「AIの文の埋め込み、解明された」
AI sentence embedding, elucidated.
コンピュータと言語のギャップを埋める:AI文埋め込みがNLPを革新する
このブログ記事では、コンピュータが文や文章を理解する方法について解説します。このディスカッションを始めるにあたり、n-gramベクトルやTF-IDFベクトルを使って文を表現する初期の方法から時間を巻き戻してみましょう。後のセクションでは、ニューラルバッグオブワーズから文の変換器や言語モデルまで、現在見られる方法について説明します。カバーする技術は多岐にわたります。シンプルでエレガントなn-gramから旅を始めましょう。
1. N-gramベクトル
コンピュータは単語を理解することはできませんが、数値を理解することができます。そのため、コンピュータで処理する際には、単語や文をベクトルに変換する必要があります。文をベクトルとして表現する最も初期の手法の1つは、情報理論の父であるクロード・シャノンの1948年の論文にさかのぼることができます。この画期的な研究では、文は単語のn-gramベクトルとして表現されました。これはどういう意味でしょうか?
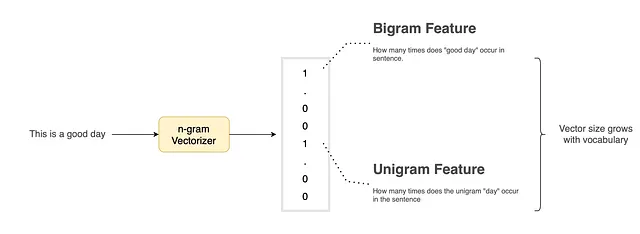
例えば、「これはいい日です」という文を考えてみましょう。この文を以下のようなn-gramに分解することができます:
- ユニグラム:これ、は、いい、日
- バイグラム:これは、はいい、いい日
- トリグラム:これはいい、はいい日
- その他もたくさんあります…
一般的には、文は構成要素のn-gramに分解され、1からnまで反復されます。ベクトルを構築する際には、このベクトル内の各数値が文中にn-gramが存在するかどうかを表します。一部の手法では、代わりに文中のn-gramの出現回数を使用することもあります。上記の図1には、文のサンプルベクトル表現が示されています。
- GPU を最大限に活用せずに LLM を微調整する
- 時系列予測における相互作用項に関する包括的なガイド
- 「3年間の経験から厳選された130の機械学習のテクニックとリソース(さらに無料のeBookも含む)」
2. TF-IDF
文や文章を表現する別の初期の人気手法は、文のTF-IDFベクトルまたは「用語の頻度 – 逆文書頻度」ベクトルを決定することでした。この場合、文中の単語の出現回数を数えることによって…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






