AI対データアナリスト:分析の未来に影響を与えるトップ6の制約
AI対データアナリスト:未来の分析に影響を与えるトップ6の制約を解説

AIはどのようなデータ分析ができるのでしょうか?
私たちは既に、ChatGPTを最も多目的なAIツールとして知っています。プラグインを使用することで、Python、R、および他の多くの言語で「機能するコード」や複雑なSQLクエリを生成することができます。これらの機能を組み合わせれば、データ分析のすべての部分にAIを利用できるでしょう。

利用例には以下のものがあります:
- クエリの実行
- データのクリーニングおよびその他の処理
- 可視化
データを扱う際には、CSVファイル向けのJulius AIや、SQLデータベース向けのBlazeSQLなどの特殊なツールが特にこの目的のために設計されています。ChatGPTとは異なり、これらのツールは使用するたびにデータのアップロードや接続、説明が必要ではありません。
ChatGPTはCSVファイルの短期分析に使用できますが、ほとんどの企業はデータをプライベートネットワーク内のSQLデータベースに保存しています。ただし、特殊なツールはこれらのセキュリティの厳しいSQLデータベースに接続し、データベースをクエリし、結果を可視化することができます。
AIはデータ分析者を置き換えることができるのでしょうか?
データ分析はデータから洞察を得ることであり、データ分析者やデータサイエンティストは必要な洞察をステークホルダーに提供するための技術スキルを持っている人々です。しかし、現在はAIツールが以前はデータ分析者とデータサイエンティストにしかできなかったいくつかのタスクを成功裏に完了させることができます。
例えば、技術スキルを持たないビジネスステークホルダーがデータをAIツールに接続し、「年間トップ3商品の月次売上をグループ化して取得」というリクエストをすることが理論的に可能です。AIはデータを取得し、可視化することもできます。ユーザーはリクエストを数秒かけて書くだけで済みます。もし同じ質問を人間の同僚にした場合、数日かかるかもしれません。

このような画像を見ると、データ分析者にとっては驚くべきことであり同時に心配なことでもありますが、データ分析者やデータサイエンティストを置き換えることはそれほど簡単ではありません。単にSQLクエリを実行して結果をグラフ化することは彼らの仕事の一部に過ぎませんし、それさえもAIには常に信頼性を持って行われるわけではありません。上記のスクリーンショットではうまく機能しているかもしれませんが、結果が正しくない場合はどうでしょうか?
AIがデータとして誤った結果を返すコードを生成してしまった場合はどうでしょうか?AIデータアナリストを使うビジネスステークホルダーは、結果が間違っていることに気づかず、コードを理解できないため、間違いに気づくことができません。
制約#2:企業情報。
通常、新しいデータアナリストが会社で働き始めると、いくつかの列や値の意味を学ばなければなりません。これはデータモデルがビジネスによって設計されたためです。一般的な知識ではほとんどのデータベースを理解するには不十分なので、データの分析には出どころを理解することが必要です。

BlazeSQLのようなAIツールでは、AIが利用するためにこの情報を含めることができますが、最新の情報を維持するためにデータアナリストやデータサイエンティストが必要です。
制約#3:時にはAIは立ち往生します。 AKA “死角”
ChatGPTが非常に基本的な質問に立ち往生する例を見たことがあるかもしれません。これらの質問は通常非常に簡単に答えられますが、AIが苦手な思考方法で推論しなければなりません。

私たちはこれらのケースを「死角」と呼び、コードを書く場合にも存在します。たとえば、SQLクエリを生成するための一般的なAIの死角は、サブクエリの使用です。AIモデルは、サブクエリ内から列を選択しようとするクエリを生成することがよくありますが、その列は実際にはサブクエリ内に存在しない場合もあります。
WITH recent_orders AS ( SELECT customer_id, MAX(order_date) AS latest_order_date FROM orders GROUP BY customer_id)SELECT customer_id, product_id, -- (This column is not defined in the subquery) latest_order_dateFROM recent_orders
間違いが指摘されても、再度試すと同じ間違いを犯すことがよくあります。
制約#4:AIモデルはあまりにも同意する
AIモデルは、あなたの間違いでさえ同意する傾向があります。これは、AIモデルが専門家の役割を果たすべきである場合には大きな問題です。専門家は、間違っているときにあなたを修正できるはずです。
制約#5:入力の長さ
人間はプロジェクトやデータベースについて数ヶ月かけて学び、重要な情報を集めるかもしれません。一方、LLMには通常「トークン制限」と呼ばれる制限があり、一定量の入力しか受け付けることができません。

この入力の長さ(または「トークン制限」)は、複雑なタスクに対して制約があります。これら数ヶ月の学習をいかにして数ページに凝縮し、AIモデルに適合させることができるでしょうか?
一般に利用可能なGPT-4のバージョンは、入力+出力の12ページで制限されています。データアナリストは数時間の会議に出席し、ドキュメンテーションやレポートを読むかもしれません。すべての出力(コードとGPT-4からの説明)は12ページに含まれるため、出力だけでなく入力も制限に含まれることに注意してください。
これは、学習や探索が多く必要な大規模なデータ分析プロジェクトは単純に実行不可能であることを意味します。
制約#6:ソフトスキル
最後になりますが、ChatGPTや他のAIチャットボットはただのチャットボットです。データプロジェクトでの人間との相互作用やソフトスキルは重要な要素です。信頼を得たり、オフィスの政治に対処したり、非言語コミュニケーションを解釈したりすることです。これらの要素は、ステークホルダーとの協力やプロジェクトの完了において重要です。
次は何ですか?
ご覧の通り、AIには完全なデータアナリストとしての能力を制限する要素がいくつかあります。上記のリストにはいくつかの主な制限が含まれていますが、実際にデータの専門家を置き換える際にはさまざまな大きなハードルが存在します。言い換えれば、心配する必要はありません、AIがあなたを置き換えることはありません!
しかし、AIは既にデータアナリストやデータサイエンティストに大きな影響を与えています。完璧ではないかもしれませんが、既に驚異的な価値を提供しています。
AIを使って仕事を速く進める
Python、SQL、またはRなどのコードを書くことは時間がかかる場合があります。これらのAIツールは100%正確ではないかもしれませんが、多くの場合は非常にうまく機能します。彼らが生成したものを短時間で確認する方が、すべてをゼロからやり直すよりも10倍速くなることがよくあります。

AIが苦手だったり、頻繁にミスをする場合は、ゼロから作り直す方が速いこともあります。他の場合では、生産性の大幅な向上はたまにのデバッグ努力に値するでしょう。重要なのは、さまざまなツールを試し、それらの強みと弱点を学び、ワークフローに統合することです。
将来についてはどうでしょうか?
事態は非常に速く進展しているため、現在の制限のいくつかは長く関係なくなるかもしれません。特にAIツールが多くの人々に使用されている今、彼らはユーザーから学んでいます。これらの対話はモデルのトレーニングに使用され、毎日何百万もの対話が行われています。
ChatGPTは史上最も急速に成長するユーザーベースを持ち、それらのユーザーベースから学んでいます。
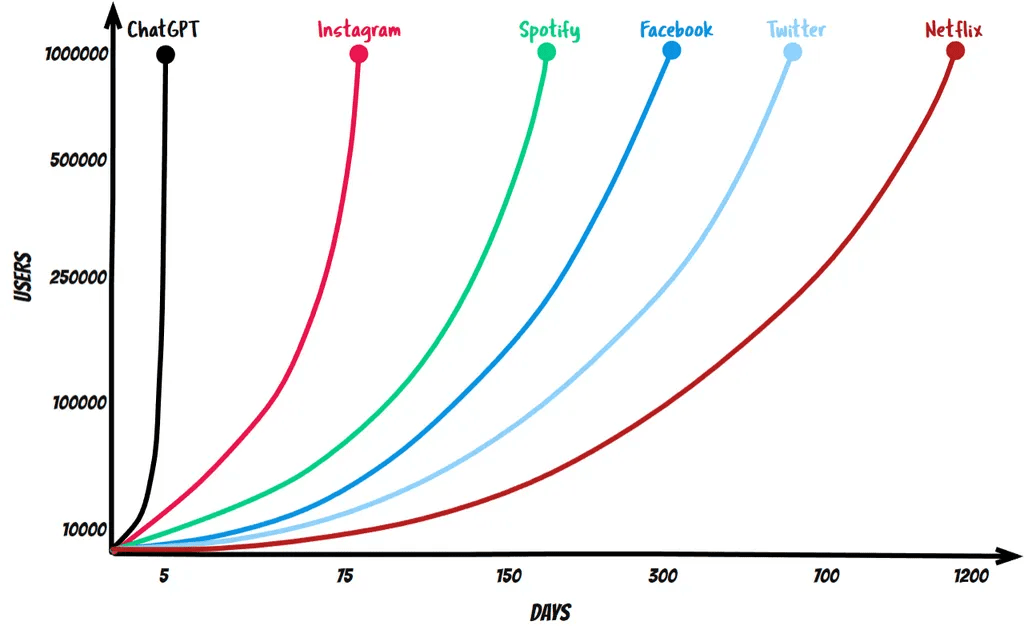
ClaudeやBardなどの競合他社が参入することで、近々大幅な改善が見込まれます。
これらの変化に備えるためには、単に新しいツールを注視し、それらと実験することです。それによって、彼らの強みと弱点を把握し、最新の技術を活用して進化に適応できるようになります。
それに関しては、注目すべきいくつかのツールがあります:
BlazeSQL(SQLデータベース用)
ChatGPT Advanced Data Analysis(csvおよびその他のファイル用)
Pandas AI(pandasライブラリに対する生成型AIの追加)
[Justus Mulli](https://www.linkedin.com/in/justus-mulli-64551889)はデータサイエンティスト兼創業者であり、金融、ヘルスケア、および電子商取引の経験を持っています。彼はデータサイエンスとAIの専門知識を活かして、さまざまな産業や職業に破壊的なAIソリューションを実装しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Data Enthusiasts向けにエキサイティングな新機能を解放するChatGPT Plus」
- スタンフォード大学とUTオースティンの研究者は、Contrastive Preference Learning (CPL)を提案します:RLHFのためのRL-Freeな方法であり、任意のMDPsとオフポリシーのデータと一緒に動作します
- 「ConvNetは復活しているのか?ウェブスケールのデータセットとビジョントランスフォーマーの性能を解明する」
- 「二つの頭を持つ分類器の使用例」
- 最新のデータを使ってファンデーションモデルを最新の状態に保つ方法は? AppleとCMUの研究者が、VLMの継続的なトレーニングのための最初のウェブスケールの時系列連続性(TiC)ベンチマークを導入しましたこれには12.7Bのタイムスタンプ付きのイメージとテキストのペアが含まれています
- 生物学的な学習から人工ニューラルネットワークへ:次は何だろうか?
- MLOps原則の紹介
