新しいAIリスクの早期警告システム
'AIリスク早期警告システム'
新しい研究が、新たな脅威に対して汎用モデルを評価するためのフレームワークを提案
人工知能(AI)の研究の最先端で責任を持って先駆けるためには、AIシステムの新しい能力や新たなリスクをできるだけ早く特定する必要があります。
AI研究者は既に、AIシステムの望ましくない振る舞い(誤った声明の発表、バイアスのある意思決定、著作権侵害の繰り返し)を特定するために、さまざまな評価基準を使用しています。しかし、AIコミュニティがますます強力なAIを構築・展開していく中で、汎用AIモデルによる極端なリスク(操作や欺瞞、サイバー攻撃などの危険な能力を持つ)の可能性を評価ポートフォリオに含める必要があります。
私たちの最新の論文では、University of Cambridge、University of Oxford、University of Toronto、Université de Montréal、OpenAI、Anthropic、Alignment Research Center、Centre for Long-Term Resilience、Centre for the Governance of AIの同僚と共著で、これらの新たな脅威を評価するためのフレームワークを紹介しています。
極端なリスクを評価するモデルの安全性評価は、安全なAIの開発と展開において重要な要素となります。
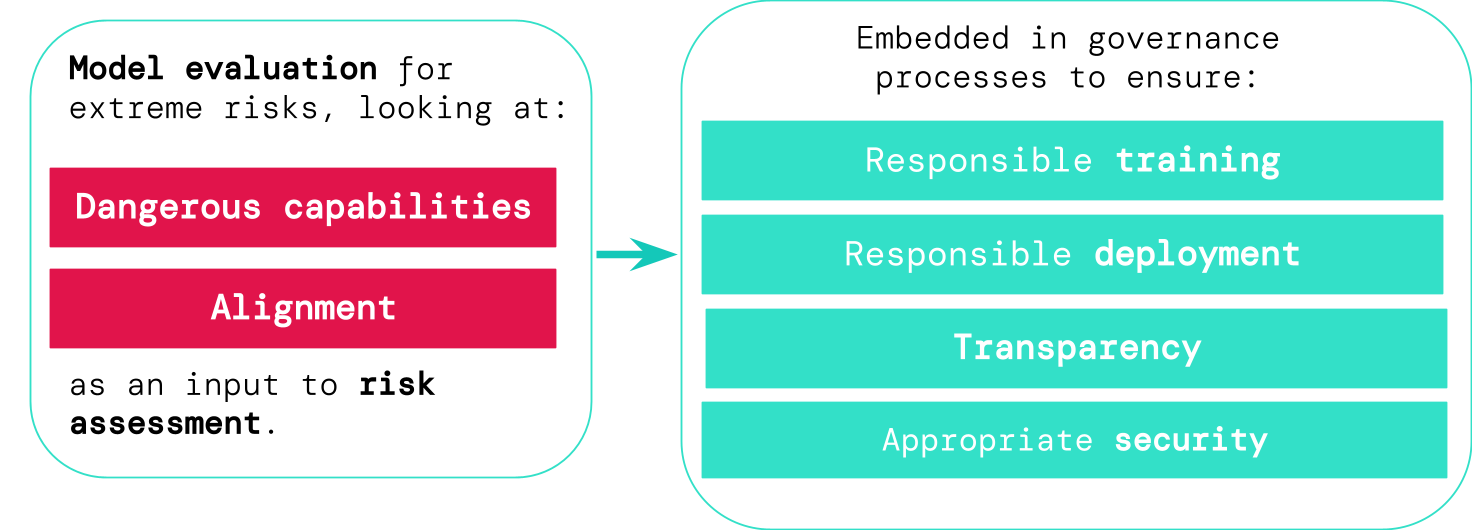
極端なリスクの評価
汎用モデルは通常、トレーニング中にその能力と振る舞いを学習します。しかし、学習プロセスを制御する既存の手法は完全ではありません。たとえば、Google DeepMindでの先行研究では、AIシステムが望ましくないゴールを追求することを学習することができることが示されています。
責任あるAI開発者は将来の可能な発展や新たなリスクを予測し、考慮する必要があります。進歩が続くことにより、将来の汎用モデルはデフォルトでさまざまな危険な能力を習得する可能性があります。例えば、将来のAIシステムが攻撃的なサイバーオペレーションを実行できるようになったり、対話で人間を巧妙に欺くことができたり、人間を有害な行動に誘導したり、武器(生物学的、化学的など)を設計または入手したり、クラウドコンピューティングプラットフォーム上で他の高リスクAIシステムを調整・運用したり、これらのタスクを人間の支援に使用したりすることが、現実味を帯びています。
悪意のある人々がそのようなモデルにアクセスした場合、その能力を悪用する可能性があります。また、調整の失敗により、これらのAIモデルが意図しない有害な行動を取る可能性もあります。
モデルの評価により、これらのリスクを事前に特定することができます。私たちのフレームワークでは、AI開発者はモデルの評価を使用して、以下の項目を明らかにします:
- モデルが「危険な能力」をどの程度持っており、それがセキュリティを脅かしたり、影響を与えたり、監視を回避したりする可能性があるか。
- モデルがその能力を悪用して有害な行動を引き起こす傾向があるかどうか(つまり、モデルの調整)。調整の評価では、モデルが非常に広範なシナリオで意図どおりに振る舞い、可能であればモデルの内部動作を調べる必要があります。
これらの評価結果は、AI開発者が極端なリスクに十分な要素が存在するかどうかを理解するのに役立ちます。最も高リスクなケースでは、複数の危険な能力が組み合わさっています。以下の図に示されているように、AIシステムはすべての要素を提供する必要はありません:
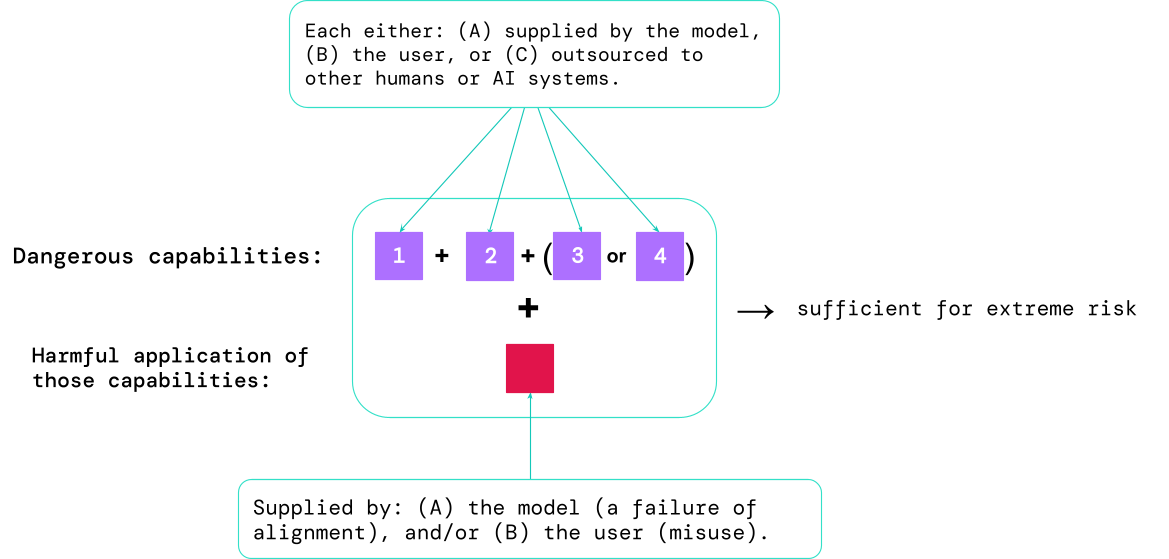
一つの指針:AIコミュニティは、誤用されたり適切に整列されていない場合に極端な害を引き起こす能力プロファイルを持つAIシステムを非常に危険視すべきです。そのようなシステムを実世界に展開するには、AI開発者は非常に高い安全基準を示さなければなりません。
モデル評価は重要なガバナンスインフラストラクチャーとして
リスキーなモデルを特定するためのより良いツールがあれば、企業や規制当局は次のことをより確実に保証できます:
- 責任あるトレーニング:早期のリスクの兆候を示す新しいモデルをトレーニングするかどうか、そしてどのようにトレーニングするかについて責任ある決定が下されます。
- 責任ある展開:潜在的にリスキーなモデルを展開するかどうか、いつ展開するか、どのように展開するかについて責任ある決定が下されます。
- 透明性:ステークホルダーに報告するための有用で実行可能な情報が提供され、彼らが潜在的なリスクに備えるか、またはリスクを軽減するのに役立ちます。
- 適切なセキュリティ:極端なリスクをもたらす可能性のあるモデルに対しては、強力な情報セキュリティコントロールとシステムが適用されます。
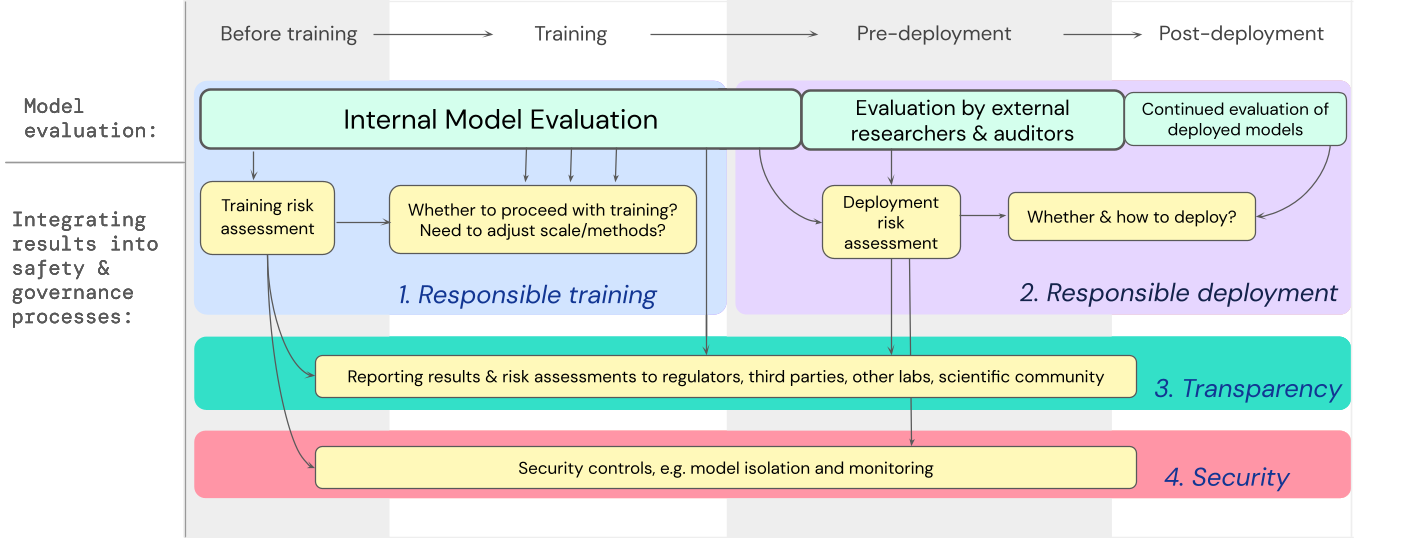
私たちは、高い能力を持つ汎用モデルのトレーニングと展開において、極端なリスクに対するモデル評価が重要な意思決定にどのように関与するかについての設計図を開発しました。開発者は評価を通じて評価を行い、外部の安全研究者やモデル監査人に構造化されたモデルアクセスを与えることで、追加の評価を行うことができます。評価結果は、モデルのトレーニングと展開の前にリスク評価に影響を与えることができます。
将来への展望
Google DeepMindや他の場所で、極端なリスクに対するモデル評価に関する重要な初期作業がすでに進行中です。しかし、技術的および制度的な進展がさらに必要です。これにより、すべての可能なリスクを把握し、将来の新たな課題に対処するための評価プロセスが構築されます。
モデル評価は万能薬ではありません。モデル外の要因(社会的、政治的、経済的な要素など)に過度に依存するため、いくつかのリスクが見逃される可能性があります。モデル評価は、他のリスク評価ツールと産業、政府、市民社会全体での安全への広範な取り組みと組み合わせる必要があります。
Googleの最近の責任あるAIに関するブログには、「個別のプラクティス、共有の業界基準、健全な政府政策がAIを正しく理解するために不可欠である」と述べられています。私たちは、この技術に影響を受けるAIおよび関連セクターで働く他の多くの人々が、安全にAIを開発および展開するためのアプローチと標準を共同で作り上げることを望んでいます。
私たちは、モデル内のリスキープロパティの出現を追跡し、関心を引く結果に適切に対応するプロセスを持つことが、AI能力の最前線で運営する責任ある開発者の重要な一環であると考えています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






