最初のLLMアプリを構築するために知っておく必要があるすべて
All you need to know to build the first LLM app.
ドキュメントローダー、埋め込み、ベクトルストア、プロンプトテンプレートのステップバイステップチュートリアル
目次
画像をクリックして記事を閲覧することができます。
シンプルなLLMアプリケーションを構築する方法を説明する短いチュートリアルを探している場合は、「6. ベクトルストアの作成」セクションにスキップすることができます。そこには、ベクトルストア、プロンプトテンプレート、LLM呼び出しに必要なすべてのコードスニペットがあります。


- 再帰型ニューラルネットワークの基礎からの説明と視覚化
- AIは自己を食べるのか?このAI論文では、モデルの崩壊と呼ばれる現象が紹介されており、モデルが時間の経過とともに起こり得ないイベントを忘れ始める退行的な学習プロセスを指します
- より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放







なぜLLMsが必要なのか
言語の進化は、今日の形式で知識を効率的に共有し、協力することを可能にし、私たち人間を信じられないほど前進させてきました。したがって、私たちのコレクティブな知識の大部分は、未整理の書かれたテキストを通じて保存され、伝えられ続けています。
過去20年間に行われた情報とプロセスのデジタル化に関する取り組みは、しばしば関係データベースによるますます多くのデータの蓄積に集中してきました。このアプローチにより、従来の分析的機械学習アルゴリズムが私たちのデータを処理し理解することができます。
しかし、構造化された方法でますます多くのデータを保存するための私たちの幅広い努力にもかかわらず、私たちはまだ私たちの知識の全体を捉え、処理することができません。
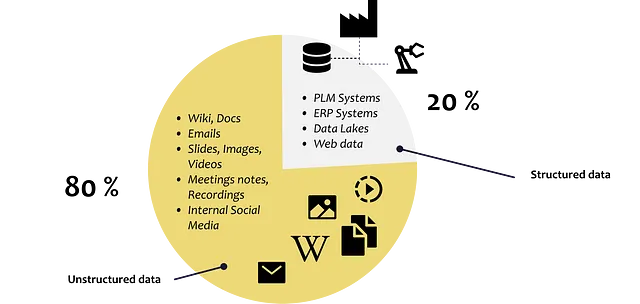
企業のすべてのデータの約80%は、職務の説明、履歴書、メール、テキスト文書、パワーポイントスライド、音声録音、ビデオ、ソーシャルメディアなどの非構造化データです。
GPT3.5に至るまでの開発と進歩は、私たちが構造化されているかどうかに関係なく、多様なデータセットを効果的に解釈し分析することを可能にする重要なマイルストーンを示しています。現在、テキスト、画像、オーディオファイルなど、さまざまな形式のコンテンツを理解し生成することができるモデルがあります。
では、私たちの必要性とデータに彼らの能力をどのように活用できるのでしょうか?
ファインチューニングとコンテキストインジェクション
一般的に、大規模な言語モデルが知りえない質問に答えるために、大きく異なる2つのアプローチがあります: モデルのファインチューニング と コンテキストインジェクション
ファインチューニング
ファインチューニングは、特定のタスクに最適化するために、追加のデータで既存の言語モデルをトレーニングすることを指します。
スクラッチから言語モデルをトレーニングする代わりに、BERTやLLamaなどの事前にトレーニングされたモデルを使用し、ユースケース固有のトレーニングデータを追加して、特定のタスクのニーズに合わせて適応させます。
スタンフォード大学のチームは、LLM Llamaを使用して、50,000のユーザー/モデルの相互作用の例を使用してファインチューニングしました。その結果、ユーザーと対話し、クエリに答えるチャットボットが作成されました。このファインチューニングのステップにより、モデルがエンドユーザーとの相互作用方法が変わりました。
→ ファインチューニングに関する誤解
PLLMs(事前にトレーニングされた言語モデル)のファインチューニングは、モデルを特定のタスクに適応させる方法ですが、独自のドメイン知識をモデルに注入することはできません。これは、モデルがすでに大量の一般言語データでトレーニングされており、特定のドメインデータが通常の場合、モデルがすでに学習した内容を上書きするのに十分な情報ではないためです。
したがって、モデルをファインチューニングすると、正しい答えを提供することがあるかもしれませんが、プレトレーニングで学習した情報に大きく依存しているため、特定のタスクにとって正確または関連性があるとは限りません。言い換えると、ファインチューニングは、モデルが通信する方法に適応するのを助けますが、必ずしも通信内容に適応するわけではありません。(ポルシェAG、2023年)
ここで、コンテキストインジェクションが登場します。
インコンテキスト学習/コンテキストインジェクション
コンテキストインジェクションを使用する場合、LLM自体を変更するのではなく、プロンプト自体に注目し、関連するコンテキストをプロンプトに挿入します。
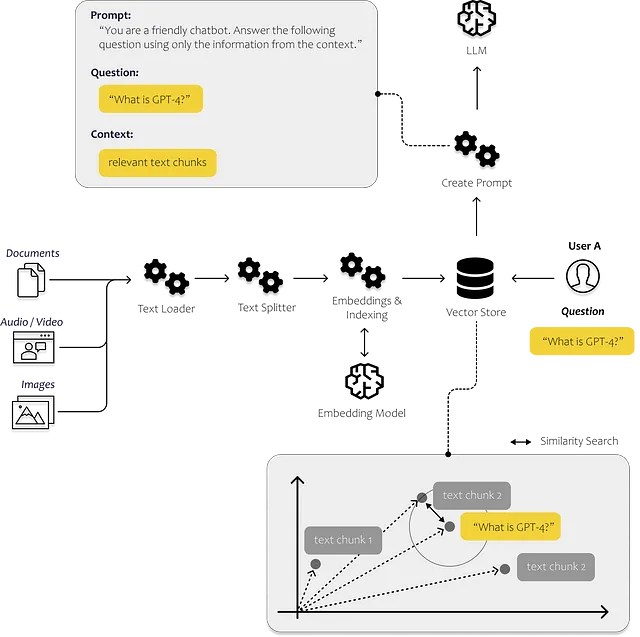
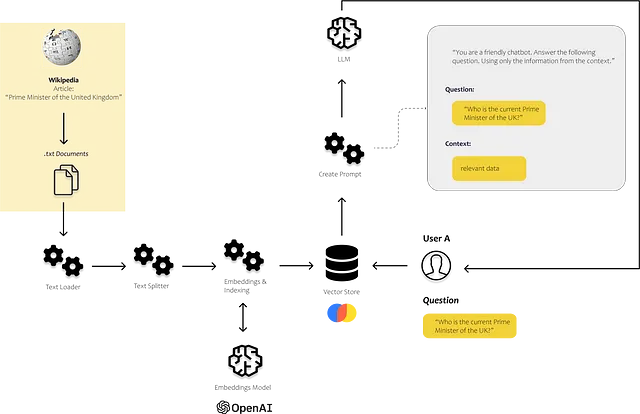
そのため、最適な情報をプロンプトに提供する方法を考える必要があります。以下の図では、全体がどのように機能するかを模式的に示しています。テキストの断片をお互いに比較できるプロセスが必要です。
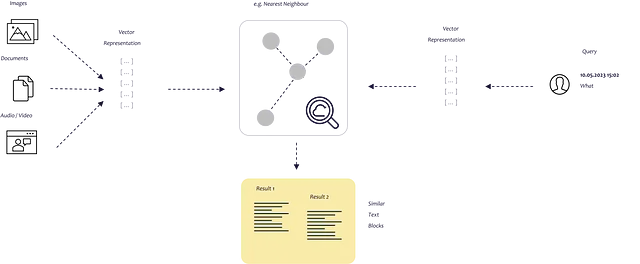
これは埋め込みを使用して行うことができます。埋め込みを使用すると、テキストをベクトルに変換して、多次元の埋め込み空間でテキストを表現できるようになります。空間内でお互いに近い位置にあるポイントは、しばしば同じコンテキストで使用されます。この類似性検索が永遠に続かないようにするために、ベクトルをベクトルデータベースに格納してインデックスを付けます。
Microsoftは、Bing Chatでこれがどのように機能するかを示しています。Bingは、LLMが言語とコンテキストを理解する能力と、従来のWeb検索の効率性を組み合わせています。
この記事の目的は、自分自身のテキストやドキュメントを分析し、それらから得られた洞察を解決策がユーザーに返す回答に取り込むための簡単なソリューションのプロセスを示すことです。すべてのステップとコンポーネントを説明し、エンドツーエンドソリューションを実装するために必要なものを説明します。
では、LLMの機能をどのように活用できるでしょうか?ステップバイステップで説明していきましょう。
ステップバイステップチュートリアル – あなたの最初のLLMアプリ
次に、LLMsを利用して、個人データに関する問い合わせに応答するために、個人データの内容をベクトルデータベースに転送します。このステップは重要であり、テキスト内の関連セクションを効率的に検索できるようにします。このデータとLLMsの機能を使用して、ユーザーの質問に答えるためのテキストを解釈します。
また、データに基づいて質問に回答するようにチャットボットを誘導することもできます。これにより、チャットボットが対象のデータに焦点を当て、正確で関連性のある回答を提供することができます。
このユースケースを実装するためには、LangChainに大いに依存する必要があります。
LangChainとは?
「LangChainは、言語モデルによって動力を得たアプリケーションを開発するためのフレームワークです。」(Langchain, 2023)
したがって、LangChainはPythonのフレームワークであり、チャットボット、要約ツールなど、LLMを活用したいあらゆるツールの作成を支援するために設計されました。このライブラリは、必要な様々なコンポーネントを組み合わせて接続することができます。
Langchainの最も重要なモジュールは次のとおりです(Langchain, 2023):
- Models: 様々なモデルタイプのインターフェース
- Prompts: プロンプトの管理、最適化、およびシリアル化
- Indexes: ドキュメントローダー、テキスト分割、ベクターストアなどの機能により、データにより迅速で効率的なアクセスが可能
- Chains: 単一のLLM呼び出しを超えて、呼び出しのシーケンスを設定することができます
以下の画像で、これらのコンポーネントがどこで使われるかを見ることができます。indexesモジュールのドキュメントローダーとテキスト分割を使って、自分自身の非構造化データをロードして処理します。promptsモジュールを使用して、見つかった内容をプロンプトテンプレートに挿入し、最後にモデルのモジュールを使用してプロンプトを送信します。
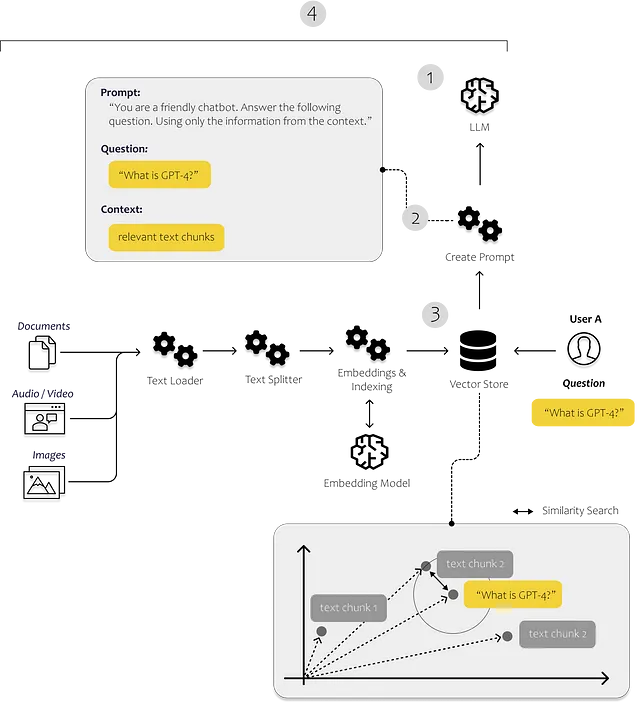
5. Agents: エージェントとは、LLMを使用してどのアクションを実行するかを決定するエンティティです。アクションを実行した後、そのアクションの結果を観察し、タスクが完了するまでプロセスを繰り返します。
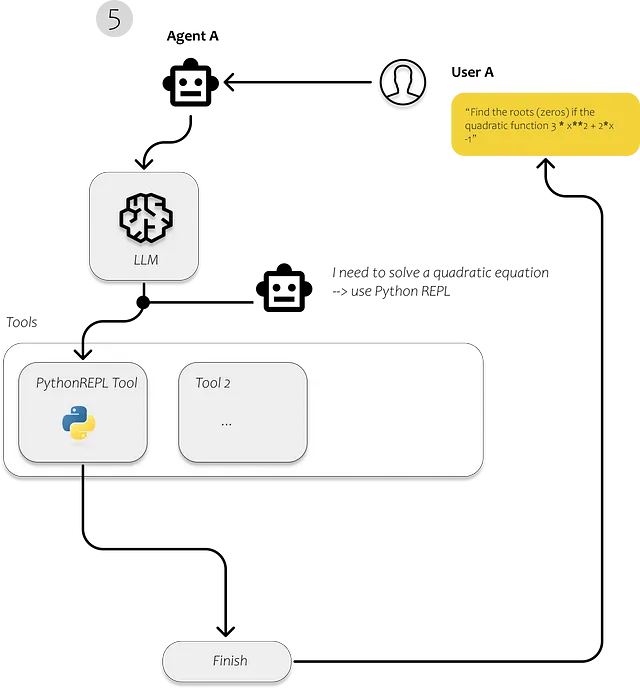
LangChainを使用して、最初にドキュメントをロードし、分析し、効率的に検索可能にします。テキストをインデックス化した後、ユーザーの質問に回答するために関連するテキストの断片を認識することがはるかに効率的になります。
シンプルなアプリケーションに必要なのは、もちろんLLMです。OpenAI APIを介してGPT3.5を使用します。その後、独自のデータをLLMにフィードすることができるベクターストアが必要です。異なるクエリに対して異なるアクションを実行したい場合は、各クエリごとに何を実行するかを決定するエージェントが必要です。
まず、独自のドキュメントをインポートする必要があります。
次のセクションでは、LangChainのLoader Moduleに含まれるモジュールについて説明し、様々なソースから異なるタイプのドキュメントをロードする方法について説明します。
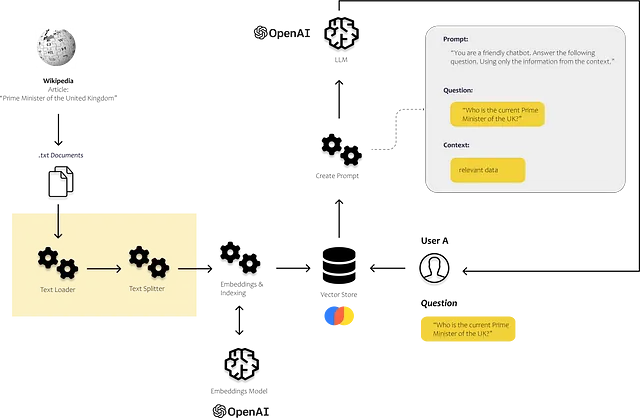
1. Langchainを使用してドキュメントをロードする
LangChainは、さまざまなソースから多数のドキュメントをロードすることができます。LangChainのドキュメントには、HTMLページ、S3バケット、PDF、Notion、Googleドライブなどのローダーが含まれています。
このシンプルな例では、GPT3.5のトレーニングデータに含まれていなかったデータを使用します。GPT3.5についての知識が限定されていると仮定して、GPT4に関するウィキペディアの記事を使用します。
この簡単な例では、LangChainのローダーを使用せず、BeautifulSoupを使用して直接テキストをスクレイピングしています。
ウェブサイトをスクレイピングする場合は、ウェブサイトの利用規約と使用したいテキストやデータの著作権/ライセンス状況に従ってのみ行ってください。
import requestsfrom bs4 import BeautifulSoupurl = "https://en.wikipedia.org/wiki/GPT-4"response = requests.get(url)soup = BeautifulSoup(response.content, 'html.parser')# find the content divcontent_div = soup.find('div', {'class': 'mw-parser-output'})# remove unwanted elements from divunwanted_tags = ['sup', 'span', 'table', 'ul', 'ol']for tag in unwanted_tags: for match in content_div.findAll(tag): match.extract()print(content_div.get_text())
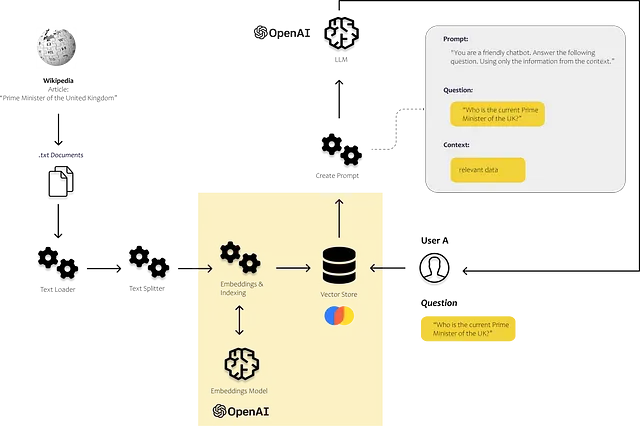
2. ドキュメントをテキスト断片に分割する
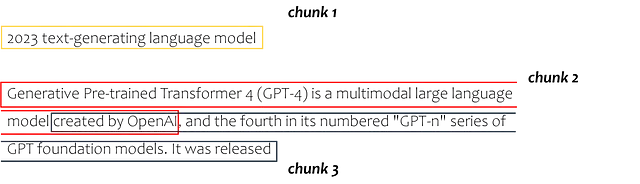
次に、テキストをテキストチャンクと呼ばれる小さなセクションに分割する必要があります。各テキストチャンクは、埋め込み空間のデータポイントを表し、コンピューターがこれらのチャンク間の類似性を決定できるようにします。
以下のテキストスニペットでは、langchainのテキストスプリッターモジュールを利用しています。この特定の場合では、チャンクサイズを100、チャンクオーバーラップを20で指定しています。一般的には、より大きなテキストチャンクを使用することが一般的ですが、使用ケースに最適なサイズを見つけるために少し試行することができます。ただし、すべてのLLMにはトークン制限があります(GPT 3.5の場合、4000トークン)。テキストブロックをプロンプトに挿入するため、プロンプト全体が4000トークンより大きくならないようにする必要があります。
from langchain.text_splitter import RecursiveCharacterTextSplitterarticle_text = content_div.get_text()text_splitter = RecursiveCharacterTextSplitter( # Set a really small chunk size, just to show. chunk_size = 100, chunk_overlap = 20, length_function = len,)texts = text_splitter.create_documents([article_text])print(texts[0])print(texts[1])
これにより、次のようにテキスト全体が分割されます。
3. テキストチャンクから埋め込みへ
次に、テキストのコンポーネントをアルゴリズムが理解できるようにし、比較できるようにする必要があります。人間の言葉をビットとバイトで表されるデジタル形式に変換する方法を見つける必要があります。
以下の画像は、ほとんどの人にとって明らかな単純な例を示しています。ただし、コンピューターにとって「Charles」という名前が女性ではなく男性と関連付けられていること、そしてCharlesが男性であれば、彼は女性ではなく王であることを理解させる方法を見つける必要があります。

ここ数年で、これを実現する新しい方法やモデルが登場しています。我々が望むのは、単語の意味をn次元空間に変換し、テキストチャンクを互いに比較し、類似性の尺度を計算することができるようにすることです。
埋め込みモデルは、単語が通常使用される文脈を分析することによって、まさにそれを実現しようとします。紅茶、コーヒー、そして朝食はしばしば同じ文脈で使用されるため、例えば紅茶とピーよりも互いに近くなります。紅茶とピーは似ているように聞こえますが、一緒に使用されることはめったにありません。(AssemblyAI、2022)

埋め込みモデルは、埋め込み空間内の各単語に対してベクトルを提供します。最後に、ベクトルを使用して、データポイント間の距離として単語間の類似性を計算するなどの数学的計算を実行できます。

テキストを埋め込みに変換するには、Word2Vec、GloVe、fastText、またはELMoなどの方法があります。
埋め込みモデル
Word2Vecは、単語間の類似性を捉えるために、シンプルなニューラルネットワークを使用します。私たちは大量のテキストデータでこのモデルをトレーニングし、各単語にn次元の埋め込み空間の点を割り当て、ベクトルの形式でその意味を表すモデルを作成したいと考えています。
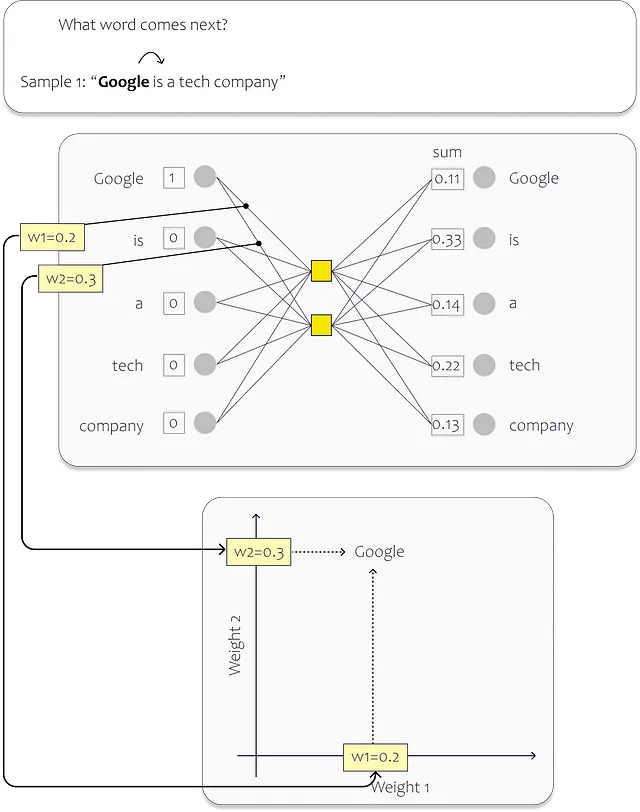
トレーニングでは、データセット内の各ユニークな単語に入力層のニューロンを割り当てます。以下の画像は単純な例を示しています。この場合、隠れ層には2つのニューロンしか含まれていません。単語を2次元の埋め込み空間にマップしたいため、2つあります。(実際のモデルははるかに大きく、単語をより高次元の空間で表します。OpenAIのAda埋め込みモデルは、例えば1536次元を使用しています)トレーニングプロセスの後、個々の重みは埋め込み空間での位置を記述します。
この例では、データセットは単一の文「Google is a tech company.」で構成されています。文中の各単語はニューラルネットワーク(NN)の入力として機能します。したがって、ネットワークには各単語に対して1つの入力ニューロンがあります。
トレーニングプロセス中、私たちは各入力単語の次の単語を予測することに焦点を当てます。文の先頭から始めると、「Google」という単語に対応する入力ニューロンは1の値を受け取り、残りのニューロンは0の値を受け取ります。この特定のシナリオで単語「is」を予測するようにネットワークをトレーニングすることを目的としています。
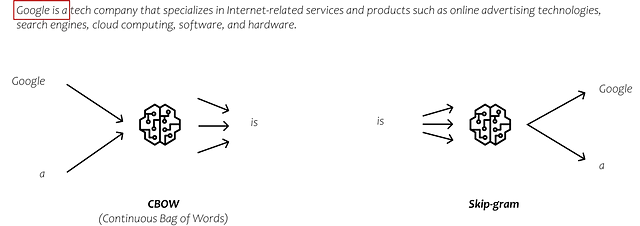
実際には、埋め込みモデルを学習するための複数のアプローチがあり、トレーニングプロセス中に出力を予測する独自の方法を持っています。一般的に使用される2つの方法はCBOW(Continuous Bag of Words)とSkip-gramです。
CBOWでは、周囲の単語を入力とし、中央の単語を予測することを目的としています。対照的に、Skip-gramでは、中央の単語を入力とし、その左右に出現する単語を予測しようとします。ただし、これらの方法の詳細については深入りしません。これらのアプローチは、テキストデータの膨大なコンテキストを分析して、単語間の関係を捉える表現である埋め込みを提供しています。
もし埋め込みについてもっと知りたい場合は、インターネット上には豊富な情報があります。ただし、視覚的かつステップバイステップのガイドを希望する場合は、Josh Starmer氏による「Word Embedding and Word2Vec」のStatQuestを視聴すると役立つかもしれません。
埋め込みモデルに戻る
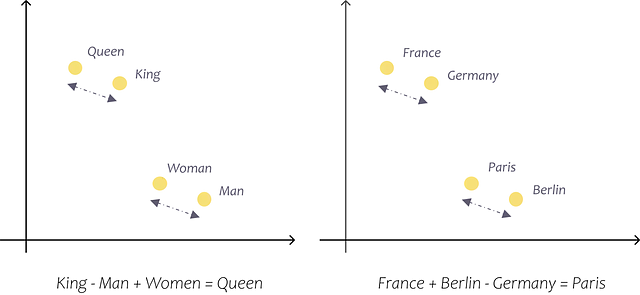
2次元の埋め込み空間で単純な例を使って説明したことは、より大きなモデルにも当てはまります。たとえば、標準のWord2Vecベクトルは300次元であり、OpenAIのAdaモデルは1536次元です。これらの事前学習済みのベクトルを使用することで、単語間の関係と意味を精度良く捉え、計算を行うことができます。たとえば、これらのベクトルを使用することで、フランス+ベルリン−ドイツ=パリ、faster + warm − fast = warmerといった計算ができます(Tazzyman、n.d.)。
次に、OpenAI APIを使用して、OpenAIのLLMsだけでなく、埋め込みモデルを活用したいと思います。
注意:埋め込みモデルとLLMsの違いは、埋め込みモデルが単語やフレーズのベクトル表現を作成し、その意味や関係を捉えることに焦点を当てるのに対し、LLMsは提供されたプロンプトやクエリに基づいて、一貫性のある文脈に即したテキストを生成するためにトレーニングされた多目的モデルであることです。
OpenAIの埋め込みモデル
OpenAIのさまざまなLLMと同様に、Ada、Davinci、Curie、Babbageなど、さまざまな埋め込みモデルから選択できます。その中で、Ada-002は現在最も高速で費用対効果が高いモデルであり、Davinciは一般的に最高の精度と性能を提供します。ただし、自分自身で試して使用ケースに最適なモデルを見つける必要があります。OpenAI埋め込みについて詳しく理解したい場合は、OpenAIのドキュメントを参照してください。
埋め込みモデルの目的は、テキストチャンクをベクトルに変換することです。Adaの第2世代の場合、これらのベクトルは1536の出力寸法を持ち、1536次元空間内の特定の位置または方向を表します。
OpenAIは、これらの埋め込みベクトルを次のように説明しています。
「数値的に似ている埋め込みは、意味的にも似ています。たとえば、「canine companions say」の埋め込みベクトルは、「woof」の埋め込みベクトルよりも「meow」の埋め込みベクトルにより類似している可能性があります(OpenAI、2022)。
意味的に似た単語やフレーズは、埋め込み空間内でお互いに近くなります。- OpenAIによる画像
試してみましょう。次のようにOpenAIのAPIを使用して、テキストスニペットを埋め込みに翻訳します。
import openaiprint(texts[0])embedding = openai.Embedding.create( input=texts[0].page_content, model="text-embedding-ada-002")["data"][0]["embedding"]len(embedding)
「2023年のテキスト生成言語モデル」などの最初のテキストチャンクを含むテキストを1536次元のベクトルに変換します。各テキストチャンクについてこれを行うことで、お互いに近く、より似ているテキストチャンクを1536次元空間で観察できます。
次に、ユーザーの質問をテキストチャンクと比較するために埋め込みを生成し、空間内の他のデータポイントと比較することによって、それを試してみましょう。

テキストチャンクとユーザーの質問をベクトルとして表現すると、さまざまな数学的可能性を探索する能力が得られます。2つのデータポイント間の類似性を決定するには、多次元空間内の近接性を計算する必要があります。これは距離メトリックを使用して実現されます。ポイント間の距離を計算するためのいくつかの方法があります。Maarten Grootendorstは、VoAGIのポストの1つで、それらのうち9つをまとめました。
よく使われる距離メトリックはコサイン類似度です。したがって、質問とテキストチャンクのコサイン類似度を計算してみましょう。
import numpy as npfrom numpy.linalg import norm# calculate the embeddings for the user's questionusers_question = "What is GPT-4?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")# create a list to store the calculated cosine similaritycos_sim = []for index, row in df.iterrows(): A = row.ada_embedding B = question_embedding # calculate the cosine similarity cosine = np.dot(A,B)/(norm(A)*norm(B)) cos_sim.append(cosine)df["cos_sim"] = cos_simdf.sort_values(by=["cos_sim"], ascending=False)
これで、質問に答えるためにLLMに提供するテキストチャンクの数を選択できます。
次のステップは、使用したいLLMを決定することです。
4. 使用するモデルを定義する
Langchainは、OpenAIのGPTやHuggingfaceなど、さまざまなモデルと統合を提供しています。OpenAIのGPTをLarge Language Modelとして使用することを決定した場合、最初のステップはAPIキーを定義することです。現在、OpenAIは一定数のトークンを超えると有料アカウントに切り替える必要がありますが、一定の無料使用容量も提供しています。
GoogleのようにGPTを使用して短い質問に答える場合、コストは比較的低く抑えられます。しかし、個人データなどの広範な文脈を提供する必要がある質問に回答する場合、クエリはすぐに数千のトークンを蓄積する可能性があります。それによりコストが大幅に増加します。しかし、心配しないでください、コスト制限を設定できます。
トークンとは何ですか?
簡単に言えば、トークンとは単語または単語のグループです。しかし、英語では、動詞の時制、複数形、または複合語など、単語に異なる形がある場合があります。これを扱うために、サブワードトークン化を使用することができます。これは、単語をそのルート、接頭辞、接尾辞、およびその他の言語要素などの小さな部分に分解することです。例えば、単語「tiresome」は「tire」と「some」に分割でき、一方、「tired」は「tire」と「d」に分割できます。これにより、「tiresome」と「tired」が同じルートを共有し、類似の派生を持つことが認識できます。(Wang、2023)
OpenAIは、トークンが何であるかを理解するためのトークナイザーをウェブサイトで提供しています。OpenAIによると、1つのトークンは一般的な英語のテキストの場合、テキストの約4文字に対応します。これは、おおよそ3/4の単語に相当します(つまり、100トークン≈75単語)。トークナイザーアプリをOpenAIのウェブサイトで見つけることができ、実際に何がトークンとしてカウントされるかを知ることができます。
使用量制限を設定する
コストを心配している場合は、OpenAIユーザーポータルのオプションで月額コストを制限することができます。
APIキーはOpenAIのユーザーアカウントで見つけることができます。最も簡単な方法は、Googleで「OpenAI APIキー」と検索することです。これにより、新しいキーを作成するための設定ページに直接移動することができます。
Pythonで使用する場合、キーを環境変数として保存する必要があります。環境変数の名前は「OPENAI_API_KEY」とします:
import osos.environment["OPENAI_API_KEY"] = "testapikey213412"モデルを定義する際には、いくつかの設定を行うことができます。OpenAI Playgroundは、使用する設定を決定する前に、さまざまなパラメーターで少し遊ぶことができます:
Playground WebUIの右側には、LLMの出力に影響を与えるOpenAIによって提供されたいくつかのパラメーターがあります。モデル選択と温度という2つのパラメーターを探索する価値があります。
さまざまなモデルから選択できるオプションがあります。Text-davinci-003モデルは現在、最も大きく、最も強力です。一方、Text-ada-001のようなモデルは、より小さく、より速く、よりコスト効果が高いです。
以下に、OpenAIの価格表の概要を示します。Adaは、最も強力なモデルであるDavinciに比べて安価です。したがって、Adaのパフォーマンスが要件を満たす場合、費用を節約するだけでなく、より短い応答時間を実現できます。
Davinciを使用して始めて、Adaでも十分な結果が得られるかどうかを評価できます。
では、Jupyter Notebookで試してみましょう。Langchainを使用してGPTに接続しています。
from langchain.llms import OpenAIllm = OpenAI(temperature=0.7)すべての属性を含むリストを表示するには、__dict__を使用します:
llm.__dict__
特定のモデルを指定しない場合、langchainコネクタはデフォルトで「text-davinci-003」を使用します。
これで、Pythonでモデルを直接呼び出すことができます。単にllm関数を呼び出し、プロンプトを入力します。

今、GPTに一般的な人間の知識に関する何でも尋ねることができます。

GPTは、トレーニングデータに含まれていないトピックに関しては、限られた情報しか提供できません。これには、一般に利用できない特定の詳細や、トレーニングデータが最後に更新された後に発生したイベントなどが含まれます。

では、モデルが現在の出来事に関する質問に答えられるようにするにはどうすればよいでしょうか?
前述したように、方法があります。プロンプトに必要な情報を与える必要があります。
英国の現在の首相についての質問に答えるために、「英国の首相」のWikipedia記事からプロンプトに必要な情報を与えます。プロセスを要約すると、以下のようになります:
- 記事を読み込む
- テキストをテキストチャンクに分割する
- テキストチャンクの埋め込みを計算する
- すべてのテキストチャンクとユーザーの質問の類似性を計算する
import requestsfrom bs4 import BeautifulSoupfrom langchain.text_splitter import RecursiveCharacterTextSplitterimport numpy as npfrom numpy.linalg import norm##################################################################### ドキュメントを読み込み##################################################################### スクレイピングするWikipediaページのURLurl = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'# URLにGETリクエストを送信response = requests.get(url)# HTMLコンテンツをBeautifulSoupで解析soup = BeautifulSoup(response.content, 'html.parser')# ページのすべてのテキストを取得text = soup.get_text()##################################################################### テキストを分割する####################################################################text_splitter = RecursiveCharacterTextSplitter( # チャンクサイズを非常に小さく設定して、表示するだけ。 chunk_size = 100, chunk_overlap = 20, length_function = len,)texts = text_splitter.create_documents([text])for text in texts: text_chunks.append(text.page_content)##################################################################### 埋め込みを計算する####################################################################df = pd.DataFrame({'text_chunks': text_chunks})# テキストチャンクのリストを作成するtext_chunks=[]for text in texts: text_chunks.append(text.page_content)# text-embedding-adaモデルから埋め込みを取得するdef get_embedding(text, model="text-embedding-ada-002"): text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))##################################################################### ユーザーの質問に対する類似性を計算する##################################################################### ユーザーの質問の埋め込みを計算するusers_question = "Who is the current Prime Minister of the UK?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")次に、ユーザーの質問に最も類似したテキストチャンクを見つけてみましょう:
from langchain import PromptTemplatefrom langchain.llms import OpenAI# ユーザーの質問の埋め込みを計算するusers_question = "Who is the current Prime Minister of the UK?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")# 計算されたコサイン類似度を保存するリストを作成するcos_sim = []for index, row in df.iterrows(): A = row.ada_embedding B = question_embedding # コサイン類似度を計算する cosine = np.dot(A,B)/(norm(A)*norm(B)) cos_sim.append(cosine)df["cos_sim"] = cos_simdf.sort_values(by=["cos_sim"], ascending=False)
テキストチャンクはかなり乱雑に見えますが、GPTが処理できるかどうかを確認してみましょう。
関連する情報を保持しているテキストセグメントを特定したので、モデルが質問に答えられるかどうかをテストできます。これを実現するには、モデルに対して明確にタスクを伝えるようにプロンプトを構築する必要があります。
5. プロンプトテンプレートを定義する
必要な情報を含むテキストスニペットを持っているので、プロンプトを構築する必要があります。プロンプト内で、モデルが質問に答えるための希望するモードを指定する必要があります。モードを定義すると、LLMに回答を生成するための希望する動作スタイルを指定しています。
LLMはさまざまなタスクに利用できます。以下は、可能性の幅広い例のいくつかです:
- 要約:「このテキストを3段落にまとめ、役員向けに要約してください:[TEXT]」
- 知識抽出:「この記事に基づいて:[TEXT]、家を購入する前に人々が考慮すべきことは何ですか?」
- コンテンツの作成(メール、メッセージ、コードなど):「プロジェクトのドキュメントの更新をジェーンに依頼するメールを書いてください。非公式で友好的なトーンを使用してください。」
- 文法とスタイルの改善:「これを標準的な英語に修正し、トーンを友好的なものに変更してください:[TEXT]」
- 分類:「各メッセージをサポートチケットのタイプとして分類してください:[TEXT]」
この例では、Wikipediaからデータを抽出して、ユーザーとのやり取りをチャットボットのように実装する解決策を実装したいと思います。助言に熱心で役立つヘルプデスクのエキスパートのように質問に答えるようにしたいと思います。
LLMを正しい方向に導くために、プロンプトに次の指示を追加します:
「人を助けることが大好きなチャットボットです!与えられた文脈のみを使用して、以下の質問に答えてください。わからない場合、明示的に文脈に答えがない場合は「申し訳ありませんが、お力になれません。」と言ってください。」
これにより、GPTがデータベースに格納された情報のみを利用することができる制限が設定されます。この制限により、チャットボットが応答を生成するために依存したソースを提供することができ、トレーサビリティと信頼性の確立に不可欠です。さらに、信頼性の低い情報を生成する問題に対処し、意思決定のために企業で利用できる回答を提供することができます。
文脈として、最も類似度の高い上位50個のテキストチャンクを使用しています。通常、1〜2つのテキストパッセージでほとんどの質問に回答できるため、テキストチャンクのサイズを大きくする方が良かったと思われます。ただし、ユースケースに最適なサイズを決定することは、あなた次第です。
from langchain import PromptTemplatefrom langchain.llms import OpenAI# 使用するLLMを定義するllm = OpenAI(temperature=1)# ユーザーの質問の埋め込みを計算するusers_question = "Who is the current Prime Minster of the UK?"question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")# 計算されたコサイン類似度を格納するリストを作成するcos_sim = []for index, row in df.iterrows(): A = row.ada_embedding B = question_embedding # コサイン類似度を計算する cosine = np.dot(A,B)/(norm(A)*norm(B)) cos_sim.append(cosine)df["cos_sim"] = cos_simdf.sort_values(by=["cos_sim"], ascending=False)# プロンプトの文脈を定義するために最も関連性の高いテキストチャンクを連結するcontext = ""for index, row in df[0:50].iterrows(): context = context + " " + row.text_chunks# プロンプトテンプレートを定義するtemplate = """You are a chat bot who loves to help people! Given the following context sections, answer thequestion using only the given context. If you are unsure and the answer is notexplicitly writting in the documentation, say "Sorry, I don't know how to help with that."Context sections:{context}Question:{users_question}Answer:"""prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])# プロンプトテンプレートを埋めるprompt_text = prompt.format(context = context, question=users_question)llm(prompt_text)この特定のテンプレートを使用することで、文脈とユーザーの質問をプロンプトに組み込みます。生成された応答は以下の通りです:

驚くべきことに、この単純な実装でも満足できる結果が得られたようです。イギリスの首相に関するいくつかの質問をシステムに対して行い、その結果を確認してみましょう。すべてを変更せずに、ユーザーの質問だけを置き換えます:
users_question = "Who was the first Prime Minister of the UK?"
ある程度機能しているようです。しかし、今後の目標は、この遅いプロセスを堅牢で効率的なものに変換することです。これを実現するために、ベクトルストアに埋め込みとインデックスを格納するインデックスステップを導入します。これにより、全体的なパフォーマンスが向上し、応答時間が短縮されます。
6. ベクトルストア(ベクトルデータベース)の作成
ベクトルストアは、ベクトルとして表現できる大量のデータを効率的に格納および検索するために最適化されたデータストアの一種です。これらのタイプのデータベースは、類似性の測定やその他の数学的操作に基づいて、データのサブセットを効率的にクエリおよび取得することができます。
テキストデータをベクトルに変換することは最初のステップですが、私たちのニーズには十分ではありません。ベクトルをデータフレームに格納し、クエリを受け取るたびに単語間の類似度をステップバイステップで検索する場合、全体的なプロセスは非常に遅くなります。
埋め込みデータを効率的に検索するためには、それらをインデックスする必要があります。インデックスは、ベクトルデータベースの2番目の重要な構成要素です。インデックスは、クエリとベクトルストア内の最も関連のあるドキュメントまたはアイテムをマップする方法を提供しますが、すべてのクエリとすべてのドキュメントの類似度を計算する必要はありません。
近年、多数のベクトルストアがリリースされています。特にLLMsの分野では、ベクトルストアに関する注目が爆発的に増加しています。

さて、ここで1つを選んで、私たちのユースケースに試してみましょう。前のセクションで行ったことに似て、再び埋め込みを計算し、ベクトルストアに格納しています。これには、LangChainとchromaから適切なモジュールを使用しています。
- ユーザーの質問に答えるために使用するデータを収集してください:
import requestsfrom bs4 import BeautifulSoupfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.vectorstores import Chromafrom langchain.document_loaders import TextLoader# スクレイピングしたいWikipediaページのURLurl = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'# URLにGETリクエストを送信response = requests.get(url)# HTMLコンテンツをBeautifulSoupを使用してパースsoup = BeautifulSoup(response.content, 'html.parser')# ページのすべてのテキストを検索text = soup.get_text()text = text.replace('\n', '')# 新しいファイルを書き込みモードで開き、ファイルオブジェクトを変数に格納するwith open('output.txt', 'w', encoding='utf-8') as file: # 文字列をファイルに書き込む file.write(text)2.データをロードし、データをテキストチャンクに分割する方法を定義します
from langchain.text_splitter import RecursiveCharacterTextSplitter# ドキュメントをロードwith open('./output.txt', encoding='utf-8') as f: text = f.read()# テキスト分割子を定義するtext_splitter = RecursiveCharacterTextSplitter( chunk_size = 500, chunk_overlap = 100, length_function = len,)texts = text_splitter.create_documents([text])3.テキストチャンクの埋め込みを計算して、ベクトルストア(ここではChroma)に格納するために使用する埋め込みモデルを定義します
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chroma# 埋め込みモデルを定義するembeddings = OpenAIEmbeddings()# テキストチャンクと埋め込みモデルを使用して、ベクトルストアに情報を格納するdb = Chroma.from_documents(texts, embeddings)4.ユーザーの質問の埋め込みを計算し、ベクトルストア内の類似したテキストチャンクを検索し、それらを使用してプロンプトを構築します
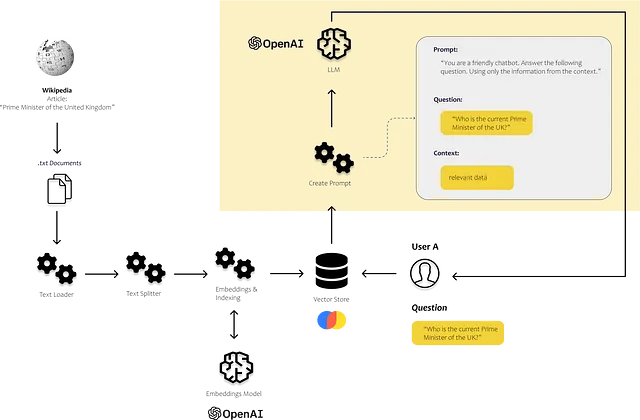
from langchain.llms import OpenAIfrom langchain import PromptTemplateusers_question = "イギリスの現在の首相は誰ですか?"# ベクトルストアを使用して類似したテキストチャンクを検索するresults = db.similarity_search( query=user_question, n_results=5)# プロンプトテンプレートを定義するtemplate = """あなたは人々を助けることが大好きなチャットボットです! 次のコンテキストセクションが与えられた場合、指定されたコンテキストだけを使用して質問に答えてください。ドキュメントに明示的に書かれていない場合は、「すみません、それについてはわかりません。」と言ってください。コンテキストのセクション:{context}質問:{users_question}回答:"""prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])# プロンプトテンプレートに情報を埋め込むprompt_text = prompt.format(context = results, users_question = users_question)# 定義されたLLMを使用してテキストを生成するllm(prompt_text)
概要
私たちのLLMがデータに関する質問を分析して回答するために、通常はモデルをファインチューニングしません。代わりに、ファインチューニングのプロセスでは、モデルが特定のタスクに効果的に応答する能力を向上させることを目的として、新しい情報を教えるのではなく、モデルの能力を改善します。
Alpaca 7Bの場合、LLM(LLaMA)はチャットボットのように振る舞うようにファインチューニングされました。モデルの応答を改善することに重点が置かれ、完全に新しい情報を教えることはありませんでした。
ですから、私たち自身のデータに関する質問に答えるために、コンテキストインジェクションアプローチを使用しています。コンテキストインジェクションを使用したLLMアプリを作成することは、比較的簡単なプロセスです。主な課題は、ベクトルデータベースに格納されるデータを整理してフォーマットすることです。これにより、文脈的に類似した情報を効率的に取得し、信頼性の高い結果を得ることができます。
本記事の目的は、埋め込みモデル、ベクトルストア、LLMを使用してユーザーのクエリを処理するための最小限のアプローチを示すことです。これらの技術がどのように協力して、絶えず変化する事実に対しても関連性の高い正確な回答を提供できるかを示しています。
このストーリーが気に入りましたか?
- 新しいストーリーが公開されたときに通知を受け取るには、無料で購読してください。
- 1か月に3つ以上の無料ストーリーを読みたいですか? – VoAGI会員になって、1か月5ドルで購読してください。サインアップ時に私の紹介リンクを使用することで、あなたをサポートすることができます。追加費用はかかりません。
LinkedInで私に連絡することもできます!
参考文献
AssemblyAI(監督)。 (2022年1月5日)。 単語埋め込みの完全な概要。 https://www.youtube.com/watch?v=5MaWmXwxFNQ
Grootendorst、M.(2021年12月7日)。 データサイエンスの9つの距離測定。 VoAGI。 https://towardsdatascience.com/9-distance-measures-in-data-science-918109d069fa
Langchain。 (2023)。 LangChainへようこそ – 🦜🔗 LangChain 0.0.189。 https://python.langchain.com/en/latest/index.html
Nelson、P.(2023)。 検索と非構造化データ分析のトレンド|
Accenture。 検索とコンテンツ分析ブログ。 https://www.accenture.com/us-en/blogs/search-and-content-analytics-blog/search-unstructured-data-analytics-trends
OpenAI。 (2022)。 テキストとコードの埋め込みの紹介。 https://openai.com/blog/introducing-text-and-code-embeddings
OpenAI(監督)。 (2023年3月14日)。 GPT-4で何ができるのか? https://www.youtube.com/watch?v=oc6RV5c1yd0
Porsche AG。 (2023年5月17日)。 ChatGPT&エンタープライズナレッジ:“ビジネスユニットにチャットボットを作成するにはどうすればよいですか?” #NextLevelGermanEngineering。 https://medium.com/next-level-german-engineering/chatgpt-enterprise-knowledge-how-can-i-create-a-chatbot-for-my-business-unit-4380f7b3d4c0
Tazzyman、S.(2023)。 ニューラルネットワークモデル。 NLP-Guidance。 https://moj-analytical-services.github.io/NLP-guidance/NNmodels.html
Wang、W.(2023年4月12日)。 トランスフォーマーベースのモデルの詳細な調査。 VoAGI。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






