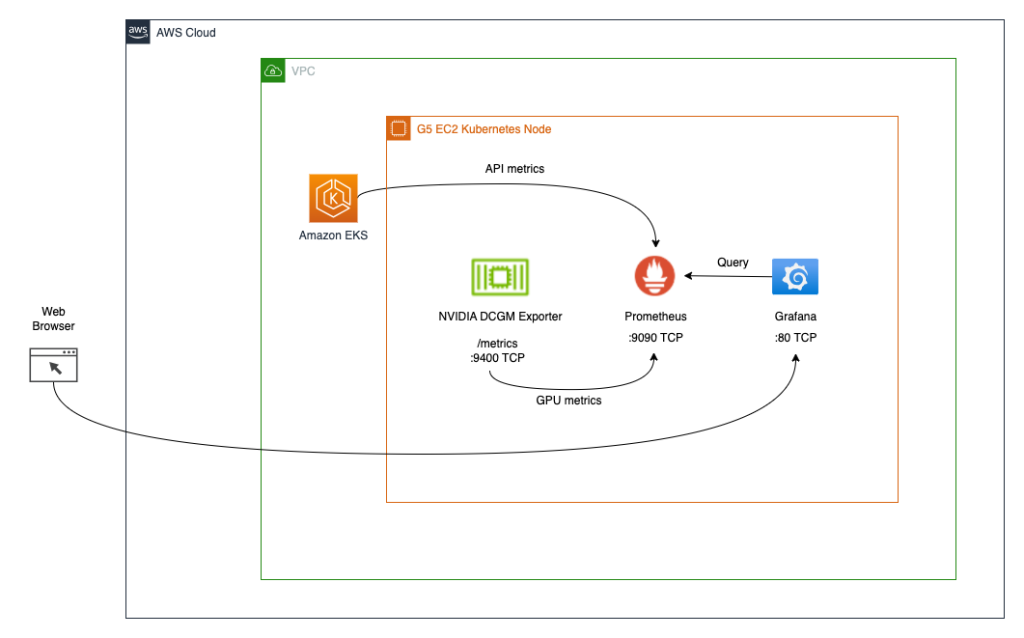
前提条件
この記事からスタック全体を再現するために、必要なツール(aws cli、eksctl、helmなど)がすでにインストールされているコンテナを使用します。GitHubからコンテナプロジェクトをクローンするには、gitが必要です。コンテナをビルドして実行するには、Dockerが必要です。アーキテクチャを展開するには、AWSの認証情報が必要です。ポートフォワーディングを使用してKubernetesサービスへのアクセスを有効にするためには、kubectlも必要です。
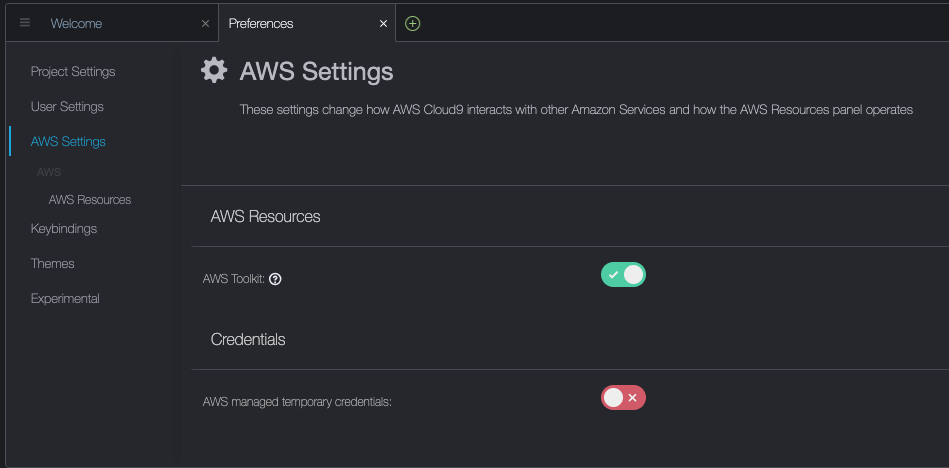
これらの前提条件は、ローカルマシン、NICE DCVを備えたEC2インスタンス、またはAWS Cloud9にインストールすることができます。この記事では、c5.2xlargeのCloud9インスタンスと40GBのローカルストレージボリュームを使用します。Cloud9を使用する場合は、以下のスクリーンショットに示すように、AWSの管理された一時クレデンシャルを無効にしてください。
aws-do-eksコンテナのビルドと実行
お好みの環境でターミナルシェルを開き、次のコマンドを実行します:
git clone https://github.com/aws-samples/aws-do-eks
cd aws-do-eks
./build.sh
./run.sh
./exec.sh結果は以下のとおりです:
root@e5ecb162812f:/eks#これで、必要なすべてのツールを備えたコンテナ環境でシェルを持つことができました。以降、このシェルを「aws-do-eksシェル」と呼びます。以降のセクションでのコマンドは、明示的に指示されない限り、このシェルで実行します。
ノードグループを持つEKSクラスタを作成する
このグループには、選択したGPUインスタンスファミリが含まれます。この例ではg5.2xlargeインスタンスタイプを使用します。
aws-do-eksプロジェクトには、クラスター構成のコレクションが付属しています。単一の構成変更で所望のクラスター構成を設定することができます。
- コンテナシェルで
./env-config.shを実行し、CONF=conf/eksctl/yaml/eks-gpu-g5.yamlを設定します - クラスター構成を確認するには、
./eks-config.shを実行します
次のクラスターマニフェストが表示されるはずです:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-g5
version: "1.25"
region: us-east-1
availabilityZones:
- us-east-1a
- us-east-1b
- us-east-1c
- us-east-1d
managedNodeGroups:
- name: sys
instanceType: m5.xlarge
desiredCapacity: 1
iam:
withAddonPolicies:
autoScaler: true
cloudWatch: true
- name: g5
instanceType: g5.2xlarge
instancePrefix: g5-2xl
privateNetworking: true
efaEnabled: false
minSize: 0
desiredCapacity: 1
maxSize: 10
volumeSize: 80
iam:
withAddonPolicies:
cloudWatch: true
iam:
withOIDC: true- クラスターを作成するには、コンテナ内で次のコマンドを実行します
./eks-create.sh出力は次のようになります:
root@e5ecb162812f:/eks# ./eks-create.sh
/eks/impl/eksctl/yaml /eks
./eks-create.sh
2023年5月22日 20:50:59 UTC
/eks/conf/eksctl/yaml/eks-gpu-g5.yamlを使用してクラスターを作成しています...
eksctl create cluster -f /eks/conf/eksctl/yaml/eks-gpu-g5.yaml
2023年5月22日 20:50:59 [ℹ] eksctlバージョン0.133.0を使用しています
2023年5月22日 20:50:59 [ℹ] リージョンはus-east-1を使用しています
2023年5月22日 20:50:59 [ℹ] us-east-1aのサブネット - public:192.168.0.0/19 private:192.168.128.0/19
2023年5月22日 20:50:59 [ℹ] us-east-1bのサブネット - public:192.168.32.0/19 private:192.168.160.0/19
2023年5月22日 20:50:59 [ℹ] us-east-1cのサブネット - public:192.168.64.0/19 private:192.168.192.0/19
2023年5月22日 20:50:59 [ℹ] us-east-1dのサブネット - public:192.168.96.0/19 private:192.168.224.0/19
2023年5月22日 20:50:59 [ℹ] ノードグループ"sys"は""[AmazonLinux2/1.25]- クラスタが正常に作成されたことを確認するには、次のコマンドを実行します。
kubectl get nodes -L node.kubernetes.io/instance-type
出力は以下のようになります。
NAME STATUS ROLES AGE VERSION INSTANCE_TYPE
ip-192-168-18-137.ec2.internal Ready <none> 47m v1.25.9-eks-0a21954 m5.xlarge
ip-192-168-214-241.ec2.internal Ready <none> 46m v1.25.9-eks-0a21954 g5.2xlarge
この例では、クラスタにm5.xlargeおよびg5.2xlargeのインスタンスが1つずつあるため、前の出力には2つのノードが表示されます。
クラスタ作成プロセス中にNVIDIAデバイスプラグインがインストールされます。クラスタ作成後にNVIDIA GPU Operatorを使用するため、削除する必要があります。
- 次のコマンドでプラグインを削除します。
kubectl -n kube-system delete daemonset nvidia-device-plugin-daemonset
次の出力が表示されます。
daemonset.apps "nvidia-device-plugin-daemonset" deleted
NVIDIA Helmリポジトリのインストール
次のコマンドでNVIDIA Helmリポジトリをインストールします。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
NVIDIA GPU Operatorを使用してDCGMエクスポーターをデプロイする
DCGMエクスポーターをデプロイするには、次の手順を実行してください。
- DCGMエクスポーターのGPUメトリックス設定を準備します。
curl https://raw.githubusercontent.com/NVIDIA/dcgm-exporter/main/etc/dcp-metrics-included.csv > dcgm-metrics.csv
dcgm-metrics.csvファイルを編集するオプションがあります。必要に応じてメトリックスを追加または削除することができます。
- gpu-operator namespaceとDCGMエクスポーターのConfigMapを作成します。
kubectl create namespace gpu-operator && /
kubectl create configmap metrics-config -n gpu-operator --from-file=dcgm-metrics.csv
出力は以下のようになります。
namespace/gpu-operator created
configmap/metrics-config created
- EKSクラスタにGPUオペレータを適用します。
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator \
--set dcgmExporter.config.name=metrics-config \
--set dcgmExporter.env[0].name=DCGM_EXPORTER_COLLECTORS \
--set dcgmExporter.env[0].value=/etc/dcgm-exporter/dcgm-metrics.csv \
--set toolkit.enabled=false
出力は以下のようになります。
NAME: gpu-operator-1684795140
LAST DEPLOYED: Day Month Date HH:mm:ss YYYY
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
- DCGMエクスポーターのポッドが実行されていることを確認します。
kubectl -n gpu-operator get pods | grep dcgm
出力は以下のようになります。
nvidia-dcgm-exporter-lkmfr 1/1 Running 0 1m
ログを確認すると、「"Starting webserver"」というメッセージが表示されます。
kubectl -n gpu-operator logs -f $(kubectl -n gpu-operator get pods | grep dcgm | cut -d ' ' -f 1)
出力は以下のようになります。
Defaulted container "nvidia-dcgm-exporter" out of: nvidia-dcgm-exporter, toolkit-validation (init)
time="2023-05-22T22:40:08Z" level=info msg="Starting dcgm-exporter"
time="2023-05-22T22:40:08Z" level=info msg="DCGM successfully initialized!"
time="2023-05-22T22:40:08Z" level=info msg="Collecting DCP Metrics"
time="2023-05-22T22:40:08Z" level=info msg="No configmap data specified, falling back to metric file /etc/dcgm-exporter/dcgm-metrics.csv"
time="2023-05-22T22:40:08Z" level=info msg="Initializing system entities of type: GPU"
time="2023-05-22T22:40:09Z" level=info msg="Initializing system entities of type: NvSwitch"
time="2023-05-22T22:40:09Z" level=info msg="Not collecting switch metrics: no switches to monitor"
time="2023-05-22T22:40:09Z" level=info msg="Initializing system entities of type: NvLink"
time="2023-05-22T22:40:09Z" level=info msg="Not collecting link metrics: no switches to monitor"
time="2023-05-22T22:40:09Z" level=info msg="Kubernetes metrics collection enabled!"
time="2023-05-22T22:40:09Z" level=info msg="Pipeline starting"
time="2023-05-22T22:40:09Z" level=info msg="Starting webserver"
NVIDIA DCGM Exporterは、Prometheusメトリクスエンドポイントを公開し、CloudWatchエージェントが取り込むことができます。エンドポイントを表示するには、次のコマンドを使用します:
kubectl -n gpu-operator get services | grep dcgm
次の出力が表示されます:
nvidia-dcgm-exporter ClusterIP 10.100.183.207 <none> 9400/TCP 10m
- GPUの利用率を生成するために、gpu-burnバイナリを実行するポッドを展開します
kubectl apply -f https://raw.githubusercontent.com/aws-samples/aws-do-eks/main/Container-Root/eks/deployment/gpu-metrics/gpu-burn-deployment.yaml
次の出力が表示されます:
deployment.apps/gpu-burn created
このデプロイメントは、連続的な100%の利用率を20秒間生成し、その後20秒間の利用率を0%にします。
- エンドポイントが正常に機能していることを確
CloudWatchエージェントの設定と展開
CloudWatchエージェントの設定と展開を行うには、以下の手順を完了してください:
- YAMLファイルをダウンロードして編集する
curl -O https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/k8s/1.3.15/k8s-deployment-manifest-templates/deployment-mode/service/cwagent-prometheus/prometheus-eks.yaml
このファイルにはとが含まれています。この記事では、両方を編集します。
prometheus-eks.yamlファイルを編集する
お気に入りのエディタでprometheus-eks.yamlファイルを開き、cwagentconfig.jsonセクションを以下の内容に置き換えます:
apiVersion: v1
data:
# cwagent json config
cwagentconfig.json: |
{
"logs": {
"metrics_collected": {
"prometheus": {
"prometheus_config_path": "/etc/prometheusconfig/prometheus.yaml",
"emf_processor": {
"metric_declaration": [
{
"source_labels": ["Service"],
"label_matcher": ".*dcgm.*",
"dimensions": [["Service","Namespace","ClusterName","job","pod"]],
"metric_selectors": [
"^DCGM_FI_DEV_GPU_UTIL$",
"^DCGM_FI_DEV_DEC_UTIL$",
"^DCGM_FI_DEV_ENC_UTIL$",
"^DCGM_FI_DEV_MEM_CLOCK$",
"^DCGM_FI_DEV_MEM_COPY_UTIL$",
"^DCGM_FI_DEV_POWER_USAGE$",
"^DCGM_FI_DEV_ROW_REMAP_FAILURE$",
"^DCGM_FI_DEV_SM_CLOCK$",
"^DCGM_FI_DEV_XID_ERRORS$",
"^DCGM_FI_PROF_DRAM_ACTIVE$",
"^DCGM_FI_PROF_GR_ENGINE_ACTIVE$",
"^DCGM_FI_PROF_PCIE_RX_BYTES$",
"^DCGM_FI_PROF_PCIE_TX_BYTES$",
"^DCGM_FI_PROF_PIPE_TENSOR_ACTIVE$"
]
}
]
}
}
},
"force_flush_interval": 5
}
}
prometheusの設定セクションに、DCGMエクスポーターのジョブ定義を追加する
- job_name: 'kubernetes-pod-dcgm-exporter'
sample_limit: 10000
metrics_path: /api/v1/metrics/prometheus
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_container_name]
action: keep
regex: '^DCGM.*$'
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: ${1}:9400
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: Namespace
- source_labels: [__meta_kubernetes_pod]
action: replace
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container_name
- action: replace
source_labels:
- __meta_kubernetes_pod_controller_name
target_label: pod_controller_name
- action: replace
source_labels:
- __meta_kubernetes_pod_controller_kind
target_label: pod_controller_kind
- action: replace
source_labels:
- __meta_kubernetes_pod_phase
target_label: pod_phase
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: NodeName
- ファイルを保存し、
cwagent-dcgmの設定をクラスターに適用する
kubectl apply -f ./prometheus-eks.yaml
以下の出力が表示されます:
namespace/amazon-cloudwatch created
configmap/prometheus-cwagentconfig created
configmap/prometheus-config created
serviceaccount/cwagent-prometheus created
clusterrole.rbac.authorization.k8s.io/cwagent-prometheus-role created
clusterrolebinding.rbac.authorization.k8s.io/cwagent-prometheus-role-binding created
deployment.apps/cwagent-prometheus created
- CloudWatchエージェントポッドが実行されていることを確認します
kubectl -n amazon-cloudwatch get pods
次の出力が表示されます:
NAME READY STATUS RESTARTS AGE
cwagent-prometheus-7dfd69cc46-s4cx7 1/1 Running 0 15m
CloudWatchコンソールでメトリクスを可視化する
CloudWatchでメトリクスを可視化するには、次の手順を完了します:
- ナビゲーションペインのメトリクスの下で、CloudWatchコンソールを開きます
- カスタムネームスペースセクションで、ContainerInsights/Prometheusの新しいエントリを選択します
ContainerInsights/Prometheusネームスペースの詳細については、「追加のPrometheusソースのスクレイピングとそれらのメトリクスのインポート」を参照してください。
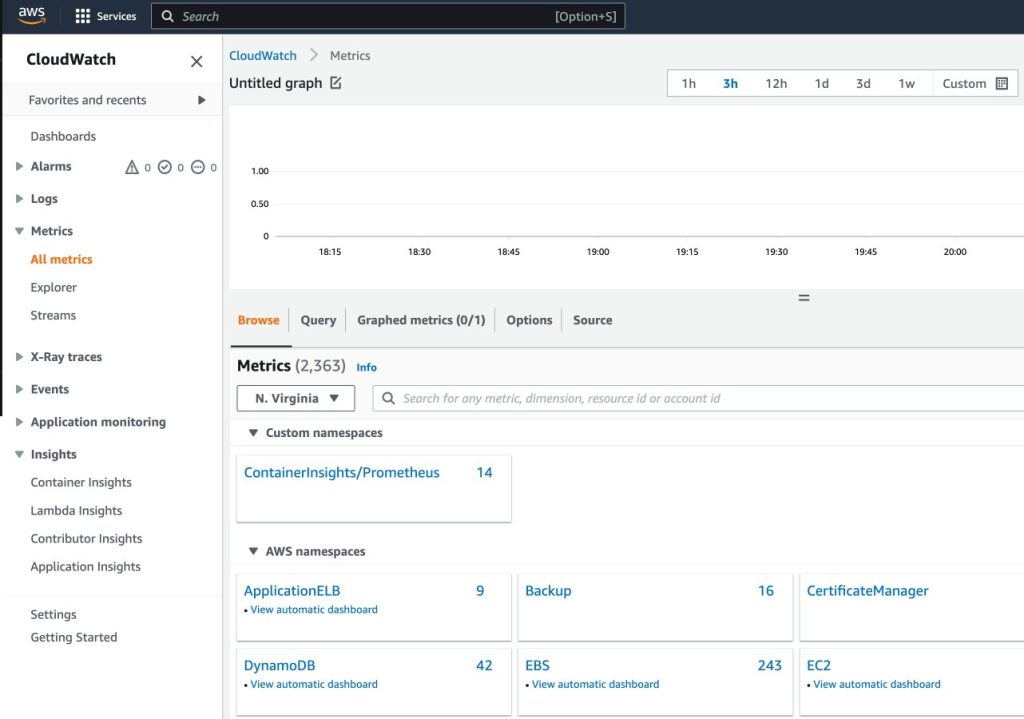
- メトリック名にドリルダウンし、
DCGM_FI_DEV_GPU_UTILを選択します
- グラフ化されたメトリクスタブで、期間を5秒に設定します

- リフレッシュ間隔を10秒に設定します
20秒ごとにgpu-burnパターンがオンとオフになるDCGMエクスポータから収集されたメトリクスが表示されます。
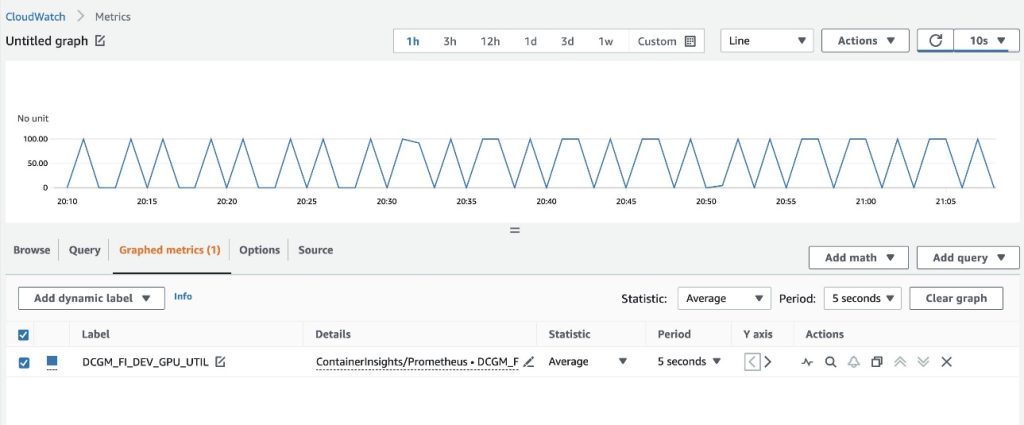
参照タブでは、各メトリクスのポッド名を含むデータが表示されます。
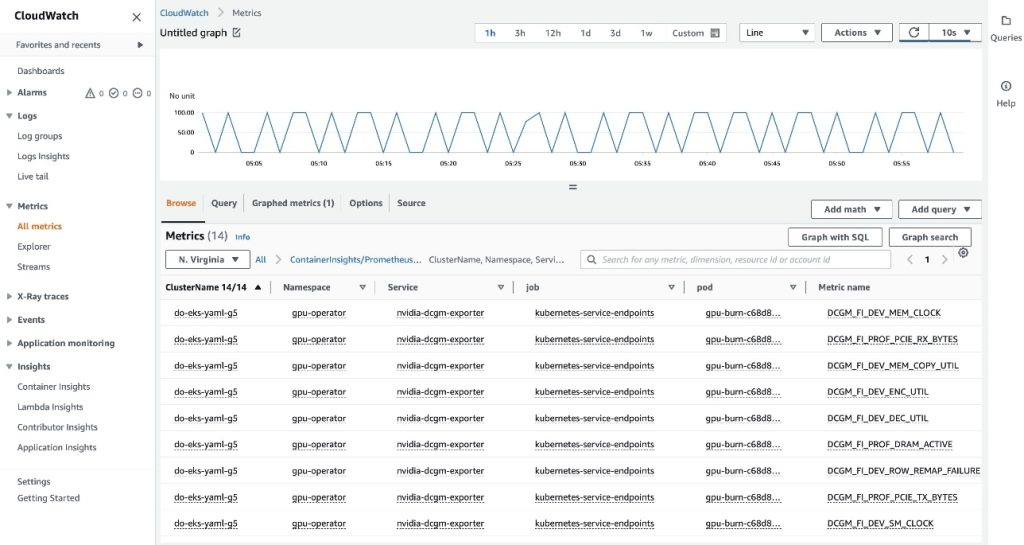
EKS APIメタデータはDCGMメトリクスデータと組み合わされ、提供されたポッドベースのGPUメトリクスが生成されます。
これにて、CloudWatchエージェントを介してDCGMメトリクスをCloudWatchにエクスポートする最初のアプローチが完了しました。
次のセクションでは、DCGMメトリクスをPrometheusにエクスポートし、Grafanaで可視化するための2番目のアーキテクチャを構成します。
PrometheusとGrafanaを使用してDCGMからGPUメトリクスを可視化する
次の手順を完了します:
- Prometheusコミュニティヘルムチャートを追加します
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
このチャートはPrometheusとGrafanaの両方をデプロイします。インストールコマンドを実行する前に、チャートを編集する必要があります。
- チャートの構成値を
/tmpに保存します
helm inspect values prometheus-community/kube-prometheus-stack > /tmp/kube-prometheus-stack.values
- チャートの構成ファイルを編集します
保存されたファイル(/tmp/kube-prometheus-stack.values)を編集し、次のオプションを設定します。設定名を検索し、値を設定します:
prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
- 次のConfigMapを
additionalScrapeConfigsセクションに追加します
additionalScrapeConfigs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
- 更新された値でPrometheusスタックを展開します
helm install prometheus-community/kube-prometheus-stack \
--create-namespace --namespace prometheus \
--generate-name \
--values /tmp/kube-prometheus-stack.values
次の出力が表示されます:
NAME: kube-prometheus-stack-1684965548
LAST DEPLOYED: Wed May 24 21:59:14 2023
NAMESPACE: prometheus
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stackがインストールされました。次のコマンドを実行してステータスを確認してください:
kubectl --namespace prometheus get pods -l "release=kube-prometheus-stack-1684965548"
Operatorを使用してAlertmanagerとPrometheusインスタンスを作成および設定する手順については、
https://github.com/prometheus-operator/kube-prometheus を参照してください。
- Prometheusのポッドが実行されていることを確認します
kubectl get pods -n prometheus
次の出力が表示されます:
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-1684-alertmanager-0 2/2 Running 0 6m55s
kube-prometheus-stack-1684-operator-6c87649878-j7v55 1/1 Running 0 6m58s
kube-prometheus-stack-1684965548-grafana-dcd7b4c96-bzm8p 3/3 Running 0 6m58s
kube-prometheus-stack-1684965548-kube-state-metrics-7d856dptlj5 1/1 Running 0 6m58s
kube-prometheus-stack-1684965548-prometheus-node-exporter-2fbl5 1/1 Running 0 6m58s
kube-prometheus-stack-1684965548-prometheus-node-exporter-m7zmv 1/1 Running 0 6m58s
prometheus-kube-prometheus-stack-1684-prometheus-0 2/2 Running 0 6m55s
PrometheusとGrafanaのポッドはRunning状態です。
次に、DCGMメトリクスがPrometheusにフローしていることを確認します。
- Prometheus UIにポートフォワードします
EKSで実行されているPrometheus UIをクラスターの外部からのリクエストに公開するための異なる方法があります。ここではkubectlポートフォワーディングを使用します。これまで、aws-do-eksコンテナ内でコマンドを実行してきました。クラスター内で実行されているPrometheusサービスにアクセスするために、ホストからトンネルを作成します。ここでは、ホストシェルで新しいターミナルシェルでコンテナの外で次のコマンドを実行します。これを「ホストシェル」と呼びます。
kubectl -n prometheus port-forward svc/$(kubectl -n prometheus get svc | grep prometheus | grep -v alertmanager | grep -v operator | grep -v grafana | grep -v metrics | grep -v exporter | grep -v operated | cut -d ' ' -f 1) 8080:9090 &
ポートフォワーディングプロセスが実行されている間、以下の方法でホストからPrometheus UIにアクセスできます。
- Prometheus UIを開く
- Cloud9を使用している場合は、
プレビュー->実行中のアプリケーションのプレビューに移動し、Cloud9 IDE内のタブでPrometheus UIを開き、タブの右上隅の アイコンをクリックして新しいウィンドウでポップアウトします。
アイコンをクリックして新しいウィンドウでポップアウトします。
- ローカルホストで使用している場合、またはリモートデスクトップを介してEC2インスタンスに接続している場合は、ブラウザを開き、URL
http://localhost:8080 を訪問します。
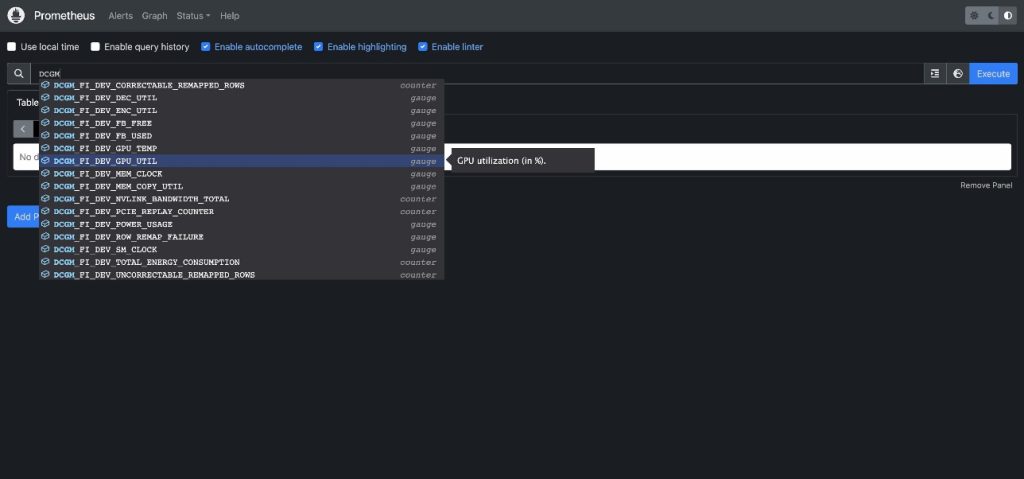
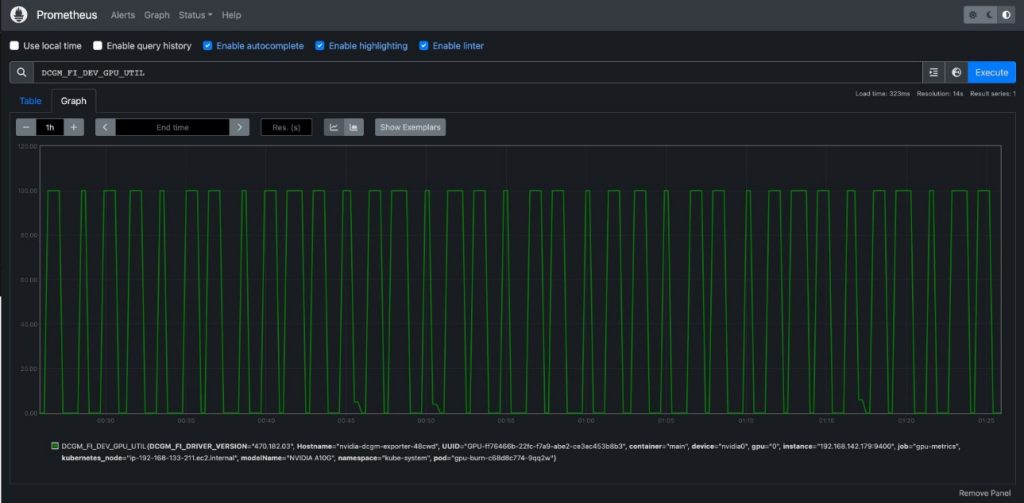
DCGMを入力して、Prometheusに流れているDCGMメトリクスを表示しますDCGM_FI_DEV_GPU_UTILを選択し、実行を選び、グラフタブに移動して、予想されるGPU利用率パターンを表示します
- Prometheusのポートフォワーディングプロセスを停止します
ホストのシェルで以下のコマンドラインを実行します:
kill -9 $(ps -aef | grep port-forward | grep -v grep | grep prometheus | awk '{print $2}')
これで、Grafanaダッシュボードを使用してDCGMメトリクスを可視化することができます。
- Grafana UIにログインするためのパスワードを取得します
kubectl -n prometheus get secret $(kubectl -n prometheus get secrets | grep grafana | cut -d ' ' -f 1) -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
- Grafanaサービスのポートフォワーディングを行います
ホストのシェルで以下のコマンドラインを実行します:
kubectl port-forward -n prometheus svc/$(kubectl -n prometheus get svc | grep grafana | cut -d ' ' -f 1) 8080:80 &
- Grafana UIにログインします
前述の方法で、Prometheus UIにアクセスしたのと同じ方法で、Grafana UIのログイン画面にアクセスします。Cloud9を使用している場合は、Preview->Preview Running Applicationを選択して、新しいウィンドウでポップアウトしてください。ローカルホストまたはリモートデスクトップを使用している場合は、URL http://localhost:8080 を訪問します。ユーザー名はadmin、パスワードは先ほど取得したものです。
- ナビゲーションペインでDashboardsを選択します
- Newを選び、Importを選びます
 NVIDIA DCGM Exporter Dashboardに記載されているデフォルトのDCGM Grafanaダッシュボードをインポートします。
NVIDIA DCGM Exporter Dashboardに記載されているデフォルトのDCGM Grafanaダッシュボードをインポートします。
import via grafana.comのフィールドに12239を入力し、Loadを選びます- データソースとしてPrometheusを選びます
- Importを選びます
以下のスクリーンショットに示されているのと同様のダッシュボードが表示されます。
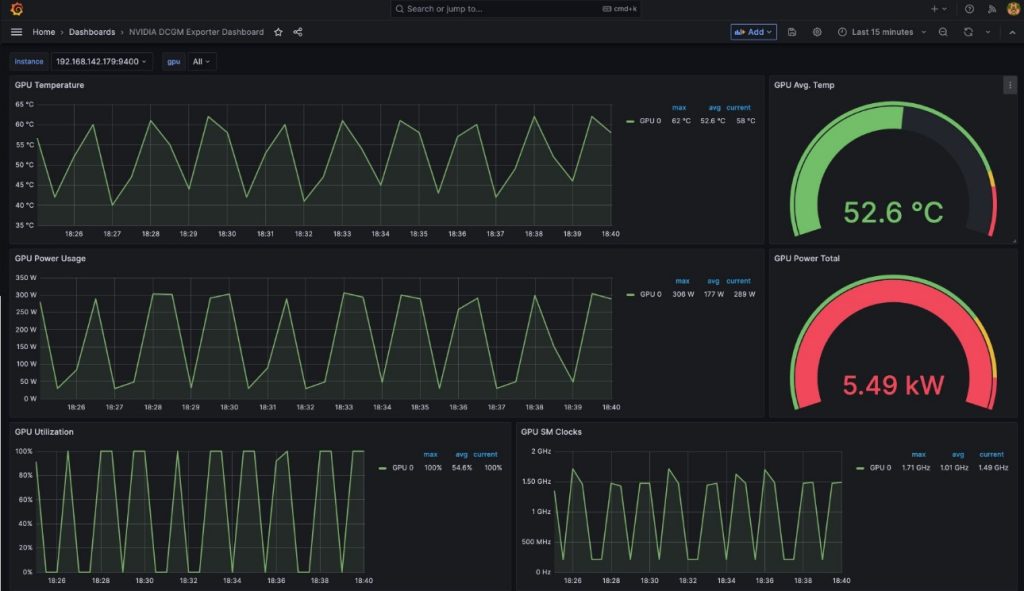
これらのメトリクスがポッドベースであることを示すために、このダッシュボードのGPU利用率パネルを変更します。
- パネルとオプションメニュー(三点リーダー)を選択します
- オプションセクションを展開し、凡例フィールドを編集します
- そこにある値を
Pod {{pod}}で置き換え、保存を選択します
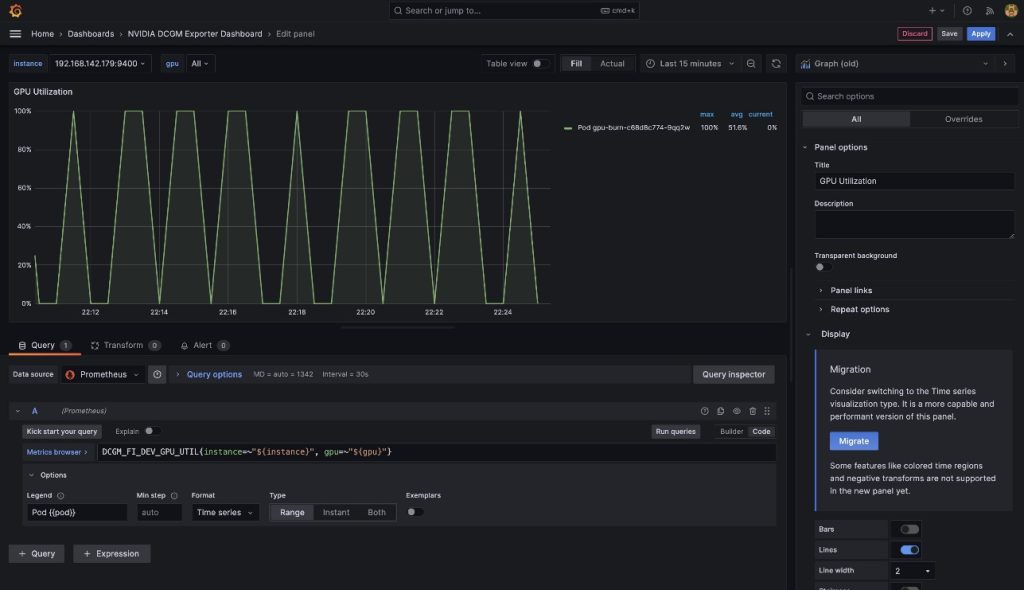 これにより、表示されるGPU利用率に関連する
これにより、表示されるGPU利用率に関連するgpu-burnポッド名が凡例に表示されます。
- Grafana UIサービスのポートフォワーディングを停止します
ホストシェルで以下を実行します:
kill -9 $(ps -aef | grep port-forward | grep -v grep | grep prometheus | awk '{print $2}')
この投稿では、オープンソースのPrometheusとGrafanaをEKSクラスタにデプロイして使用する方法を示しました。必要に応じて、このデプロイメントはAmazon Managed Service for PrometheusとAmazon Managed Grafanaで置き換えることができます。
リソースのクリーンアップ
作成したリソースをクリーンアップするには、aws-do-eksコンテナシェルから以下のスクリプトを実行します:
./eks-delete.sh
まとめ
この投稿では、NVIDIA DCGM Exporterを使用してGPUメトリクスを収集し、CloudWatchまたはPrometheusとGrafanaで可視化する方法を紹介しました。これらのアーキテクチャを使用して、独自のAWS環境でNVIDIA DCGMによるGPU利用率のモニタリングを実現することをお勧めします。
追加リソース
- Amazon EC2 GPUインスタンス
- NVIDIA DCGM: クラスタ環境でのGPUの管理とモニタリング
- kube-prometheus-stack GitHubリポジトリ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
「自律ロボット研究所によって発見された最も頑丈な構造」
-
「AIとの会話の仕方」
翻訳結果は:
-
「カタストロフィックな忘却を防ぎつつ、タスクに微調整されたモデルのファインチューニングにqLoRAを活用する:LLaMA2(-chat)との事例研究」
-
「OpenAI WhisperとHugging Chat APIを使用したビデオの要約」
-
「マイクロソフトが新しいAI搭載スマートバックパックに特許を申請」
-
「モデルガバナンスを向上させるために、Amazon SageMaker Model Cardsの共有を利用してください」
-
Amazon SageMakerのマルチモデルエンドポイントを使用して、TorchServeを使ってGPU上で複数の生成AIモデルを実行し、推論コストを最大75%節約できます





