AI WebTVの構築
AI WebTVの構築
AI WebTVは、自動ビデオと音楽合成の最新の進歩を紹介するための実験的なデモです。
👉 AI WebTVスペースにアクセスしてストリームを視聴できます。
モバイルデバイスを使用している場合は、Twitchのミラーからストリームを視聴できます。

- 「AIオートメーションエージェンシーのリードを増やす方法(月間100件以上のミーティング)」
- ベイズハイパーパラメータ調整を使って効果的に回帰モデルを最適化する
- 共和分対スパリアス相関:正確な分析のための違いを理解する
AI WebTVの目的は、ZeroscopeやMusicGenなどのオープンソースのテキストからビデオを生成するモデルを使用して、エンターテイニングでアクセスしやすい方法でビデオをデモすることです。
これらのオープンソースモデルは、Hugging Faceハブで見つけることができます:
- ビデオ用: zeroscope_v2_576とzeroscope_v2_XL
- 音楽用: musicgen-melody
個々のビデオシーケンスは意図的に短く作られており、WebTVは芸術方向性やプログラミングを持つ実際のショーではなく、テックデモ/ショーリールとして見るべきです。
AI WebTVは、ビデオショットのシーケンスを取り、テキストからビデオを生成するモデルに渡してテイクのシーケンスを生成することで動作します。
さらに、人間によって書かれた基本テーマとアイデアは、LLM(この場合はChatGPT)を通じて渡され、各ビデオクリップごとにさまざまな個別のプロンプトを生成するために使用されます。
以下は、AI WebTVの現在のアーキテクチャのダイアグラムです:
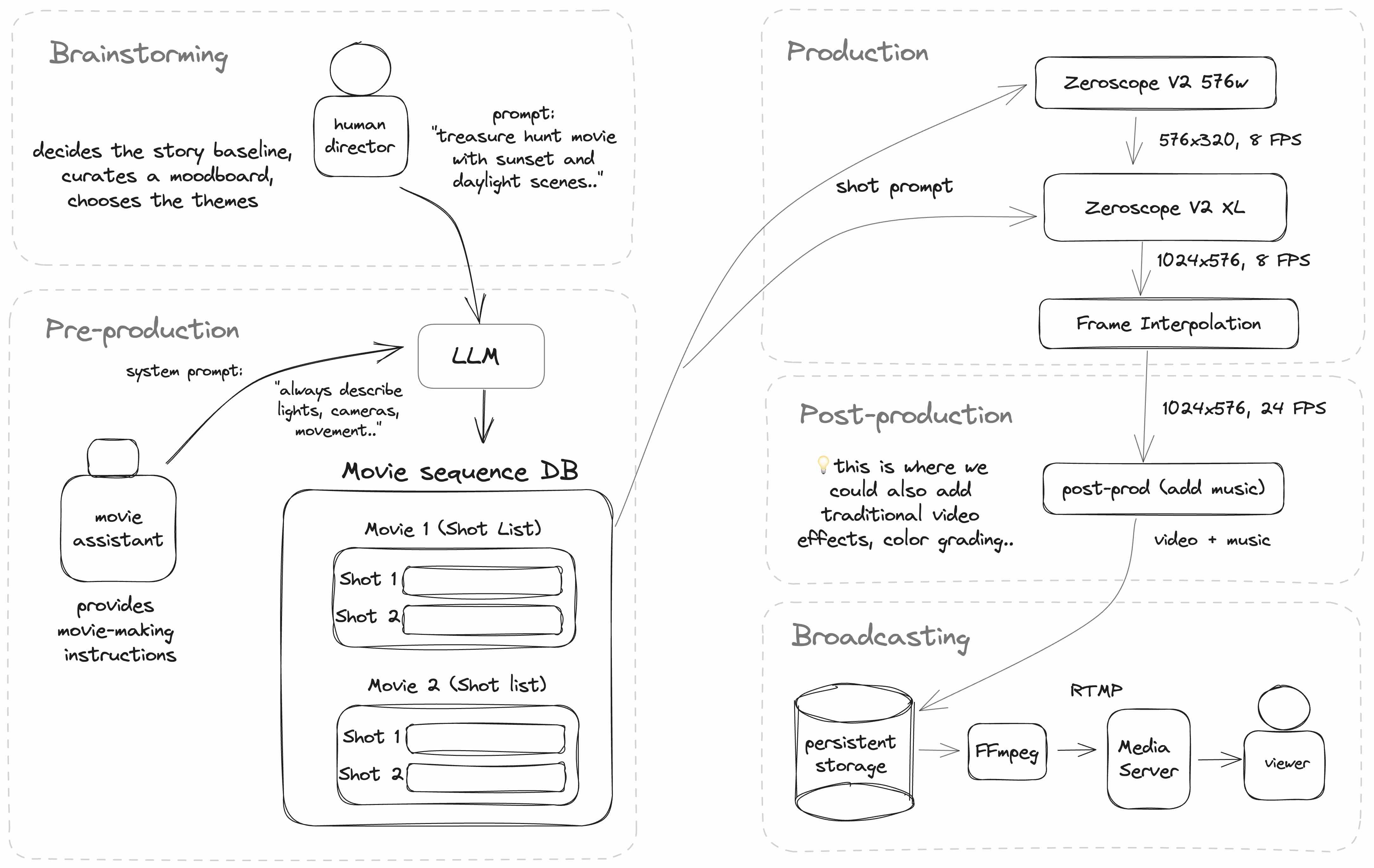
WebTVはNodeJSとTypeScriptで実装されており、Hugging Faceでホストされているさまざまなサービスを使用しています。
テキストからビデオへのモデル
中心となるビデオモデルはZeroscope V2で、ModelScopeに基づいています。
Zeroscopeは、2つのパートで構成されており、次のように連鎖させることができます:
- 最初のパスでは、zeroscope_v2_576を使用して576×320のビデオクリップを生成します
- オプションの2番目のパスでは、zeroscope_v2_XLを使用してビデオを1024×576にアップスケールします
👉 生成とアップスケールの両方に同じプロンプトを使用する必要があります。
ビデオチェーンの呼び出し
クイックプロトタイプを作成するために、WebTVはGradioを実行している2つの重複したHugging Face SpacesからZeroscopeを実行します。これは、@gradio/client NPMパッケージを使用して呼び出されます。元のスペースは以下で見つけることができます:
- @hystsによるzeroscope-v2
- @fffiloniによるZeroscope XL
コミュニティによって展開された他のスペースも、HubでZeroscopeを検索すれば見つけることができます。
👉 パブリックスペースは過密になり、いつでも一時停止される可能性があります。独自のシステムを展開する場合は、これらのスペースを複製して独自のアカウントで実行してください。
Spaceでホストされたモデルの使用
Gradioを使用しているSpaceは、REST APIを公開する機能を持っており、それをNodeから@gradio/clientモジュールを使用して呼び出すことができます。
以下は例です:
import { client } from "@gradio/client"
export const generateVideo = async (prompt: string) => {
const api = await client("*** SPACEのURL ***")
// "run()"関数をパラメータの配列とともに呼び出す
const { data } = await api.predict("/run", [
prompt,
42, // シード値
24, // nbFrames
35 // nbSteps
])
const { orig_name } = data[0][0]
const remoteUrl = `${instance}/file=${orig_name}`
// ファイルはダウンロードしてローカルに保存できます
}後処理
個々のテイク(ビデオクリップ)がアップスケールされた後、大きな動きのためのフレーム補間アルゴリズムであるFILM(Frame Interpolation for Large Motion)に渡されます:
- 元のリンク: ウェブサイト, ソースコード
- Hugging Face上のモデル: /frame-interpolation-film-style
- @fffiloniによるvideo_frame_interpolationという複製可能なHugging Face Space
後処理では、MusicGenで生成された音楽も追加されます:
- 元のリンク:ウェブサイト、ソースコード
- Hugging Face Spaceで複製できるもの:MusicGen
ストリームのブロードキャスト
注意:ビデオストリームを作成するために使用できる複数のツールがあります。AI WebTVでは、現在、mp4ビデオファイルとm4aオーディオファイルから作成されたプレイリストを読み込むためにFFmpegを使用しています。
以下はそのようなプレイリストを作成する例です:
import { promises as fs } from "fs"
import path from "path"
const allFiles = await fs.readdir("** VIDEO FOLDERのパス **")
const allVideos = allFiles
.map(file => path.join(dir, file))
.filter(filePath => filePath.endsWith('.mp4'))
let playlist = 'ffconcat version 1.0\n'
allFilePaths.forEach(filePath => {
playlist += `file '${filePath}'\n`
})
await fs.promises.writeFile("playlist.txt", playlist)これにより、次のようなプレイリストの内容が生成されます:
ffconcat version 1.0
file 'video1.mp4'
file 'video2.mp4'
...次に、このプレイリストを再度読み込み、FLVストリームをRTMPサーバーに送信するために再度FFmpegが使用されます。FLVは古い形式ですが、低遅延のためにリアルタイムストリーミングの世界でまだ人気があります。
ffmpeg -y -nostdin \
-re \
-f concat \
-safe 0 -i channel_random.txt -stream_loop -1 \
-loglevel error \
-c:v libx264 -preset veryfast -tune zerolatency \
-shortest \
-f flv rtmp://<サーバー>FFmpegにはさまざまな設定オプションがあります。詳細については公式ドキュメントを参照してください。
RTMPサーバーには、NGINX-RTMPモジュールなどのGitHubでオープンソースの実装があります。
AI WebTV自体はnode-media-serverを使用しています。
💡 TwitchのRTMPエントリーポイントのいずれかに直接ストリーミングすることもできます。詳細についてはTwitchのドキュメントをご覧ください。
以下は生成されたコンテンツのいくつかの例です。
最初に注意する点は、Zeroscope XLの2回目のパスを適用することで画像の品質が大幅に向上することです。フレーム補間の影響も明確に見えます。
キャラクターとシーンの構成
プロンプト:メガネとフードを着用したプログラマーのラマが、コードの行が表示される画面を真剣に見つめている、薄暗い部屋でのフォトリアルな映画、Canon EOS、アンビエントライティング、高詳細度、シネマティック、artstationで話題
プロンプト:グループ化された食べ物のキャラクターがピラミッドを形成する3Dレンダリングアニメーションで、バナナが上に立って勝ち誇っています。キャラメルコットンキャンディのような雲とチョコレートの道がある街、Pixarのスタイル、CGI、アンビエントライティング、直射日光、豊かなカラースキーム、超リアル、シネマティック、フォトリアル
プロンプト:鋭い目でカメラを見つめる、アンビエントライティングで高いコントラストのシルエットを作り出す、IMAXカメラ、高詳細度、シネマティック効果、ゴールデンアワー、フィルムグレインの赤いキツネの至近距離
動的なシーンのシミュレーション
テキストからビデオへのモデルの本当に魅力的な点の1つは、訓練された現象をエミュレートする能力です。
大規模な言語モデルとその人間の反応を模倣する説得力のあるコンテンツを合成する能力については、既に見てきましたが、ビデオに適用すると新たな次元になります。
ビデオモデルは、液体、人、動物、または車両などの動くオブジェクトを含むシーンの次のフレームを予測します。現時点では、このエミュレーションは完全ではありませんが、将来のモデル(より大規模または専門化されたデータセットで訓練されるなど)の精度を評価すること、およびエージェントの振る舞いをシミュレートする能力を評価することは興味深いでしょう。
プロンプト:陽の光がシーンを照らす花の周りを元気に飛び回る蜂のシネマティック映画のショット、4k IMAXでキャプチャーされた、柔らかいボケの背景付き
プロンプト:急流の川でサケを捕まえるグリズリーベアのダイナミックな映像。水しぶきを強調した環境光、低いアングル、IMAXカメラ、4Kムービーの品質、ゴールデンアワー、フィルムグレイン。
プロンプト:カリフォルニアの海岸での静かな朝の空撮映像。波が岩の岸に優しく打ち寄せる様子。鮮やかな色彩で海岸が照らされる驚くべき日の出。DJI Phantom 4 Proで美しく捉えられた風景の色彩と質感が柔らかな朝の光で生き生きと蘇る。フィルムグレイン、シネマティック、IMAX、ムービー。
💡 これらの能力が将来的にはもっと探求されることは興味深い。例えば、より多様な現象をカバーするより大規模なビデオデータセットでビデオモデルのトレーニングを行うなど。
スタイリングとエフェクト
プロンプト:帽子をかぶった友好的なブロッコリーキャラクターがキャンディでいっぱいの街の通りを歩く3Dレンダリングされたビデオ。明るい太陽と青い空、Pixarのスタイル、シネマティック、写実的、ムービー、環境光、自然光、CGI、広角ビュー、昼間、超リアル。
プロンプト:夜明けの山岳地帯での宇宙飛行士とラマのシネマティックな映画の撮影。柔らかな色彩がかった風景の山々、朝霧、毛皮に光る露、がんばったNASAのスーツ、Canon EOS、高詳細なスキン、壮大な構図、高品質、4K、Artstationで話題、美しい。
プロンプト:パンダと黒猫が小舟で流れる川を進むStudio Ghibliスタイル。シネマティックで美しい構図。ボートに追従するIMAXカメラパンニング。高品質、シネマティック、ムービー、霧効果、フィルムグレイン、Artstationで話題。
失敗例
方向の誤り: モデルは時々移動と方向に問題を抱えます。例えば、ここではクリップが逆再生されているように見えます。また、修飾キーワードの「緑」も考慮されていませんでした。
プロンプト:緑のカボチャが釘のベッドに落ちる映画。チャンクが飛び散るスローモーエクスプロージョン、劇的な照明に追加された環境の霧。IMAXカメラで撮影された8Kウルトラハイデフィニション、高品質、Artstationで話題。
リアルなシーンでのレンダリングエラー: 動く垂直線や波などのアーティファクトが見られることがあります。これの原因は不明ですが、使用されたキーワードの組み合わせによるものかもしれません。
プロンプト:グランドキャニオン上空を魅力的に飛ぶフィルムのショット。オレンジと赤の彫られた岩層と台地。真昼の太陽の下で深い影が燃えるような風景と対比。DJI Phantom 4 Proで撮影された広がり、質感、色彩を捉えるカメラ。フィルムグレイン、シネマティック、ムービー。
テキストやオブジェクトの挿入: モデルは時々プロンプトからの単語をシーンに挿入します。例えば、「IMAX」という単語はIMAXが映ります。プロンプトで「Canon EOS」や「ドローン映像」という言葉を使うと、それらのオブジェクトがビデオに現れることもあります。
次の例では、「ラマ」という単語がラマを挿入するだけでなく、炎の中のラマの単語も2回現れることに注目してください。
プロンプト:消防士として行動するラマの映画のシーン。消防士の制服を着たラマが劇的に炎に水を噴射する様子。混沌とした都市のシーンで撮影された映像。Canon EOS、環境光、高品質、受賞歴あり、高詳細な毛皮、シネマティック、Artstationで話題。
以下は前述の観察から導かれる早期の推奨事項です:
ビデオ固有のプロンプトキーワードの使用
Stable Diffusionで画像の特定の側面をプロンプトしない場合、服の色や昼の時間などのものはランダムになるか、中立的な昼の光などの一般的な値が割り当てられることがあります。
同様に、ビデオモデルでも特定のことについて具体的に指定する必要があります。例えば、カメラやキャラクターの移動、向き、速度、方向などです。クリエイティブな目的(アイデア生成)で指定しないこともできますが、常に望む結果を得るとは限りません(例:逆再生でアニメーションされたエンティティ)。
シーン間の一貫性の維持
複数のビデオのシーケンスを作成する予定がある場合は、各プロンプトにできるだけ多くの詳細を追加することで、異なるシーケンス間で重要な詳細(例:色)が失われることがないようにする必要があります。
💡これにより、プロンプトがZeroscope XLを使用した拡大部分の品質も向上します。
フレーム補間を活用する
フレーム補間は強力なツールであり、小さなレンダリングエラーを修正し、多くの欠陥を特徴に変えることができます。特に、アニメーションが多いシーンやカートゥーン効果が許容されるシーンでは有効です。FILMアルゴリズムは、ビデオクリップ内の前後のイベントとフレームの要素を滑らかにします。
これは、カメラがパンや回転する場合に背景を変位させるのに非常に効果的であり、また、生成後のフレーム数の制御など、スローモーション効果を作成するための創造的な自由も提供します。
AI WebTVストリームをお楽しみいただき、これがさらなる創造につながることを願っています。
初めての試みであるため、テックデモの焦点ではなかったことがいくつかあります。例えば、より長く多様なシーケンスの生成、音声の追加(効果音、対話)、複雑なシナリオの生成と編成、または言語モデルエージェントによるパイプラインの制御などです。
これらのアイデアのいくつかは、AI WebTVの将来のアップデートに取り入れられるかもしれませんが、研究者、エンジニア、ビルダーのコミュニティがどのようなことを考え出すかも楽しみにしています!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






